INGEREGELDE doorvoercapaciteit voor Foundation-API's
Dit artikel laat zien hoe u modellen implementeert met behulp van Foundation Model-API's met geconfigureerde doorvoer. Databricks raadt ingestelde doorvoer aan voor productieworkloads en biedt geoptimaliseerde invoerverwerking voor basismodellen met prestatiegaranties.
Wat is geconfigureerde doorvoer?
Geconfigureerde doorvoer verwijst naar het aantal toekens voor verzoeken dat u tegelijkertijd naar een endpoint kunt verzenden. Geconfigureerde doorvoer-eindpunten zijn speciale eindpunten die zijn ingesteld voor een bereik van tokens per seconde dat u naar het eindpunt kunt verzenden.
Zie de volgende bronnen voor meer informatie:
- Wat betekenen tokens per seconde bereik in geconfigureerde doorvoercapaciteit?
- uw eigen LLM-eindpuntbenchmarking uitvoeren
Zie Ingerichte doorvoer voor een lijst met ondersteunde modelarchitecturen voor ingerichte doorvoereindpunten.
Eisen
Zie de vereisten. Zie Nauwkeurig afgestemde basismodellen implementerenvoor het implementeren van nauwkeurig afgestemde basismodellen.
[Aanbevolen] Basismodellen implementeren vanuit Unity Catalog
Belangrijk
Deze functie bevindt zich in openbare preview-versie.
Databricks raadt aan de basismodellen te gebruiken die vooraf zijn geïnstalleerd in Unity Catalog. U vindt deze modellen onder de catalogus system in het schema ai (system.ai).
Een basismodel implementeren:
- Navigeer naar
system.aiin Catalog Explorer. - Klik op de naam van het model dat u wilt implementeren.
- Klik op de modelpagina op de knop Dit model inzetten.
- De pagina Een service-eindpunt maken wordt weergegeven. Zie Uw ingerichte doorvoereindpunt maken met behulp van de gebruikersinterface.
Basismodellen implementeren vanuit Databricks Marketplace
U kunt ook basismodellen installeren in Unity Catalog vanuit Databricks Marketplace.
U kunt zoeken naar een modelfamilie en op de modelpagina de optie Toegang krijgen selecteren. Vervolgens kunt u uw logingegevens invoeren om het model in Unity Catalog te installeren.
Nadat het model is geïnstalleerd in Unity Catalog, kunt u een modelservingeindpunt maken bij gebruik van de gebruikersinterface voor bediening.
DBRX-modellen implementeren
Databricks raadt aan het DBRX Instruct-model voor uw workloads te gebruiken. Als u het DBRX Instruct-model wilt gebruiken met behulp van ingerichte doorvoer, volgt u de richtlijnen in [Aanbevolen] Basismodellen implementeren vanuit Unity Catalog.
Bij het leveren van deze DBRX-modellen ondersteunt de ingerichte doorvoer een contextlengte van maximaal 16.000.
DBRX-modellen gebruiken de volgende standaardsysteemprompt om relevantie en nauwkeurigheid in modelreacties te garanderen:
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
Fijn afgestelde basismodellen implementeren
Als u de modellen in het system.ai schema niet kunt gebruiken of modellen kunt installeren vanuit De Databricks Marketplace, kunt u een verfijnd basismodel implementeren door het in te loggen op Unity Catalog. Deze sectie en de volgende secties laten zien hoe u uw code instelt om een MLflow-model te registreren bij Unity Catalog en uw ingerichte doorvoereindpunt te maken met behulp van de gebruikersinterface of de REST API.
Zie Ingerichte doorvoerlimieten voor de ondersteunde Meta Llama 3.1-, 3.2- en 3.3-modellen en de beschikbaarheid van hun regio's.
Eisen
- Het implementeren van nauwkeurig afgestemde basismodellen wordt alleen ondersteund door MLflow 2.11 of hoger. Databricks Runtime 15.0 ML en hoger installeert de compatibele MLflow-versie vooraf.
- Databricks raadt het gebruik van modellen in Unity Catalog aan voor een snellere upload en download van grote modellen.
Definieer catalogusnaam, schemanaam en modelnaam
Als u een nauwkeurig afgestemd basismodel wilt implementeren, definieert u de doelcatalogus, het schema en de modelnaam van uw keuze.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Uw model registreren
Als u de geconfigureerde doorvoer voor uw modeleindpunt wilt inschakelen, registreer uw model dan met behulp van de MLflow-transformers-variant en specificeer het task-argument met de juiste modeltype-interface uit de volgende opties:
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
Met deze argumenten geeft u de API-handtekening op die wordt gebruikt voor het eindpunt van het model. Raadpleeg de documentatie voor MLflow voor meer informatie over deze taken en bijbehorende invoer-/uitvoerschema's.
Hier volgt een voorbeeld van hoe je een taalmodel voor tekstvoltooiing kunt vastleggen met MLflow:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mixtral-8x7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mixtral-8x7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency.
save_pretrained=False
)
Notitie
Als u MLflow eerder dan 2.12 gebruikt, moet u in plaats daarvan de taak opgeven binnen metadata parameter van dezelfde mlflow.transformer.log_model() functie.
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
Ingerichte doorvoer ondersteunt ook zowel de basis- als grote GTE-insluitingsmodellen. Hier volgt een voorbeeld van het registreren van het model Alibaba-NLP/gte-large-en-v1.5, zodat het kan worden aangeboden met geconfigureerde doorvoer.
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
Nadat uw model is geregistreerd in Unity Catalog, gaat u verder met het geprovisioneerde doorvoereindpunt maken met behulp van de gebruikersinterface om een model-serveereindpunt met geprovisioneerde doorvoer te creëren.
Uw ingerichte doorvoereindpunt maken met behulp van de gebruikersinterface
Nadat het vastgelegde model zich in Unity Catalog bevindt, maakt u een geconfigureerd doorvoer-serveeindpunt aan de hand van de volgende stappen:
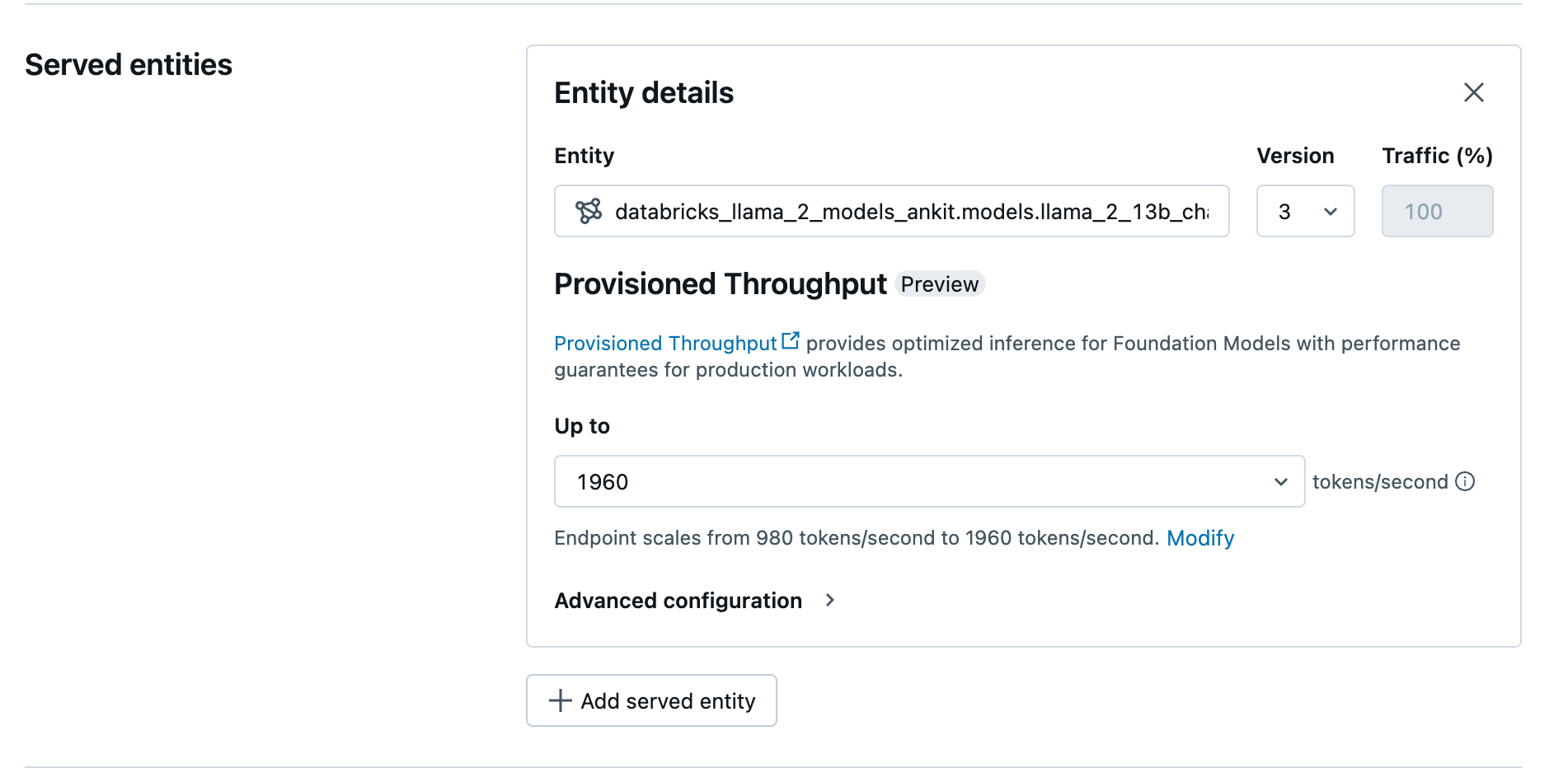
- Navigeer naar de bedieningsinterface in uw werkruimte.
- Selecteer Maak een service-eindpunt.
- Selecteer in het veld Entity uw model in Unity Catalog. Voor in aanmerking komende modellen toont de gebruikersinterface van de bediende entiteit het scherm Geconfigureerde doorvoer.
- In de vervolgkeuzelijst Maximaal kunt u de maximale verwerkingscapaciteit in tokens per seconde voor uw eindpunt configureren.
- Ingerichte doorvoereindpunten worden automatisch geschaald, zodat u Wijzigen kunt selecteren om het minimale aantal tokens per seconde te bekijken waar uw eindpunt naar kan worden afgeschaald.
Uw ingerichte doorvoereindpunt maken met behulp van de REST API
Als u uw model wilt implementeren in de ingerichte doorvoermodus met behulp van de REST API, moet u min_provisioned_throughput en max_provisioned_throughput velden in uw aanvraag opgeven. Als u de voorkeur geeft aan Python, kunt u ook een eindpunt maken met behulp van de MLflow Deployment SDK.
Zie Ingerichte doorvoer in stappenom het geschikte bereik van ingerichte doorvoer voor uw model te identificeren.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Log-kans voor chatvoltooiingstaken
Voor chatvoltooiingstaken kunt u de parameter logprobs gebruiken om de logkans aan te geven van het bemonsteren van een token in het kader van het proces voor het genereren van een groot taalmodel. U kunt logprobs gebruiken voor verschillende scenario's, waaronder classificatie, beoordeling van model onzekerheid en het uitvoeren van metrische evaluatiegegevens. Zie chattaak voor parameterdetails.
toegewezen doorvoer in gradaties ophalen
Voorziene doorvoer is beschikbaar in eenheden van tokens per seconde, waarbij de specifieke eenheden per model variëren. Om het geschikte bereik voor uw behoeften te identificeren, raadt Databricks aan om de API voor modeloptimalisatie-informatie binnen het platform te gebruiken.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
Hier volgt een voorbeeldantwoord van de API:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Notebook-voorbeelden
De volgende notebooks geven voorbeelden van het maken van een toegewezen doorvoer Foundation Model-API.
Beschikbare doorvoer voor GTE-modelnotebook
Ingerichte doorvoer voor BGE-modelnotebook
In het volgende notebook ziet u hoe u het gedestilleerde Llama-model DeepSeek R1 in Unity Catalog kunt downloaden en registreren, zodat u het kunt implementeren via een geconfigureerd throughput-endpoint van Foundation Model APIs.
Ingerichte doorvoer voor het DeepSeek R1 gedistilleerde Llama-modelnotebook
Beperkingen
- Modelimplementatie kan mislukken vanwege problemen met GPU-capaciteit, wat resulteert in een time-out tijdens het maken of bijwerken van het eindpunt. Neem contact op met uw Databricks-accountteam om het probleem op te lossen.
- Automatisch schalen voor Foundation Models API's is langzamer dan het serveren van CPU-modellen. Databricks raadt overprovisionering aan om aanvraag time-outs te voorkomen.
- GTE v1.5 (Engels) genereert geen genormaliseerde insluitingen.