Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Pijplijnen kunnen veel gegevenssets bevatten met veel datastromen om ze up-to-date te houden. Pijplijnen verzorgen automatisch het beheer van updates en clusters om de updates efficiënt uit te voeren. Er is echter enige overhead bij het beheren van grote aantallen stromen, en soms kan dit leiden tot grotere dan verwachte initialisatie of zelfs beheeroverhead tijdens de verwerking.
Als u vertragingen ondervindt die optreden wanneer u moet wachten op de initialisatie van geactiveerde pijplijnen, zoals initialisatietijden van meer dan vijf minuten, kunt u overwegen om de verwerking op te splitsen in verschillende pijplijnen, zelfs wanneer de datasets dezelfde brongegevens gebruiken.
Opmerking
Geactiveerde pijplijnen voeren de initialisatiestappen uit telkens wanneer ze worden geactiveerd. Continue pijplijnen voeren alleen de initialisatiestappen uit wanneer ze worden gestopt en opnieuw worden gestart. Deze sectie is het handigst voor het optimaliseren van geactiveerde pijplijn initialisatie.
Wanneer u een pijplijn wilt splitsen
Er zijn verschillende gevallen waarin het splitsen van een pijplijn voordelig kan zijn voor prestatieverbetering.
- De
INITIALIZINGenSETTING_UP_TABLESfasen duren langer dan u wilt, wat van invloed is op de totale tijd van de pijplijn. Als dit meer dan 5 minuten is, wordt deze vaak verbeterd door uw pijplijn te splitsen. - Het stuurprogramma dat het cluster beheert, kan een knelpunt worden bij het uitvoeren van veel (meer dan 30-40) streamingtabellen binnen één pijplijn. Als uw stuurprogramma niet reageert, nemen de duur van streamingquery's toe, wat van invloed is op de totale tijd van uw update.
- Een geactiveerde pijplijn met meerdere streamingtabelstromen kan mogelijk niet alle paralleliseerbare stroomupdates parallel uitvoeren.
Informatie over prestatieproblemen
In deze sectie worden enkele prestatieproblemen beschreven die kunnen optreden als gevolg van het hebben van veel tabellen en stromen in één pijplijn.
Knelpunten in de fasen INITIALISEREN en TABELINSTALLATIE.
De eerste fasen van de uitvoering kunnen een prestatieknelpunt zijn, afhankelijk van de complexiteit van de pijplijn.
Initialisatiefase
Tijdens deze fase worden logische plannen gemaakt, inclusief plannen voor het bouwen van de afhankelijkheidsgrafiek en het bepalen van de volgorde van tabelupdates.
SETTING_UP_TABLES-fase
Tijdens deze fase worden de volgende processen uitgevoerd op basis van de plannen die in de vorige fase zijn gemaakt:
- Schemavalidatie en -oplossing voor alle tabellen die in de pijplijn zijn gedefinieerd.
- Bouw de afhankelijkheidsgrafiek en bepaal de volgorde van de tabeluitvoering.
- Controleer of elke gegevensset actief is in de pijplijn of nieuw is sinds een eerdere update.
- Maak streamingtabellen in de eerste update en maak voor gematerialiseerde weergaven tijdelijke weergaven of back-uptabellen die tijdens elke pijplijnupdate zijn vereist.
Waarom INITIALISEREN en TAFELS_INRICHTEN langer kunnen duren
Grote pijplijnen met veel stromen voor veel gegevenssets kunnen om verschillende redenen langer duren:
- Voor pijplijnen met veel stromen en complexe afhankelijkheden kan het langer duren voordat het werk is voltooid.
- Complexe transformaties, inclusief
Auto CDCtransformaties, kunnen een knelpunt in de prestaties veroorzaken vanwege de bewerkingen die nodig zijn om de tabellen te materialiseren op basis van de gedefinieerde transformaties. - Er zijn ook scenario's waarin een aanzienlijk aantal stromen traag kan zijn, zelfs als deze stromen geen deel uitmaken van een update. Denk bijvoorbeeld aan een pijplijn met meer dan 700 stromen, waarvan er minder dan 50 worden bijgewerkt voor elke trigger, op basis van een configuratie. In dit voorbeeld moet elke uitvoering enkele van de stappen voor alle 700 tabellen doorlopen, de gegevensframes ophalen en vervolgens de stappen selecteren die moeten worden uitgevoerd.
Knelpunten in het stuurprogramma
Het stuurprogramma beheert de updates binnen de uitvoering. Er moet logica voor elke tabel worden uitgevoerd om te bepalen welke exemplaren in een cluster elke stroom moeten verwerken. Bij het uitvoeren van meerdere (meer dan 30-40) streamingtabellen binnen één pijplijn, kan de driver een knelpunt worden voor CPU-resources doordat deze de werklast over het cluster verdeelt.
Het stuurprogramma kan ook geheugenproblemen ondervinden. Dit kan vaker gebeuren wanneer het aantal parallelle stromen 30 of meer is. Er is geen specifiek aantal stromen of gegevenssets die problemen met het geheugen van het stuurprogramma kunnen veroorzaken, maar is afhankelijk van de complexiteit van de taken die parallel worden uitgevoerd.
Streamingstromen kunnen parallel worden uitgevoerd, maar hiervoor moet het stuurprogramma gelijktijdig geheugen en CPU gebruiken voor alle streams. In een geactiveerde pijplijn kan het stuurprogramma een subset van streams tegelijk verwerken om geheugen- en CPU-beperkingen te voorkomen.
Door in al deze gevallen de pijplijnen te splitsen zodat er in elk een optimale set stromen is, kan de initialisatie- en verwerkingstijd worden versneld.
Compromissen met het splitsen van pijplijnen
Wanneer al uw stromen zich in dezelfde pijplijn bevinden, beheert Lakeflow Spark-declaratieve pijplijnen afhankelijkheden voor u. Wanneer er meerdere pijplijnen zijn, moet u de afhankelijkheden tussen pijplijnen beheren.
Afhankelijkheden Mogelijk hebt u een downstream-pijplijn die afhankelijk is van meerdere upstream-pijplijnen (in plaats van één). Als u bijvoorbeeld drie pijplijnen hebt,
pipeline_A,pipeline_Benpipeline_C, enpipeline_Cafhankelijk is van zowelpipeline_Aalspipeline_B, wilt u datpipeline_Cpas wordt bijgewerkt als zowelpipeline_Aalspipeline_Bhun respectieve updates hebben voltooid. Een manier om dit aan te pakken, is door de afhankelijkheden te organiseren door elke pijplijn een taak in een taak te maken met de afhankelijkheden die correct zijn gemodelleerd, zodatpipeline_Calleen updates worden uitgevoerd nadat beidepipeline_Azijn voltooid.pipeline_BConcurrency Mogelijk hebt u verschillende stromen in een pijplijn die zeer verschillende tijdsduur in beslag nemen, bijvoorbeeld als
flow_Aupdates binnen 15 seconden enflow_Benkele minuten duren. Het kan handig zijn om de querytijden te bekijken voordat u uw pijplijnen splitst en kortere query's groepeert.
Plannen voor het splitsen van uw pijplijnen
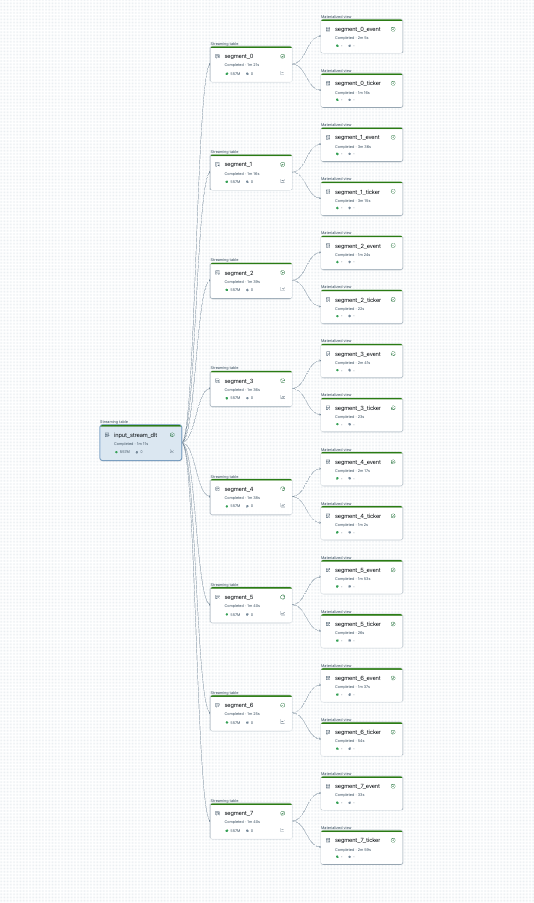
U kunt de pijplijnsplitsing visualiseren voordat u begint. Hier volgt een grafiek van een bronpijplijn die 25 tabellen verwerkt. Eén hoofdgegevensbron wordt gesplitst in 8 segmenten, elk met twee weergaven.
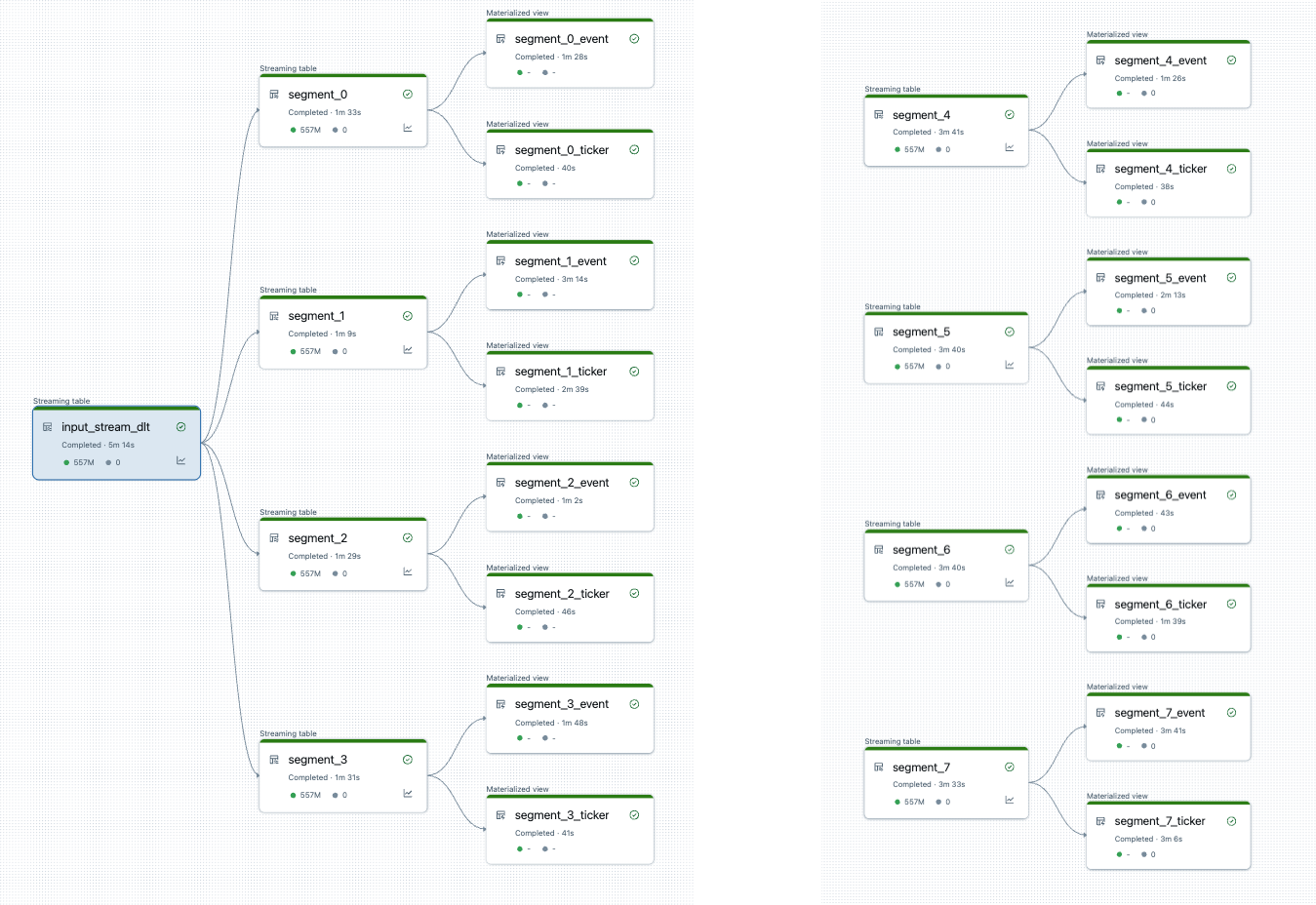
Na het splitsen van de pijplijn zijn er twee pijplijnen. Eén verwerkt de gegevensbron met één hoofddatasource en vier segmenten en bijbehorende weergaven. De tweede pijplijn verwerkt de andere vier segmenten en de bijbehorende overzichten. De tweede pijplijn is afhankelijk van de eerste om de hoofdgegevensbron bij te werken.
De pijplijn splitsen zonder een volledige vernieuwing
Nadat u de pijplijnsplitsing hebt gepland, maakt u eventuele nieuwe pijplijnen die nodig zijn en verplaatst u tabellen tussen pijplijnen om de taakverdeling van de pijplijn te verdelen. U kunt tabellen verplaatsen zonder een volledige vernieuwing te veroorzaken.
Zie Tabellen verplaatsen tussen pijplijnen voor meer informatie.
Er zijn enkele beperkingen met deze aanpak:
- De pijplijnen moeten in de Unity Catalog zijn.
- Bron- en doelpijplijnen moeten zich in dezelfde werkruimte bevinden. Verplaatsingen tussen werkruimten worden niet ondersteund.
- De doelpijplijn moet worden gemaakt en eenmaal worden uitgevoerd (zelfs als deze mislukt) vóór de verplaatsing.
- U kunt een tabel niet verplaatsen van een pijplijn die gebruikmaakt van de standaardpublicatiemodus naar een tabel die gebruikmaakt van de verouderde publicatiemodus. Zie LIVE-schema (verouderd) voor meer informatie.