Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Belangrijk
Deze functie bevindt zich in de bètaversie.
In dit artikel wordt beschreven hoe u een generatieve AI-agent maakt voor gegevensextractie met behulp van Agent Bricks: Informatieextractie.
Agent Bricks biedt een eenvoudige, no-code-benadering voor het bouwen en optimaliseren van domeinspecifieke, hoogwaardige AI-agentsystemen voor veelvoorkomende AI-use cases.
Wat is Agent Bricks: Informatieextractie?
Agent Bricks ondersteunt gegevensextractie en vereenvoudigt het proces van het transformeren van een groot aantal niet-gelabelde tekstdocumenten in een gestructureerde tabel met geëxtraheerde informatie voor elk document.
Voorbeelden van gegevensextractie zijn:
- Prijzen en lease-informatie ophalen uit contracten.
- Gegevens van klantnotities ordenen.
- Belangrijke informatie ophalen uit nieuwsartikelen.
Agent Bricks: Informatieextractie maakt gebruik van geautomatiseerde evaluatiemogelijkheden, waaronder MLflow en Agent Evaluation, om een snelle beoordeling van de kostenkwaliteit mogelijk te maken voor uw specifieke extractietaak. Met deze evaluatie kunt u weloverwogen beslissingen nemen over het evenwicht tussen nauwkeurigheid en investeringen in resources.
Behoeften
- Een werkruimte met het volgende:
- Mozaïek AI Agent Bricks Preview (bèta) ingeschakeld. Zie Azure Databricks Previews beheren.
- Serverloze rekenkracht ingeschakeld. Zie Serverloze berekening inschakelen.
- Unity Catalog ingeschakeld. Zie Een werkruimte inschakelen voor Unity Catalog.
- Een werkruimte in een van de ondersteunde regio's:
eastus,eastus2,westus,centralus, ofnorthcentralus. - Toegang tot basismodellen in Unity Catalog via het
system.aischema. - Toegang tot een serverloos budgetbeleid met een niet-nulbudget.
- Mogelijkheid om de
ai_querySQL-functie te gebruiken. - Bestanden waaruit u gegevens wilt extraheren. De bestanden moeten zich in een Unity Catalog-volume of -tabel bevinden.
- Als u PDF-bestanden wilt gebruiken, converteert u ze eerst naar een Unity Catalog-tabel. Zie PDF's gebruiken in Agent Bricks.
- Als u uw agent wilt bouwen, hebt u ten minste 1 niet-gelabeld document in uw Unity Catalog-volume of 1 rij in uw tabel nodig.
- Als u uw agent wilt optimaliseren ((optioneel) stap 4: Een geoptimaliseerde agent controleren en implementeren), moet u ten minste 75 niet-gelabelde documenten in uw Unity Catalog-volume of ten minste 75 rijen in uw tabel hebben.
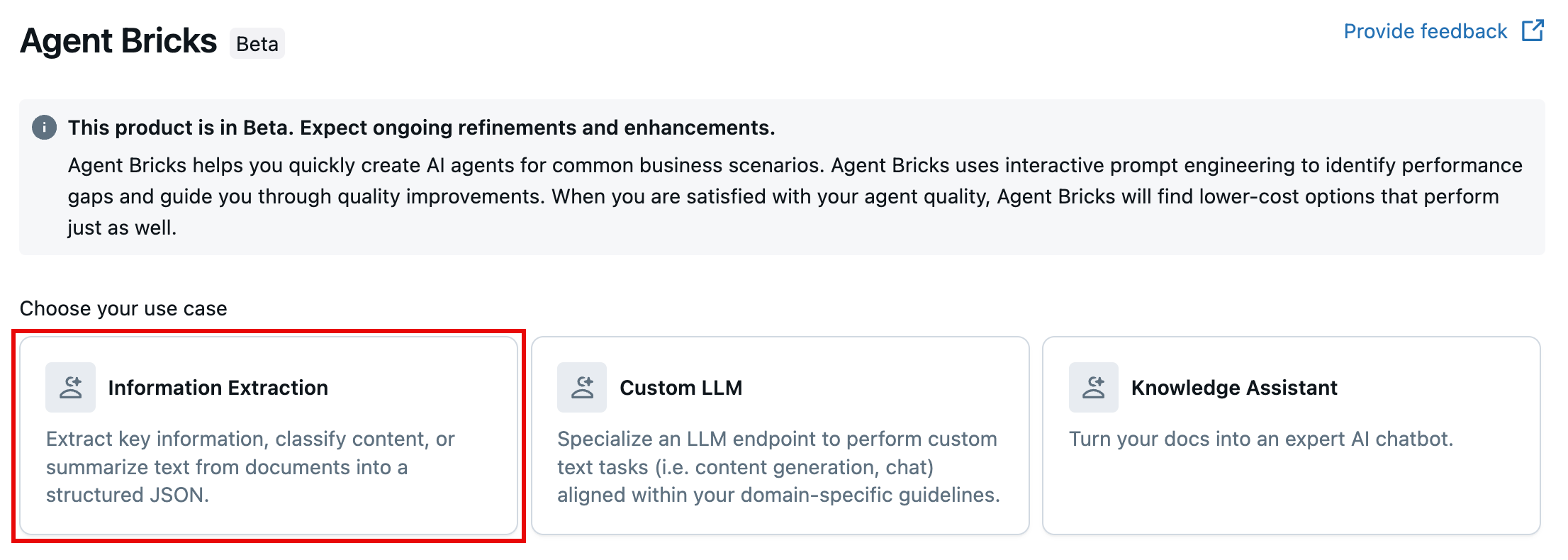
Een agent voor gegevensextractie maken
Ga naar ![]() Agents in het linkernavigatiedeelvenster van uw werkruimte en klik op Gegevensextractie.
Agents in het linkernavigatiedeelvenster van uw werkruimte en klik op Gegevensextractie.
Stap 1: Invoergegevens en uitvoervoorbeeld toevoegen
Klik op het tabblad Configureren op Een voorbeeld >weergeven om een voorbeeldinvoer- en modelreactie uit te vouwen voor een agent voor gegevensextractie.
Configureer uw agent in het onderstaande deelvenster:
Selecteer in het veld Brondocumenten de map of tabel die u wilt gebruiken vanuit uw Unity Catalog-volume. Als u een tabel hebt geselecteerd, selecteert u de kolom met uw tekstgegevens in de vervolgkeuzelijst.
De map moet documenten bevatten in een ondersteunde documentindeling en de tabelkolom moet gegevens bevatten in een ondersteunde gegevensindeling. Deze gegevensset wordt gebruikt om uw agent te maken.
Als u PDF-bestanden wilt gebruiken, converteert u ze eerst naar een Unity Catalog-tabel. Zie PDF's gebruiken in Agent Bricks.
Hier volgt een voorbeeldvolume:
/Volumes/main/info-extraction/bbc_articles/Geef in het veld Voorbeelduitvoer een voorbeeldantwoord op:
{ "title": "Economy Slides to Recession", "category": "Politics", "paragraphs": [ { "summary": "GDP fell by 0.1% in the last three months of 2004.", "word_count": 38 }, { "summary": "Consumer spending had been depressed by one-off factors such as the unseasonably mild winter.", "word_count": 42 } ], "tags": ["Recession", "Economy", "Consumer Spending"], "estimate_time_to_read_min": 1, "published_date": "2005-01-15", "needs_review": false }Geef een naam op voor uw agent. U kunt de standaardnaam laten staan als u deze niet wilt wijzigen.
Selecteer Agent maken.
Ondersteunde documentindelingen
In de volgende tabel ziet u de ondersteunde documentbestandstypen voor uw brondocumenten als u een Unity Catalog-volume opgeeft.
| Codebestanden | Documentbestanden | Logboekbestanden |
|---|---|---|
|
|
|
Ondersteunde gegevensindelingen
Agent Bricks: Informatieextractie ondersteunt de volgende gegevenstypen en schema's voor uw brondocumenten als u een Unity Catalog-tabel opgeeft. Agent Bricks kan deze gegevenstypen ook uit elk document extraheren.
strintfloatboolean- Aangepaste geneste velden
- Matrices van de bovenstaande gegevenstypen
Stap 2: uw agent bouwen en verbeteren
Verfijn uw schemadefinitie op het tabblad Opbouwen in het deelvenster Agentconfiguratie voor betere resultaten.
(Optioneel) Voeg globale instructies toe voor uw agent, zoals een prompt die kan worden toegepast op alle velden.
Pas de beschrijvingen aan van de schemavelden die uw agent moet gebruiken voor uitvoerantwoorden. Deze beschrijvingen zijn wat de agent nodig heeft om te begrijpen wat u wilt extraheren.

Klik op Agent bijwerken.
Bekijk aanbevelingen en voorbeelduitvoer aan de linkerkant van het tabblad Build .
Bekijk voorbeelden van modeluitvoer op basis van de specificaties die voor elk veld zijn opgegeven.
Bekijk de aanbevelingen van Databricks voor het optimaliseren van agentprestaties.
Pas desgewenst aanbevelingen toe en pas uw beschrijvingen en instructies aan in het deelvenster Agentconfiguratie .
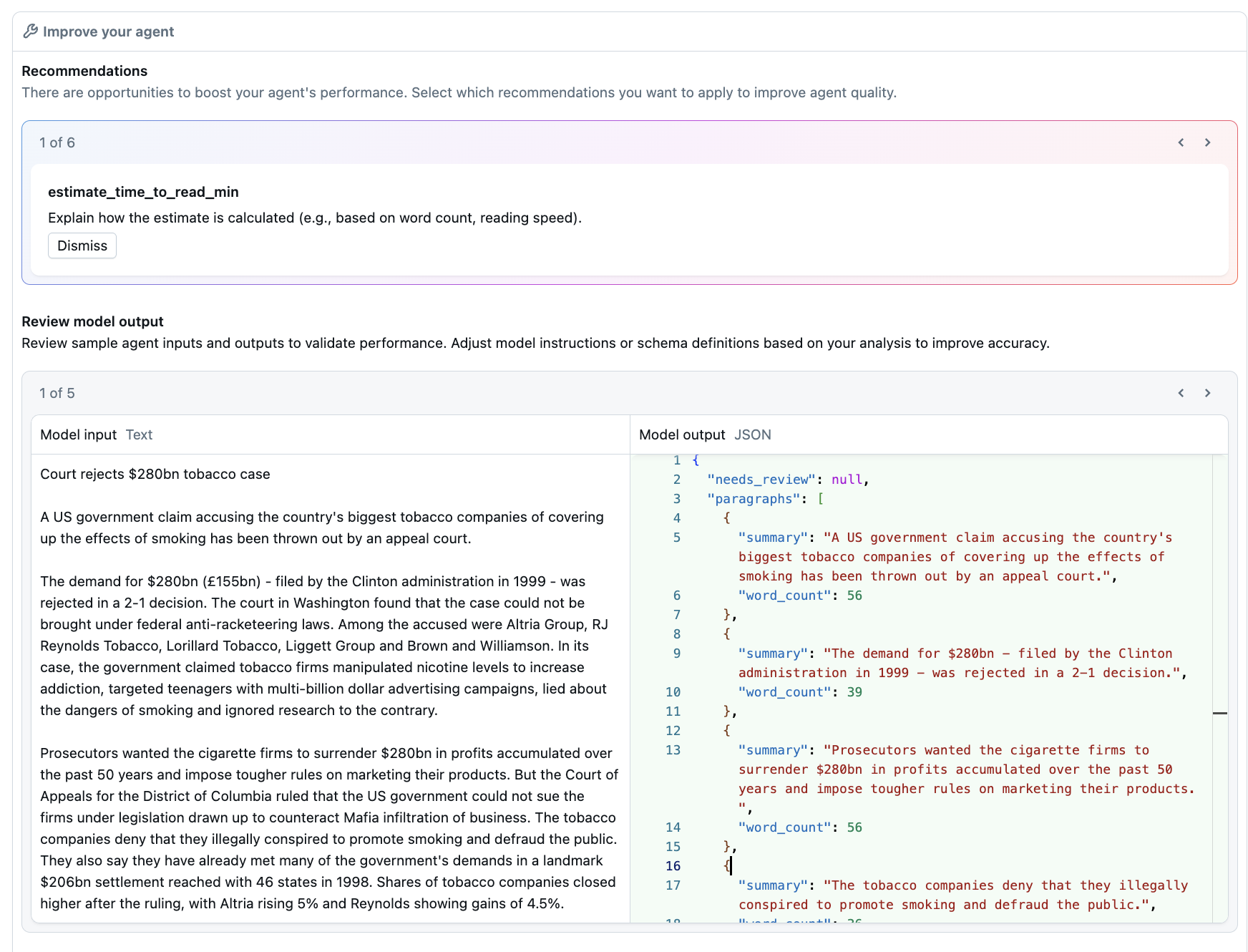
Nadat u wijzigingen en aanbevelingen hebt toegepast, selecteert u Update-agent om deze wijzigingen op te slaan in uw agent. Het deelvenster Uw agent verbeteren wordt bijgewerkt om de uitvoer van een nieuw voorbeeldmodel weer te geven. De aanbevelingen in dit deelvenster worden niet bijgewerkt.
U hebt nu een agent voor gegevensextractie.
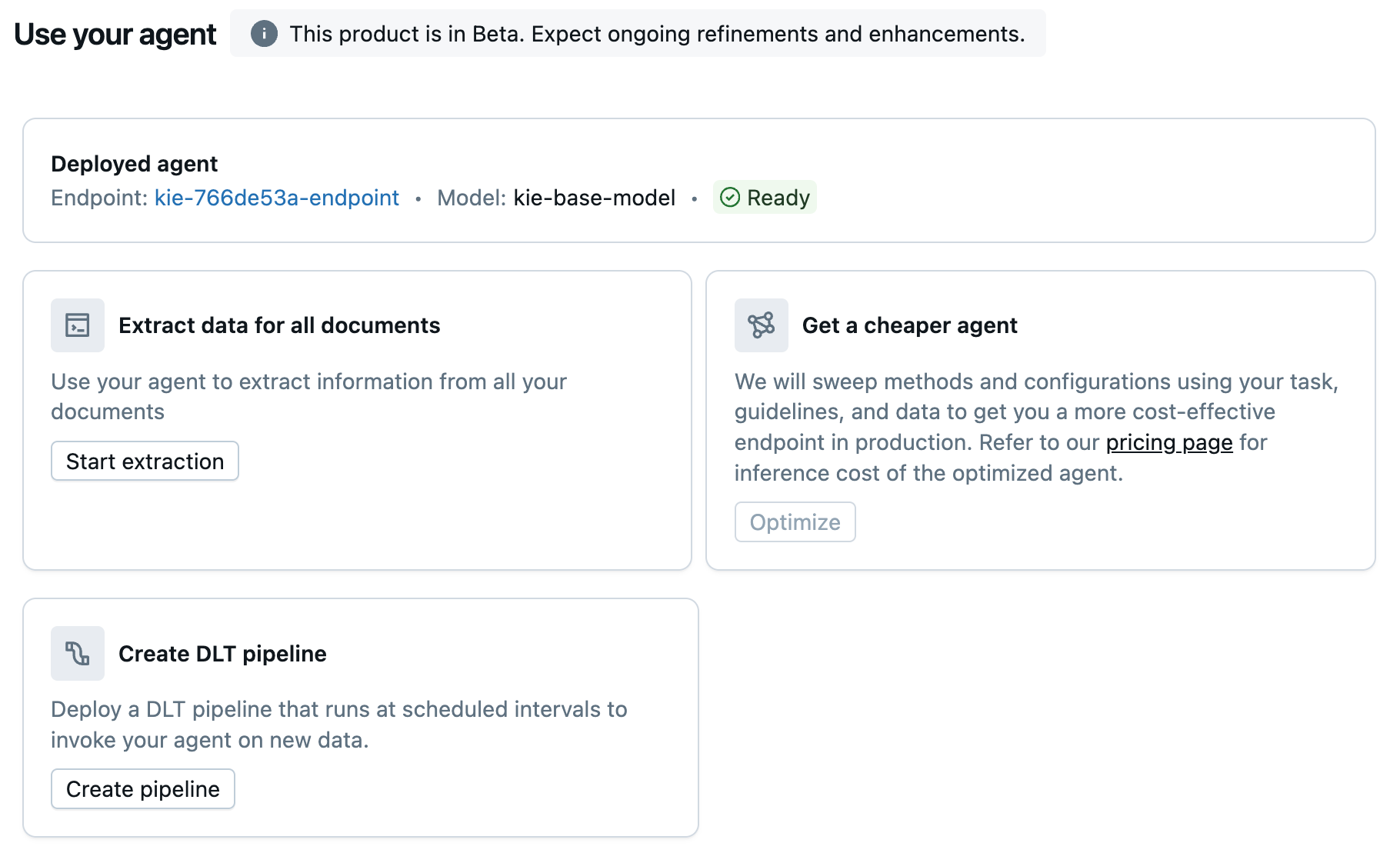
Stap 3: Uw agent gebruiken
U kunt uw agent gebruiken in werkstromen in Databricks.
Op het tabblad Gebruiken ,
Selecteer Extractie starten om de SQL-editor te openen en aanvragen
ai_queryte verzenden naar uw nieuwe agent voor gegevensextractie.(Optioneel) Selecteer Optimaliseren als u uw agent wilt optimaliseren voor kosten.
- Optimalisatie vereist ten minste 75 bestanden.
- Optimalisatie kan ongeveer een uur duren.
- Het aanbrengen van wijzigingen aan uw huidige actieve agent wordt geblokkeerd wanneer optimalisatie wordt uitgevoerd.
Wanneer de optimalisatie is voltooid, wordt u doorgestuurd naar het tabblad Controleren om een vergelijking te bekijken van uw huidige actieve agent en een agent die is geoptimaliseerd voor kosten. Zie (optioneel) Stap 4: Een geoptimaliseerde agent controleren en implementeren.
- (Optioneel) Selecteer Pijplijn maken om een pijplijn te implementeren die met geplande intervallen wordt uitgevoerd om uw agent op nieuwe gegevens te gebruiken. Zie declaratieve pijplijnen van Lakeflow voor meer informatie over pijplijnen.
(Optioneel) Stap 4: Een geoptimaliseerde agent controleren en implementeren
Wanneer u Optimaliseren selecteert op het tabblad Gebruik , vergelijkt Databricks meerdere verschillende optimalisatiestrategieën om een geoptimaliseerde agent te bouwen en aan te bevelen. Deze strategieën omvatten Foundation Model Fine-tuning die gebruikmaakt van Databricks Geos.
Op het tabblad Controleren ,
In de evaluatieresultaten kunt u de geoptimaliseerde agent en uw actieve agent visueel vergelijken. Voor het uitvoeren van evaluatie kiest Databricks een metrische waarde op basis van het gegevenstype van elk veld en gebruikt een evaluatiegegevensset om uw actieve agent en de agent te vergelijken die is geoptimaliseerd voor kosten. Deze evaluatieset is gebaseerd op een subset van de gegevens die u hebt gebruikt om de oorspronkelijke agent te maken.
- Metrische gegevens worden vastgelegd in de MLflow-uitvoering per veld (geaggregeerd naar het veld op het hoogste niveau).
- Selecteer de
overall_scoreenis_schema_matchkolommen in de vervolgkeuzelijst Kolommen.
Nadat u deze resultaten hebt bekeken, klikt u op Implementeren als u deze geoptimaliseerde agent wilt implementeren in plaats van uw momenteel actieve agent.
PDF's gebruiken in Agent Bricks
PDF-bestanden worden nog niet standaard ondersteund in Agent Bricks: Informatieextractie en aangepaste LLM. U kunt de UI-werkstroom van Agent Brick echter gebruiken om een map met PDF-bestanden te converteren naar Markdown en vervolgens de resulterende Unity Catalog-tabel als invoer gebruiken bij het bouwen van uw agent. Deze werkstroom gebruikt ai_parse_document voor de conversie. Volg deze stappen:
Klik op Agents in het linkernavigatiedeelvenster om Agent Bricks te openen in Databricks.
Klik in de rechterbovenhoek op
 Pdf-bestanden gebruiken in Agent Bricks.
Pdf-bestanden gebruiken in Agent Bricks.Voer in het deelvenster dat wordt geopend de volgende velden in om een nieuwe werkstroom te maken om uw PDF-bestanden te converteren:
- Selecteer de map met PDF-bestanden: selecteer de map Unity Catalog met de PDF-bestanden die u wilt gebruiken.
- Selecteer de doeltabel: Selecteer het doelschema voor de geconverteerde Markdown-tabel en pas desgewenst de tabelnaam aan in het onderstaande veld.
- Selecteer actief SQL Warehouse: selecteer het SQL Warehouse om de werkstroom te laten draaien.
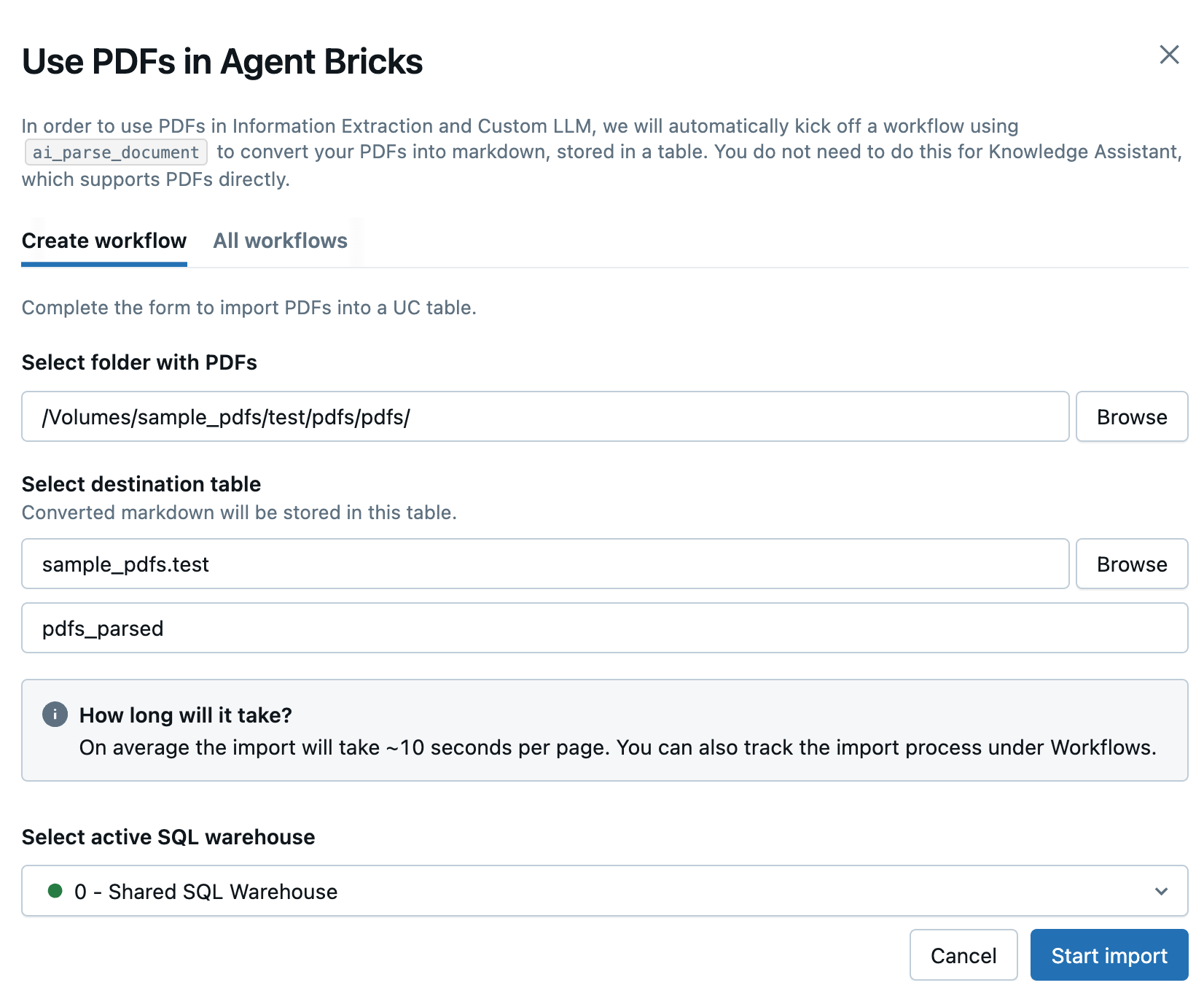
Klik op Importeren starten.
U wordt omgeleid naar het tabblad Alle werkstromen , waarin al uw PDF-werkstromen worden vermeld. Gebruik dit tabblad om de status van uw taken te controleren.
Als uw werkstroom mislukt, klikt u op de taaknaam om deze te openen en bekijkt u foutberichten om fouten op te sporen.
Wanneer uw werkstroom is voltooid, klikt u op de taaknaam om de tabel in Catalog Explorer te openen om de kolommen te verkennen en te begrijpen.
Gebruik de Tabel Unity Catalog als invoergegevens in Agent Bricks bij het configureren van uw agent.
Beperkingen
- Databricks raadt ten minste 1000 documenten aan om uw agent te optimaliseren. Wanneer u meer documenten toevoegt, neemt de kennisbasis waaruit de agent kan leren toe, wat de kwaliteit van de agent en de extractienauwkeurigheid verbetert.
- Als uw brondocumenten een bestand bevatten dat groter is dan 3 MB, mislukt het maken van de agent.
- Documenten die groter zijn dan 64 kB, kunnen tijdens het bouwen van agents worden overgeslagen.
- De invoer- en uitvoerlimiet is 128.000 tokens.
- Werkruimten die gebruikmaken van Azure Private Link, inclusief opslag achter Azure Private Link, worden niet ondersteund.
- Union-schematypen worden niet ondersteund.