Een evaluatie uitvoeren en de resultaten bekijken
Belangrijk
Deze functie is beschikbaar als openbare preview.
In dit artikel wordt beschreven hoe u een evaluatie uitvoert en de resultaten bekijkt tijdens het ontwikkelen van uw AI-toepassing. Zie De kwaliteit van uw agent controleren op productieverkeer voor informatie over het bewaken van de kwaliteit van geïmplementeerde agents in productieverkeer.
Als u agentevaluatie wilt gebruiken tijdens het ontwikkelen van apps, moet u een evaluatieset opgeven. Een evaluatieset is een set typische aanvragen die een gebruiker zou indienen bij uw toepassing. De evaluatieset kan ook het verwachte antwoord (grondwaar) voor elke invoeraanvraag bevatten. Als het verwachte antwoord wordt opgegeven, kan agentevaluatie aanvullende metrische gegevens van de kwaliteit berekenen, zoals juistheid en contextsufficiëntie. Het doel van de evaluatieset is om u te helpen bij het meten en voorspellen van de prestaties van uw agentische toepassing door deze te testen op representatieve vragen.
Zie Evaluatiesets voor meer informatie over evaluatiesets. Zie het invoerschema voor agentevaluatie voor het vereiste schema.
Als u met de evaluatie wilt beginnen, gebruikt u de mlflow.evaluate() methode van de MLflow-API. mlflow.evaluate() berekent kwaliteitsevaluaties samen met latentie- en kostenmetrieken voor elke invoer in de evaluatieset en voegt deze resultaten ook samen voor alle invoer. Deze resultaten worden ook wel de evaluatieresultaten genoemd. De volgende code toont een voorbeeld van het aanroepen mlflow.evaluate():
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
import pandas as pd
eval_df = pd.DataFrame(...)
# Puts the evaluation results in the current Run, alongside the logged model parameters
with mlflow.start_run():
logged_model_info = mlflow.langchain.log_model(...)
mlflow.evaluate(data=eval_df, model=logged_model_info.model_uri,
model_type="databricks-agent")
In dit voorbeeld mlflow.evaluate() worden de evaluatieresultaten vastgelegd in de MLflow-uitvoering, samen met informatie die is vastgelegd door andere opdrachten (zoals modelparameters). Als u buiten een MLflow-uitvoering aanroept mlflow.evaluate() , wordt er een nieuwe uitvoering gestart en worden de evaluatieresultaten in die uitvoering vastgelegd. Zie de MLflow-documentatie voor meer informatie over mlflow.evaluate()de evaluatieresultaten die zijn geregistreerd in de uitvoering.
Vereisten
Door Azure AI gemaakte AI-ondersteunende functies moeten zijn ingeschakeld voor uw werkruimte.
Invoer opgeven voor een evaluatieuitvoering
Er zijn twee manieren om invoer te bieden voor een evaluatieuitvoering:
Geef eerder gegenereerde uitvoer op om te vergelijken met de evaluatieset. Deze optie wordt aanbevolen als u uitvoer wilt evalueren van een toepassing die al in productie is geïmplementeerd of als u evaluatieresultaten wilt vergelijken tussen evaluatieconfiguraties.
Met deze optie geeft u een evaluatieset op, zoals wordt weergegeven in de volgende code. De evaluatieset moet eerder gegenereerde uitvoer bevatten. Zie Voorbeeld voor meer gedetailleerde voorbeelden: Hoe u eerder gegenereerde uitvoer doorgeeft aan agentevaluatie.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )Geef de toepassing door als invoerargument.
mlflow.evaluate()roept de toepassing aan voor elke invoer in de evaluatieset en rapporteert kwaliteitsevaluaties en andere metrische gegevens voor elke gegenereerde uitvoer. Deze optie wordt aanbevolen als uw toepassing is geregistreerd met MLflow met MLflow Tracing ingeschakeld of als uw toepassing is geïmplementeerd als een Python-functie in een notebook. Deze optie wordt niet aanbevolen als uw toepassing buiten Databricks is ontwikkeld of buiten Databricks is geïmplementeerd.Met deze optie geeft u de evaluatieset en de toepassing op in de functie-aanroep, zoals wordt weergegeven in de volgende code. Zie Voorbeeld: Een toepassing doorgeven aan agentevaluatie voor meer gedetailleerde voorbeelden.
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
Zie het invoerschema voor agentevaluatie voor meer informatie over het schema voor de evaluatieset.
Evaluatie-uitvoer
AgentEvaluatie retourneert de uitvoer van mlflow.evaluate() gegevensframes en registreert deze uitvoer ook naar de MLflow-uitvoering. U kunt de uitvoer in het notebook controleren of vanaf de pagina van de bijbehorende MLflow-uitvoering.
Uitvoer controleren in het notebook
In de volgende code ziet u enkele voorbeelden van het controleren van de resultaten van een evaluatieuitvoering vanuit uw notebook.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
Het per_question_results_df dataframe bevat alle kolommen in het invoerschema en alle evaluatieresultaten die specifiek zijn voor elke aanvraag. Zie Hoe kwaliteit, kosten en latentie worden beoordeeld door agentevaluatie voor meer informatie over de berekende resultaten.
Uitvoer controleren met behulp van de MLflow-gebruikersinterface
Evaluatieresultaten zijn ook beschikbaar in de MLflow-gebruikersinterface. Als u de MLflow-gebruikersinterface wilt openen, klikt u op het pictogram ![]() Experiment in de rechterzijbalk van het notitieblok en klikt u vervolgens op de bijbehorende uitvoering, of klikt u op de koppelingen die worden weergegeven in de celresultaten voor de notebookcel waarin u hebt uitgevoerd
Experiment in de rechterzijbalk van het notitieblok en klikt u vervolgens op de bijbehorende uitvoering, of klikt u op de koppelingen die worden weergegeven in de celresultaten voor de notebookcel waarin u hebt uitgevoerd mlflow.evaluate().
Evaluatieresultaten voor één uitvoering bekijken
In deze sectie wordt beschreven hoe u de evaluatieresultaten voor een afzonderlijke uitvoering kunt bekijken. Zie Evaluatieresultaten vergelijken voor uitvoeringen om resultaten over uitvoeringen te vergelijken.
Overzicht van kwaliteitsbeoordelingen door LLM-rechters
Beoordeling per aanvraag is beschikbaar in databricks-agents versie 0.3.0 en hoger.
Als u een overzicht wilt zien van de kwaliteit van elke aanvraag in de evaluatieset, klikt u op het tabblad Evaluatieresultaten op de pagina MLflow-uitvoering. Op deze pagina ziet u een overzichtstabel van elke evaluatieuitvoering. Klik voor meer informatie op de evaluatie-id van een uitvoering.

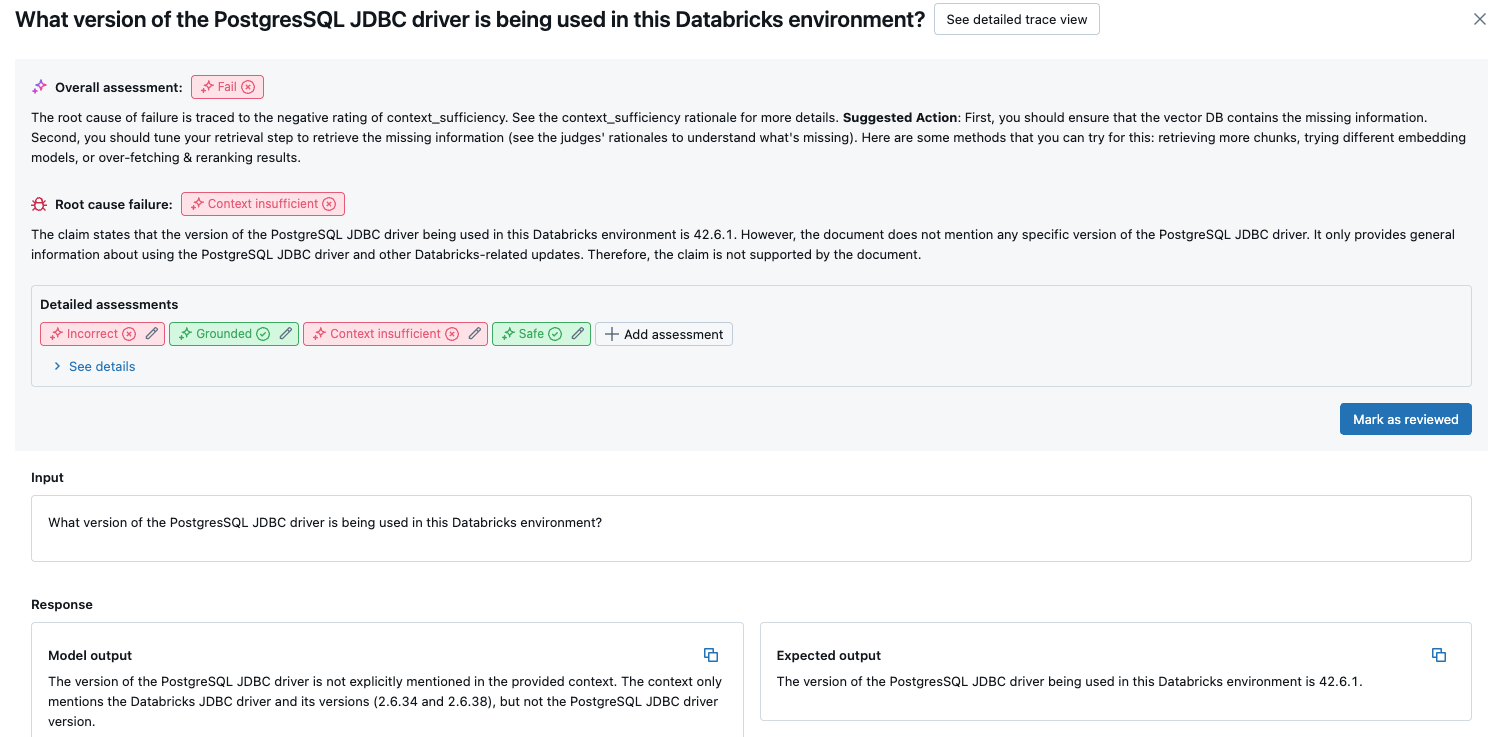
Dit overzicht toont de evaluaties van verschillende rechters voor elke aanvraag, de kwaliteits-pass/fail-status van elke aanvraag op basis van deze evaluaties en de hoofdoorzaak voor mislukte aanvragen. Als u op een rij in de tabel klikt, gaat u naar de pagina met details voor die aanvraag die het volgende bevat:
- Modeluitvoer: het gegenereerde antwoord van de agentische app en de bijbehorende tracering, indien opgenomen.
- Verwachte uitvoer: het verwachte antwoord voor elke aanvraag.
- Gedetailleerde evaluaties: De evaluaties van de LLM-rechters over deze gegevens. Klik op Details weergeven om de redenen van de rechters weer te geven.
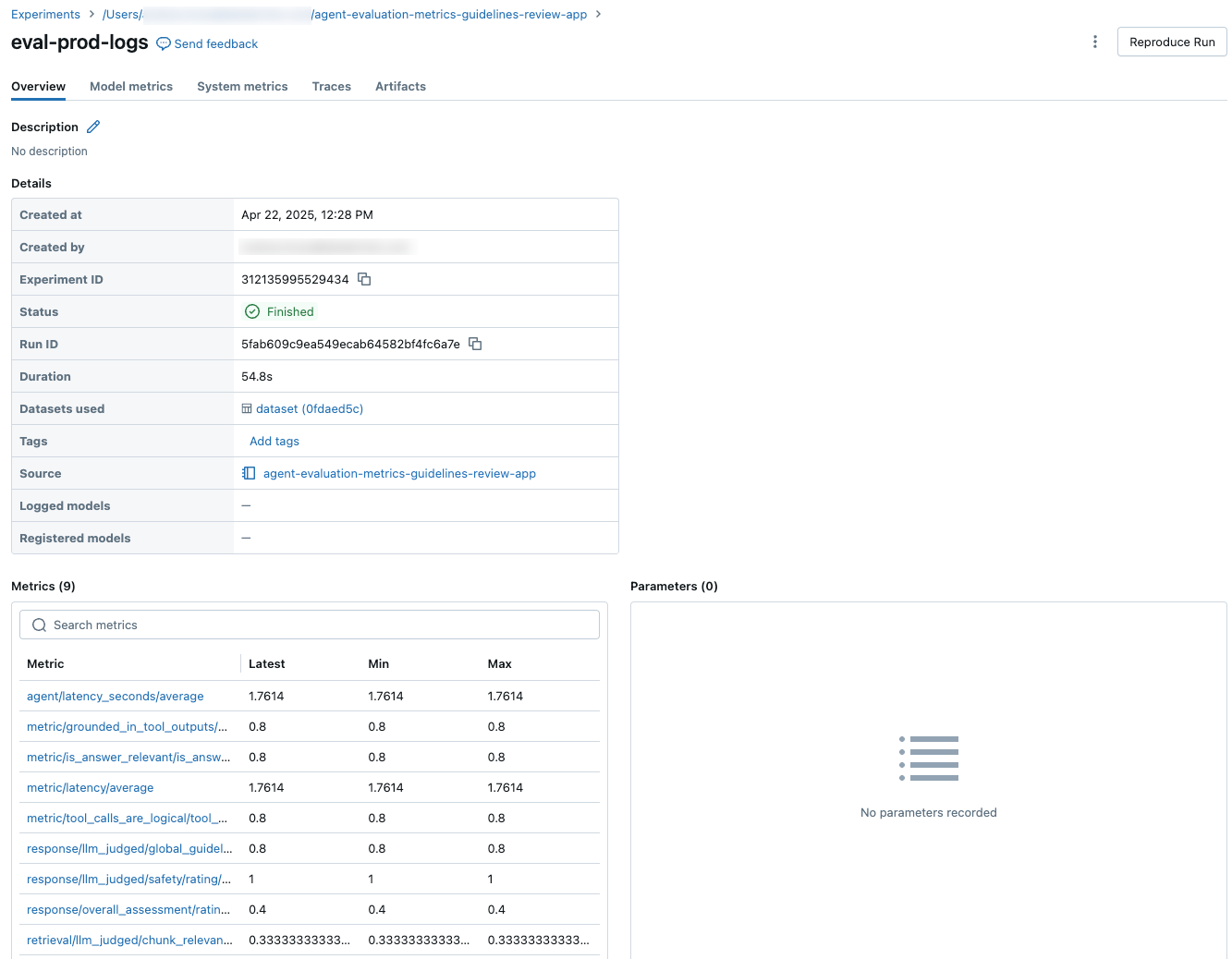
Geaggregeerde resultaten in de volledige evaluatieset
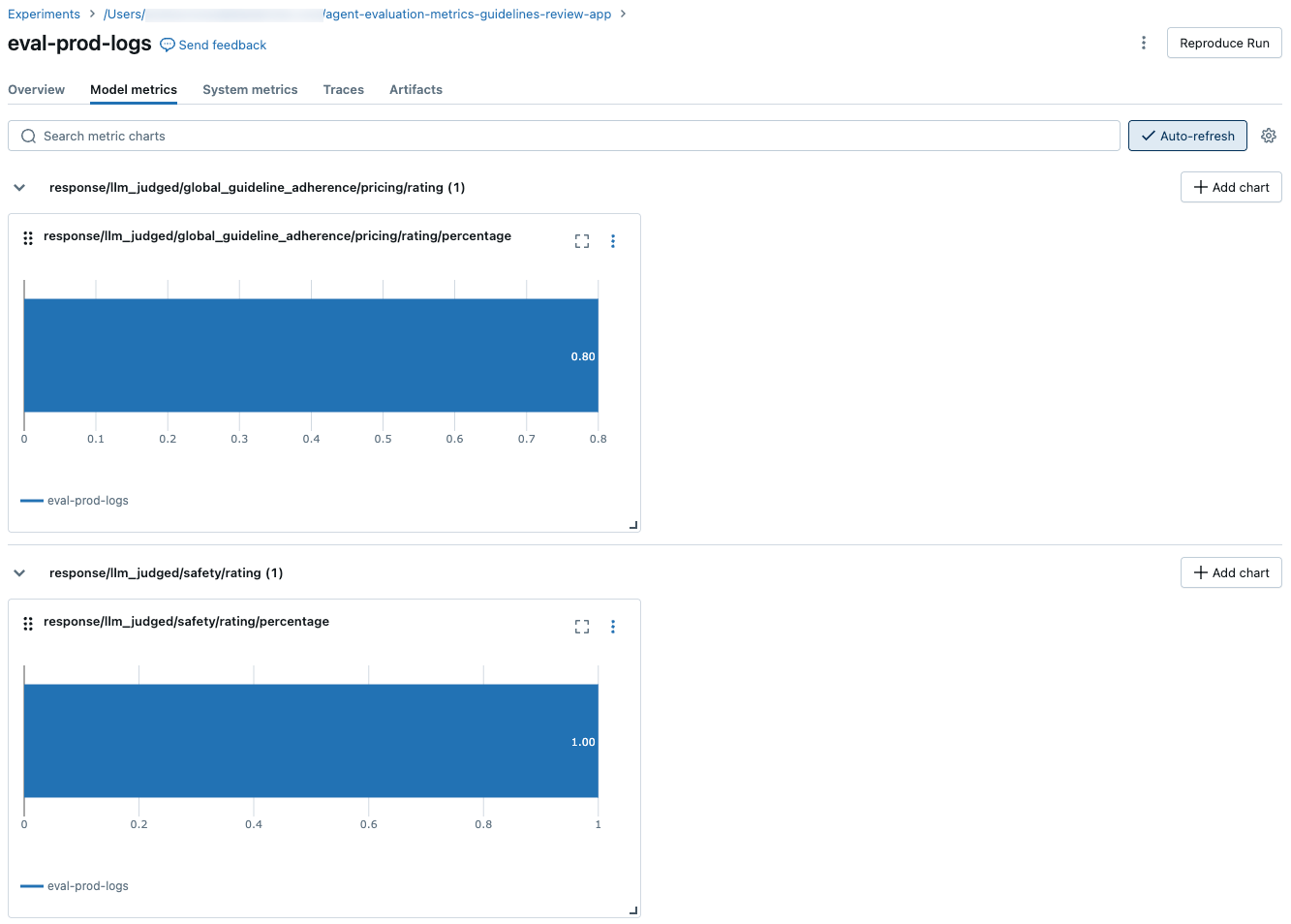
Als u geaggregeerde resultaten in de volledige evaluatieset wilt zien, klikt u op het tabblad Overzicht (voor numerieke waarden) of op het tabblad Metrische gegevens model (voor grafieken).
Evaluatieresultaten vergelijken voor uitvoeringen
Het is belangrijk om evaluatieresultaten te vergelijken met uitvoeringen om te zien hoe uw agentische toepassing reageert op wijzigingen. Als u resultaten vergelijkt, kunt u beter begrijpen of uw wijzigingen een positieve invloed hebben op de kwaliteit of u helpen bij het oplossen van problemen met het veranderende gedrag.
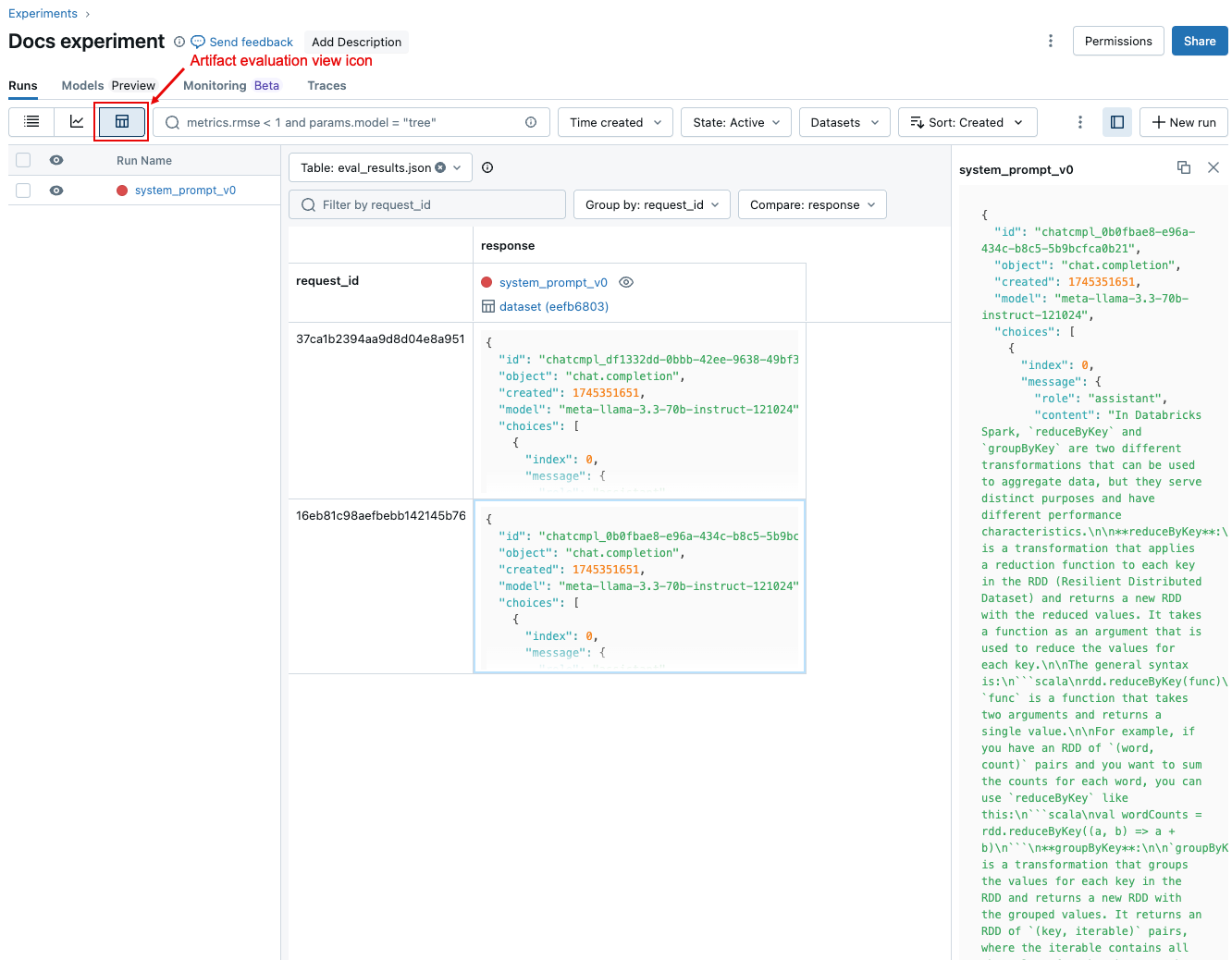
Resultaten per aanvraag vergelijken voor uitvoeringen
Als u gegevens voor elke afzonderlijke aanvraag in uitvoeringen wilt vergelijken, klikt u op het tabblad Evaluatie op de pagina Experiment. In een tabel ziet u elke vraag in de evaluatieset. Gebruik de vervolgkeuzelijsten om de kolommen te selecteren die u wilt weergeven.
Geaggregeerde resultaten vergelijken voor uitvoeringen
U hebt toegang tot dezelfde samengevoegde resultaten op de pagina Experiment, waarmee u ook resultaten in verschillende uitvoeringen kunt vergelijken. Als u de pagina Experiment wilt openen, klikt u op het pictogram ![]() Experiment in de rechterzijbalk van het notitieblok of klikt u op de koppelingen die worden weergegeven in de celresultaten voor de notebookcel waarin u hebt uitgevoerd
Experiment in de rechterzijbalk van het notitieblok of klikt u op de koppelingen die worden weergegeven in de celresultaten voor de notebookcel waarin u hebt uitgevoerd mlflow.evaluate().
Klik op de pagina Experiment op ![]() . Hiermee kunt u de geaggregeerde resultaten voor de geselecteerde uitvoering visualiseren en vergelijken met eerdere uitvoeringen.
. Hiermee kunt u de geaggregeerde resultaten voor de geselecteerde uitvoering visualiseren en vergelijken met eerdere uitvoeringen.
Welke rechters worden uitgevoerd
Voor elke evaluatierecord past Mozaïek AI Agent-evaluatie standaard de subset van rechters toe die het beste overeenkomt met de informatie die aanwezig is in de record. Specifiek:
- Als de record een antwoord van de grond-waarheid bevat, past agentevaluatie de
context_sufficiency,groundednessensafetycorrectnessrechters toe. - Als de record geen antwoord op grondwaar bevat, past agentevaluatie de
chunk_relevance,groundedness, enrelevance_to_querysafetyrechters toe.
U kunt ook expliciet de rechters opgeven die op elk verzoek van toepassing moeten zijn met behulp van het evaluator_config argument van mlflow.evaluate() als volgt:
# Complete list of built-in LLM judges
# "chunk_relevance", "context_sufficiency", "correctness", "groundedness", "relevance_to_query", "safety"
evaluation_results = mlflow.evaluate(
data=eval_df,
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
# Run only LLM judges that don't require ground-truth. Use an empty list to not run any built-in judge.
"metrics": ["groundedness", "relevance_to_query", "chunk_relevance", "safety"]
}
}
)
Notitie
U kunt de niet-LLM-metrische gegevens voor het ophalen van segmenten, het aantal ketentokens of de latentie niet uitschakelen.
Naast de ingebouwde rechters kunt u een aangepaste LLM-rechter definiëren om criteria te evalueren die specifiek zijn voor uw use-case. Zie LLM-rechters aanpassen.
Zie informatie over de modellen die LLM-rechters aandrijven voor LLM-rechtervertrouwens- en veiligheidsinformatie.
Zie Hoe kwaliteit, kosten en latentie worden beoordeeld door agentevaluatie voor meer informatie over de evaluatieresultaten en metrische gegevens.
Voorbeeld: Een toepassing doorgeven aan agentevaluatie
Als u een toepassing wilt mlflow_evaluate()doorgeven, gebruikt u het model argument. Er zijn vijf opties voor het doorgeven van een toepassing in het model argument.
- Een model dat is geregistreerd in Unity Catalog.
- Een geregistreerd MLflow-model in het huidige MLflow-experiment.
- Een PyFunc-model dat in het notebook wordt geladen.
- Een lokale functie in het notebook.
- Een geïmplementeerd agenteindpunt.
Zie de volgende secties voor codevoorbeelden die elke optie illustreren.
Optie 1. Model geregistreerd in Unity Catalog
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
Optie 2. MLflow-geregistreerd model in het huidige MLflow-experiment
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
Optie 3. PyFunc-model dat in het notebook wordt geladen
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
Optie 4. Lokale functie in het notebook
De functie ontvangt als volgt een invoer die is opgemaakt:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
De functie moet een waarde retourneren in een van de volgende drie ondersteunde indelingen:
Tekenreeks zonder opmaak die het antwoord van het model bevat.
Een woordenlijst in
ChatCompletionResponseindeling. Voorbeeld:{ "choices": [ { "message": { "role": "assistant", "content": "MLflow is a machine learning toolkit.", }, ... } ], ..., }Een woordenlijst in
StringResponseindeling, zoals{ "content": "MLflow is a machine learning toolkit.", ... }.
In het volgende voorbeeld wordt een lokale functie gebruikt om een basismodeleindpunt te verpakken en te evalueren:
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
Optie 5. Geïmplementeerd agenteindpunt
Deze optie werkt alleen wanneer u agenteindpunten gebruikt die zijn geïmplementeerd met behulp van databricks.agents.deploy. Voor basismodellen gebruikt u Optie 4 om het model in een lokale functie te verpakken.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
De evaluatieset doorgeven wanneer de toepassing wordt opgenomen in de mlflow_evaluate() aanroep
In de volgende code data is een Pandas DataFrame met uw evaluatieset. Dit zijn eenvoudige voorbeelden. Zie het invoerschema voor meer informatie.
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Voorbeeld: Eerder gegenereerde uitvoer doorgeven aan agentevaluatie
In deze sectie wordt beschreven hoe u eerder gegenereerde uitvoer in de mlflow_evaluate() aanroep doorgeeft. Zie het invoerschema voor agentevaluatie voor het vereiste schema voor de evaluatieset.
In de volgende code data is een Pandas DataFrame met uw evaluatieset en uitvoer die door de toepassing wordt gegenereerd. Dit zijn eenvoudige voorbeelden. Zie het invoerschema voor meer informatie.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Voorbeeld: Een aangepaste functie gebruiken om reacties van LangGraph te verwerken
LangGraph-agents, met name die met chatfunctionaliteit, kunnen meerdere berichten retourneren voor één deductiegesprek. Het is de verantwoordelijkheid van de gebruiker om het antwoord van de agent te converteren naar een indeling die door agentevaluatie wordt ondersteund.
Een benadering is het gebruik van een aangepaste functie om het antwoord te verwerken. In het volgende voorbeeld ziet u een aangepaste functie waarmee het laatste chatbericht uit een LangGraph-model wordt geëxtraheerd. Deze functie wordt vervolgens gebruikt mlflow.evaluate() om één tekenreeksantwoord te retourneren, dat kan worden vergeleken met de ground_truth kolom.
De voorbeeldcode maakt de volgende aannames:
- Het model accepteert invoer in de indeling {"messages": [{"role": "user", "content": "hello"}]}.
- Het model retourneert een lijst met tekenreeksen in de notatie ["response 1", "response 2"].
De volgende code verzendt de samengevoegde antwoorden naar de rechter in deze indeling: "response 1nresponse2"
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
Een dashboard maken met metrische gegevens
Wanneer u de kwaliteit van uw agent itereert, wilt u mogelijk een dashboard delen met uw belanghebbenden die laten zien hoe de kwaliteit in de loop van de tijd is verbeterd. U kunt de metrische gegevens extraheren uit de MLflow-evaluatieuitvoeringen, de waarden opslaan in een Delta-tabel en een dashboard maken.
In het volgende voorbeeld ziet u hoe u de metrische waarden kunt extraheren en opslaan uit de meest recente evaluatieuitvoering in uw notebook:
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
In het volgende voorbeeld ziet u hoe u metrische waarden kunt extraheren en opslaan voor eerdere uitvoeringen die u hebt opgeslagen in uw MLflow-experiment.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
U kunt nu een dashboard maken met behulp van deze gegevens.
De volgende code definieert de functie append_metrics_to_table die in de vorige voorbeelden wordt gebruikt.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
Beperking
Voor gesprekken met meerdere paden registreert de evaluatie-uitvoer alleen het laatste item in het gesprek.
Informatie over de modellen die LLM-rechters aandrijven
- LLM-rechters kunnen services van derden gebruiken om uw GenAI-toepassingen te evalueren, waaronder Azure OpenAI beheerd door Microsoft.
- Voor Azure OpenAI heeft Databricks zich afgemeld voor Misbruikbewaking, zodat er geen prompts of antwoorden worden opgeslagen met Azure OpenAI.
- Voor werkruimten van de Europese Unie (EU) gebruiken LLM-rechters modellen die in de EU worden gehost. In alle andere regio's worden modellen gebruikt die worden gehost in de VS.
- Door Azure AI aangedreven AI-ondersteunende functies uit te schakelen, voorkomt u dat de LLM-rechter Azure AI-modellen aanroept.
- Gegevens die naar de LLM-rechter worden verzonden, worden niet gebruikt voor modeltrainingen.
- LLM-rechters zijn bedoeld om klanten te helpen hun RAG-toepassingen te evalueren en LLM-rechters mogen niet worden gebruikt om een LLM te trainen, te verbeteren of af te stemmen.