Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Apache Spark- is een geïntegreerde analyse-engine voor grootschalige gegevensverwerking. Azure Data Explorer is een snelle, volledig beheerde gegevensanalyseservice voor realtime analyse van grote hoeveelheden gegevens.
De Kusto-connector voor Spark is een opensource-project dat op elk Spark-cluster kan worden uitgevoerd. Hiermee worden gegevensbron en gegevenssink geïmplementeerd voor het verplaatsen van gegevens tussen Azure Data Explorer en Spark-clusters. Met Behulp van Azure Data Explorer en Apache Spark kunt u snelle en schaalbare toepassingen bouwen die gericht zijn op gegevensgestuurde scenario's. Bijvoorbeeld machine learning (ML), Extract-Transform-Load (ETL) en Log Analytics. Met de connector wordt Azure Data Explorer een geldig gegevensarchief voor standaard Spark-bron- en sinkbewerkingen, zoals write, read, en writeStream.
U kunt naar Azure Data Explorer schrijven via opname in de wachtrij of streamingopname. Lezen vanuit Azure Data Explorer ondersteunt het uitsnoeien van kolommen en predikaat-doorvoer. Dit filtert de gegevens in Azure Data Explorer en vermindert het volume van overgedragen gegevens.
In dit artikel wordt beschreven hoe u de Azure Data Explorer Spark-connector installeert en configureert en gegevens verplaatst tussen Azure Data Explorer en Apache Spark-clusters.
Notitie
Hoewel sommige voorbeelden in dit artikel verwijzen naar een Azure Databricks Spark-cluster, neemt de Azure Data Explorer Spark-connector geen directe afhankelijkheden op Databricks of een andere Spark-distributie.
Voorwaarden
- Een Azure-abonnement. Maak een gratis Azure-account.
- Een Azure Data Explorer-cluster en -database. Een cluster en database maken.
- Een Spark-cluster
- Connectorbibliotheek installeren:
- Vooraf gemaakte bibliotheken voor Spark 2.4+Scala 2.11 of Spark 3+scala 2.12
- Maven-opslagplaats
- Maven 3.x geïnstalleerd
Fooi
Spark 2.3.x-versies worden ook ondersteund, maar mogelijk moet u enkele afhankelijkheden in pom.xmlwijzigen.
De Spark-connector bouwen
Vanaf versie 2.3.0 introduceren we nieuwe artefact-id's ter vervanging van spark-kusto-connector: kusto-spark_3.0_2.12 gericht op Spark 3.x en Scala 2.12.
Notitie
Versies vóór 2.5.1 werken niet meer voor opname naar een bestaande tabel. Werk deze bij naar een latere versie. Deze stap is optioneel. Als u vooraf gebouwde bibliotheken gebruikt, bijvoorbeeld Maven, raadpleegt u Spark-cluster instellen.
Vereisten voor bouwen
Raadpleeg deze bron voor het bouwen van de Spark-connector.
Voor Scala/Java-toepassingen die Maven-projectdefinities gebruiken, koppelt u uw toepassing aan het meest recente artefact. Zoek het meest recente artefact op Maven Central.
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).Als u geen vooraf gedefinieerde bibliotheken gebruikt, moet u de bibliotheken installeren die worden vermeld in afhankelijkheden inclusief de volgende Kusto Java SDK bibliotheken. Om de juiste versie te vinden om te installeren, kijkt u in de pom van de relevante release.
Jar bouwen en alle tests uitvoeren:
mvn clean package -DskipTestsAls u jar wilt bouwen, voert u alle tests uit en installeert u JAR in uw lokale Maven-opslagplaats:
mvn clean install -DskipTests
Zie connectorgebruikvoor meer informatie.
Spark-cluster instellen
Notitie
Het is raadzaam om de nieuwste release van de Kusto Spark-connector te gebruiken bij het uitvoeren van de volgende stappen.
Configureer de volgende Spark-clusterinstellingen op basis van Azure Databricks-cluster Spark 3.0.1 en Scala 2.12:
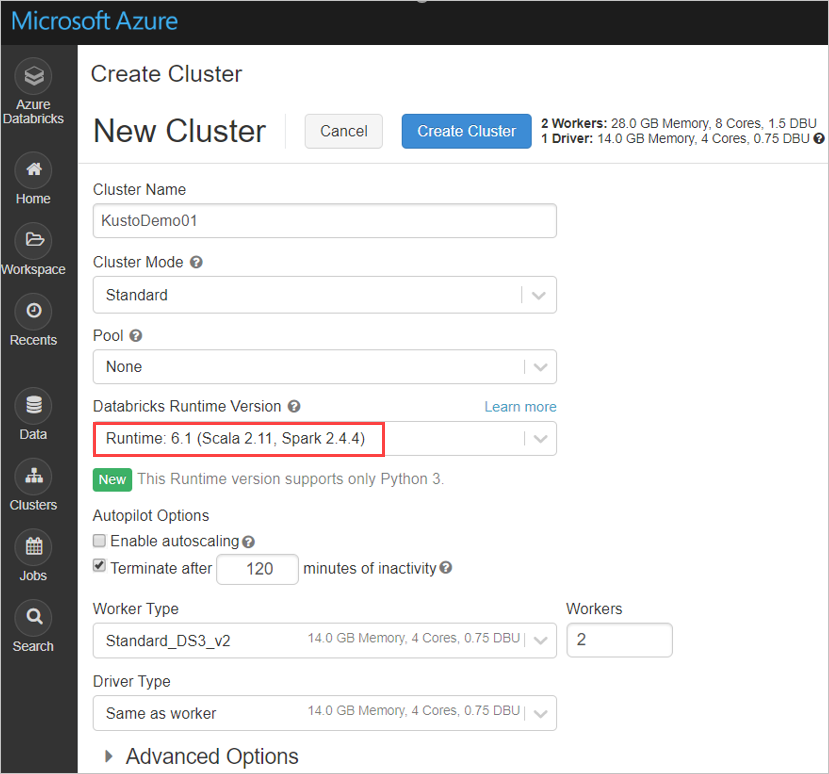
Installeer de nieuwste spark-kusto-connector-bibliotheek vanuit Maven:
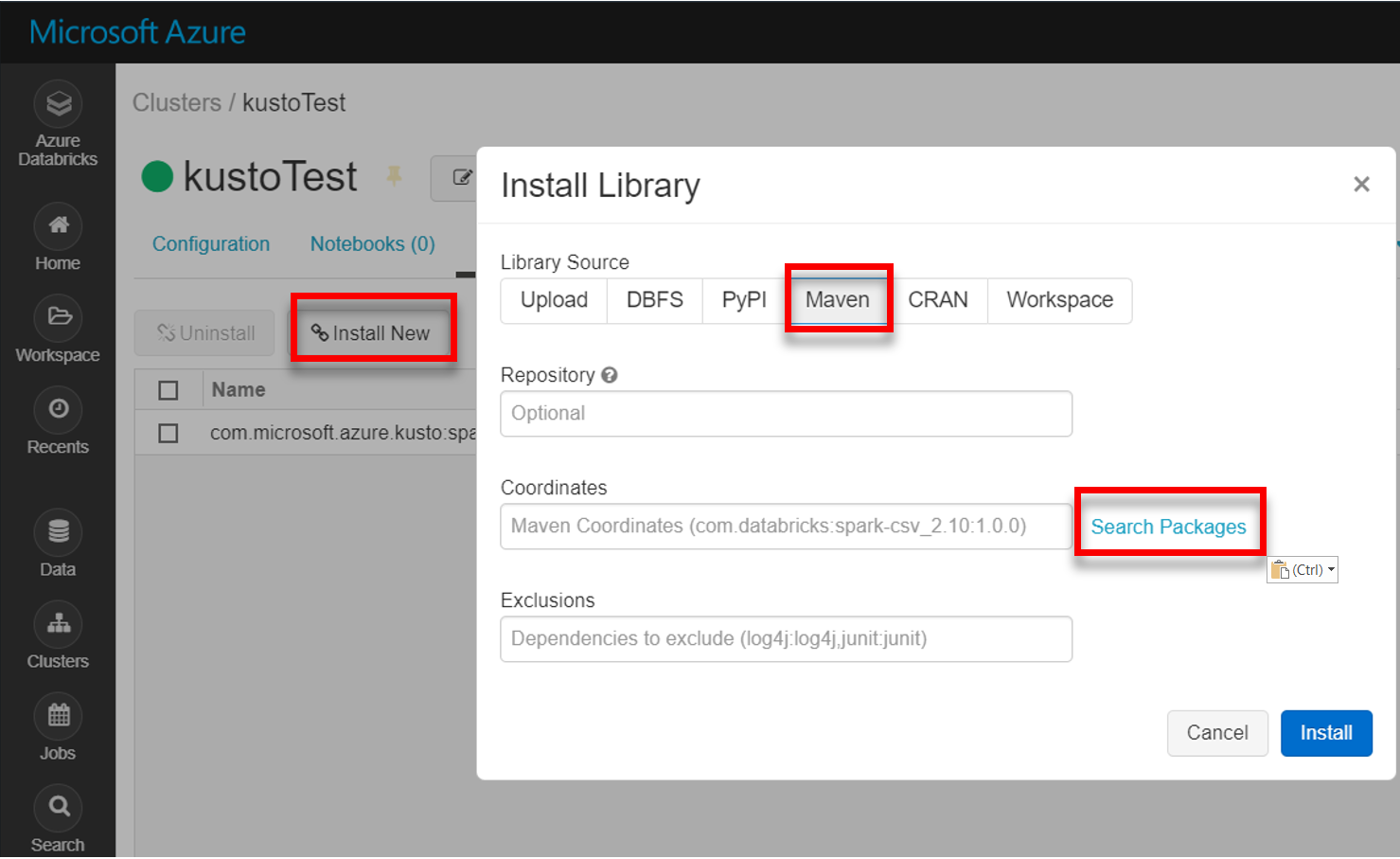
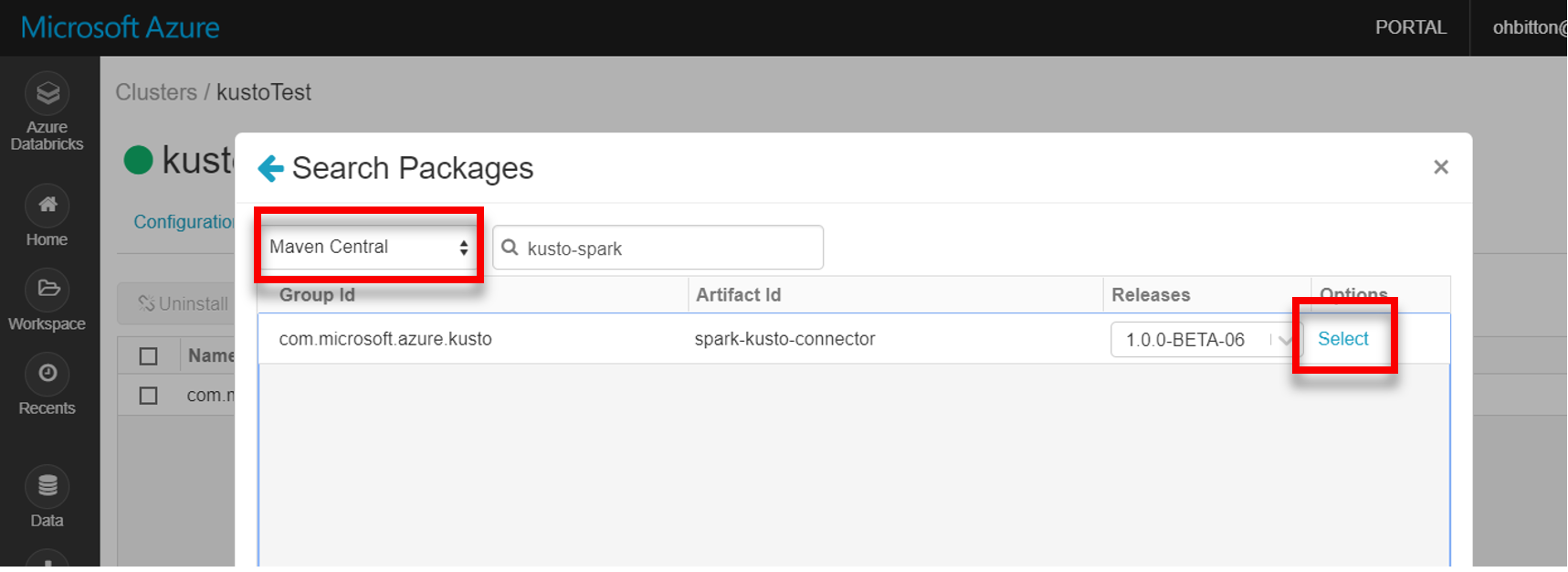
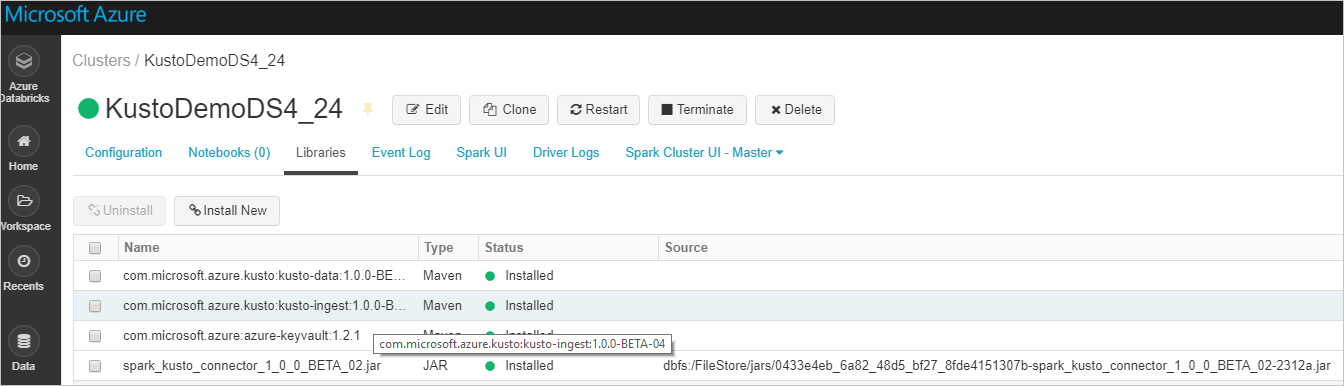
Controleer of alle vereiste bibliotheken zijn geïnstalleerd:
Controleer voor installatie met behulp van een JAR-bestand of andere afhankelijkheden zijn geïnstalleerd:
Authenticatie
Met de Kusto Spark-connector kunt u zich verifiëren met Microsoft Entra ID met behulp van een van de volgende methoden:
- Een Microsoft Entra toepassing
- Een Microsoft Entra-toegangstoken
- apparaatverificatie (voor niet-productiescenario's)
- Een Azure Key Vault-. Om toegang te krijgen tot de Key Vault-resource, installeert u het azure-keyvault-pakket en verstrekt u de inloggegevens van de applicatie.
Microsoft Entra-toepassingsverificatie
Microsoft Entra-toepassingsverificatie is de eenvoudigste en meest voorkomende verificatiemethode en wordt aanbevolen voor de Kusto Spark-connector.
Meld u aan bij uw Azure-abonnement via Azure CLI. Verifieer vervolgens in de browser.
az loginKies het abonnement om de hoofdgebruiker te hosten. Deze stap is nodig wanneer u meerdere abonnementen hebt.
az account set --subscription YOUR_SUBSCRIPTION_GUIDMaak de service-principal. In dit voorbeeld wordt de service-principal
my-service-principalgenoemd.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Kopieer vanuit de geretourneerde JSON-gegevens de
appId,passwordentenantvoor toekomstig gebruik.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
U hebt uw Microsoft Entra-toepassing en service-principal gemaakt.
