Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In data engineering verwijst backfilling naar het proces van retroactief verwerken van historische gegevens via een gegevenspijplijn die is ontworpen voor het verwerken van huidige of streaminggegevens.
Normaal gesproken is dit een afzonderlijke stroom die gegevens naar uw bestaande tabellen verzendt. In de volgende afbeelding ziet u een backfillstroom die historische gegevens naar de bronstabellen in uw pijplijn verzendt.
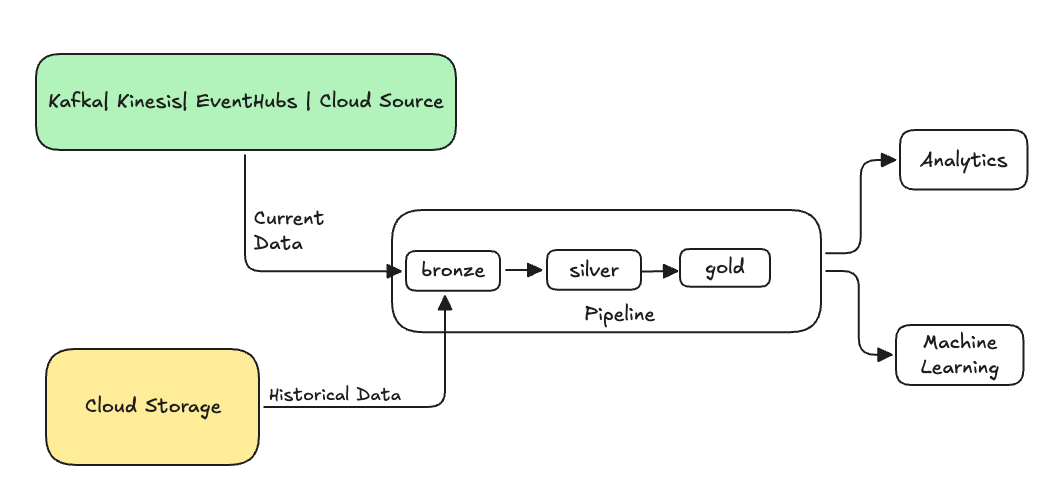
Voor sommige scenario's waarvoor mogelijk een backfill is vereist:
- Historische gegevens van een verouderd systeem verwerken om een machine learning-model (ML) te trainen of een historisch trendanalysedashboard te bouwen.
- Hiermee wordt een subset van gegevens opnieuw verwerkt vanwege een probleem met gegevenskwaliteit met upstream-gegevensbronnen.
- Uw zakelijke vereisten zijn gewijzigd en u moet gegevens invullen voor een andere periode die niet wordt gedekt door de eerste pijplijn.
- Uw bedrijfslogica is gewijzigd en u moet zowel historische als huidige gegevens opnieuw verwerken.
Een backfill in declaratieve Lakeflow Spark-pijplijnen wordt ondersteund met een gespecialiseerde append-flow die gebruikmaakt van de ONCE optie. Zie append_flow of CREATE FLOW (pijplijnen) voor meer informatie over de ONCE optie.
Overwegingen bij het doorvoeren van historische gegevens in een streamingtabel
- Voeg doorgaans de gegevens toe aan de bronsstreamingtabel. Downstream zilver- en goudlagen halen de nieuwe gegevens uit de bronslaag op.
- Zorg ervoor dat uw pijplijn dubbele gegevens probleemloos kan verwerken als dezelfde gegevens meerdere keren worden toegevoegd.
- Zorg ervoor dat het historische gegevensschema compatibel is met het huidige gegevensschema.
- Houd rekening met de grootte van het gegevensvolume en de vereiste SLA voor verwerkingstijd en configureer het cluster en de batchgrootten dienovereenkomstig.
Voorbeeld: Een backfill toevoegen aan een bestaande pijplijn
In dit voorbeeld hebt u een pijplijn die onbewerkte gebeurtenisregistratiegegevens opneemt uit een cloudopslagbron vanaf 01 januari 2025. U realiseert zich later dat u de vorige drie jaar historische gegevens wilt invullen voor downstreamrapportage en analyse van gebruiksscenario's. Alle gegevens bevinden zich op één locatie, gepartitioneerd op jaar, maand en dag, in JSON-indeling.
Eerste pijplijn
Hier volgt de beginnende pijplijncode die incrementeel de onbewerkte gebeurtenisregistratiegegevens uit de cloudopslag opneemt.
Python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
SQL
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
Hier gebruiken we de modifiedAfter Auto Loader-optie om ervoor te zorgen dat we niet alle gegevens verwerken van het cloud-opslagpad. De incrementele verwerking wordt bij die grens afgekapt.
Aanbeveling
Andere gegevensbronnen, zoals Kafka, Kinesis en Azure Event Hubs, hebben gelijkwaardige lezeropties om hetzelfde gedrag te bereiken.
Backfill-gegevens uit de afgelopen 3 jaar
Nu wilt u een of meer stromen toevoegen om eerdere gegevens in te vullen. Voer in dit voorbeeld de volgende stappen uit:
- Gebruik de
append onceworkflow. Hiermee wordt een eenmalige backfill uitgevoerd zonder verder te gaan na die eerste backfill. De code blijft aanwezig in uw pijplijn en als de pijplijn ooit volledig wordt vernieuwd, wordt de backfill opnieuw uitgevoerd. - Maak drie backfill-stromen, één voor elk jaar (in dit geval worden de gegevens in het pad gesplitst per jaar). Voor Python parameteriseren we het maken van de stromen, maar in SQL herhalen we de code drie keer, één keer voor elke stroom.
Als u aan uw eigen project werkt en geen serverloze berekeningen gebruikt, kunt u de maximale werkrollen voor de pijplijn bijwerken. Het verhogen van het maximum aantal werknemers zorgt ervoor dat u over de middelen beschikt om de historische gegevens te verwerken, terwijl u doorgaat met het verwerken van de huidige streaminggegevens binnen de verwachte SLA.
Aanbeveling
Als u serverloze berekeningen gebruikt met verbeterde automatische schaalaanpassing (de standaardinstelling), wordt het cluster automatisch groter wanneer uw belasting toeneemt.
Python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
SQL
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
Deze implementatie markeert verschillende belangrijke patronen.
Scheiding van verantwoordelijkheden
- Incrementele verwerking is onafhankelijk van backfill-bewerkingen.
- Elke stroom heeft zijn eigen configuratie- en optimalisatie-instellingen.
- Er is een duidelijk onderscheid tussen incrementele en backfillbewerkingen.
Gecontroleerde uitvoering
- Als u de
ONCEoptie gebruikt, zorgt u ervoor dat elke backfill precies eenmaal wordt uitgevoerd. - De backfillstroom blijft in de pijplijngrafiek staan, maar wordt inactief nadat deze is voltooid. Het is automatisch gereed voor gebruik bij een volledige verversing.
- Er is een duidelijk audit-trail van backfill-operaties in de definitie van de pijplijn.
Optimalisatie van verwerking
- U kunt de grote backfill splitsen in meerdere kleinere backfills voor snellere verwerking of voor controle over de verwerking.
- Met verbeterde automatische schaalaanpassing wordt de clustergrootte dynamisch geschaald op basis van de huidige clusterbelasting.
Ontwikkeling van schema's
- Het gebruik van
schemaEvolutionMode="addNewColumns"gaat soepel om met schemawijzigingen. - U hebt consistente schemadeductie voor historische en huidige gegevens.
- Er is een veilige verwerking van nieuwe kolommen in nieuwere gegevens.