Werken met functietabellen in werkruimtefunctiearchief
Notitie
In deze documentatie wordt het archief met werkruimtefuncties behandeld. Databricks raadt aan om functie-engineering te gebruiken in Unity Catalog. Werkruimtefunctiearchief wordt in de toekomst afgeschaft.
Op deze pagina wordt beschreven hoe u functietabellen maakt en gebruikt in de werkruimtefunctieopslag.
Notitie
Als uw werkruimte is ingeschakeld voor Unity Catalog, is elke tabel die wordt beheerd door Unity Catalog met een primaire sleutel automatisch een functietabel die u kunt gebruiken voor modeltraining en -deductie. Alle Unity Catalog-mogelijkheden, zoals beveiliging, herkomst, taggen en toegang tot meerdere werkruimten, zijn automatisch beschikbaar voor de functietabel. Zie Werken met functietabellen voor meer informatie over het werken met functietabellen in een werkruimte met Unity Catalog.
Zie Functies ontdekken en functieherkomst bijhouden voor informatie over het bijhouden van functieherkomsten en het bijhouden van functieherkomsten.
Notitie
Namen van database- en functietabellen kunnen alleen alfanumerieke tekens en onderstrepingstekens (_) bevatten.
Een database voor functietabellen maken
Voordat u functietabellen maakt, moet u een database maken om ze op te slaan.
%sql CREATE DATABASE IF NOT EXISTS <database-name>
Functietabellen worden opgeslagen als Delta-tabellen. Wanneer u een functietabel maakt met create_table (Feature Store-client v0.3.6 en hoger) of create_feature_table (v0.3.5 en lager), moet u de databasenaam opgeven. Met dit argument maakt u bijvoorbeeld een Delta-tabel met de naam customer_features in de database recommender_system.
name='recommender_system.customer_features'
Wanneer u een functietabel publiceert naar een online winkel, zijn de standaardtabel en databasenaam de tabelnaam die u hebt opgegeven bij het maken van de tabel; u kunt verschillende namen opgeven met behulp van de publish_table methode.
In de gebruikersinterface van Databricks Feature Store ziet u de naam van de tabel en database in het onlinearchief, samen met andere metagegevens.
Een functietabel maken in Databricks Feature Store
Notitie
U kunt ook een bestaande Delta-tabel registreren als een functietabel. Zie Een bestaande Delta-tabel registreren als een functietabel.
De basisstappen voor het maken van een functietabel zijn:
- Schrijf de Python-functies om de functies te berekenen. De uitvoer van elke functie moet een Apache Spark DataFrame met een unieke primaire sleutel zijn. De primaire sleutel kan bestaan uit een of meer kolommen.
- Maak een functietabel door een exemplaar te maken van een
FeatureStoreClienten gebruikcreate_table(v0.3.6 en hoger) ofcreate_feature_table(v0.3.5 en lager). - Vul de functietabel in met behulp van
write_table.
Zie de Naslaginformatie over de Python-API voor feature store voor meer informatie over de opdrachten en parameters die in de volgende voorbeelden worden gebruikt.
V0.3.6 en hoger
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
name='recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_table call
# customer_feature_table = fs.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
V0.3.5 en lager
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
Een bestaande Delta-tabel registreren als een functietabel
Met v0.3.8 en hoger kunt u een bestaande Delta-tabel registreren als functietabel. De Delta-tabel moet aanwezig zijn in de metastore.
Notitie
Als u een geregistreerde functietabel wilt bijwerken, moet u de Python-API van de Feature Store gebruiken.
fs.register_table(
delta_table='recommender.customer_features',
primary_keys='customer_id',
description='Customer features'
)
Toegang tot functietabellen beheren
Zie Toegang tot functietabellen beheren.
Een functietabel bijwerken
U kunt een functietabel bijwerken door nieuwe functies toe te voegen of door specifieke rijen te wijzigen op basis van de primaire sleutel.
De volgende metagegevens van de functietabel kunnen niet worden bijgewerkt:
- Primaire sleutel
- Partitiesleutel
- Naam of type van een bestaande functie
Nieuwe functies toevoegen aan een bestaande functietabel
U kunt op twee manieren nieuwe functies toevoegen aan een bestaande functietabel:
- Werk de bestaande functie voor functieberekening bij en voer deze uit
write_tablemet het geretourneerde DataFrame. Hiermee wordt het schema van de functietabel bijgewerkt en worden nieuwe functiewaarden samengevoegd op basis van de primaire sleutel. - Maak een nieuwe functie voor functieberekening om de nieuwe functiewaarden te berekenen. Het DataFrame dat door deze nieuwe rekenfunctie wordt geretourneerd, moet de primaire sleutels en partitiesleutels van de functietabellen bevatten (indien gedefinieerd). Voer
write_tableuit met het DataFrame om de nieuwe functies naar de bestaande functietabel te schrijven, met behulp van dezelfde primaire sleutel.
Alleen specifieke rijen in een functietabel bijwerken
Gebruiken mode = "merge" in write_table. Rijen waarvan de primaire sleutel niet bestaat in het DataFrame dat in de write_table aanroep wordt verzonden, blijven ongewijzigd.
fs.write_table(
name='recommender.customer_features',
df = customer_features_df,
mode = 'merge'
)
Een taak plannen om een functietabel bij te werken
Om ervoor te zorgen dat functies in functietabellen altijd de meest recente waarden hebben, raadt Databricks u aan een taak te maken waarmee een notebook wordt uitgevoerd om uw functietabel regelmatig bij te werken, zoals elke dag. Als u al een niet-geplande taak hebt gemaakt, kunt u deze converteren naar een geplande taak om ervoor te zorgen dat de functiewaarden altijd up-to-date zijn.
Code voor het bijwerken van een functietabel gebruikt mode='merge', zoals wordt weergegeven in het volgende voorbeeld.
fs = FeatureStoreClient()
customer_features_df = compute_customer_features(data)
fs.write_table(
df=customer_features_df,
name='recommender_system.customer_features',
mode='merge'
)
Eerdere waarden van dagelijkse functies opslaan
Definieer een functietabel met een samengestelde primaire sleutel. Neem de datum op in de primaire sleutel. Voor een functietabel store_purchaseskunt u bijvoorbeeld een samengestelde primaire sleutel (date, user_id) en partitiesleutel date gebruiken voor efficiënte leesbewerkingen.
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
Vervolgens kunt u code maken om te lezen uit de functietabelfiltering date naar de gewenste periode.
U kunt ook een tijdreeksfunctietabel maken door de date kolom op te geven als een tijdstempelsleutel met behulp van het timestamp_keys argument.
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
timestamp_keys=['date'],
schema=customer_features_df.schema,
description='Customer timeseries features'
)
Hiermee schakelt u opzoekacties naar een bepaald tijdstip in wanneer u deze gebruikt create_training_set of score_batch. Het systeem voert een tijdstempeldeelname uit met behulp van de timestamp_lookup_key opgegeven tijdstempel.
Als u de functietabel up-to-date wilt houden, stelt u een regelmatig geplande taak in om functies te schrijven of streamt u nieuwe functiewaarden naar de functietabel.
Een pijplijn voor het berekenen van streamingfuncties maken om functies bij te werken
Als u een berekeningspijplijn voor streamingfuncties wilt maken, geeft u een streaming DataFrame door als argument aan write_table. Deze methode retourneert een StreamingQuery-object.
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass # not shown
customer_transactions = spark.readStream.load("dbfs:/events/customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fs.write_table(
df=stream_df,
name='recommender_system.customer_features',
mode='merge'
)
Lezen uit een functietabel
Gebruik read_table deze optie om functiewaarden te lezen.
fs = feature_store.FeatureStoreClient()
customer_features_df = fs.read_table(
name='recommender.customer_features',
)
Functietabellen zoeken en bladeren
Gebruik de gebruikersinterface van Feature Store om functietabellen te zoeken of te doorzoeken.
Selecteer in de zijbalk Machine Learning > Feature Store om de gebruikersinterface van de functieopslag weer te geven.
Voer in het zoekvak de naam van een functietabel, een functie of een gegevensbron in die wordt gebruikt voor functieberekening. U kunt ook alle of een deel van de sleutel of waarde van een tag invoeren. Zoektekst is niet hoofdlettergevoelig.

Metagegevens van functietabel ophalen
De API voor het ophalen van metagegevens van functietabellen is afhankelijk van de Databricks Runtime-versie die u gebruikt. Gebruik bij v0.3.6 en hoger get_table. Gebruik v0.3.5 en lager get_feature_table.
# this example works with v0.3.6 and above
# for v0.3.5, use `get_feature_table`
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.get_table("feature_store_example.user_feature_table")
Werken met functietabeltags
Tags zijn sleutel-waardeparen die u kunt maken en gebruiken om functietabellen te zoeken. U kunt tags maken, bewerken en verwijderen met behulp van de gebruikersinterface van de Feature Store of de Python-API van de Feature Store.
Werken met functietabeltags in de gebruikersinterface
Gebruik de gebruikersinterface van Feature Store om functietabellen te zoeken of te doorzoeken. Selecteer Machine Learning > Feature Store in de zijbalk om toegang te krijgen tot de gebruikersinterface.
Een tag toevoegen met behulp van de gebruikersinterface van de Feature Store
Klik
 als deze nog niet is geopend. De tabel tags wordt weergegeven.
als deze nog niet is geopend. De tabel tags wordt weergegeven.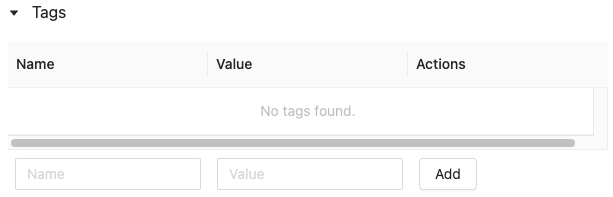
Klik in de velden Naam en Waarde en voer de sleutel en waarde voor uw tag in.
Klik op Toevoegen.
Een tag bewerken of verwijderen met behulp van de gebruikersinterface van feature store
Als u een bestaande tag wilt bewerken of verwijderen, gebruikt u de pictogrammen in de kolom Acties .
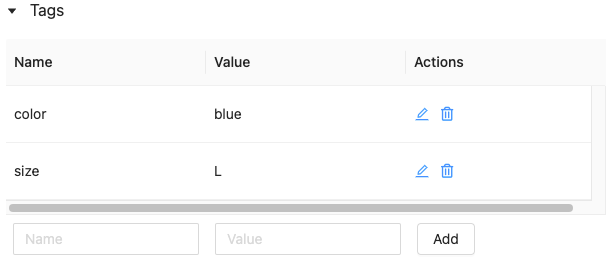
Werken met functietabeltags met behulp van de Python-API van de Feature Store
Op clusters met v0.4.1 en hoger kunt u tags maken, bewerken en verwijderen met behulp van de Python-API van de Feature Store.
Vereisten
Feature Store-client v0.4.1 en hoger
Functietabel met tag maken met behulp van de Python-API van de Feature Store
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
...
)
Tags toevoegen, bijwerken en verwijderen met behulp van de Python-API van de Feature Store
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Upsert a tag
fs.set_feature_table_tag(table_name="my_table", key="quality", value="gold")
# Delete a tag
fs.delete_feature_table_tag(table_name="my_table", key="quality")
Gegevensbronnen voor een functietabel bijwerken
In het functiearchief worden automatisch de gegevensbronnen bijgehouden die worden gebruikt voor het berekenen van functies. U kunt de gegevensbronnen ook handmatig bijwerken met behulp van de Python-API van de Feature Store.
Vereisten
Feature Store-client v0.5.0 en hoger
Gegevensbronnen toevoegen met behulp van de Python-API van de Feature Store
Hieronder ziet u enkele voorbeeldopdrachten. Zie de API-documentatie voor meer informatie.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Use `source_type="table"` to add a table in the metastore as data source.
fs.add_data_sources(feature_table_name="clicks", data_sources="user_info.clicks", source_type="table")
# Use `source_type="path"` to add a data source in path format.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="dbfs:/FileStore/user_metrics.json", source_type="path")
# Use `source_type="custom"` if the source is not a table or a path.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="user_metrics.txt", source_type="custom")
Gegevensbronnen verwijderen met behulp van de Python-API van de Feature Store
Zie de API-documentatie voor meer informatie.
Notitie
Met de volgende opdracht worden gegevensbronnen van alle typen ('tabel', 'pad' en 'aangepast') verwijderd die overeenkomen met de bronnamen.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.delete_data_sources(feature_table_name="clicks", sources_names="user_info.clicks")
Een functietabel verwijderen
U kunt een functietabel verwijderen met behulp van de gebruikersinterface van de Feature Store of de Python-API van de Feature Store.
Notitie
- Het verwijderen van een functietabel kan leiden tot onverwachte fouten in upstream-producenten en downstreamgebruikers (modellen, eindpunten en geplande taken). U moet gepubliceerde online winkels verwijderen bij uw cloudprovider.
- Wanneer u een functietabel verwijdert met behulp van de API, wordt de onderliggende Delta-tabel ook verwijderd. Wanneer u een functietabel uit de gebruikersinterface verwijdert, moet u de onderliggende Delta-tabel afzonderlijk verwijderen.
Een functietabel verwijderen met behulp van de gebruikersinterface
Klik
 op de pagina functietabel rechts van de naam van de functietabel en selecteer Verwijderen. Als u geen machtiging CAN MANAGE voor de functietabel hebt, ziet u deze optie niet.
op de pagina functietabel rechts van de naam van de functietabel en selecteer Verwijderen. Als u geen machtiging CAN MANAGE voor de functietabel hebt, ziet u deze optie niet.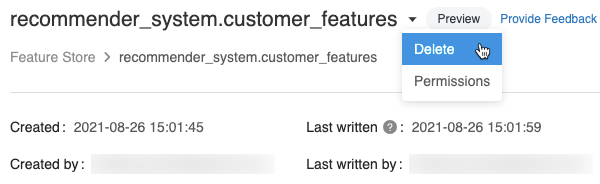
Klik in het dialoogvenster Functietabel verwijderen op Verwijderen om te bevestigen.
Als u ook de onderliggende Delta-tabel wilt verwijderen, voert u de volgende opdracht uit in een notebook.
%sql DROP TABLE IF EXISTS <feature-table-name>;
Een functietabel verwijderen met behulp van de Python-API van de Feature Store
Met Feature Store-client v0.4.1 en hoger kunt drop_table u een functietabel verwijderen. Wanneer u een tabel verwijdert, drop_tablewordt de onderliggende Delta-tabel ook verwijderd.
fs.drop_table(
name='recommender_system.customer_features'
)
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor