Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
U maakt en implementeert een ETL-pijplijn (extraheren, transformeren en laden) met CDC (Change Data Capture) met behulp van Lakeflow-pijplijnen voor gegevensindeling en Automatisch laden. Een ETL-pijplijn implementeert de stappen voor het lezen van gegevens uit bronsystemen, het transformeren van die gegevens op basis van vereisten, zoals gegevenskwaliteitscontroles en recordontdubbeling en het schrijven van de gegevens naar een doelsysteem, zoals een datawarehouse of een data lake.
In deze zelfstudie gebruikt u gegevens uit een customers tabel in een MySQL-database om:
- Extraheer de wijzigingen uit een transactionele database met behulp van Debezium of een ander hulpprogramma en sla ze op in de cloudobjectopslag (S3, ADLS of GCS). In deze zelfstudie slaat u het instellen van een extern CDC-systeem over en genereert u in plaats daarvan valse gegevens om de zelfstudie te vereenvoudigen.
- Gebruik Automatisch laden om de berichten incrementeel te laden vanuit de opslag van cloudobjecten en de onbewerkte berichten in de
customers_cdctabel op te slaan. Auto Loader bepaalt het schema en beheert de evolutie ervan. - Maak de tabel om de
customers_cdc_cleangegevenskwaliteit te controleren aan de hand van verwachtingen. Het mag bijvoorbeeldidnooit zijnnullomdat het wordt gebruikt om upsert-bewerkingen uit te voeren. - Voer
AUTO CDC ... INTOuit op de opgeschoonde CDC-gegevens om wijzigingen bij te werken in de uiteindelijkecustomers-tabel. - Laat zien hoe een pijplijn een scd2-tabel (langzaam veranderende dimensie) kan maken om alle wijzigingen bij te houden.
Het doel is om de onbewerkte gegevens bijna in realtime op te nemen en een tabel te maken voor uw analistenteam en tegelijkertijd gegevenskwaliteit te garanderen.
In de zelfstudie wordt gebruikgemaakt van de medallion Lakehouse-architectuur, waarbij onbewerkte gegevens worden opgenomen via de bronslaag, gegevens worden opgeschoond en gevalideerd met de zilveren laag, en dimensionale modellering en aggregatie worden toegepast door de gouden laag. Zie Wat is de medallion lakehouse-architectuur? voor meer informatie.
De geïmplementeerde stroom ziet er als volgt uit:
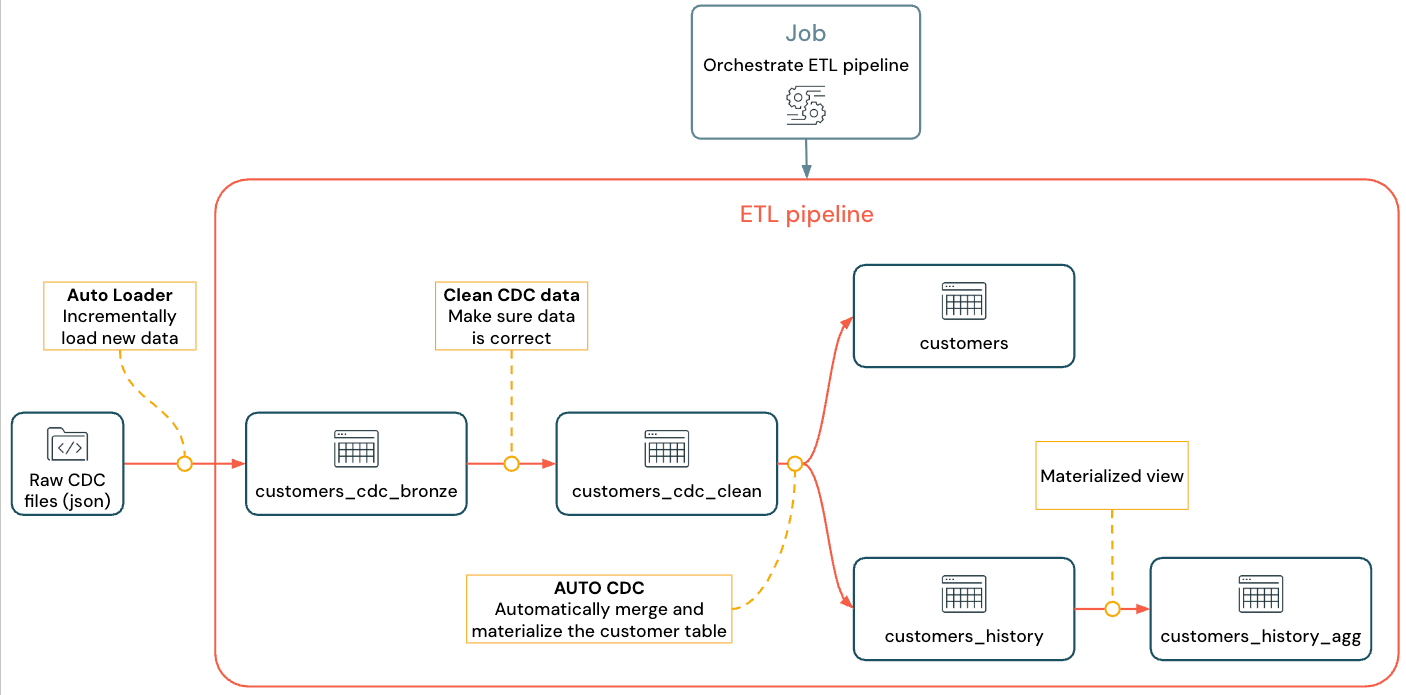
Zie Spark-declaratieve pijplijnen, Wat is Automatisch laden?, en Gegevensopnamen en momentopnamen wijzigen voor meer informatie over pijplijn, Automatisch laden en CDC
Requirements
Als u deze zelfstudie wilt voltooien, moet u aan de volgende vereisten voldoen:
- Unity Catalog is ingeschakeld voor uw werkruimte.
- Serverloze rekenkracht is beschikbaar in uw werkruimte (standaard ingeschakeld in werkruimten met Unity Catalog). Serverloze Lakeflow-pijplijnen zijn niet beschikbaar in alle werkruimteregio's. Zie Functies met beperkte regionale beschikbaarheid voor beschikbare regio's. Als serverloze berekening niet beschikbaar is, moeten de stappen werken met de standaard rekenkracht voor uw werkruimte.
- Machtiging voor het maken van een rekenresource of toegang tot een rekenresource.
- Machtigingen voor het maken van een nieuw schema in een catalogus. De vereiste machtigingen zijn
USE CATALOGenCREATE SCHEMA. - Machtigingen voor het maken van een nieuw volume in een bestaand schema. De vereiste machtigingen zijn
USE SCHEMAenCREATE VOLUME. - Zie Identiteiten, machtigingen en rechten voor pijplijnen beheren voor de volledige set rechten die vereist zijn om pijplijnen en de uitvoer ervan te maken, uit te voeren, te vernieuwen en weer te geven.
Wijzigingen in gegevens vastleggen in een ETL-pijplijn
Change Data Capture (CDC) is het proces waarmee wijzigingen in records worden vastgelegd die zijn aangebracht in een transactionele database (bijvoorbeeld MySQL of PostgreSQL) of een datawarehouse. CDC legt bewerkingen vast, zoals het verwijderen, toevoegen en bijwerken van gegevens, meestal als een stroom om tabellen in externe systemen opnieuw te materialiseren. CDC maakt incrementeel laden mogelijk terwijl u geen updates bulksgewijs hoeft te laden.
Opmerking
Sla om deze handleiding te vereenvoudigen het instellen van een extern CDC-systeem over. Stel dat cdc-gegevens worden uitgevoerd en opgeslagen als JSON-bestanden in cloudobjectopslag (S3, ADLS of GCS). In deze zelfstudie wordt de Faker bibliotheek gebruikt om de gegevens te genereren die in de zelfstudie worden gebruikt.
CDC vastleggen
Er zijn diverse CDC-hulpprogramma's beschikbaar. Een van de toonaangevende open source oplossingen is Debezium, maar andere implementaties die gegevensbronnen vereenvoudigen, bestaan, zoals Fivetran, Qlik Replicate, StreamSets, Talend, Oracle GoldenGate en AWS DMS.
In deze zelfstudie gebruikt u CDC-gegevens van een extern systeem, zoals Debezium of DMS. Debezium legt elke gewijzigde rij vast. Het verzendt doorgaans de geschiedenis van gegevenswijzigingen naar Kafka-onderwerpen of slaat ze op als bestanden.
U moet de CDC-gegevens opnemen uit de customers tabel (JSON-indeling), controleren of deze juist is en vervolgens de tabel klanten in Lakehouse materialiseren.
CDC-invoer van Debezium
Voor elke wijziging ontvangt u een JSON-bericht met alle velden van de rij die wordt bijgewerkt (id, firstnamelastname, , email). address Het bericht bevat ook aanvullende metagegevens:
-
operation: Een bewerkingscode, meestal (DELETE,APPEND,UPDATE). -
operation_date: De datum en tijdstempel van het record voor elke bewerkingsactie.
Tools zoals Debezium kunnen meer geavanceerde uitvoer produceren, zoals de rijwaarde vóór de wijziging, maar in deze tutorial laten we ze voor de eenvoud achterwege.
Stap 1: Een pijplijn maken
Maak een nieuwe ETL-pijplijn om een query uit te voeren op uw CDC-gegevensbron en tabellen te genereren in uw werkruimte.
Klik in uw werkruimte op
 Nieuw in de zijbalk en selecteer vervolgens ETL-pijplijn. Hiermee opent u de pijplijneditor met een standaardpijplijnnaam, zoals
Nieuw in de zijbalk en selecteer vervolgens ETL-pijplijn. Hiermee opent u de pijplijneditor met een standaardpijplijnnaam, zoals New Pipeline <date> <time>.Selecteer de naam en voer een beschrijvende naam in, zoals
Pipelines with CDC tutorial.Klik rechts van de naam op de catalogus en het schema om standaardinstellingen te kiezen waarvoor u schrijfmachtigingen hebt.
Deze catalogus en dit schema worden standaard gebruikt als u geen catalogus of schema opgeeft in uw code. Uw code kan naar elke catalogus of elk schema schrijven door het volledige pad op te geven. In deze zelfstudie worden de standaardwaarden gebruikt die u hier opgeeft.
(Optioneel) Selecteer in het
my_transformationbronbestand dat voor u is gemaakt Python of SQL in de vervolgkeuzelijst taal om de taal voor het bestand in te stellen.Klik op
 Gebruik voorbeeldcode.
Gebruik voorbeeldcode.
De Lakeflow Pipelines Editor wordt geopend met voorbeeldbestanden in uw pijplijn. U voegt in latere stappen uw eigen transformatiebestanden toe. Stel vervolgens de voorbeeldgegevens in voor import in de handleiding.
Stap 2: De voorbeeldgegevens maken die u in deze zelfstudie wilt importeren
Deze stap is niet nodig als u uw eigen gegevens uit een bestaande bron importeert. Voor deze zelfstudie genereert u valse gegevens als voorbeeld voor de zelfstudie. Maak een notebook om het script voor het genereren van Python gegevens uit te voeren. Deze code hoeft slechts eenmaal te worden uitgevoerd om de voorbeeldgegevens te genereren, dus maak deze in de map van explorations de pijplijn, die niet wordt uitgevoerd als onderdeel van een pijplijnupdate.
Opmerking
Deze code maakt gebruik van Faker om de voorbeeld-CDC-gegevens te genereren. Faker is beschikbaar voor automatische installatie, dus de handleiding maakt gebruik van %pip install faker. U kunt ook een afhankelijkheid van faker instellen voor de notebook. Zie Afhankelijkheden toevoegen aan het notebook.
Klik binnen de Lakeflow Pipelines-editor in de zijbalk van de assetbrowser links van de editor op
Voeg toe en kies Verkennen.Geef het Naam, zoals
Setup data, selecteer Python. U kunt de standaardlocatiemap verlaten. Dit is een nieuweexplorationsmap.Klik op Create. Hiermee maakt u een notitieblok in de nieuwe map.
Voer de volgende code in de eerste cel in. U moet de definitie van
<my_catalog>en<my_schema>aanpassen om overeen te komen met de standaardcatalogus en het standaardschema dat u in de vorige procedure hebt geselecteerd.%pip install faker # Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = dbName = db = "<my_schema>" spark.sql(f'USE CATALOG `{catalog}`') spark.sql(f'USE SCHEMA `{schema}`') spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{db}`.`raw_data`') volume_folder = f"/Volumes/{catalog}/{db}/raw_data" try: dbutils.fs.ls(volume_folder+"/customers") except: print(f"folder doesn't exist, generating the data under {volume_folder}...") from pyspark.sql import functions as F from faker import Faker from collections import OrderedDict import uuid fake = Faker() import random fake_firstname = F.udf(fake.first_name) fake_lastname = F.udf(fake.last_name) fake_email = F.udf(fake.ascii_company_email) fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S")) fake_address = F.udf(fake.address) operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)]) fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0]) fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None) df = spark.range(0, 100000).repartition(100) df = df.withColumn("id", fake_id()) df = df.withColumn("firstname", fake_firstname()) df = df.withColumn("lastname", fake_lastname()) df = df.withColumn("email", fake_email()) df = df.withColumn("address", fake_address()) df = df.withColumn("operation", fake_operation()) df_customers = df.withColumn("operation_date", fake_date()) df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder+"/customers")Als u de gegevensset wilt genereren die in de zelfstudie wordt gebruikt, typt u Shift + Enter om de code uit te voeren:
Optional. Als u een voorbeeld wilt bekijken van de gegevens die in deze zelfstudie worden gebruikt, voert u de volgende code in de volgende cel in en voert u de code uit. Werk de catalogus en het schema bij zodat deze overeenkomen met het pad uit de vorige code.
# Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = "<my_schema>" display(spark.read.json(f"/Volumes/{catalog}/{schema}/raw_data/customers"))
Hiermee wordt een grote gegevensset gegenereerd (met valse CDC-gegevens) die u in de rest van de zelfstudie kunt gebruiken. In de volgende stap neemt u de gegevens op met behulp van automatisch laden.
Stap 3: Incrementeel gegevens opnemen met automatisch laden
De volgende stap is het opnemen van de onbewerkte gegevens uit de (nep) cloudopslag in een bronslaag.
Dit kan om meerdere redenen lastig zijn, omdat u moet:
- Opereren op schaal, met de mogelijkheid om miljoenen kleine bestanden te verwerken.
- Schema en JSON-type afleiden.
- Onjuiste records afhandelen met een onjuist JSON-schema.
- Zorg voor de evolutie van schema's (bijvoorbeeld een nieuwe kolom in de klantentabel).
Auto Loader vereenvoudigt deze opname, inclusief schemadeductie en schemaontwikkeling, terwijl het schalen naar miljoenen binnenkomende bestanden. Automatisch laden is beschikbaar in Python met behulp van cloudFiles en in SQL met behulp van de SELECT * FROM STREAM read_files(...) en kan worden gebruikt met verschillende indelingen (JSON, CSV, Apache Avro, enzovoort):
Het definiëren van de tabel als een streamingtabel garandeert dat u alleen nieuwe binnenkomende gegevens verbruikt. Als u deze niet definieert als een streamingtabel, worden alle beschikbare gegevens gescand en opgenomen. Zie Streamingtabellen voor meer informatie.
Als u de binnenkomende CDC-gegevens wilt opnemen met behulp van automatisch laden, kopieert en plakt u de volgende code in het codebestand dat is gemaakt met uw pijplijn (aangeroepen
my_transformation.pyofmy_transformation.sql). U kunt Python of SQL gebruiken op basis van de taal die u hebt gekozen bij het maken van de pijplijn. Vervang de<catalog>en<schema>door de instellingen die u hebt ingesteld voor de standaardinstelling voor de pijplijn.Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # Replace with the catalog and schema name that # you are using: path = "/Volumes/<catalog>/<schema>/raw_data/customers" # Create the target bronze table dp.create_streaming_table("customers_cdc_bronze", comment="New customer data incrementally ingested from cloud object storage landing zone") # Create an Append Flow to ingest the raw data into the bronze table @dp.append_flow( target = "customers_cdc_bronze", name = "customers_bronze_ingest_flow" ) def customers_bronze_ingest_flow(): return ( spark.readStream .format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.inferColumnTypes", "true") .load(f"{path}") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_bronze_ingest_flow AS INSERT INTO customers_cdc_bronze BY NAME SELECT * FROM STREAM read_files( -- replace with the catalog/schema you are using: "/Volumes/<catalog>/<schema>/raw_data/customers", format => "json", inferColumnTypes => "true" )Klik op
 Voer een bestand of pijplijn uit om een update voor de verbonden pijplijn te starten. Met slechts één bronbestand in uw pijplijn zijn deze functioneel gelijkwaardig.
Voer een bestand of pijplijn uit om een update voor de verbonden pijplijn te starten. Met slechts één bronbestand in uw pijplijn zijn deze functioneel gelijkwaardig.
Wanneer de update is voltooid, wordt de editor bijgewerkt met informatie over uw pijplijn.
- De pijplijngrafiek, ook wel de gerichte acyclische grafiek (DAG) genoemd, in de zijbalk rechts van uw code, toont één tabel,
customers_cdc_bronze. - Een samenvatting van de update wordt boven aan de browser voor pijplijnassets weergegeven.
- Details van de gegenereerde tabel worden weergegeven in het onderste deelvenster en u kunt door gegevens uit de tabel bladeren door deze te selecteren.
Dit zijn de onbewerkte bronslaaggegevens die zijn geïmporteerd uit cloudopslag. In de volgende stap schoont u de gegevens op om een tabel met zilveren lagen te maken.
Stap 4: Opschonen en verwachtingen voor het bijhouden van de gegevenskwaliteit
Nadat de bronslaag is gedefinieerd, maakt u de zilveren laag door verwachtingen toe te voegen om de gegevenskwaliteit te beheren. Controleer de volgende voorwaarden:
- Id mag nooit zijn
null. - Het CDC-bewerkingswijze moet geldig zijn.
- JSON moet correct worden gelezen door Auto Loader.
Rijen die niet aan deze voorwaarden voldoen, worden verwijderd.
Zie Gegevenskwaliteit beheren met de verwachtingen van pijplijnen voor meer informatie.
Klik in de zijbalk van de assetbrowser voor pijplijnen op het
, vervolgens op Toevoegen en daarna op Transformatie.Voer een Name (bijvoorbeeld
customers_silver) in en kies een taal (Python of SQL) voor het broncodebestand. De.pyof.sqlextensie wordt toegevoegd op basis van uw taalkeuze. U kunt talen in een pijplijn combineren en vergelijken, zodat u een van beide talen voor deze stap kunt kiezen.Als u een zilveren laag met een opgeschoonde tabel wilt maken en beperkingen wilt opleggen, kopieert en plakt u de volgende code in het nieuwe bestand (kies Python of SQL op basis van de taal van het bestand).
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table( name = "customers_cdc_clean", expect_all_or_drop = {"no_rescued_data": "_rescued_data IS NULL","valid_id": "id IS NOT NULL","valid_operation": "operation IN ('APPEND', 'DELETE', 'UPDATE')"} ) @dp.append_flow( target = "customers_cdc_clean", name = "customers_cdc_clean_flow" ) def customers_cdc_clean_flow(): return ( spark.readStream.table("customers_cdc_bronze") .select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean ( CONSTRAINT no_rescued_data EXPECT (_rescued_data IS NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_operation EXPECT (operation IN ('APPEND', 'DELETE', 'UPDATE')) ON VIOLATION DROP ROW ) COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_cdc_clean_flow AS INSERT INTO customers_cdc_clean BY NAME SELECT * FROM STREAM customers_cdc_bronze;Klik op
Voer een bestand of pijplijn uit om een update voor de verbonden pijplijn te starten.Omdat er nu twee bronbestanden zijn, doen deze niet hetzelfde, maar in dit geval is de uitvoer hetzelfde.
- Voer de pijplijn uit om uw hele pijplijn uit te voeren, inclusief de code uit stap 3. Als uw invoergegevens zouden worden bijgewerkt, zou dit eventuele wijzigingen van die bron naar uw bronslaag ophalen. Hiermee wordt de code niet uitgevoerd vanuit de stap voor het instellen van gegevens, omdat deze zich in de map verkenningen bevindt en geen deel uitmaakt van de bron voor uw pijplijn.
- Als u het bestand uitvoert , wordt alleen het huidige bronbestand uitgevoerd. In dit geval worden, zonder dat uw invoergegevens worden bijgewerkt, de zilveren gegevens gegenereerd uit de bronstabel in de cache. Het is handig om alleen dit bestand uit te voeren voor snellere iteratie bij het maken of bewerken van uw pijplijncode.
Wanneer de update is voltooid, ziet u dat in de pijplijngrafiek nu twee tabellen worden weergegeven (met de zilveren laag, afhankelijk van de bronslaag) en in het onderste deelvenster ziet u details voor beide tabellen. Boven in de assetbrowser van de pijplijn worden nu de tijden van meerdere runs weergegeven, maar alleen de details van de meest recente run.
Maak vervolgens de uiteindelijke versie van de gouden laag van de customers tabel.
Stap 5: Materieer de klantentabel met een geautomatiseerde CDC-stroom
Tot nu toe hebben de tabellen de CDC-gegevens in elke stap doorgegeven. Maak nu de customers tabel om zowel de meest actuele weergave te bevatten als replica van de oorspronkelijke tabel, en niet de lijst met CDC-bewerkingen die het hebben gemaakt.
Dit is niettrivieel om handmatig te implementeren. U moet factoren zoals deduplicatie van gegevens in overweging nemen om de meest recente rij te behouden.
Pijplijnen lossen deze uitdagingen echter op met de AUTO CDC bewerking.
Klik in de zijbalk van de assetbrowser voor pijplijnen op
Toevoegen en Transformatie.Voer een Name in en kies een taal (Python of SQL) voor het nieuwe broncodebestand. U kunt opnieuw een van beide talen voor deze stap kiezen, maar gebruik de juiste code hieronder.
Als u de CDC-gegevens wilt verwerken met behulp van
AUTO CDC, kopieert en plakt u de volgende code in het nieuwe bestand.Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table(name="customers", comment="Clean, materialized customers") dp.create_auto_cdc_flow( target="customers", # The customer table being materialized source="customers_cdc_clean", # the incoming CDC keys=["id"], # what we'll be using to match the rows to upsert sequence_by=col("operation_date"), # de-duplicate by operation date, getting the most recent value ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), # DELETE condition except_column_list=["operation", "operation_date", "_rescued_data"], )SQL
CREATE OR REFRESH STREAMING TABLE customers; CREATE FLOW customers_cdc_flow AS AUTO CDC INTO customers FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 1;Klik op
Voer het bestand uit om een update voor de verbonden pijplijn te starten.
Wanneer de update is voltooid, ziet u dat in uw pijplijngrafiek drie tabellen worden weergegeven, die van brons naar zilver naar goud gaan.
Stap 6: Updategeschiedenis bijhouden met langzaam veranderend dimensietype 2 (SCD2)
Het is vaak vereist om een tabel te maken die alle wijzigingen bijhoudt die het gevolg zijn van APPEND, UPDATEen DELETE:
- Geschiedenis: U wilt een geschiedenis van alle wijzigingen in de tabel behouden.
- Traceerbaarheid: U wilt zien welke bewerking is uitgevoerd.
SCD2 met Lakeflow-pijplijnen
Delta ondersteunt wijzigingsgegevensstroom (CDF) en table_change kan query's uitvoeren op tabelwijzigingen in SQL en Python. Het belangrijkste gebruiksvoorbeeld van CDF is echter het vastleggen van wijzigingen in een pijplijn, niet om vanaf het begin een volledige weergave van tabelwijzigingen te maken.
Dingen worden veel ingewikkelder om te implementeren als u gebeurtenissen hebt die buiten de volgorde zijn. Als u de wijzigingen moet sequentieereren op basis van een tijdstempel en een wijziging moet ontvangen die in het verleden is gebeurd, moet u een nieuwe vermelding toevoegen aan de SCD-tabel en de vorige vermeldingen bijwerken.
Lakeflow-pijplijnen verwijderen deze complexiteit. U kunt een afzonderlijke tabel maken die alle wijzigingen bevat vanaf het begin van de tijd, die automatisch door de pijplijn wordt onderhouden. Deze tabel ondersteunt optimalisaties van gegevensindelingen, zoals liquid clustering, en verwerkt automatisch out-of-order records op basis van _sequence_by. Zie Liquid Clustering gebruiken voor tabellen.
Als u een SCD2-tabel wilt maken, gebruikt u de optie STORED AS SCD TYPE 2 in SQL of stored_as_scd_type="2" in Python.
Opmerking
U kunt beperken welke kolommen de functie bijhoudt met behulp van de optie: TRACK HISTORY ON {columnList | EXCEPT(exceptColumnList)}
Klik in de zijbalk van de assetbrowser voor pijplijnen op
Toevoegen en Transformatie.Voer een Name in en kies een taal (Python of SQL) voor het nieuwe broncodebestand.
Kopieer en plak de volgende code in het nieuwe bestand.
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # create the table dp.create_streaming_table( name="customers_history", comment="Slowly Changing Dimension Type 2 for customers" ) # store all changes as SCD2 dp.create_auto_cdc_flow( target="customers_history", source="customers_cdc_clean", keys=["id"], sequence_by=col("operation_date"), ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), except_column_list=["operation", "operation_date", "_rescued_data"], stored_as_scd_type="2", ) # Enable SCD2 and store individual updatesSQL
CREATE OR REFRESH STREAMING TABLE customers_history; CREATE FLOW customers_history_cdc AS AUTO CDC INTO customers_history FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 2;Klik op
Voer het bestand uit om een update voor de verbonden pijplijn te starten.
Wanneer de update is voltooid, bevat de pijplijngrafiek de nieuwe customers_history-tabel, die afhankelijk is van de silver layer-tabel, en in het onderste deelvenster worden de details voor alle vier tabellen weergegeven.
Stap 7: Maak een gerealiseerde weergave die bijhoudt wie de informatie het meest heeft gewijzigd
De tabel customers_history bevat alle historische wijzigingen die een gebruiker heeft aangebracht in hun gegevens. Maak een eenvoudige gerealiseerde weergave in de gouden laag die bijhoudt wie de informatie het meest heeft gewijzigd. Dit kan worden gebruikt voor analyse van fraudedetectie of aanbevelingen van gebruikers in een praktijkscenario. Bovendien heeft het toepassen van wijzigingen met SCD2 dubbele waarden al verwijderd, zodat u de rijen rechtstreeks per gebruikers-id kunt tellen.
Klik in de zijbalk van de assetbrowser voor pijplijnen op
Toevoegen en Transformatie.Voer een Name in en kies een taal (Python of SQL) voor het nieuwe broncodebestand.
Kopieer en plak de volgende code in het nieuwe bronbestand.
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * @dp.table( name = "customers_history_agg", comment = "Aggregated customer history" ) def customers_history_agg(): return ( spark.read.table("customers_history") .groupBy("id") .agg( count_distinct("address").alias("address_count"), count_distinct("email").alias("email_count"), count_distinct("firstname").alias("firstname_count"), count_distinct("lastname").alias("lastname_count") ) )SQL
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS SELECT id, count(distinct address) as address_count, count(distinct email) AS email_count, count(distinct firstname) AS firstname_count, count(distinct lastname) AS lastname_count FROM customers_history GROUP BY idKlik op
Voer het bestand uit om een update voor de verbonden pijplijn te starten.
Nadat de update is voltooid, is er een nieuwe tabel in de pijplijngrafiek die afhankelijk is van de customers_history tabel en u kunt deze bekijken in het onderste deelvenster. Uw pijplijn is nu voltooid. U kunt deze testen door een volledige pijplijn uit te voeren. De enige stappen die nog worden uitgevoerd, zijn het plannen van de pijplijn om regelmatig bij te werken.
Stap 8: Een taak maken om de ETL-pijplijn uit te voeren
Maak vervolgens een werkstroom om de stappen voor gegevensopname, verwerking en analyse in uw pijplijn te automatiseren met behulp van een Databricks-taak.
- Kies boven aan de editor de knop Planning .
- Als het dialoogvenster Planningen wordt weergegeven, kiest u Planning toevoegen.
- Hiermee opent u het dialoogvenster Nieuwe planning , waarin u een taak kunt maken om uw pijplijn volgens een planning uit te voeren.
- Geef desgewenst de taak een naam.
- Standaard is de planning ingesteld op één keer per dag. U kunt deze standaardinstelling accepteren of uw eigen planning instellen. Als u Geavanceerd kiest, kunt u een specifieke tijd instellen waarop de taak wordt uitgevoerd. Als u meer opties selecteert, kunt u meldingen maken wanneer de taak wordt uitgevoerd.
- Selecteer Maken om de wijzigingen toe te passen en de taak te maken.
De taak wordt nu dagelijks uitgevoerd om uw pijplijn up-to-date te houden. U kunt Planning opnieuw kiezen om de lijst met planningen weer te geven. U kunt planningen voor uw pijplijn beheren vanuit dat dialoogvenster, inclusief het toevoegen, bewerken of verwijderen van planningen.
Als u op de naam van de planning (of taak) klikt, gaat u naar de pagina van de taak in de lijst taken en pijplijnen . Hier kunt u details bekijken over taakuitvoeringen, inclusief de geschiedenis van uitvoeringen, of de taak direct uitvoeren met de knop Nu uitvoeren .
Zie Monitor Lakeflow-taken voor meer informatie over taakuitvoeringen.