Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Notitie
Op deze pagina worden JSON-voorbeelden van beleidsdefinities gebruikt. In het nieuwe beleidsformulier worden de meeste JSON-beleidsdefinities verborgen met behulp van vervolgkeuzelijsten en andere UI-elementen. De beleidsregels en logica zijn nog steeds hetzelfde, maar gebruikers kunnen definities configureren zonder JSON-code te schrijven. Als u het nieuwe formulier niet wilt gebruiken, kunt u de instelling Nieuw formulier boven aan de beleidspagina uitschakelen.
Deze pagina is een verwijzing voor berekeningsbeleidsdefinities, waaronder een lijst met beschikbare beleidskenmerken en beperkingstypen. Er zijn ook voorbeeldbeleidsregels waarnaar u kunt verwijzen voor veelvoorkomende gebruiksvoorbeelden.
Wat zijn beleidsdefinities?
Beleidsdefinities zijn afzonderlijke beleidsregels die worden uitgedrukt in JSON.
Een definitie kan een regel toevoegen aan een van de kenmerken die worden beheerd met de Clusters-API. Deze definities stellen bijvoorbeeld een standaardtijd voor automatisch bepalen in, verbieden dat gebruikers pools gebruiken en het gebruik van Photon afdwingen:
{
"autotermination_minutes": {
"type": "unlimited",
"defaultValue": 4320,
"isOptional": true
},
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"runtime_engine": {
"type": "fixed",
"value": "PHOTON",
"hidden": true
}
}
Er kan slechts één beperking per kenmerk zijn. Het pad van een kenmerk weerspiegelt de naam van het API-kenmerk. Voor geneste kenmerken voegt het pad de geneste kenmerknamen samen met behulp van puntjes. Kenmerken die niet zijn gedefinieerd in een beleidsdefinitie, worden niet beperkt.
Beleidsdefinities configureren met behulp van het nieuwe beleidsformulier
Met het nieuwe beleidsformulier kunt u beleidsdefinities configureren met behulp van vervolgkeuzelijsten en andere elementen van de gebruikersinterface. Dit betekent dat beheerders beleidsregels kunnen schrijven zonder de syntaxis van het beleid te hoeven leren of ernaar te verwijzen.
JSON-beleidsdefinities worden nog steeds ondersteund in het nieuwe formulier. Deze kunnen worden toegevoegd aan het veld Aangepaste JSON onder Geavanceerde opties.
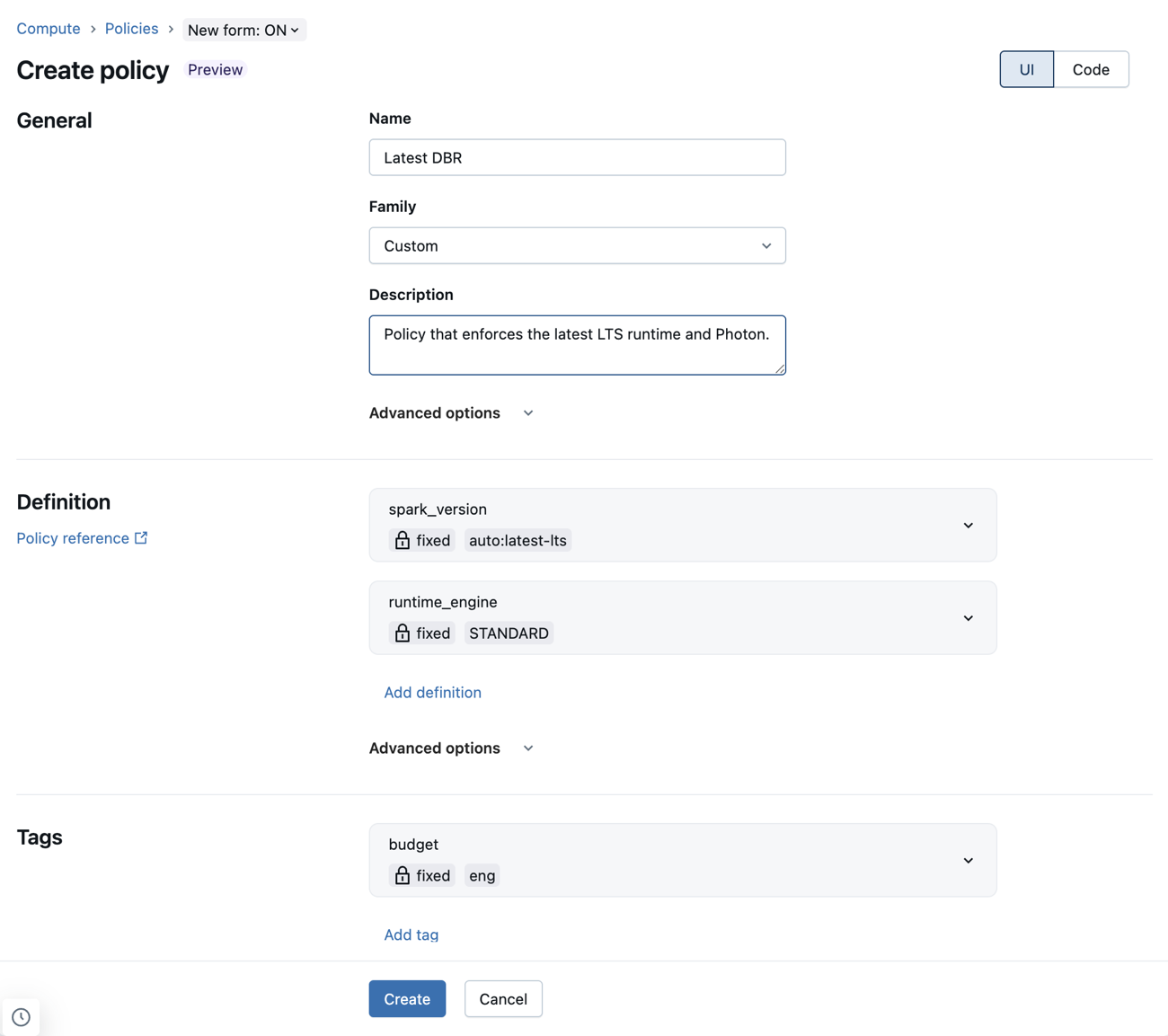
Bekende beperkingen met behulp van het nieuwe beleidsformulier
Als een beleid niet wordt ondersteund door het nieuwe formulier voor rekenbeleid, worden alle incompatibele definities weergegeven in het aangepaste JSON-veld in de sectie Geavanceerde opties . Voor de onderstaande velden wordt alleen een subset van geldig beleid ondersteund:
-
workload_type: Het beleid moet zowel
workload_type.clients.notebooksalsworkload_type.clients.jobsdefiniëren. Elk van deze regels moet worden vastgezet op ofweltrueoffalse. -
dbus_per_hour: Alleen bereikbeleidsregels die opgeven
maxValueen niet opgevenminValue, worden ondersteund. -
ssh_public_keys: Alleen vaste beleidsregels worden ondersteund. Het
ssh_public_keysbeleid mag geen indexen overslaan. Bijvoorbeeld,ssh_public_keys.0,ssh_public_keys.1ssh_public_keys.2is geldig, maarssh_public_keys.0ssh_public_keys.2, isssh_public_keys.3niet geldig. -
cluster_log_conf: De
cluster_log_conf.pathlijst mag geen acceptatielijst of een blokkeringslijst zijn. -
init_scripts: Geïndexeerd beleid (namelijk
init_scripts.0.volumes.destination) moet worden opgelost. Wildcardbeleid (dat wil zeggen,init_scripts.*.volumes.destination) moet verboden zijn. Geïndexeerd beleid mag geen indexen overslaan.
ondersteunde kenmerken
Beleidsregels ondersteunen alle beheerde kenmerken met de Clusters API. Het type beperkingen dat u op kenmerken kunt plaatsen, kan per instelling variëren op basis van hun type en relatie tot de elementen van de gebruikersinterface. U kunt geen beleid gebruiken om rekenmachtigingen te definiëren.
U kunt ook beleidsregels gebruiken om het maximum aantal DBU's per uur en clustertype in te stellen. Zie Virtuele kenmerkpaden.
De volgende tabel bevat de ondersteunde paden voor beleidskenmerken:
| Kenmerkpad | Typen | Beschrijving |
|---|---|---|
autoscale.max_workers |
optioneel nummer | Als dit veld is verborgen, verwijdert u het veld maximumaantal werknemers uit de gebruikersinterface. |
autoscale.min_workers |
optioneel nummer | Als u dit verborgen hebt, verwijdert u het veld minimumaantal werknemers uit de gebruikersinterface. |
autotermination_minutes |
getal | Een waarde van 0 vertegenwoordigt geen automatische beëindiging. Als dit verborgen is, verwijdert u het selectievakje voor automatische beëindiging en de waarde-invoer uit de gebruikersinterface. |
azure_attributes.availability |
tekenreeks | Bepaalt of het rekengebruik gebruikmaakt van on-demand of spot-exemplaren (SPOT_AZURE, ON_DEMAND_AZUREof SPOT_WITH_FALLBACK_AZURE). |
azure_attributes.first_on_demand |
getal | Hiermee bepaalt u hoeveel clusterknooppunten on-demand exemplaren gebruiken, te beginnen met het stuurprogrammaknooppunt. Een waarde van 1 stelt bijvoorbeeld het stuurprogrammaknooppunt in op on-demand. Een waarde van 2 stelt het driverknooppunt en één werkknooppunt in op on-demand. |
azure_attributes.spot_bid_max_price |
getal | Hiermee bepaalt u de maximumprijs voor Azure-spot-exemplaren. |
cluster_log_conf.path |
tekenreeks | De doel-URL van de logboekbestanden. |
cluster_log_conf.type |
tekenreeks | Het type logboekbestemming.
DBFS en VOLUMES zijn de enige acceptabele waarden. |
cluster_name |
tekenreeks | De clusternaam. |
custom_tags.* |
tekenreeks | Regel specifieke tagwaarden door de tagnaam toe te voegen, bijvoorbeeld: custom_tags.<mytag>. |
data_security_mode |
tekenreeks | Hiermee stelt u de toegangsmodus van het cluster in. Unity Catalog vereist SINGLE_USER of USER_ISOLATION (Standard-toegangsmodus in de gebruikersinterface). Een waarde van NONE betekent dat er geen beveiligingsfuncties zijn ingeschakeld. |
docker_image.basic_auth.password |
tekenreeks | Het wachtwoord voor de basisauthenticatie van de Databricks Container Services-afbeelding. |
docker_image.basic_auth.username |
tekenreeks | De gebruikersnaam voor de basisverificatie van de Databricks Container Services-image. |
docker_image.url |
tekenreeks | Beheert de image-URL van Databricks Container Services. Als dit verborgen is, verwijdert u de sectie Databricks Container Services uit de gebruikersinterface. |
driver_node_type_id |
optionele tekst | Als dit verborgen is, verwijdert u de typeselectie van het stuurprogrammaknooppunt uit de gebruikersinterface. |
driver_node_type_flexibility.alternate_node_type_ids |
tekenreeks | Hiermee geeft u alternatieve knooppunttypen voor het stuurprogrammaknooppunt. Alleen vaste beleidsregels worden ondersteund. Zie Flexibele knooppunttypen. |
enable_local_disk_encryption |
Booleaans | Ingesteld op true om schijven die lokaal zijn gekoppeld aan het cluster te versleutelen (zoals opgegeven via de API) in of false uit te schakelen. |
init_scripts.*.workspace.destination
init_scripts.*.volumes.destination
init_scripts.*.abfss.destination
init_scripts.*.file.destination
|
tekenreeks |
* verwijst naar de index van het init-script in de kenmerkmatrix. Zie Beleid documenteren voor array-attributen. |
instance_pool_id |
tekenreeks | Hiermee bepaalt u de pool die door werkknooppunten wordt gebruikt als driver_instance_pool_id ook is gedefinieerd; anders geldt het voor alle clusternodes. Als u pools gebruikt voor werkknooppunten, moet u ook pools gebruiken voor het stuurprogrammaknooppunt. Wanneer verborgen, wordt de selectie van de pool uit de gebruikersinterface verwijderd. |
driver_instance_pool_id |
tekenreeks | Indien opgegeven configureert u een andere pool voor het stuurprogrammaknooppunt dan voor werkknooppunten. Als dit niet is opgegeven, wordt instance_pool_idovergenomen. Als u pools gebruikt voor werkknooppunten, moet u ook pools gebruiken voor het stuurprogrammaknooppunt. Wanneer verborgen, wordt de selectie van bestuurderspools uit de gebruikersinterface verwijderd. |
is_single_node |
Booleaans | Als true is ingesteld, moet de computing een enkel knooppunt zijn. Dit kenmerk wordt alleen ondersteund wanneer de gebruiker het eenvoudige formulier gebruikt. |
node_type_id |
tekenreeks | Als dit verborgen is, verwijdert u de selectie van het werkknooppunttype uit de gebruikersinterface. |
worker_node_type_flexibility.alternate_node_type_ids |
tekenreeks | Specificeert alternatieve typen knooppunten voor werkknooppunten. Alleen vaste beleidsregels worden ondersteund. Zie Flexibele knooppunttypen. |
num_workers |
optioneel nummer | Wanneer verborgen, wordt de werknummerspecificatie uit de gebruikersinterface verwijderd. |
runtime_engine |
tekenreeks | Bepaalt of het cluster Photon gebruikt of niet. Mogelijke waarden zijn PHOTON of STANDARD. |
single_user_name |
tekenreeks | Hiermee bepaalt u welke gebruikers of groepen kunnen worden toegewezen aan de rekenresource. |
spark_conf.* |
optionele tekst | Hiermee bepaalt u specifieke configuratiewaarden door de naam van de configuratiesleutel toe te voegen, bijvoorbeeld: spark_conf.spark.executor.memory. |
spark_env_vars.* |
optionele tekst | Hiermee bepaalt u specifieke waarden voor spark-omgevingsvariabele door de omgevingsvariabele toe te voegen, bijvoorbeeld: spark_env_vars.<environment variable name>. |
spark_version |
tekenreeks | De versienaam van de Spark-afbeelding zoals gespecificeerd door de API (de Databricks Runtime). U kunt ook speciale beleidswaarden gebruiken die de Databricks Runtime dynamisch selecteren. Zie Speciale beleidswaarden voor de selectie van Databricks Runtime. |
use_ml_runtime |
Booleaans | Hiermee bepaalt u of een ML-versie van de Databricks Runtime moet worden gebruikt. Dit kenmerk wordt alleen ondersteund wanneer de gebruiker het eenvoudige formulier gebruikt. |
workload_type.clients.jobs |
Booleaans | Hiermee definieert u of de rekenresource kan worden gebruikt voor taken. Zie Voorkom dat rekenkracht wordt gebruikt voor taken. |
workload_type.clients.notebooks |
Booleaans | Hiermee definieert u of de rekenresource kan worden gebruikt met notebooks. Zie Voorkom dat rekenkracht wordt gebruikt voor taken. |
Virtuele kenmerkpaden
Deze tabel bevat twee extra synthetische kenmerken die worden ondersteund door beleidsregels. Als u het nieuwe beleidsformulier gebruikt, kunnen deze kenmerken worden ingesteld in de sectie Geavanceerde opties .
| Kenmerkpad | Typen | Beschrijving |
|---|---|---|
dbus_per_hour |
getal | Berekend kenmerk dat de maximale DBU's vertegenwoordigt die een resource per uur kan gebruiken, inclusief het stuurprogrammaknooppunt. Deze metrische waarde is een directe manier om de kosten op het afzonderlijke rekenniveau te beheren. Gebruik met bereikbeperking. |
cluster_type |
tekenreeks | Vertegenwoordigt het type cluster dat kan worden gemaakt:
Opgegeven typen berekeningen toestaan of blokkeren die op basis van het beleid worden gemaakt. Als de all-purpose waarde niet is toegestaan, wordt het beleid niet getoond in de algemene interface voor het creëren van computetaken. Als de job-waarde niet is toegestaan, wordt de richtlijn niet weergegeven in de compute-UI voor het maken van opdrachten. |
Flexibele knooppunttypen
Met de kenmerken voor flexibele knooppunttypen kunt u alternatieve knooppunttypen opgeven die de rekenresource kan gebruiken als het primaire knooppunttype niet beschikbaar is. Deze kenmerken hebben speciale beleidsvereisten:
- Alleen vaste beleidsregels worden ondersteund. Alle andere beleidstypen zijn niet toegestaan en worden geweigerd tijdens het maken van het beleid.
- Een lege tekenreeks bij het beleid resulteert in een lege lijst van alternatieve knooppunttypen, waardoor flexibele knooppunttypen worden uitgeschakeld.
Aanpassing voor een specifieke lijst met knooppunttypen
In tegenstelling tot de bijbehorende clusters-API-velden die gebruikmaken van een matrix met tekenreeksen, gebruiken de rekenbeleidskenmerken één tekenreekswaarde waarmee de matrix van knooppunttypen wordt gecodeerd als een door komma's gescheiden lijst. Bijvoorbeeld:
{
"worker_node_type_flexibility.alternate_node_type_ids": {
"type": "fixed",
"value": "nodeA,nodeB"
}
}
Als u de Clusters-API gebruikt om een rekenresource te maken met een toegewezen beleid, raadt Databricks aan de velden niet worker_node_type_flexibility in driver_node_type_flexibility te stellen. Als u deze velden instelt, moeten de knooppunttypen en de volgorde van de matrix exact overeenkomen met de door komma's gescheiden lijst van het beleid, anders kan de berekening niet worden gemaakt. De bovenstaande beleidsdefinitie wordt bijvoorbeeld ingesteld als:
"worker_node_type_flexibility": {
"alternate_node_type_ids": ["nodeA", "nodeB"]
}
Flexibele knooppunttypen uitschakelen
Als u flexibele knooppunttypen wilt uitschakelen, stelt u de waarde in op een lege tekenreeks. Bijvoorbeeld:
{
"worker_node_type_flexibility.alternate_node_type_ids": {
"type": "fixed",
"value": ""
}
}
Speciale beleidswaarden voor Databricks Runtime-selectie
Het kenmerk spark_version ondersteunt speciale waarden die dynamisch worden toegewezen aan een Databricks Runtime-versie op basis van de huidige set ondersteunde Databricks Runtime-versies.
De volgende waarden kunnen worden gebruikt in het kenmerk spark_version:
-
auto:latest: verwijst naar de nieuwste GA Databricks Runtime-versie. -
auto:latest-ml: Komt overeen met de meest recente versie van Databricks Runtime ML. -
auto:latest-lts: Verwijst naar de nieuwste Long-Term Support (LTS) versie van Databricks Runtime. -
auto:latest-lts-ml: Verwijst naar de nieuwste LTS Databricks Runtime ML-versie. -
auto:prev-major: wijst naar de tweede nieuwste GA Databricks Runtime-versie. Alsauto:latestbijvoorbeeld 14,2 is, isauto:prev-major13,3. -
auto:prev-major-ml: komt overeen met de op één na nieuwste GA-versie van Databricks Runtime ML. Alsauto:latestbijvoorbeeld 14,2 is, isauto:prev-major13,3. -
auto:prev-lts: Verwijst naar de op een na nieuwste LTS-versie van Databricks Runtime. Alsauto:latest-ltsbijvoorbeeld 13,3 is, isauto:prev-lts12,2. -
auto:prev-lts-ml: Verwijst naar de één-na-nieuwste LTS Databricks Runtime ML-versie. Alsauto:latest-ltsbijvoorbeeld 13,3 is, isauto:prev-lts12,2.
Notitie
Als u deze waarden gebruikt, wordt de automatische berekening niet bijgewerkt wanneer er een nieuwe runtimeversie wordt uitgebracht. Een gebruiker moet expliciet de compute-instellingen voor de Databricks Runtime-versie bewerken om deze te wijzigen.
Ondersteunde beleidstypen
Deze sectie bevat een verwijzing voor elk van de beschikbare beleidstypen. Er zijn twee categorieën beleidstypen: vaste beleidsregels en beperkingsbeleid.
Vaste beleidsregels verhinderen gebruikersconfiguratie op een kenmerk. De twee typen vaste beleidsregels zijn:
Door beleidsregels te beperken, worden de opties van een gebruiker voor het configureren van een kenmerk beperkt. Door beleidsregels te beperken, kunt u ook standaardwaarden instellen en kenmerken optioneel maken. Zie Aanvullende beleidsvelden voor beperkingen.
Uw opties voor het beperken van beleidsregels zijn:
vast beleid
Vaste beleidsregels beperken het kenmerk tot de opgegeven waarde. Voor andere kenmerkwaarden dan numerieke en booleaanse waarden moet de waarde worden vertegenwoordigd door of converteerbaar naar een tekenreeks.
Met vast beleid kunt u het kenmerk ook verbergen in de gebruikersinterface door het veld hidden in te stellen op true.
interface FixedPolicy {
type: "fixed";
value: string | number | boolean;
hidden?: boolean;
}
Met dit voorbeeldbeleid wordt de Databricks Runtime-versie vastgezet en wordt het veld verborgen in de gebruikersinterface.
{
"spark_version": { "type": "fixed", "value": "auto:latest-lts", "hidden": true }
}
Verboden beleid
Een verboden beleid voorkomt dat gebruikers een kenmerk configureren. Verboden beleidsregels zijn alleen compatibel met optionele kenmerken.
interface ForbiddenPolicy {
type: "forbidden";
}
Dit beleid verbiedt het koppelen van pools aan de computing voor werkknooppunten. Pools zijn ook verboden voor de besturingsnode, omdat driver_instance_pool_id het beleid erft.
{
"instance_pool_id": { "type": "forbidden" }
}
beleid voor toegangsverlening
Een allowlist-beleid specificeert een lijst met waarden die de gebruiker kan kiezen bij het configureren van een kenmerk.
interface AllowlistPolicy {
type: "allowlist";
values: (string | number | boolean)[];
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
Met dit voorbeeld van een acceptatielijst kan de gebruiker kiezen tussen twee Databricks Runtime-versies:
{
"spark_version": { "type": "allowlist", "values": ["13.3.x-scala2.12", "12.2.x-scala2.12"] }
}
beleid voor blokkeerlijst
Het bloklijstbeleid bevat niet-toegestane waarden. Omdat de waarden exacte overeenkomsten moeten zijn, werkt dit beleid mogelijk niet zoals verwacht wanneer het kenmerk leniënt is in de weergave van de waarde (bijvoorbeeld het toestaan van voorloop- en volgspaties).
interface BlocklistPolicy {
type: "blocklist";
values: (string | number | boolean)[];
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
In dit voorbeeld wordt voorkomen dat de gebruiker 7.3.x-scala2.12 selecteert als Databricks Runtime.
{
"spark_version": { "type": "blocklist", "values": ["7.3.x-scala2.12"] }
}
Regex-beleid
Een regex-beleid beperkt de beschikbare waarden tot de waarden die overeenkomen met de regex. Zorg ervoor dat uw regex is verankerd aan het begin en einde van de tekenreekswaarde voor veiligheid.
interface RegexPolicy {
type: "regex";
pattern: string;
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
In dit voorbeeld worden de Databricks Runtime-versies beperkt waaruit een gebruiker kan kiezen:
{
"spark_version": { "type": "regex", "pattern": "13\\.[3456].*" }
}
Bereikbeleid
Een bereikbeleid beperkt de waarde tot een opgegeven bereik met behulp van de velden minValue en maxValue. De waarde moet een decimaal getal zijn.
De numerieke limieten moeten worden vertegenwoordigd als een dubbele drijvende-kommawaarde. Als u een gebrek aan een specifieke limiet wilt aangeven, kunt u minValue of maxValueweglaten.
interface RangePolicy {
type: "range";
minValue?: number;
maxValue?: number;
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
In dit voorbeeld wordt het maximale aantal werknemers beperkt tot 10.
{
"num_workers": { "type": "range", "maxValue": 10 }
}
Onbeperkt beleid
Het onbeperkte beleid wordt gebruikt om kenmerken vereist te maken of om de standaardwaarde in de gebruikersinterface in te stellen.
interface UnlimitedPolicy {
type: "unlimited";
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
In dit voorbeeld wordt de COST_BUCKET-tag toegevoegd aan de berekening:
{
"custom_tags.COST_BUCKET": { "type": "unlimited" }
}
Als u een standaardwaarde wilt instellen voor een Spark-configuratievariabele, maar u kunt deze ook weglaten (verwijderen):
{
"spark_conf.spark.my.conf": { "type": "unlimited", "isOptional": true, "defaultValue": "my_value" }
}
Aanvullende limiterende beleidsvelden
Voor het beperken van beleidstypen kunt u twee extra velden opgeven:
-
defaultValue: de waarde die automatisch wordt ingevuld in de gebruikersinterface voor het creëren van berekeningen. -
isOptional: een beperkend beleid voor een kenmerk maakt dit automatisch vereist. Als u het kenmerk optioneel wilt maken, stelt u het veldisOptionalin optrue.
Notitie
Standaardwaarden worden niet automatisch toegepast op berekeningen die zijn gemaakt met de Clusters-API. Als u standaardwaarden wilt toepassen met behulp van de API, voegt u de parameter toe apply_policy_default_values aan de berekeningsdefinitie en stelt u deze in op true.
In dit voorbeeldbeleid wordt de standaardwaarde id1 voor de pool voor werkknooppunten opgegeven, maar wordt deze optioneel. Wanneer u de berekening maakt, kunt u een andere pool selecteren of ervoor kiezen om er geen te gebruiken. Als driver_instance_pool_id niet is gedefinieerd in het beleid of bij het instellen van de berekening, wordt dezelfde pool gebruikt voor de worker nodes en de driver node.
{
"instance_pool_id": { "type": "unlimited", "isOptional": true, "defaultValue": "id1" }
}
Beleid schrijven voor matrixkenmerken
U kunt op twee manieren beleidsregels voor matrixkenmerken opgeven:
- Algemene beperkingen voor alle matrixelementen. Deze beperkingen maken gebruik van het jokerteken
*in het beleidspad. - Specifieke beperkingen voor een matrixelement in een specifieke index. Deze beperkingen gebruiken een getal in het pad.
Notitie
De kenmerken van het flexibele knooppunttype (worker_node_type_flexibility.alternate_node_type_ids en driver_node_type_flexibility.alternate_node_type_ids) zijn velden van het matrixtype in de Clusters-API, maar ze volgen niet het jokerteken/geïndexeerde padpatroon dat hier wordt beschreven. Voor deze kenmerken is één beleidsregel vereist waarmee de volledige lijst wordt opgegeven als een door komma's gescheiden tekenreeks. Zie Flexibele knooppunttypen voor meer informatie.
Voor het matrixkenmerk init_scriptsbeginnen de algemene paden bijvoorbeeld met init_scripts.* en de specifieke paden met init_scripts.<n>, waarbij <n> een geheel getalindex in de matrix is (beginnend met 0).
U kunt algemene en specifieke beperkingen combineren, in welk geval de algemene beperking van toepassing is op elk matrixelement dat geen specifieke beperking heeft. In elk geval is slechts één beleidsbeperking van toepassing.
In de volgende secties ziet u voorbeelden van veelvoorkomende voorbeelden die gebruikmaken van matrixkenmerken.
Vermeldingen specifiek voor inclusie zijn vereist
U kunt geen specifieke waarden vereisen zonder de volgorde op te geven. Bijvoorbeeld:
{
"init_scripts.0.volumes.destination": {
"type": "fixed",
"value": "<required-script-1>"
},
"init_scripts.1.volumes.destination": {
"type": "fixed",
"value": "<required-script-2>"
}
}
Een vaste waarde voor de hele lijst vereisen
{
"init_scripts.0.volumes.destination": {
"type": "fixed",
"value": "<required-script-1>"
},
"init_scripts.*.volumes.destination": {
"type": "forbidden"
}
}
Het gebruik helemaal weigeren
{
"init_scripts.*.volumes.destination": {
"type": "forbidden"
}
}
Vermeldingen toestaan die een specifieke beperking volgen
{
"init_scripts.*.volumes.destination": {
"type": "regex",
"pattern": ".*<required-content>.*"
}
}
Een specifieke set init-scripts herstellen
In het geval van init_scripts paden kan de matrix een van meerdere structuren bevatten waarvoor mogelijk alle mogelijke varianten moeten worden verwerkt, afhankelijk van de use-case. Als u bijvoorbeeld een specifieke set init-scripts wilt vereisen en een variant van de andere versie niet wilt gebruiken, kunt u het volgende patroon gebruiken:
{
"init_scripts.0.volumes.destination": {
"type": "fixed",
"value": "<volume-paths>"
},
"init_scripts.1.volumes.destination": {
"type": "fixed",
"value": "<volume-paths>"
},
"init_scripts.*.workspace.destination": {
"type": "forbidden"
},
"init_scripts.*.abfss.destination": {
"type": "forbidden"
},
"init_scripts.*.file.destination": {
"type": "forbidden"
}
}
Beleidsvoorbeelden
Deze sectie bevat beleidsvoorbeelden die u kunt gebruiken als verwijzingen voor het maken van uw eigen beleid. U kunt ook de door Azure Databricks geleverde beleidsfamilies gebruiken als sjablonen voor veelvoorkomende gebruiksscenario's voor beleid.
- algemeen rekenbeleid
- Limieten definiëren voor declaratieve pijplijnen van Lakeflow Spark
- eenvoudig middelgroot beleid
- taakonafhankelijk beleid
- Extern metastorebeleid
- Voorkomen dat rekenvermogen wordt gebruikt in taken
- Beleid voor automatisch schalen verwijderen
- Handhaving van aangepaste tags
Algemeen rekenbeleid
Een rekenbeleid voor algemeen gebruik dat is bedoeld om gebruikers te begeleiden en bepaalde functionaliteit te beperken, waarbij tags zijn vereist, het maximum aantal exemplaren wordt beperkt en time-outs worden afgedwongen.
{
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"spark_version": {
"type": "regex",
"pattern": "12\\.[0-9]+\\.x-scala.*"
},
"node_type_id": {
"type": "allowlist",
"values": ["Standard_L4s", "Standard_L8s", "Standard_L16s"],
"defaultValue": "Standard_L16s_v2"
},
"driver_node_type_id": {
"type": "fixed",
"value": "Standard_L16s_v2",
"hidden": true
},
"autoscale.min_workers": {
"type": "fixed",
"value": 1,
"hidden": true
},
"autoscale.max_workers": {
"type": "range",
"maxValue": 25,
"defaultValue": 5
},
"autotermination_minutes": {
"type": "fixed",
"value": 30,
"hidden": true
},
"custom_tags.team": {
"type": "fixed",
"value": "product"
}
}
Limieten definiëren op de rekencapaciteit van declaratieve pijplijnen van Lakeflow Spark
Notitie
Wanneer u beleid gebruikt voor het configureren van declaratieve pijplijnen voor Lakeflow Spark, raadt Databricks aan om één beleid toe te passen op zowel de default als maintenance de berekening.
Als u een beleid voor een pijplijnreken wilt configureren, maakt u een beleid met het veld cluster_type ingesteld op dlt. In het volgende voorbeeld wordt een minimaal beleid gemaakt voor het berekenen van declaratieve Pijplijnen in Lakeflow Spark:
{
"cluster_type": {
"type": "fixed",
"value": "dlt"
},
"num_workers": {
"type": "unlimited",
"defaultValue": 3,
"isOptional": true
},
"node_type_id": {
"type": "unlimited",
"isOptional": true
},
"spark_version": {
"type": "unlimited",
"hidden": true
}
}
Eenvoudige middelgrote verzekering
Hiermee kunnen gebruikers een middelgrote rekenkracht maken met minimale configuratie. Het enige vereiste veld tijdens het maken is de rekennaam; de rest is vast en verborgen.
{
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"spark_conf.spark.databricks.cluster.profile": {
"type": "forbidden",
"hidden": true
},
"autoscale.min_workers": {
"type": "fixed",
"value": 1,
"hidden": true
},
"autoscale.max_workers": {
"type": "fixed",
"value": 10,
"hidden": true
},
"autotermination_minutes": {
"type": "fixed",
"value": 60,
"hidden": true
},
"node_type_id": {
"type": "fixed",
"value": "Standard_L8s_v2",
"hidden": true
},
"driver_node_type_id": {
"type": "fixed",
"value": "Standard_L8s_v2",
"hidden": true
},
"spark_version": {
"type": "fixed",
"value": "auto:latest-ml",
"hidden": true
},
"custom_tags.team": {
"type": "fixed",
"value": "product"
}
}
Beleid uitsluitend voor banen
Hiermee kunnen gebruikers rekenprocessen maken om taken uit te voeren. Gebruikers kunnen met dit beleid geen algemene rekencapaciteit aanmaken.
{
"cluster_type": {
"type": "fixed",
"value": "job"
},
"dbus_per_hour": {
"type": "range",
"maxValue": 100
},
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"num_workers": {
"type": "range",
"minValue": 1
},
"node_type_id": {
"type": "regex",
"pattern": "Standard_[DLS]*[1-6]{1,2}_v[2,3]"
},
"driver_node_type_id": {
"type": "regex",
"pattern": "Standard_[DLS]*[1-6]{1,2}_v[2,3]"
},
"spark_version": {
"type": "unlimited",
"defaultValue": "auto:latest-lts"
},
"custom_tags.team": {
"type": "fixed",
"value": "product"
}
}
Het externe metastorebeleid
Hiermee kunnen gebruikers een compute-omgeving aanmaken met een door de beheerder gedefinieerde metastore die al is gekoppeld. Dit is handig om gebruikers in staat te stellen hun eigen rekenkracht te maken zonder dat er extra configuratie nodig is.
{
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionURL": {
"type": "fixed",
"value": "jdbc:sqlserver://<jdbc-url>"
},
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionDriverName": {
"type": "fixed",
"value": "com.microsoft.sqlserver.jdbc.SQLServerDriver"
},
"spark_conf.spark.databricks.delta.preview.enabled": {
"type": "fixed",
"value": "true"
},
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionUserName": {
"type": "fixed",
"value": "<metastore-user>"
},
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionPassword": {
"type": "fixed",
"value": "<metastore-password>"
}
}
Voorkomen dat rekenkracht wordt gebruikt voor taken
Dit beleid voorkomt dat gebruikers de berekening gebruiken om taken uit te voeren. Gebruikers kunnen de berekening alleen gebruiken met notebooks.
{
"workload_type.clients.notebooks": {
"type": "fixed",
"value": true
},
"workload_type.clients.jobs": {
"type": "fixed",
"value": false
}
}
Beleid voor automatisch schalen verwijderen
Met dit beleid wordt automatisch schalen uitgeschakeld en kan de gebruiker het aantal werkers binnen een bepaald bereik instellen.
{
"num_workers": {
"type": "range",
"maxValue": 25,
"minValue": 1,
"defaultValue": 5
}
}
Handhaving van aangepaste tags
Als u een regel voor rekentags wilt toevoegen aan een beleid, gebruikt u het kenmerk custom_tags.<tag-name>.
Elke gebruiker die dit beleid gebruikt, moet bijvoorbeeld een COST_CENTER tag invullen met 9999, 9921 of 9531 om het rekenproces te starten:
{ "custom_tags.COST_CENTER": { "type": "allowlist", "values": ["9999", "9921", "9531"] } }