Rekenfuncties op aanvraag met door de gebruiker gedefinieerde Python-functies
In dit artikel wordt beschreven hoe u functies op aanvraag maakt en gebruikt in Azure Databricks.
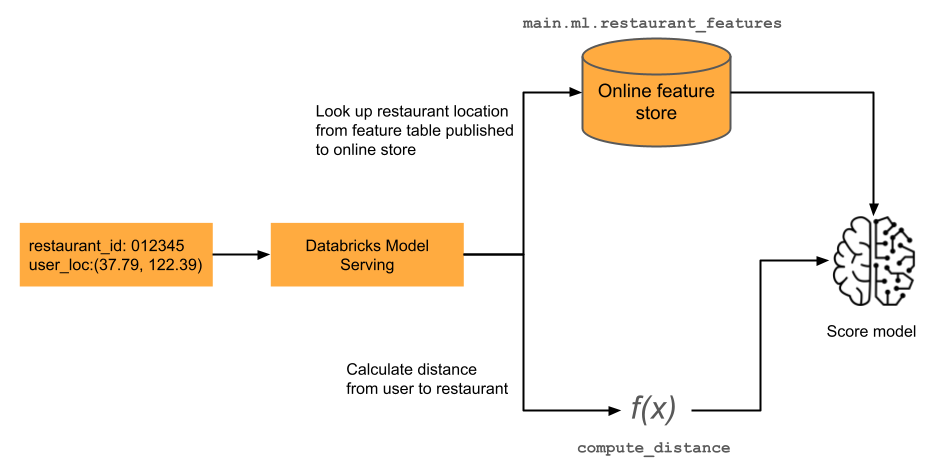
Machine learning-modellen voor realtime toepassingen vereisen vaak de meest recente functiewaarden. In het voorbeeld in het diagram is één functie voor een aanbevelingsmodel voor het restaurant de huidige afstand van de gebruiker van een restaurant. Deze functie moet worden berekend op aanvraag, dat wil gezegd op het moment van de scoreaanvraag. Bij ontvangst van een scoreaanvraag zoekt het model de locatie van het restaurant op en past het vervolgens een vooraf gedefinieerde functie toe om de afstand tussen de huidige locatie van de gebruiker en het restaurant te berekenen. Deze afstand wordt doorgegeven als invoer voor het model, samen met andere vooraf samengestelde functies uit het functiearchief.
Als u functies op aanvraag wilt gebruiken, moet uw werkruimte zijn ingeschakeld voor Unity Catalog en moet u Databricks Runtime 13.3 LTS ML of hoger gebruiken.
Wat zijn functies op aanvraag?
"On-demand" verwijst naar functies waarvan de waarden niet van tevoren bekend zijn, maar worden berekend op het moment van deductie. In Azure Databricks gebruikt u door de gebruiker gedefinieerde Python-functies (UDF's) om op te geven hoe u functies op aanvraag berekent. Deze functies worden beheerd door Unity Catalog en kunnen worden gedetecteerd via Catalog Explorer.
Workflow
Als u functies op aanvraag wilt berekenen, geeft u een door de gebruiker gedefinieerde Python-functie (UDF) op die beschrijft hoe u de functiewaarden berekent.
- Tijdens de training geeft u deze functie en de bijbehorende invoerbindingen op in de
feature_lookupsparameter van decreate_training_setAPI. - U moet het getrainde model registreren met behulp van de methode
log_modelFeature Store. Dit zorgt ervoor dat het model automatisch on-demand functies evalueert wanneer het wordt gebruikt voor deductie. - Voor batchgewijs scoren berekent en retourneert de
score_batchAPI automatisch alle functiewaarden, inclusief functies op aanvraag. - Wanneer u een model gebruikt met Databricks Model Serving, gebruikt het model automatisch de Python UDF om functies op aanvraag te berekenen voor elke scoreaanvraag.
Een Python UDF maken
U kunt een Python UDF maken in een notebook of in Databricks SQL.
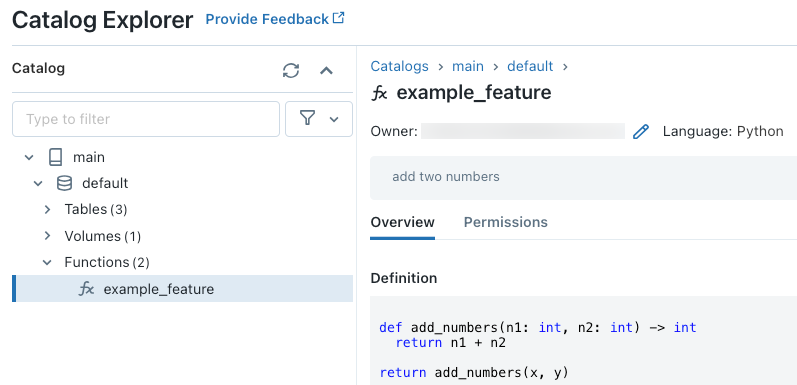
Als u bijvoorbeeld de volgende code uitvoert in een notebookcel, wordt de Python UDF example_feature gemaakt in de catalogus main en het schema default.
%sql
CREATE FUNCTION main.default.example_feature(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int:
return n1 + n2
return add_numbers(x, y)
$$
Nadat u de code hebt uitgevoerd, kunt u door de naamruimte op drie niveaus in Catalog Explorer navigeren om de functiedefinitie weer te geven:
Zie Een Python UDF registreren bij Unity Catalog en de handleiding voor sql-talen voor meer informatie over het maken van Python UDF's.
Ontbrekende functiewaarden verwerken
Wanneer een Python UDF afhankelijk is van het resultaat van een FeatureLookup, is de waarde die wordt geretourneerd als de aangevraagde opzoeksleutel niet wordt gevonden, afhankelijk van de omgeving. Wanneer u deze gebruikt score_batch, is Nonede geretourneerde waarde. Wanneer u online serveren gebruikt, is float("nan")de geretourneerde waarde.
De volgende code is een voorbeeld van het afhandelen van beide gevallen.
%sql
CREATE OR REPLACE FUNCTION square(x INT)
RETURNS INT
LANGUAGE PYTHON AS
$$
import numpy as np
if x is None or np.isnan(x):
return 0
return x * x
$$
Een model trainen met behulp van functies op aanvraag
Als u het model wilt trainen, gebruikt u een FeatureFunction, die wordt doorgegeven aan de create_training_set API in de feature_lookups parameter.
In de volgende voorbeeldcode wordt de Python UDF main.default.example_feature gebruikt die in de vorige sectie is gedefinieerd.
# Install databricks-feature-engineering first with:
# %pip install databricks-feature-engineering
# dbutils.library.restartPython()
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering import FeatureFunction, FeatureLookup
from sklearn import linear_model
fe = FeatureEngineeringClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureEngineeringClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fe.create_training_set(
df=base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
Het model registreren en registreren bij Unity Catalog
Modellen die zijn verpakt met functiemetagegevens kunnen worden geregistreerd bij Unity Catalog. De functietabellen die worden gebruikt om het model te maken, moeten worden opgeslagen in Unity Catalog.
Om ervoor te zorgen dat het model automatisch functies op aanvraag evalueert wanneer het wordt gebruikt voor deductie, moet u de register-URI instellen en vervolgens het model als volgt registreren:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
Als de Python UDF waarmee de on-demand-functies worden gedefinieerd, python-pakketten importeert, moet u deze pakketten opgeven met behulp van het argument extra_pip_requirements. Voorbeeld:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
Beperking
Functies op aanvraag kunnen alle gegevenstypen uitvoeren die worden ondersteund door Feature Store , behalve MapType en ArrayType.
Notebookvoorbeelden: Functies op aanvraag
In het volgende notebook ziet u een voorbeeld van het trainen en beoordelen van een model dat gebruikmaakt van een functie op aanvraag.
Demonotitieblok met basisfuncties op aanvraag
In het volgende notebook ziet u een voorbeeld van een aanbevelingsmodel voor restaurants. De locatie van het restaurant wordt opgezoekd vanuit een online tabel van Databricks. De huidige locatie van de gebruiker wordt verzonden als onderdeel van de scoreaanvraag. Het model maakt gebruik van een functie op aanvraag om de realtime afstand van de gebruiker naar het restaurant te berekenen. Die afstand wordt vervolgens gebruikt als invoer voor het model.
Restaurantaanbevelingsfuncties op aanvraag met behulp van een demonotitieblok voor onlinetabellen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor