Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Belangrijk
Deze functie is bèta en is beschikbaar in de volgende regio's: us-east-1 en us-west-2.
Met de declaratieve API's van de feature store kunt u vanuit gegevensbronnen tijdvensteraggregatiefuncties definiëren en berekenen. In deze handleiding worden de volgende werkstromen behandeld:
-
Werkstroom voor functieontwikkeling
- Hiermee
create_featuredefinieert u functieobjecten voor Unity Catalog die kunnen worden gebruikt in modeltraining en het leveren van werkstromen.
- Hiermee
-
Werkstroom voor modeltraining
- Gebruik
create_training_setdeze functie om geaggregeerde functies van een bepaald tijdstip voor machine learning te berekenen. Hiermee wordt een trainingssetobject geretourneerd dat een Spark DataFrame met berekende functies kan retourneren die zijn uitgebreid naar de observatiegegevensset voor het trainen van een model. - Aanroepen
log_modelmet deze trainingsset om dit model op te slaan in Unity Catalog, samen met herkomst tussen functie- en modelobjecten. -
score_batchmaakt gebruik van Unity Catalog-herkomst om functiedefinitiecode te gebruiken om juiste functieaggregaties voor een bepaald tijdstip uit te voeren, uitgebreid naar de deductiegegevensset voor het scoren van modellen.
- Gebruik
-
Kenmerk materialisatie en voorziening werkstroom
- Na het definiëren van een kenmerk met
create_featureof het ophalen ervan met behulp vanget_feature, kunt u hetmaterialize_featureskenmerk of de set kenmerken materialiseren naar een offline-winkel voor efficiënt hergebruik of naar een online-winkel voor online-aanbieding. - Gebruik
create_training_setmet de gemaakte weergave om een gegevensset voor offline batchtraining voor te bereiden.
- Na het definiëren van een kenmerk met
Zie voor gedetailleerde documentatie over log_model en score_batch, Functies gebruiken om modellen te trainen.
Requirements
Een klassiek rekencluster met Databricks Runtime 17.0 ML of hoger.
U moet het aangepaste Python-pakket installeren. De volgende regels code moeten worden uitgevoerd telkens wanneer een notebook wordt uitgevoerd:
%pip install databricks-feature-engineering>=0.14.0 dbutils.library.restartPython()
Quickstart-voorbeeld
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering.entities import DeltaTableSource, Sum, Avg, ContinuousWindow, OfflineStoreConfig
from datetime import timedelta
CATALOG_NAME = "main"
SCHEMA_NAME = "feature_store"
TABLE_NAME = "transactions"
# 1. Create data source
source = DeltaTableSource(
catalog_name=CATALOG_NAME,
schema_name=SCHEMA_NAME,
table_name=TABLE_NAME,
entity_columns=["user_id"],
timeseries_column="transaction_time"
)
# 2. Define features
fe = FeatureEngineeringClient()
features = [
fe.create_feature(
catalog_name=CATALOG_NAME,
schema_name=SCHEMA_NAME,
name="avg_transaction_30d",
source=source,
inputs=["amount"],
function=Avg(),
time_window=ContinuousWindow(window_duration=timedelta(days=30))
),
fe.create_feature(
catalog_name=CATALOG_NAME,
schema_name=SCHEMA_NAME,
source=source,
inputs=["amount"],
function=Sum(),
time_window=ContinuousWindow(window_duration=timedelta(days=7))
# name auto-generated: "amount_sum_continuous_7d"
),
]
# 3. Create training set using declarative features
`labeled_df` should have columns "user_id", "transaction_time", and "target". It can have other context features specific to the individual observations.
training_set = fe.create_training_set(
df=labeled_df,
features=features,
label="target",
)
training_set.load_df().display() # action: joins labeled_df with computed feature
# 4. Train model
with mlflow.start_run():
training_df = training_set.load_df()
# training code
fe.log_model(
model=model,
artifact_path="recommendation_model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name=f"{CATALOG_NAME}.{SCHEMA_NAME}.recommendation_model",
)
# 5. (Optional) Materialize features for serving
fe.materialize_features(
features=features,
offline_config=OfflineStoreConfig(
catalog_name=CATALOG_NAME,
schema_name=SCHEMA_NAME,
table_name_prefix="customer_features"
),
pipeline_state="ACTIVE",
cron_schedule="0 0 * * * ?" # Hourly
)
Opmerking
Nadat u functies hebt gerealiseerd, kunt u modellen bedienen met behulp van cpu-modellen. Zie Materialiseer en serveer declaratieve functies voor meer informatie over online serveren.
Gegevensbronnen
DeltaTableSource
Opmerking
Toegestane gegevenstypen voor timeseries_column: TimestampType, DateType. Andere gegevenstypen voor gehele getallen kunnen werken, maar leiden tot verlies in precisie voor tijdvensteraggregaties.
De volgende code toont een voorbeeld met behulp van de main.analytics.user_events tabel uit Unity Catalog:
from databricks.feature_engineering.entities import DeltaTableSource
source = DeltaTableSource(
catalog_name="main", # Catalog name
schema_name="analytics", # Schema name
table_name="user_events", # Table name
entity_columns=["user_id"], # Join keys, used to look up features for an entity
timeseries_column="event_time" # Timestamp for time windows
)
Declaratieve functie-API
create_feature() API
FeatureEngineeringClient.create_feature() biedt uitgebreide validatie en zorgt voor de juiste functieconstructie:
FeatureEngineeringClient.create_feature(
source: DataSource, # Required: DeltaTableSource
inputs: List[str], # Required: List of column names from the source
function: Union[Function, str], # Required: Aggregation function (Sum, Avg, Count, etc.)
time_window: TimeWindow, # Required: TimeWindow for aggregation
catalog_name: str, # Required: The catalog name for the feature
schema_name: str, # Required: The schema name for the feature
name: Optional[str], # Optional: Feature name (auto-generated if omitted)
description: Optional[str], # Optional: Feature description
filter_condition: Optional[str], # Optional: SQL WHERE clause to filter source data
) -> Feature
Parameters:
-
source: De gegevensbron die wordt gebruikt in functieberekening -
inputs: Lijst met kolomnamen uit de bron die moet worden gebruikt als invoer voor aggregatie -
function: de aggregatiefunctie (functie-exemplaar of tekenreeksnaam). Zie de lijst met ondersteunde functies hieronder. -
time_window: Het tijdvenster voor aggregatie (TimeWindow-exemplaar of woordenboek met 'duur' en optionele 'offset') -
catalog_name: De catalogusnaam voor de functie -
schema_name: De schemanaam voor de functie -
name: Optionele functienaam (automatisch gegenereerd indien weggelaten) -
description: Optionele beschrijving van de functie -
filter_condition: Optionele SQL-component WHERE voor het filteren van brongegevens vóór aggregatie. Voorbeeld:"status = 'completed'","transaction" = "Credit" AND "amount > 100"
Retourneert: Een gevalideerd Feature-instance
Verhoogt: ValueError als validatie mislukt
Automatisch gegenereerde namen
Wanneer name wordt weggelaten, volgen namen het patroon: {column}_{function}_{window}. Voorbeeld:
-
price_avg_continuous_1h(gemiddelde prijs van 1 uur) -
transaction_count_continuous_30d_1d(Transactietelling van 30 dagen met een offset van 1 dag vanaf de tijdstempel van de gebeurtenis)
Ondersteunde functies
Opmerking
Alle functies worden toegepast op een tijdvenster voor aggregatie, zoals beschreven in de sectie tijdvensters hieronder.
| Functie | Steno | Description | Voorbeeld van een toepassing |
|---|---|---|---|
Sum() |
"sum" |
Totaal van waarden | Dagelijks app-gebruik per gebruiker in minuten |
Avg() |
"avg", "mean" |
Gemiddelde van waarden | Gemiddelde transactiebedrag |
Count() |
"count" |
Aantal records | Aantal aanmeldingen per gebruiker |
Min() |
"min" |
Minimumwaarde | Laagste hartslag geregistreerd door een draagbaar apparaat |
Max() |
"max" |
Maximale waarde | Maximale aantal keren per sessie |
StddevPop() |
"stddev_pop" |
Standaarddeviatie van populatie | Variabiliteit van dagelijkse transactiehoeveelheid voor alle klanten |
StddevSamp() |
"stddev_samp" |
Voorbeeld van standaarddeviatie | Variabiliteit van klikfrequenties voor advertentiecampagnes |
VarPop() |
"var_pop" |
Afwijking van populatie | Verspreiding van sensormetingen voor IoT-apparaten in een fabriek |
VarSamp() |
"var_samp" |
Voorbeeldvariantie | Verspreiding van filmbeoordelingen over een steekproefgroep |
ApproxCountDistinct(relativeSD=0.05) |
"approx_count_distinct"* |
Geschat unieke aantal | Uniek aantal gekochte artikelen |
ApproxPercentile(percentile=0.95,accuracy=100) |
N/A | Percentiel bij benadering | reactielatentie p95 |
First() |
"first" |
Eerste waarde | Eerste tijdstempel voor aanmelding |
Last() |
"last" |
Laatste waarde | Meest recente aankoopbedrag |
*Functies met parameters gebruiken standaardwaarden wanneer de verkorte notatie voor tekenreeksen wordt toegepast.
In het volgende voorbeeld ziet u functies voor vensteraggregatie die zijn gedefinieerd in dezelfde gegevensbron.
from databricks.feature_engineering.entities import Sum, Avg, Count, Max, ApproxCountDistinct
fe = FeatureEngineeringClient()
sum_feature = fe.create_feature(source=source, inputs=["amount"], function=Sum(), ...)
avg_feature = fe.create_feature(source=source, inputs=["amount"], function=Avg(), ...)
distinct_count = fe.create_feature(
source=source,
inputs=["product_id"],
function=ApproxCountDistinct(relativeSD=0.01),
...
)
Functies met filtervoorwaarden
De declaratieve functie-API's ondersteunen ook het toepassen van een SQL-filter, dat wordt toegepast als een WHERE component in aggregaties. Filters zijn handig bij het werken met grote brontabellen met een superset van gegevens die nodig zijn voor functieberekeningen en minimaliseert de noodzaak voor het maken van afzonderlijke weergaven boven op deze tabellen.
from databricks.feature_engineering.entities import Sum, Count, ContinuousWindow
from datetime import timedelta
# Only aggregate high-value transactions
high_value_sales = fe.create_feature(
catalog_name="main",
schema_name="ecommerce",
source=transactions,
inputs=["amount"],
function=Sum(),
time_window=ContinuousWindow(window_duration=timedelta(days=30)),
filter_condition="amount > 100" # Only transactions over $100
)
# Multiple conditions using SQL syntax
completed_orders = fe.create_feature(
catalog_name="main",
schema_name="ecommerce",
source=orders,
inputs=["order_id"],
function=Count(),
time_window=ContinuousWindow(window_duration=timedelta(days=7)),
filter_condition="status = 'completed' AND payment_method = 'credit_card'"
)
Tijdvensters
Declaratieve API's van kenmerkengineering ondersteunen drie verschillende venstertypen om het terugkijkgedrag te beheren voor op tijdvensters gebaseerde aggregaties: continue, tuimelend en glijdend.
- Doorlopende vensters kijken terug vanaf de gebeurtenistijd. Duur en verschuiving worden expliciet gedefinieerd.
- Tumbling-vensters zijn vaste, niet-overlappende tijdvensters. Elk gegevenspunt behoort tot precies één venster.
- Schuifvensters zijn overlappende en doorlopende tijdvensters met een configureerbaar verschuivingsinterval.
In de volgende afbeelding ziet u hoe ze werken.
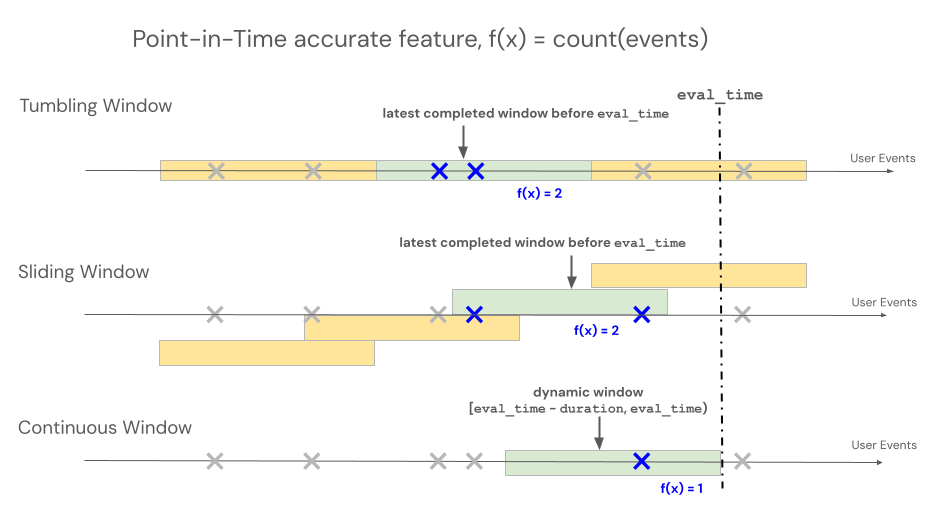
Doorlopend venster
Continue vensters zijn actuele en realtime aggregaten, die doorgaans worden gebruikt voor streaminggegevens. In streaming-pijplijnen wordt in het doorlopende venster alleen een nieuwe rij verzonden wanneer de inhoud van het venster met vaste lengte wordt gewijzigd, bijvoorbeeld wanneer een gebeurtenis binnenkomt of verlaat. Wanneer een functie voor continue vensters wordt gebruikt in trainingspijplijnen, wordt een nauwkeurige functieberekening voor een bepaald tijdstip uitgevoerd op de brongegevens met behulp van de duur van het venster met vaste lengte direct voorafgaand aan de tijdstempel van een specifieke gebeurtenis. Dit helpt het verschil tussen online en offline te voorkomen of lekkage van gegevens te voorkomen. Functies op tijd T aggregeren gebeurtenissen van [T − duur, T).
class ContinuousWindow(TimeWindow):
window_duration: datetime.timedelta
offset: Optional[datetime.timedelta] = None
De volgende tabel bevat de parameters voor een doorlopend venster. De begin- en eindtijden van het venster zijn als volgt gebaseerd op deze parameters:
- Begintijd:
evaluation_time - window_duration + offset(inclusief) - Eindtijd:
evaluation_time + offset(exclusief)
| Kenmerk | Constraints |
|---|---|
offset (optioneel) |
Moet ≤ 0 zijn (hiermee verplaatst u het venster terug in de tijd vanaf de eindtijdstempel). Gebruik offset dit om rekening te houden met eventuele systeemvertragingen tussen het moment dat de gebeurtenis wordt gemaakt en de tijdstempel van de gebeurtenis om toekomstige lekkage van gebeurtenissen in trainingsgegevenssets te voorkomen. Als er bijvoorbeeld een vertraging is van één minuut tussen het moment dat gebeurtenissen worden gecreëerd en het moment waarop deze gebeurtenissen uiteindelijk in een brontabel terechtkomen en daar een tijdstempel krijgen toegewezen, dan zou de offset timedelta(minutes=-1) zijn. |
window_duration |
Moet 0 zijn > |
from databricks.feature_engineering.entities import ContinuousWindow
from datetime import timedelta
# Look back 7 days from evaluation time
window = ContinuousWindow(window_duration=timedelta(days=7))
Definieer een doorlopend venster met offset met behulp van onderstaande code.
# Look back 7 days, but end 1 day ago (exclude most recent day)
window = ContinuousWindow(
window_duration=timedelta(days=7),
offset=timedelta(days=-1)
)
Voorbeelden van doorlopende vensters
window_duration=timedelta(days=7), offset=timedelta(days=0): Hiermee wordt een terugzoekvenster van zeven dagen gemaakt dat eindigt op de huidige evaluatietijd. Voor een evenement om 14:00 uur op dag 7, omvat dit alle gebeurtenissen van 2:00 uur op dag 0 tot (maar niet inclusief) 2:00 uur op dag 7.window_duration=timedelta(hours=1), offset=timedelta(minutes=-30): Hiermee wordt een terugzoekvenster van 1 uur gemaakt dat eindigt op 30 minuten vóór de evaluatietijd. Voor een evenement om 13:00 uur omvat dit alle gebeurtenissen van 13:30 tot (maar niet inclusief) 2:30 uur. Dit is handig om rekening te houden met vertragingen bij gegevensopname.
Tumblingvenster
Voor functies die zijn gedefinieerd door tumbling vensters, worden aggregaties berekend over een vooraf bepaald venster met vaste lengte dat voortgaat met een schuifinterval, waardoor niet-overlappende vensters worden geproduceerd die de tijd volledig opdelen. Als gevolg hiervan draagt elke gebeurtenis in de bron bij aan precies één venster. Functies op het moment t aggregeren gegevens uit vensters die eindigen op of vóór t (exclusief). Windows begint bij het Unix-tijdperk.
class TumblingWindow(TimeWindow):
window_duration: datetime.timedelta
De volgende tabel bevat de parameters voor een tumbling window.
| Kenmerk | Constraints |
|---|---|
window_duration |
Moet 0 zijn > |
from databricks.feature_engineering.entities import TumblingWindow
from datetime import timedelta
window = TumblingWindow(
window_duration=timedelta(days=7)
)
Voorbeeld van een schuivend venster
-
window_duration=timedelta(days=5): Hiermee maakt u vooraf ingestelde vaste-lengte vensters van elk 5 dagen. Voorbeeld: Venster 1 omvat dag 0 tot dag 4, venster 2 omvat dag 5 tot dag 9, venster 3 is dag 10 tot dag 14, enzovoort. In het bijzonder bevat Venster 1 alle gebeurtenissen met tijdstempels vanaf00:00:00.00dag 0 tot (maar niet inclusief) gebeurtenissen met tijdstempel00:00:00.00op dag 5. Elke gebeurtenis behoort tot precies één venster.
Schuifvenster
Voor functies die zijn gedefinieerd met behulp van schuifvensters, worden aggregaties berekend over een vooraf bepaald venster met een vaste lengte dat verschuift met een schuifinterval, waardoor overlappende vensters ontstaan. Elke gebeurtenis in de bron kan bijdragen aan functieaggregatie voor meerdere vensters. Functies op het moment t aggregeren gegevens uit vensters die eindigen op of vóór t (exclusief). Windows begint bij het Unix-tijdperk.
class SlidingWindow(TimeWindow):
window_duration: datetime.timedelta
slide_duration: datetime.timedelta
De volgende tabel bevat de parameters voor een schuifvenster.
| Kenmerk | Constraints |
|---|---|
window_duration |
Moet 0 zijn > |
slide_duration |
Moet 0 zijn > en <window_duration |
from databricks.feature_engineering.entities import SlidingWindow
from datetime import timedelta
window = SlidingWindow(
window_duration=timedelta(days=7),
slide_duration=timedelta(days=1)
)
Voorbeeld van schuifvenster
-
window_duration=timedelta(days=5), slide_duration=timedelta(days=1): Hiermee worden overlappende 5-daagse vensters gemaakt die elke keer met 1 dag vooruitgaan. Voorbeeld: Venster 1 omvat dag 0 tot dag 4, venster 2 omvat dag 1 tot dag 5, venster 3 is dag 2 tot dag 6, enzovoort. Elk venster bevat gebeurtenissen vanaf00:00:00.00de begindag tot (maar niet inclusief)00:00:00.00op de einddag. Omdat vensters elkaar overlappen, kan één gebeurtenis tot meerdere vensters behoren (in dit voorbeeld behoort elke gebeurtenis tot maximaal 5 verschillende vensters).
API-methoden
create_training_set()
Voeg functies toe met gelabelde gegevens voor ML-training:
FeatureEngineeringClient.create_training_set(
df: DataFrame, # DataFrame with training data
features: Optional[List[Feature]], # List of Feature objects
label: Union[str, List[str], None], # Label column name(s)
exclude_columns: Optional[List[str]] = None, # Optional: columns to exclude
# API continues to support creating training set using materialized feature tables and functions
) -> TrainingSet
Aanroep TrainingSet.load_df om oorspronkelijke trainingsgegevens te koppelen aan dynamisch berekende functies in een bepaald tijdstip.
Vereisten voor df argument:
- Moet alle
entity_columnsuit feature-gegevensbronnen bevatten - Moet
timeseries_columnuit functiegegevensbronnen bevatten - Moet labelkolom(en) bevatten
Correctheid van een bepaald tijdstip: Functies worden berekend met alleen brongegevens die beschikbaar zijn vóór de tijdstempel van elke rij, om toekomstige gegevenslekken in modeltraining te voorkomen. Berekeningen maken gebruik van vensterfuncties van Spark voor efficiëntie.
log_model()
Log een model met functiemetadata voor herkomsttracering en automatische functieverificatie tijdens inferentie:
FeatureEngineeringClient.log_model(
model, # Trained model object
artifact_path: str, # Path to store model artifact
flavor: ModuleType, # MLflow flavor module (e.g., mlflow.sklearn)
training_set: TrainingSet, # TrainingSet used for training
registered_model_name: Optional[str], # Optional: register model in Unity Catalog
)
De flavor parameter geeft de module MLflow-modelsmaak op die moet worden gebruikt, zoals mlflow.sklearn of mlflow.xgboost.
Modellen die zijn geregistreerd met een TrainingSet houden automatisch de gegevensherkomst bij naar de kenmerken die in de training worden gebruikt. Zie Functies gebruiken om modellen te trainen voor gedetailleerde documentatie.
score_batch()
Batchinference uitvoeren met automatische kenmerkopzoeking
FeatureEngineeringClient.score_batch(
model_uri: str, # URI of logged model
df: DataFrame, # DataFrame with entity keys and timestamps
) -> DataFrame
score_batch maakt gebruik van de functiemetagegevens die zijn opgeslagen met het model om automatisch tijdspecifieke correcte features voor inference te berekenen, waardoor consistentie met de training wordt gewaarborgd. Zie Functies gebruiken om modellen te trainen voor gedetailleerde documentatie.
Beste praktijken
Naamgeving van functies
- Gebruik beschrijvende namen voor bedrijfskritieke functies.
- Volg consistente naamconventies tussen teams.
- Laat de automatische generatie verkennende functies afhandelen.
Tijdvensters
- Gebruik offsets om instabiele recente gegevens uit te sluiten.
- Venstergrenzen uitlijnen met bedrijfscycli (dagelijks, wekelijks).
- Houd rekening met versheid van gegevens versus functiestabiliteit.
Performance
- Groepeer functies per gegevensbron om gegevensscans te minimaliseren.
- Gebruik de juiste venstergrootten voor uw use-case.
Testing
- Tijdvenstergrenzen testen met bekende gegevensscenario's.
Algemene patronen
Klantanalyse
fe = FeatureEngineeringClient()
features = [
# Recency: Number of transactions in the last day
fe.create_feature(catalog_name="main", schema_name="ecommerce", source=transactions, inputs=["transaction_id"],
function=Count(), time_window=ContinuousWindow(window_duration=timedelta(days=1))),
# Frequency: transaction count over the last 90 days
fe.create_feature(catalog_name="main", schema_name="ecommerce", source=transactions, inputs=["transaction_id"],
function=Count(), time_window=ContinuousWindow(window_duration=timedelta(days=90))),
# Monetary: total spend in the last month
fe.create_feature(catalog_name="main", schema_name="ecommerce", source=transactions, inputs=["amount"],
function=Sum(), time_window=ContinuousWindow(window_duration=timedelta(days=30)))
]
Trendanalyse
# Compare recent vs. historical behavior
fe = FeatureEngineeringClient()
recent_avg = fe.create_feature(
catalog_name="main", schema_name="ecommerce",
source=transactions, inputs=["amount"], function=Avg(),
time_window=ContinuousWindow(window_duration=timedelta(days=7))
)
historical_avg = fe.create_feature(
catalog_name="main", schema_name="ecommerce",
source=transactions, inputs=["amount"], function=Avg(),
time_window=ContinuousWindow(window_duration=timedelta(days=7), offset=timedelta(days=-7))
)
Seizoensgebonden patronen
# Same day of week, 4 weeks ago
fe = FeatureEngineeringClient()
weekly_pattern = fe.create_feature(
catalog_name="main", schema_name="ecommerce",
source=transactions, inputs=["amount"], function=Avg(),
time_window=ContinuousWindow(window_duration=timedelta(days=1), offset=timedelta(weeks=-4))
)
Beperkingen
- Namen van entiteits- en tijdreekskolommen moeten overeenkomen tussen de trainingsgegevensset (gelabelde) en brontabellen wanneer deze worden gebruikt in de
create_training_setAPI. - De kolomnaam die wordt gebruikt als de
labelkolom in de trainingsgegevensset mag niet voorkomen in de brontabellen die worden gebruikt voor het definiëren vanFeatures. - Een beperkte lijst met functies (UDAF's) wordt ondersteund in de
create_featureAPI.