Een IoT Edge-workload implementeren met GPU-delen op uw Azure Stack Edge Pro
In dit artikel wordt beschreven hoe workloads in containers de GPU's kunnen delen op uw Azure Stack Edge Pro GPU-apparaat. De aanpak omvat het inschakelen van mpS (Multi-Process Service) en het opgeven van de GPU-workloads via een IoT Edge-implementatie.
Vereisten
Zorg voordat u begint voor het volgende:
U hebt toegang tot een Gpu-apparaat van Azure Stack Edge Pro dat is geactiveerd en dat rekenkracht is geconfigureerd. U hebt het Kubernetes-API-eindpunt en u hebt dit eindpunt toegevoegd aan het
hostsbestand op uw client dat toegang heeft tot het apparaat.U hebt toegang tot een clientsysteem met een ondersteund besturingssysteem. Als u een Windows-client gebruikt, moet het systeem PowerShell 5.0 of hoger uitvoeren om toegang te krijgen tot het apparaat.
Sla de volgende implementatie
jsonop uw lokale systeem op. U gebruikt informatie uit dit bestand om de IoT Edge-implementatie uit te voeren. Deze implementatie is gebaseerd op eenvoudige CUDA-containers die openbaar beschikbaar zijn vanuit Nvidia.{ "modulesContent": { "$edgeAgent": { "properties.desired": { "modules": { "cuda-sample1": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" }, "cuda-sample2": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" } }, "runtime": { "settings": { "minDockerVersion": "v1.25" }, "type": "docker" }, "schemaVersion": "1.1", "systemModules": { "edgeAgent": { "settings": { "image": "mcr.microsoft.com/azureiotedge-agent:1.0", "createOptions": "" }, "type": "docker" }, "edgeHub": { "settings": { "image": "mcr.microsoft.com/azureiotedge-hub:1.0", "createOptions": "{\"HostConfig\":{\"PortBindings\":{\"443/tcp\":[{\"HostPort\":\"443\"}],\"5671/tcp\":[{\"HostPort\":\"5671\"}],\"8883/tcp\":[{\"HostPort\":\"8883\"}]}}}" }, "type": "docker", "status": "running", "restartPolicy": "always" } } } }, "$edgeHub": { "properties.desired": { "routes": { "route": "FROM /messages/* INTO $upstream" }, "schemaVersion": "1.1", "storeAndForwardConfiguration": { "timeToLiveSecs": 7200 } } }, "cuda-sample1": { "properties.desired": {} }, "cuda-sample2": { "properties.desired": {} } } }
GPU-stuurprogramma, CUDA-versie controleren
De eerste stap is om te controleren of op uw apparaat het vereiste GPU-stuurprogramma en de CUDA-versies worden uitgevoerd.
Verbinding maken naar de PowerShell-interface van uw apparaat.
Voer de volgende opdracht uit:
Get-HcsGpuNvidiaSmiNoteer in de Nvidia smi-uitvoer de GPU-versie en de CUDA-versie op uw apparaat. Als u Azure Stack Edge 2102-software uitvoert, komt deze versie overeen met de volgende stuurprogrammaversies:
- GPU-stuurprogrammaversie: 460.32.03
- CUDA-versie: 11.2
Hier volgt een voorbeeld van uitvoer:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Tue Feb 23 10:34:01 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 0000041F:00:00.0 Off | 0 | | N/A 40C P8 15W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Houd deze sessie open, omdat u deze gebruikt om de Nvidia smi-uitvoer in het artikel weer te geven.
Implementeren zonder context delen
U kunt nu een toepassing op uw apparaat implementeren wanneer de Multi-Process Service niet wordt uitgevoerd en er geen contextdeling is. De implementatie vindt plaats via Azure Portal in de iotedge naamruimte die op uw apparaat aanwezig is.
Gebruiker maken in IoT Edge-naamruimte
Eerst maakt u een gebruiker die verbinding maakt met de iotedge naamruimte. De IoT Edge-modules worden geïmplementeerd in de iotedge-naamruimte. Zie Kubernetes-naamruimten op uw apparaat voor meer informatie.
Volg deze stappen om een gebruiker te maken en de gebruiker toegang te verlenen tot de iotedge naamruimte.
Verbinding maken naar de PowerShell-interface van uw apparaat.
Maak een nieuwe gebruiker in de
iotedgenaamruimte. Voer de volgende opdracht uit:New-HcsKubernetesUser -UserName <user name>Hier volgt een voorbeeld van uitvoer:
[10.100.10.10]: PS>New-HcsKubernetesUser -UserName iotedgeuser apiVersion: v1 clusters: - cluster: certificate-authority-data: ===========================//snipped //======================// snipped //============================= server: https://compute.myasegpudev.wdshcsso.com:6443 name: kubernetes contexts: - context: cluster: kubernetes user: iotedgeuser name: iotedgeuser@kubernetes current-context: iotedgeuser@kubernetes kind: Config preferences: {} users: - name: iotedgeuser user: client-certificate-data: ===========================//snipped //======================// snipped //============================= client-key-data: ===========================//snipped //======================// snipped ============================ PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=Kopieer de uitvoer die wordt weergegeven in tekst zonder opmaak. Sla de uitvoer op als een configuratiebestand (zonder extensie) in de
.kubemap van uw gebruikersprofiel op uw lokale computer, bijvoorbeeldC:\Users\<username>\.kube.Verdeel de gebruiker die u hebt gemaakt, toegang tot de
iotedgenaamruimte. Voer de volgende opdracht uit:Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName <user name>Hier volgt een voorbeeld van uitvoer:
[10.100.10.10]: PS>Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName iotedgeuser [10.100.10.10]: PS>
Modules implementeren via de portal
IoT Edge-modules implementeren via Azure Portal. U implementeert openbaar beschikbare Nvidia CUDA-voorbeeldmodules die n-bodysimulatie uitvoeren.
Zorg ervoor dat de IoT Edge-service wordt uitgevoerd op uw apparaat.

Selecteer de IoT Edge-tegel in het rechterdeelvenster. Ga naar IoT Edge-eigenschappen>. Selecteer in het rechterdeelvenster de IoT Hub-resource die is gekoppeld aan uw apparaat.

Ga in de IoT Hub-resource naar Automatisch Apparaatbeheer > IoT Edge. Selecteer in het rechterdeelvenster het IoT Edge-apparaat dat is gekoppeld aan uw apparaat.

Selecteer Modules instellen.

Selecteer + Toevoegen > + IoT Edge-module.

Geef op het tabblad Module Instellingen de naam van de IoT Edge-module en de afbeeldings-URI op. Stel het pull-beleid voor installatiekopieën in op Maken.

Geef op het tabblad Omgevingsvariabelen NVIDIA_VISIBLE_DEVICES op als 0.
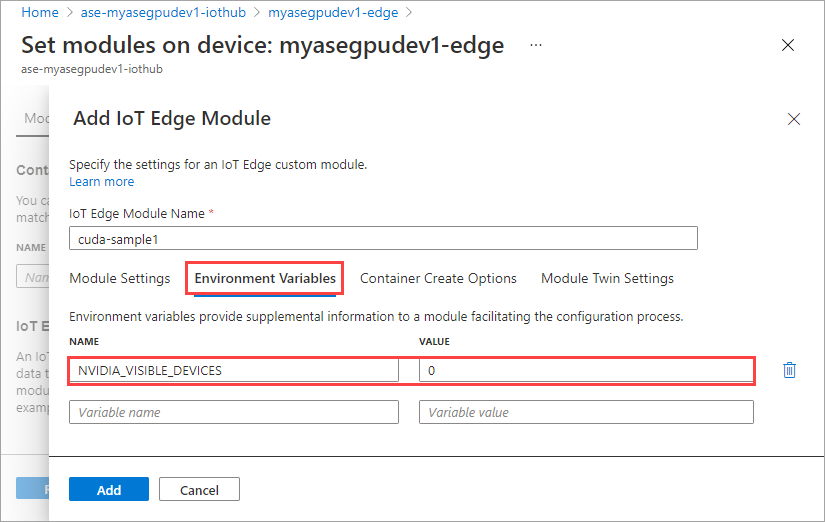
Geef op het tabblad Opties voor container maken de volgende opties op:
{ "Entrypoint": [ "/bin/sh" ], "Cmd": [ "-c", "/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done" ], "HostConfig": { "IpcMode": "host", "PidMode": "host" } }De opties worden als volgt weergegeven:

Selecteer Toevoegen.
De module die u hebt toegevoegd, moet worden weergegeven als Actief.

Herhaal alle stappen om een module toe te voegen die u hebt gevolgd bij het toevoegen van de eerste module. Geef in dit voorbeeld de naam van de module op als
cuda-sample2.
Gebruik dezelfde omgevingsvariabele als beide modules dezelfde GPU delen.

Gebruik dezelfde opties voor het maken van containers die u hebt opgegeven voor de eerste module en selecteer Toevoegen.

Selecteer Op de pagina Modules instellen de optie Controleren en maken en selecteer vervolgens Maken.

De runtimestatus van beide modules moet nu worden weergegeven als Actief.

Workloadimplementatie bewaken
Open een nieuwe PowerShell-sessie.
Vermeld de pods die worden uitgevoerd in de
iotedgenaamruimte. Voer de volgende opdracht uit:kubectl get pods -n iotedgeHier volgt een voorbeeld van uitvoer:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-ssng8 2/2 Running 0 5s cuda-sample2-6db6d98689-d74kb 2/2 Running 0 4s edgeagent-79f988968b-7p2tv 2/2 Running 0 6d21h edgehub-d6c764847-l8v4m 2/2 Running 0 24h iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 6d21h PS C:\WINDOWS\system32>Er zijn twee pods
cuda-sample1-97c494d7f-lnmnsencuda-sample2-d9f6c4688-2rld9worden uitgevoerd op uw apparaat.Hoewel beide containers de n-bodysimulatie uitvoeren, bekijkt u het GPU-gebruik van de Nvidia smi-uitvoer. Ga naar de PowerShell-interface van het apparaat en voer deze uit
Get-HcsGpuNvidiaSmi.Hier volgt een voorbeeld van uitvoer wanneer beide containers de n-body simulatie uitvoeren:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:31:16 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 52C P0 69W / 70W | 221MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 188342 C /tmp/nbody 109MiB | | 0 N/A N/A 188413 C /tmp/nbody 109MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Zoals u ziet, worden er twee containers uitgevoerd met n-bodysimulatie op GPU 0. U kunt ook het bijbehorende geheugengebruik bekijken.
Zodra de simulatie is voltooid, ziet de Nvidia smi-uitvoer dat er geen processen worden uitgevoerd op het apparaat.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:54:48 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Nadat de n-bodysimulatie is voltooid, bekijkt u de logboeken om inzicht te hebben in de details van de implementatie en de tijd die nodig is om de simulatie te voltooien.
Hier volgt een voorbeeld van uitvoer van de eerste container:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample1-869989578c-ssng8 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170171.531 ms = 98.590 billion interactions per second = 1971.801 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Hier volgt een voorbeeld van uitvoer van de tweede container:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-d74kb cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170054.969 ms = 98.658 billion interactions per second = 1973.152 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Stop de module-implementatie. In de IoT Hub-resource voor uw apparaat:
Ga naar IoT Edge voor automatische apparaatimplementatie>. Selecteer het IoT Edge-apparaat dat overeenkomt met uw apparaat.
Ga naar Modules instellen en selecteer een module.

Selecteer een module op het tabblad Modules .
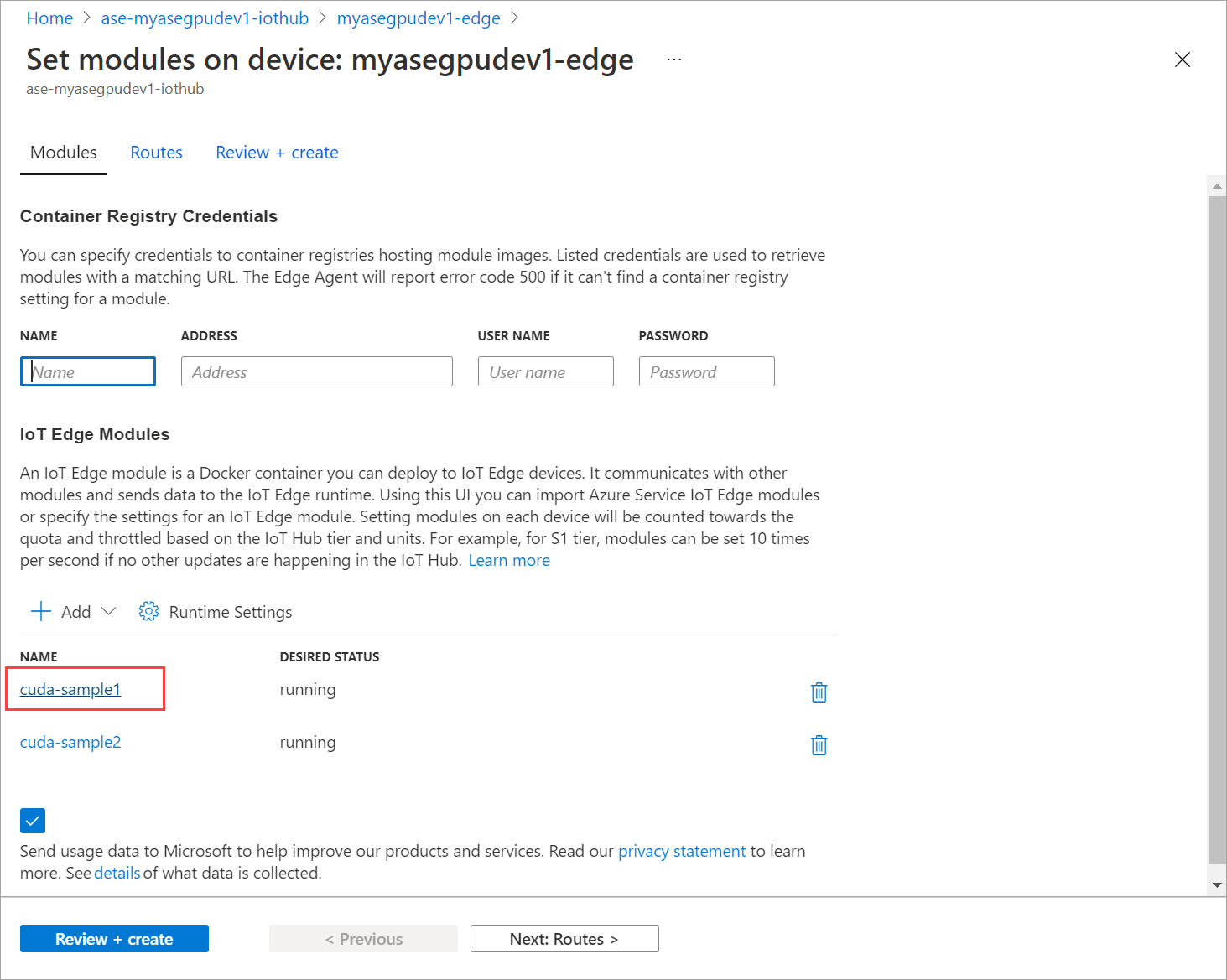
Stel op het tabblad Module-instellingen de gewenste status in op gestopt. Selecteer Bijwerken.

Herhaal de stappen om de tweede module te stoppen die op het apparaat is geïmplementeerd. Selecteer Controleren en maken en selecteer vervolgens Maken. Hiermee moet de implementatie worden bijgewerkt.

Pagina Modules instellen meerdere keren vernieuwen. totdat de runtimestatus van de module wordt weergegeven als Gestopt.

Implementeren met context delen
U kunt nu de n-bodysimulatie implementeren op twee CUDA-containers wanneer MPS wordt uitgevoerd op uw apparaat. Eerst schakelt u MPS in op het apparaat.
Verbinding maken naar de PowerShell-interface van uw apparaat.
Als u MPS op uw apparaat wilt inschakelen, voert u de
Start-HcsGpuMPSopdracht uit.[10.100.10.10]: PS>Start-HcsGpuMPS K8S-1HXQG13CL-1HXQG13: Set compute mode to EXCLUSIVE_PROCESS for GPU 0000191E:00:00.0. All done. Created nvidia-mps.service [10.100.10.10]: PS>Haal de Nvidia smi-uitvoer op uit de PowerShell-interface van het apparaat. U kunt het
nvidia-cuda-mps-serverproces zien of de MPS-service wordt uitgevoerd op het apparaat.Hier volgt een voorbeeld van uitvoer:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:37:39 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 36C P8 9W / 70W | 28MiB / 15109MiB | 0% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmiImplementeer de modules die u eerder hebt gestopt. Stel de gewenste status in op uitvoering via Set-modules.
Hier volgt de voorbeelduitvoer:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-2zxh6 2/2 Running 0 44s cuda-sample2-6db6d98689-fn7mx 2/2 Running 0 44s edgeagent-79f988968b-7p2tv 2/2 Running 0 5d20h edgehub-d6c764847-l8v4m 2/2 Running 0 27m iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 5d20h PS C:\WINDOWS\system32>U kunt zien dat de modules worden geïmplementeerd en uitgevoerd op uw apparaat.
Wanneer de modules worden geïmplementeerd, wordt de n-bodysimulatie ook uitgevoerd op beide containers. Hier volgt de voorbeelduitvoer wanneer de simulatie is voltooid op de eerste container:
PS C:\WINDOWS\system32> kubectl -n iotedge logs cuda-sample1-869989578c-2zxh6 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155256.062 ms = 108.062 billion interactions per second = 2161.232 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Hier volgt de voorbeelduitvoer wanneer de simulatie is voltooid op de tweede container:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-fn7mx cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155366.359 ms = 107.985 billion interactions per second = 2159.697 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Haal de Nvidia smi-uitvoer op van de PowerShell-interface van het apparaat wanneer beide containers de n-body simulatie uitvoeren. Hier volgt een voorbeeld van uitvoer. Er zijn drie processen, het
nvidia-cuda-mps-serverproces (type C) komt overeen met de MPS-service en de/tmp/nbodyprocessen (type M + C) komen overeen met de n-body-workloads die door de modules zijn geïmplementeerd.[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:59:44 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 54C P0 69W / 70W | 242MiB / 15109MiB | 100% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 56832 M+C /tmp/nbody 107MiB | | 0 N/A N/A 56900 M+C /tmp/nbody 107MiB | | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi