Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel wordt beschreven hoe u een verbinding van Azure Databricks configureert voor het lezen en schrijven van tables en gegevens die zijn opgeslagen in Google Cloud Storage (GCS).
Als u wilt lezen of schrijven vanuit een GCS-bucket, moet u een gekoppeld serviceaccount maken en moet u de bucket koppelen aan het serviceaccount. U maakt rechtstreeks verbinding met de bucket met een sleutel die u generate voor het serviceaccount.
Rechtstreeks toegang krijgen tot een GCS-bucket met een Google Cloud-serviceaccountsleutel
Als u rechtstreeks naar een bucket wilt lezen en schrijven, configureert u een sleutel die is gedefinieerd in uw Spark-configuratie.
Stap 1: Stel het Google Cloud-serviceaccount in Set met behulp van de Google Cloud Console
U moet een serviceaccount maken voor het Azure Databricks-cluster. Databricks raadt aan dit serviceaccount de minste bevoegdheden te geven die nodig zijn om de taken uit te voeren.
Klik op IAM en Beheerder in het linkernavigatiedeelvenster.
Klik op Serviceaccounts.
Klik op + SERVICEACCOUNT MAKEN.
Voer de naam en beschrijving van het serviceaccount in.
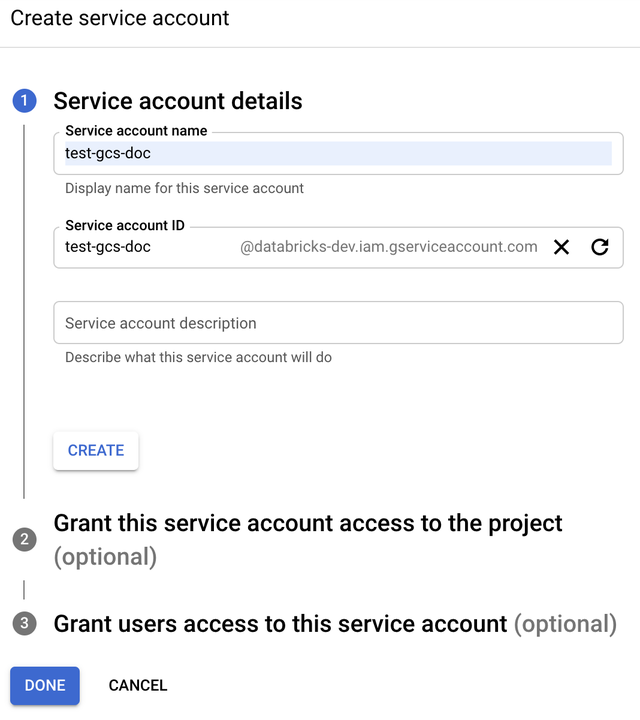
Klik op MAKEN.
Klik op CONTINUE.
Klik op GEREED.
Stap 2: Een sleutel maken om rechtstreeks toegang te krijgen tot GCS-bucket
Waarschuwing
De JSON-sleutel die u generate voor het serviceaccount is een persoonlijke sleutel die alleen mag worden gedeeld met geautoriseerde gebruikers, omdat deze de toegang tot gegevenssets en resources in uw Google Cloud-account beheert.
- Klik in de Google Cloud-console in de serviceaccounts listop het zojuist gemaakte account.
- Klik in de sectie Sleutels op ADD KEY > Create new key.
- Accepteer het JSON-sleuteltype .
- Klik op MAKEN. Het sleutelbestand wordt gedownload naar uw computer.
Stap 3: de GCS-bucket configureren
Een bucket maken
Als u nog geen bucket hebt, maakt u er een:
Klik in het linkernavigatiedeelvenster op Opslag .
Klik op BUCKET MAKEN.
Klik op MAKEN.
De bucket configureren
Configureer de bucketdetails.
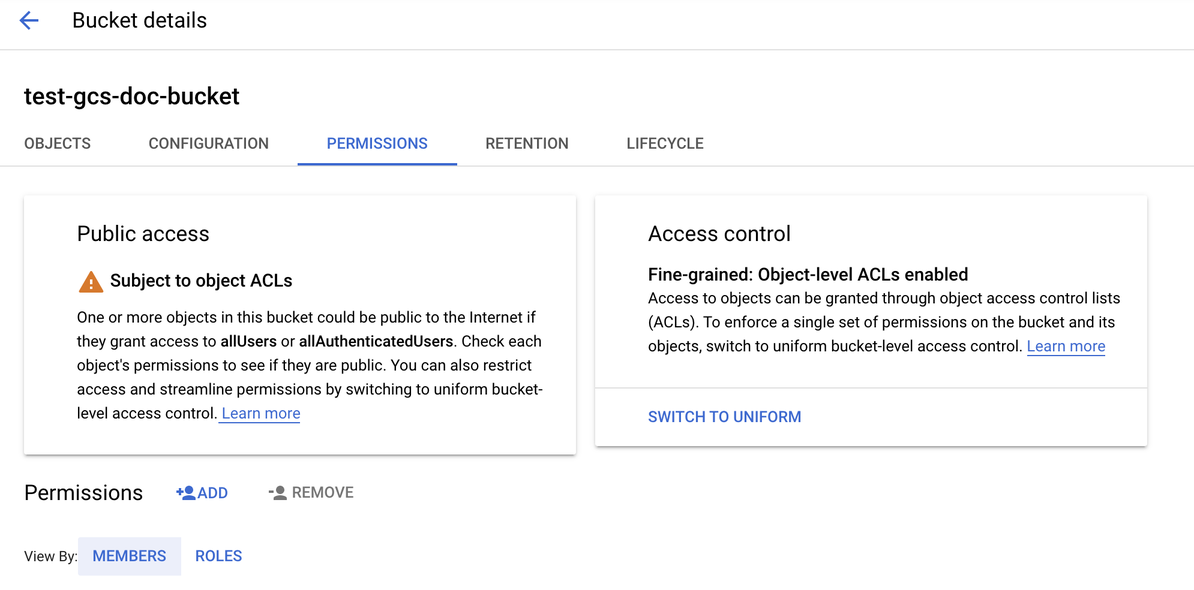
Klik op het tabblad Machtigingen .
Klik naast het label Machtigingen op TOEVOEGEN.
Geef de machtiging Opslagbeheerder op voor het serviceaccount in de bucket van de cloudopslagrollen.
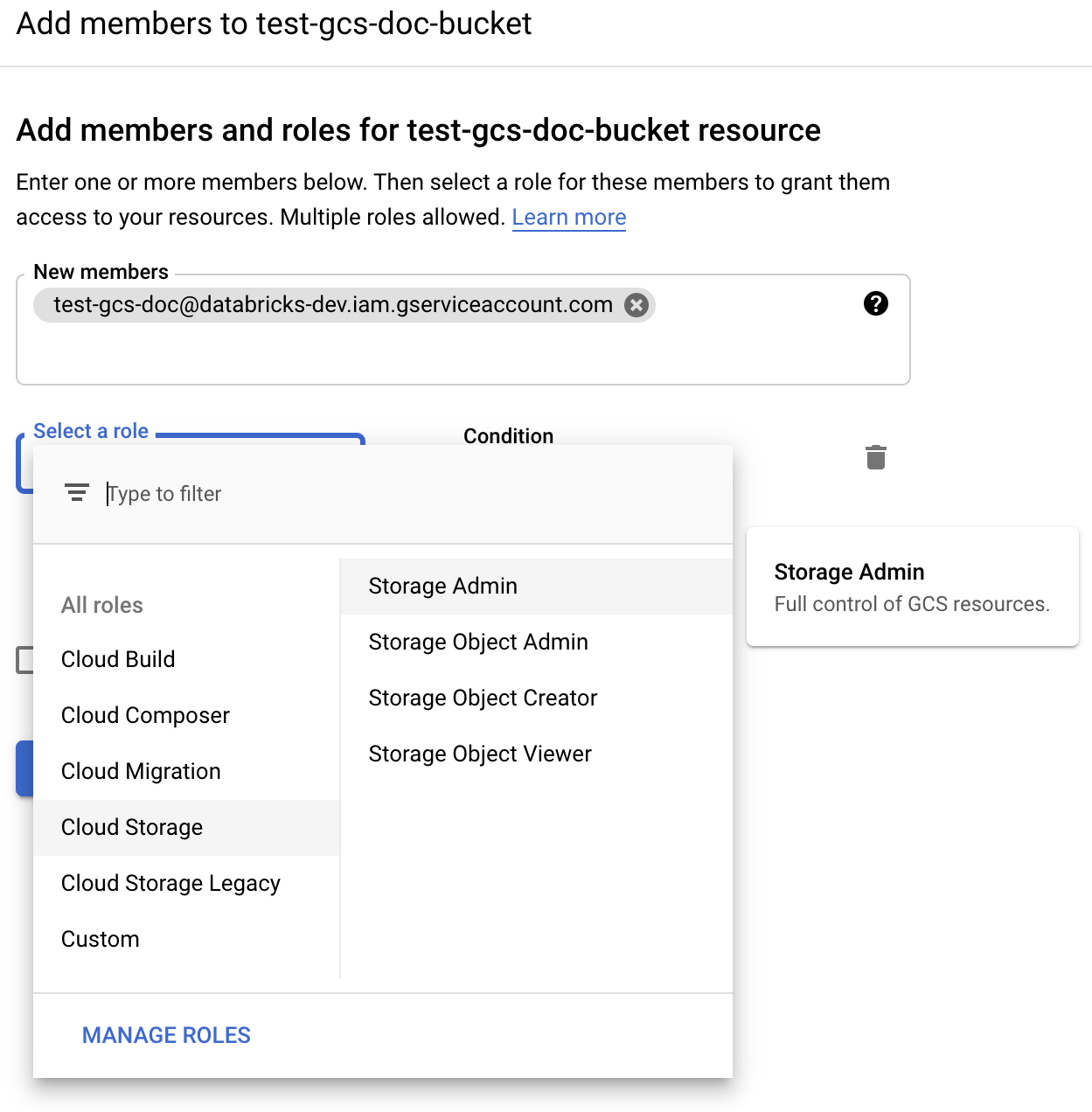
Klik op OPSLAAN.
Stap 4: De sleutel van het serviceaccount in Databricks-geheimen plaatsen
Databricks raadt aan geheime omgevingen te gebruiken voor het opslaan van alle credentials. U kunt de persoonlijke sleutel en de persoonlijke sleutel-id uit uw JSON-sleutelbestand in Databricks-geheime bereiken plaatsen. U kunt grant toegang geven aan gebruikers, service-principals en groepen in uw werkruimte om de geheime reikwijdten te lezen. Hierdoor wordt de sleutel van het serviceaccount beschermd, terwijl gebruikers toegang hebben tot GCS. Zie Geheimen beheren als u een geheim bereik wilt maken.
Stap 5: Een Azure Databricks-cluster configureren
Configureer op het tabblad Spark-configuratie een globale configuratie of een configuratie per bucket. De volgende voorbeelden set de sleutels met behulp van values opgeslagen als Databricks-geheimen.
Notitie
Gebruik clustertoegangsbeheer en notebooktoegangsbeheer samen om de toegang tot het serviceaccount en de gegevens in de GCS-bucket te beveiligen. Zie Compute-machtigingen en samenwerken met behulp van Databricks-notebooks.
Globale configuratie
Gebruik deze configuratie als de opgegeven credentials moet worden gebruikt voor toegang tot alle buckets.
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
Vervang <client-email>, <project-id> door de values van die exacte veldnamen uit het JSON-sleutelbestand.
Configuratie per bucket
Gebruik deze configuratie als u credentials moet configureren voor specifieke buckets. De syntaxis voor configuratie per bucket voegt de naam van de bucket toe aan het einde van elke configuratie, zoals in het volgende voorbeeld.
Belangrijk
Configuraties per bucket kunnen naast globale configuraties worden gebruikt. Wanneer dit is opgegeven, worden globale configuraties per bucket vervangen.
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
Vervang <client-email>, <project-id> door de values van die exacte veldnamen uit het JSON-sleutelbestand.
Stap 6: lezen uit GCS
Als u wilt lezen uit de GCS-bucket, gebruikt u een Spark-leesopdracht in elke ondersteunde indeling, bijvoorbeeld:
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
Als u naar de GCS-bucket wilt schrijven, gebruikt u een Spark-schrijfopdracht in elke ondersteunde indeling, bijvoorbeeld:
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
Vervang door <bucket-name> de naam van de bucket die u in stap 3 hebt gemaakt: de GCS-bucket configureren.