De Spark-connector maakt gebruik van de volgende Entra-app-eigenschappen voor verificatie:
| Eigenschappen | Optiestring | Beschrijving |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra-toepassings-id (cliënt). |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Microsoft Entra-authenticatie-instantie. Microsoft Entra Directory-ID (tenanthouder). Optioneel: standaard ingesteld op microsoft.com. Zie Microsoft Entra authorityvoor meer informatie. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Microsoft Entra-toepassingssleutel voor de client. |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | Als u al een accessToken hebt dat is gemaakt met toegang tot Kusto, kan deze ook worden doorgegeven aan de connector voor verificatie. |
Notitie
Oudere API-versies (kleiner dan 2.0.0) hebben de volgende naamgeving: 'kustoAADClientID', 'kustoClientAADClientPassword', 'kustoAADAuthorityID'
Kusto-bevoegdheden
Verleen de volgende bevoegdheden aan de Kusto-kant op basis van de Spark-bewerking die u wilt uitvoeren.
| Spark-bewerking | Bevoegdheden |
|---|---|
| Lezen - Enkelvoudige modus | Lezer |
| Lezen : gedistribueerde modus forceren | Lezer |
| Schrijven – Wachtrijmodus met CreateTableIfNotExist-tafelmaakoptie | Admin |
| Schrijven – In wachtrij-modus met de optie Maak tabel FailIfNotExist | Ingestor |
| Schrijven – TransactionalMode | Admin |
Zie op rollen gebaseerd toegangsbeheervoor meer informatie over principal-rollen. Zie beveiligingsrollenbeheervoor het beheren van beveiligingsrollen.
Spark-sink: schrijven naar Kusto
Stel de sinkparameters in:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Spark DataFrame als batch naar Kusto-cluster schrijven.
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Of gebruik de vereenvoudigde syntaxis:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ // Optional, for any extra options: val conf: Map[String, String] = Map() val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Streaminggegevens schrijven:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // As an alternative to adding .option by .option, you can provide a map: val conf: Map[String, String] = Map( KustoSinkOptions.KUSTO_CLUSTER -> cluster, KustoSinkOptions.KUSTO_TABLE -> table, KustoSinkOptions.KUSTO_DATABASE -> database, KustoSourceOptions.KUSTO_ACCESS_TOKEN -> accessToken) // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Spark-bron: lezen vanuit Kusto
Wanneer u kleine hoeveelheden gegevensleest, definieert u de gegevensquery:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Optioneel: als u de tijdelijke blobopslag (en niet Kusto) opgeeft, worden de blobs gemaakt onder de verantwoordelijkheid van de beller. Dit omvat het inrichten van de opslag, het roteren van toegangssleutels en het verwijderen van tijdelijke artefacten. De KustoBlobStorageUtils-module bevat helperfuncties voor het verwijderen van blobs op basis van account- en containercoördinaten en accountreferenties, of een volledige SAS-URL met schrijf-, lees- en lijstmachtigingen. Wanneer de bijbehorende RDD niet meer nodig is, slaat elke transactie tijdelijke blob-artefacten op in een afzonderlijke map. Deze map wordt vastgelegd als onderdeel van logboeken met informatie over leestransacties die zijn gerapporteerd op het Spark-stuurprogrammaknooppunt.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")In het bovenstaande voorbeeld wordt de Sleutelkluis niet geopend met behulp van de connectorinterface; een eenvoudigere methode voor het gebruik van de Databricks-geheimen wordt gebruikt.
Lees uit Kusto.
Als u de tijdelijke blobopslag opgeven, leest u deze als volgt uit Kusto:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Als Kusto- de tijdelijke blobopslag biedt, leest u deze als volgt uit Kusto:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)