Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel wordt uitgelegd hoe u een rekenresource maakt die is toegewezen aan een groep met behulp van de modus Toegewezen toegang.
Met de toegewezen groepstoegangsmodus kunnen gebruikers de operationele efficiëntie van een standaardtoegangsmoduscluster krijgen, terwijl ze ook veilig talen en workloads ondersteunen die niet worden ondersteund door de standaardtoegangsmodus, zoals Databricks Runtime voor ML, RDD-API's en R.
Eisen
De toegangsmodus voor toegewezen groepen gebruiken:
- De werkruimte moet zijn ingeschakeld voor Unity Catalog.
- U moet Databricks Runtime 15.4 of hoger gebruiken.
- De toegewezen groep moet
CAN MANAGEmachtigingen hebben voor een werkruimtemap waar ze notebooks, ML-experimenten en andere werkruimteartefacten kunnen bewaren die door het groepscluster worden gebruikt.
Wat is de toegewezen toegangsmodus?
De toegewezen toegangsmodus is de nieuwste versie van de modus voor toegang van één gebruiker. Met toegewezen toegang kan een rekenresource worden toegewezen aan één gebruiker of groep, zodat alleen de toegewezen gebruiker(s) toegang heeft tot het gebruik van de rekenresource.
Wanneer een gebruiker is verbonden met een rekenresource die is toegewezen aan een groep (een groepscluster), worden de machtigingen van de gebruiker automatisch beperkt tot de machtigingen van de groep, zodat de gebruiker de resource veilig kan delen met de andere leden van de groep.
Een rekenresource maken die is toegewezen aan een groep
- Ga in uw Azure Databricks-werkruimte naar Compute en klik op Compute maken.
- Vouw de sectie Geavanceerd uit.
- Klik onder De toegangsmodus op Handmatig en selecteer vervolgens Dedicated (voorheen: Eén gebruiker) in de vervolgkeuzelijst.
- Selecteer in het veld Eén gebruiker of groep de groep die u aan deze resource wilt toewijzen.
- Configureer de andere gewenste rekeninstellingen en klik vervolgens op Maken.
Aanbevolen procedures voor het beheren van groepsclusters
Omdat gebruikersmachtigingen zijn beperkt tot de groep bij het gebruik van groepsclusters, raadt Databricks aan om een /Workspace/Groups/<groupName> map te maken voor elke groep die u wilt gebruiken met een groepscluster. Wijs vervolgens CAN MANAGE machtigingen voor de map toe aan de groep. Hiermee kunnen groepen machtigingsfouten voorkomen. Alle notitieblokken en hulpmiddelen voor de werkruimte van de groep moeten worden beheerd in de groepsmap.
Je moet ook de volgende werkbelastingen wijzigen zodat ze op groepsclusters kunnen draaien.
- MLflow: Zorg ervoor dat u het notebook uitvoert vanuit de groepsmap of
mlflow.set_tracking_uri("/Workspace/Groups/<groupName>")gebruikt. - AutoML: stel de optionele parameter
experiment_dirin op“/Workspace/Groups/<groupName>”voor uw AutoML-uitvoeringen. -
dbutils.notebook.run: Zorg ervoor dat de groepREADmachtiging heeft op het notitieblok dat wordt uitgevoerd.
Machtigingsgedrag voor groepsclusters
Alle opdrachten, query's en andere acties die op een groepscluster worden uitgevoerd, gebruiken de machtigingen die aan de groep zijn toegewezen, niet de afzonderlijke gebruiker.
Afzonderlijke gebruikersmachtigingen kunnen niet worden afgedwongen omdat alle groepsleden volledige toegang hebben tot de Spark-API's en een gedeelde rekenomgeving. Als gebruikersmachtigingen zijn toegepast, kan één lid beperkte gegevens opvragen en een ander lid zonder toegang de resultaten nog steeds ophalen via de gedeelde omgeving. Daarom moet de groep zelf, niet de gebruiker die lid is van de groep, over de benodigde machtigingen beschikken om de actie uit te voeren.
De groep heeft bijvoorbeeld expliciete machtigingen nodig om een query uit te voeren op een tabel, toegang te krijgen tot een geheim bereik of geheim, een verbindingsreferentie voor Unity Catalog te gebruiken, toegang te krijgen tot een Git-map of een werkruimteobject te maken.
Voorbeeld van groepsmachtigingen
Wanneer u een gegevensobject maakt met behulp van het groepscluster, wordt de groep toegewezen als de eigenaar van het object.
Als u bijvoorbeeld een notebook hebt gekoppeld aan een groepscluster en de volgende opdracht uitvoert:
use catalog main;
create schema group_cluster_group_schema;
Voer vervolgens deze query uit om de eigenaar van het schema te controleren:
describe schema group_cluster_group_schema;
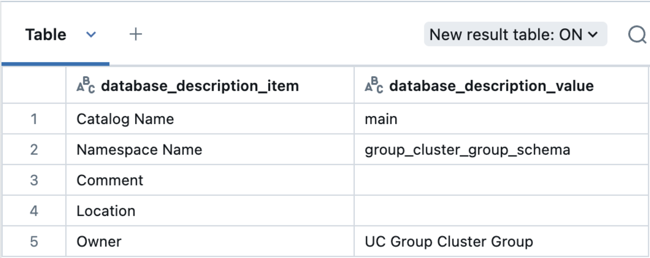
Toegewijde computing activiteit voor auditinggroep
Er zijn twee belangrijke identiteiten betrokken wanneer een groepscluster een workload uitvoert:
- De gebruiker die de workload uitvoert op het groepscluster
- De groep waarvan de machtigingen worden gebruikt om de werkelijke taken uit te voeren
De systeemtabel auditlog registreert deze identiteiten onder de volgende parameters:
-
identity_metadata.run_by: de verificatiegebruiker die de actie uitvoert -
identity_metadata.run_as: de machtigingsgroep waarvan de machtigingen worden gebruikt voor de actie.
Met de volgende voorbeeldquery worden de identiteitsmetagegevens opgehaald voor een actie die met het groepscluster wordt uitgevoerd:
select action_name, event_time, user_identity.email, identity_metadata
from system.access.audit
where user_identity.email = "uc-group-cluster-group" AND service_name = "unityCatalog"
order by event_time desc limit 100;
Bekijk de tabelreferentie van het auditlogboek voor meer voorbeeldquery's. Zie referentie van de auditlogsysteemtabel.
Bekende problemen
Werkruimtebestanden en -mappen die zijn gemaakt op basis van groepsclusters leiden ertoe dat de toegewezen objecteigenaar wordt Unknown. Volgende bewerkingen op deze objecten, zoals read, write en delete, mislukken door permissieweigeringen.
Bekende beperkingen
Toegang tot toegewezen groepen heeft de volgende beperkingen:
- Taken die zijn gemaakt met behulp van de API en SDK, kunnen geen groepstoegang worden toegewezen. Dit komt doordat de parameter van de taak
run_asslechts één gebruiker of service-principal ondersteunt. - Taken die gebruikmaken van Git mislukken omdat de tijdelijke map die door de taak wordt gebruikt om de Git-opslagplaats te uitchecken, niet kan worden geschreven. Gebruik in plaats daarvan Git-mappen .
- Systeemtabellen voor herkomst registreren de
identity_metadata.run_as(autorisatiegroep) ofidentity_metadata.run_by(de verificatiegebruiker) niet voor workloads die worden uitgevoerd op een groepscluster. - Auditlogboeken die naar de opslag van klanten worden geleverd, registreren niet de
identity_metadata.run_as(de autorisatiegroep) ofidentity_metadata.run_by(de authenticerende gebruiker) voor workloads die in een groepscluster draaien. U moet desystem.access.audittabel gebruiken om de metagegevens van de identiteit weer te geven. - Wanneer deze is gekoppeld aan een groepscluster, filtert Catalog Explorer niet op assets die alleen toegankelijk zijn voor de groep.
- Groepsbeheerders die geen groepsleden zijn, kunnen geen groepsclusters maken, bewerken of verwijderen. Alleen werkruimtebeheerders en groepsleden kunnen dit doen.
- Als de naam van een groep is gewijzigd, moet u elk rekenbeleid dat verwijst naar de groepsnaam handmatig bijwerken.
- Groepsclusters worden niet ondersteund voor werkruimten waarvoor ACL's zijn uitgeschakeld (isWorkspaceAclsEnabled == false) vanwege het inherent gebrek aan beveiliging en besturingselementen voor gegevenstoegang wanneer werkruimte-ACL's zijn uitgeschakeld.
- De
%runopdracht en andere acties die worden uitgevoerd in de notebookcontext, gebruiken altijd de machtigingen van de gebruiker in plaats van de machtigingen van de groep. Dit komt doordat deze acties worden verwerkt door de notebookomgeving, niet door de omgeving van het cluster. Alternatieve opdrachten, zoalsdbutils.notebook.run()worden uitgevoerd op het cluster en gebruiken daarom de machtigingen van de groep. - De
is_member(<group>)functie wordt geretourneerdfalsewanneer deze wordt aangeroepen op een groepscluster omdat de groep geen lid van zichzelf is. Als u het lidmaatschap van zowel groepsclusters als andere toegangsmodi correct wilt controleren, gebruikt uis_member(<group>) OR current_user() == <group>. - Rekenlogboeken kunnen niet worden toegevoegd aan volumes.
- Het maken en toegang krijgen tot model-serveer-eindpunten wordt niet ondersteund.
- Het maken en openen van vectorzoekeindpunten of -indexen wordt niet ondersteund.
- Het verwijderen van bestanden en mappen wordt niet ondersteund in groepsclusters.