Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Met fijnmazig toegangsbeheer kunt u de toegang tot specifieke gegevens beperken met behulp van weergaven, rijfilters en kolommaskers. Op deze pagina wordt uitgelegd hoe serverloze berekeningen worden gebruikt voor het afdwingen van verfijnde toegangsbeheer voor toegewezen rekenresources.
Opmerking
Toegewezen rekenkracht is algemene of taken rekenkracht die zijn geconfigureerd met Toegewezen toegangsmodus (voorheen de modus voor toegang van één gebruiker). Zie Toegangsmodi.
Behoeften
Toegewezen rekenkracht gebruiken om een query uit te voeren op een weergave of tabel met verfijnde besturingselementen voor toegang:
- De toegewezen rekenresource moet zich in Databricks Runtime 15.4 LTS of hoger hebben.
- De werkruimte moet zijn ingeschakeld voor serverloze berekeningen.
Als uw toegewezen rekenresource en werkruimte aan deze vereisten voldoen, wordt gegevensfiltering automatisch uitgevoerd.
Hoe gegevensfilters werken op toegewezen rekenkracht
Wanneer een query toegang heeft tot een databaseobject met fijnmazige toegangsbeheer, geeft de toegewezen rekenresource de query door aan de serverloze berekening van uw werkruimte om de gegevensfiltering uit te voeren. De gefilterde gegevens worden vervolgens overgebracht tussen de serverloze en toegewezen rekenkracht met behulp van tijdelijke bestanden in interne cloudopslag in werkruimten.
Azure Databricks draagt de gefilterde gegevens over met behulp van Cloud Fetch, een mogelijkheid waarmee tijdelijke resultatensets worden geschreven naar interne werkruimteopslag ( de DBFS-hoofdmap van uw werkruimte). Azure Databricks voert automatisch garbage collection uit op deze bestanden: het markeert ze voor verwijdering na 24 uur en verwijdert ze definitief na nog eens 24 uur.
Deze functionaliteit is van toepassing op de volgende databaseobjecten:
- dynamische weergaven
- Tabellen met rijfilters of kolommaskers
-
Weergaven die zijn gebouwd op tabellen waarvoor de gebruiker niet de
SELECTbevoegdheid heeft - gematerialiseerde weergaven
- Streamingtabellen
In het volgende diagram heeft een gebruiker de SELECT bevoegdheid voor table_1, view_2 en table_w_rls, waarop rijfilters zijn toegepast. De gebruiker heeft niet de SELECT bevoegdheid voor table_2, waarnaar wordt verwezen door view_2.
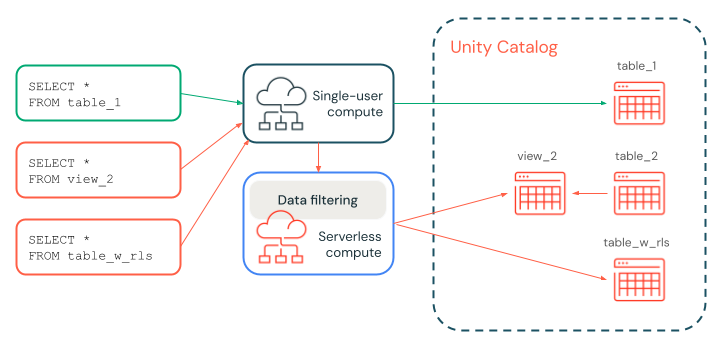
De query op table_1 wordt volledig verwerkt door de toegewezen rekenresource, omdat er geen filters vereist zijn. De query's op view_2 en table_w_rls vereisen gegevensfiltering om de gegevens te retourneren waartoe de gebruiker toegang heeft. Deze vragen worden afgehandeld door de gegevensfiltermogelijkheden van serverloze computing.
Ondersteuning voor schrijfbewerkingen
In Databricks Runtime 16.3 en hoger kunt u schrijven naar tabellen waarop rijfilters of kolommaskers zijn toegepast, met behulp van deze opties:
- De MERGE INTO SQL-opdracht, die u kunt gebruiken om
INSERT,UPDATEenDELETEfunctionaliteit te bereiken. - De deltasamenvoegbewerking.
- De
DataFrame.write.mode("append")API.
Om INSERT, UPDATE en DELETE functionaliteit te bereiken, kunt u een staging tabel en de MERGE INTO en WHEN MATCHED clausules van de WHEN NOT MATCHED instructie gebruiken.
Hier volgt een voorbeeld van een UPDATE met behulp van MERGE INTO.
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET
t.column1 = s.column1,
t.column2 = s.column2;
Hier volgt een voorbeeld van een INSERT met behulp van MERGE INTO.
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN NOT MATCHED THEN
INSERT (id, column1, column2) VALUES (s.id, s.column1, s.column2);
Hier volgt een voorbeeld van een DELETE met behulp van MERGE INTO.
MERGE INTO target_table AS t
USING source_table AS s ON t.id = s.id
WHEN MATCHED AND s.some_column = TRUE THEN DELETE;
Ondersteuning voor DDL-, SHOW-, DESCRIBE- en andere opdrachten
In Databricks Runtime 17.1 en hoger kunt u de volgende opdrachten gebruiken in combinatie met verfijnde, door toegang beheerde objecten op toegewezen rekenkracht:
- DDL-instructies
- SHOW-instructies
- DESCRIBE-statements
- OPTIMIZE
- DESCRIBE HISTORY
- FSCK REPAIR TABLE (Databricks Runtime 17.2 en hoger)
Indien nodig worden deze opdrachten automatisch uitgevoerd op serverloze berekeningen.
Sommige opdrachten worden niet ondersteund, waaronder VACCUM, RESTOREen REORG TABLE.
Serverloze rekenkosten
Klanten worden in rekening gebracht voor de serverloze rekenresources die gegevensfilterbewerkingen uitvoeren. Zie Platformlagen en invoegtoepassingen voor prijsinformatie.
Gebruikers met toegang kunnen een query uitvoeren op de system.billing.usage tabel om te zien hoeveel er in rekening is gebracht. Met de volgende query worden bijvoorbeeld de rekenkosten per gebruiker opgesplitst:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Queryprestaties weergeven wanneer gegevensfiltering is ingeschakeld
In de Spark-gebruikersinterface voor toegewezen rekenkracht worden metrische gegevens weergegeven die u kunt gebruiken om inzicht te hebben in de prestaties van uw query's. Voor elke query die u uitvoert op de rekenresource, wordt op het tabblad SQL/Dataframe de weergave van de querygrafiek weergegeven. Als een query betrokken was bij het filteren van gegevens, geeft de gebruikersinterface een RemoteSparkConnectScan-operatorknooppunt onder aan de grafiek weer. In dat knooppunt worden metrische gegevens weergegeven die u kunt gebruiken om queryprestaties te onderzoeken. Zie Rekengegevens weergeven in de Spark-gebruikersinterface.
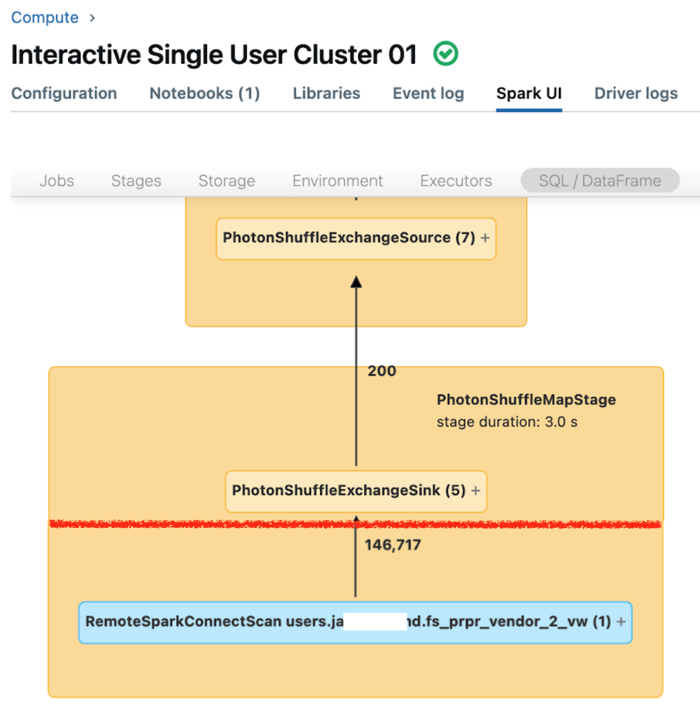
Vouw het operatorknooppunt RemoteSparkConnectScan uit om metrische gegevens weer te geven die betrekking hebben op vragen als de volgende:
- Hoeveel tijd kost het filteren van gegevens? Bekijk “totale externe uitvoeringstijd.”
- Hoeveel rijen bleef er na het filteren van gegevens? Bekijk 'rijenuitvoer'.
- Hoeveel gegevens (in bytes) zijn geretourneerd na het filteren van gegevens? De uitvoergrootte van rijen weergeven.
- Hoeveel gegevensbestanden zijn door partitionering verkleind en hoefden niet uit de opslag te worden gelezen? Bekijk 'Bestanden opgeschoond' en 'Grootte van bestanden opgeschoond'.
- Hoeveel gegevensbestanden kunnen niet worden verwijderd en moeten worden gelezen uit de opslag? Bekijk 'Bestanden gelezen' en 'Grootte van bestanden gelezen'.
- Van de bestanden die moeten worden gelezen, hoeveel waren er al in de cache? Bekijk 'Cachetreffergrootte' en 'Cachemissersgrootte'.
Beperkingen
Alleen batchlezen wordt ondersteund voor streaming-tabellen. Tabellen met rijfilters of kolommaskers bieden geen ondersteuning voor streamingworkloads op toegewezen rekenkracht.
De standaardcatalogus (
spark.sql.catalog.spark_catalog) kan niet worden gewijzigd.spark.catalog.listColumns()wordt niet ondersteund. In plaats daarvan kunt u kolomnamenSHOW COLUMNS INvermelden,SHOW PARTITIONSpartitiekolommen vermelden ofDESCRIBE TABLE [EXTENDED [AS JSON]]een gedetailleerde tabelbeschrijving ophalen.In Databricks Runtime 16.2 en lager is er geen ondersteuning voor het schrijven of vernieuwen van tabelbewerkingen voor tabellen waarop rijfilters of kolommaskers zijn toegepast.
DML-bewerkingen, zoals
INSERT,DELETE,UPDATE, enREFRESH TABLE,MERGEworden niet ondersteund. U kunt alleen (SELECT) lezen uit deze tabellen.In Databricks Runtime 16.3 en hoger worden schrijftabelbewerkingen zoals
INSERT,DELETEenUPDATEniet ondersteund, maar kunnen worden uitgevoerd met behulp vanMERGE, die ondersteund wordt.Wanneer u
DeltaTable.forName()ofDeltaTable.forPath()op dedicated compute met FGAC-ingeschakelde tabellen gebruikt, worden alleen demerge()entoDF()bewerkingen ondersteund. Voor andere DeltaTable-bewerkingen gebruikt u in plaats daarvan de bijbehorende SQL-opdrachten. Gebruik bijvoorbeeld in plaats vanhistory(), gebruikDESCRIBE HISTORYen in plaats vanclone(), gebruikSHALLOW CLONEofDEEP CLONE.In Databricks Runtime 16.2 en lager worden self-joins standaard geblokkeerd wanneer gegevensfiltering wordt aangeroepen omdat deze query's verschillende momentopnamen van dezelfde externe tabel kunnen retourneren. U kunt deze query's echter inschakelen door
spark.databricks.remoteFiltering.blockSelfJoinsin te stellen opfalseop rekenkracht waarop u deze opdrachten uitvoert.In Databricks Runtime 16.3 en hoger worden momentopnamen automatisch gesynchroniseerd tussen toegewezen en serverloze rekenresources. Vanwege deze synchronisatie retourneren self-joinquery's die gebruikmaken van de functionaliteit voor gegevensfiltering identieke momentopnamen en zijn deze standaard ingeschakeld. De uitzonderingen zijn gematerialiseerde weergaven en alle weergaven, gematerialiseerde weergaven en streamingtabellen die worden gedeeld via Delta Sharing. Voor deze objecten worden self-joins standaard geblokkeerd, maar u kunt deze query's inschakelen door
spark.databricks.remoteFiltering.blockSelfJoinsin te stellen op onwaar bij berekening waarvoor u deze opdrachten uitvoert.Als u self-joinqueries inschakelt voor eventuele weergaven, gerealiseerde weergaven en streamingtabellen, moet u ervoor zorgen dat er geen gelijktijdige schrijfbewerkingen plaatsvinden voor de objecten die worden samengevoegd.
- Geen ondersteuning in Docker-images.
- Geen ondersteuning bij het gebruik van Databricks Container Services.
- U moet poorten 8443 en 8444 openen om gedetailleerd toegangsbeheer in te schakelen voor toegewezen rekenkracht. Zie Azure Databricks implementeren in uw virtuele Azure-netwerk (VNet-injectie).