Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel wordt beschreven hoe u MLOps op het Databricks-platform kunt gebruiken om de prestaties en langetermijnefficiëntie van uw MACHINE Learning-systemen (ML) te optimaliseren. Het bevat algemene aanbevelingen voor een MLOps-architectuur en beschrijft een gegeneraliseerde werkstroom met behulp van het Databricks-platform dat u als model voor uw ML-ontwikkelingsproces kunt gebruiken. Zie LLMOps-werkstromen voor wijzigingen van deze werkstroom voor LLMOps-toepassingen.
Zie The Big Book of MLOps voor meer informatie.
Wat is MLOps?
MLOps is een set processen en geautomatiseerde stappen voor het beheren van code, gegevens en modellen om de prestaties, stabiliteit en de efficiëntie van ML-systemen op lange termijn te verbeteren. Het combineert DevOps, DataOps en ModelOps.
ML-assets, zoals code, gegevens en modellen, worden in fasen ontwikkeld die vooruitgang boeken van vroege ontwikkelingsfasen die geen strikte toegangsbeperkingen hebben en niet grondig worden getest, via een tussenliggende testfase, tot een definitieve productiefase die nauw wordt beheerd. Met het Databricks-platform kunt u deze assets op één platform beheren met geïntegreerd toegangsbeheer. U kunt gegevenstoepassingen en ML-toepassingen op hetzelfde platform ontwikkelen, waardoor de risico's en vertragingen met betrekking tot het verplaatsen van gegevens worden verminderd.
Algemene aanbevelingen voor MLOps
Deze sectie bevat enkele algemene aanbevelingen voor MLOps op Databricks met koppelingen voor meer informatie.
Een afzonderlijke omgeving maken voor elke fase
Een uitvoeringsomgeving is de plaats waar modellen en gegevens worden gemaakt of gebruikt door code. Elke uitvoeringsomgeving bestaat uit rekeninstanties, hun runtimes en bibliotheken en geautomatiseerde taken.
Databricks raadt aan afzonderlijke omgevingen te maken voor de verschillende fasen van ML-code- en modelontwikkeling met duidelijk gedefinieerde overgangen tussen fasen. De werkstroom die in dit artikel wordt beschreven, volgt dit proces, met behulp van de algemene namen voor de fasen:
Andere configuraties kunnen ook worden gebruikt om te voldoen aan de specifieke behoeften van uw organisatie.
Toegangsbeheer en versiebeheer
Toegangsbeheer en versiebeheer zijn belangrijke onderdelen van elk softwarebewerkingsproces. Databricks raadt het volgende aan:
- Gebruik Git voor versiebeheer. Pijplijnen en code moeten worden opgeslagen in Git voor versiebeheer. Het verplaatsen van ML-logica tussen fasen kan vervolgens worden geïnterpreteerd als het verplaatsen van code van de ontwikkelingsvertakking, naar de faseringsvertakking, naar de releasevertakking. Gebruik Databricks Git-mappen om te integreren met uw Git-provider en notebooks en broncode te synchroniseren met Databricks-werkruimten. Databricks biedt ook extra hulpprogramma's voor Git-integratie en versiebeheer; zie lokale ontwikkelhulpprogramma's.
- Sla gegevens op in een lakehouse-architectuur met behulp van Delta-tabellen. Gegevens moeten worden opgeslagen in een lakehouse-architectuur in uw cloudaccount. Zowel onbewerkte gegevens- als functietabellen moeten worden opgeslagen als Delta-tabellen met toegangsbeheer om te bepalen wie deze kan lezen en wijzigen.
- Modelontwikkeling beheren met MLflow. U kunt MLflow- gebruiken om het ontwikkelingsproces van het model bij te houden en codemomentopnamen, modelparameters, metrische gegevens en andere metagegevens op te slaan.
- Gebruik modellen in Unity Catalog om de levenscyclus van het model te beheren. Gebruik modellen in Unity Catalog om de status van modelversiebeheer, governance en implementatie te beheren.
Code implementeren, niet modellen
In de meeste gevallen raadt Databricks aan dat u tijdens het ML-ontwikkelingsproces code promoveert in plaats van modellen, van de ene omgeving naar de andere. Door projectassets op deze manier te verplaatsen, zorgt u ervoor dat alle code in het ML-ontwikkelingsproces dezelfde processen voor codebeoordeling en integratietests doorloopt. Het zorgt er ook voor dat de productieversie van het model wordt getraind op productiecode. Zie Modelimplementatiepatronen voor een gedetailleerdere bespreking van de opties en afwegingen.
Aanbevolen MLOps-werkstroom
In de volgende secties wordt een typische MLOps-werkstroom beschreven, waarin elk van de drie fasen wordt beschreven: ontwikkeling, fasering en productie.
In deze sectie worden de termen 'data scientist' en 'ML engineer' gebruikt als archetypische persona's; specifieke rollen en verantwoordelijkheden in de MLOps-werkstroom variëren tussen teams en organisaties.
Ontwikkelingsfase
De focus van de ontwikkelingsfase is experimenteren. Gegevenswetenschappers ontwikkelen functies en modellen en voeren experimenten uit om de modelprestaties te optimaliseren. De uitvoer van het ontwikkelingsproces is ML-pijplijncode die functieberekening, modeltraining, deductie en bewaking kan omvatten.
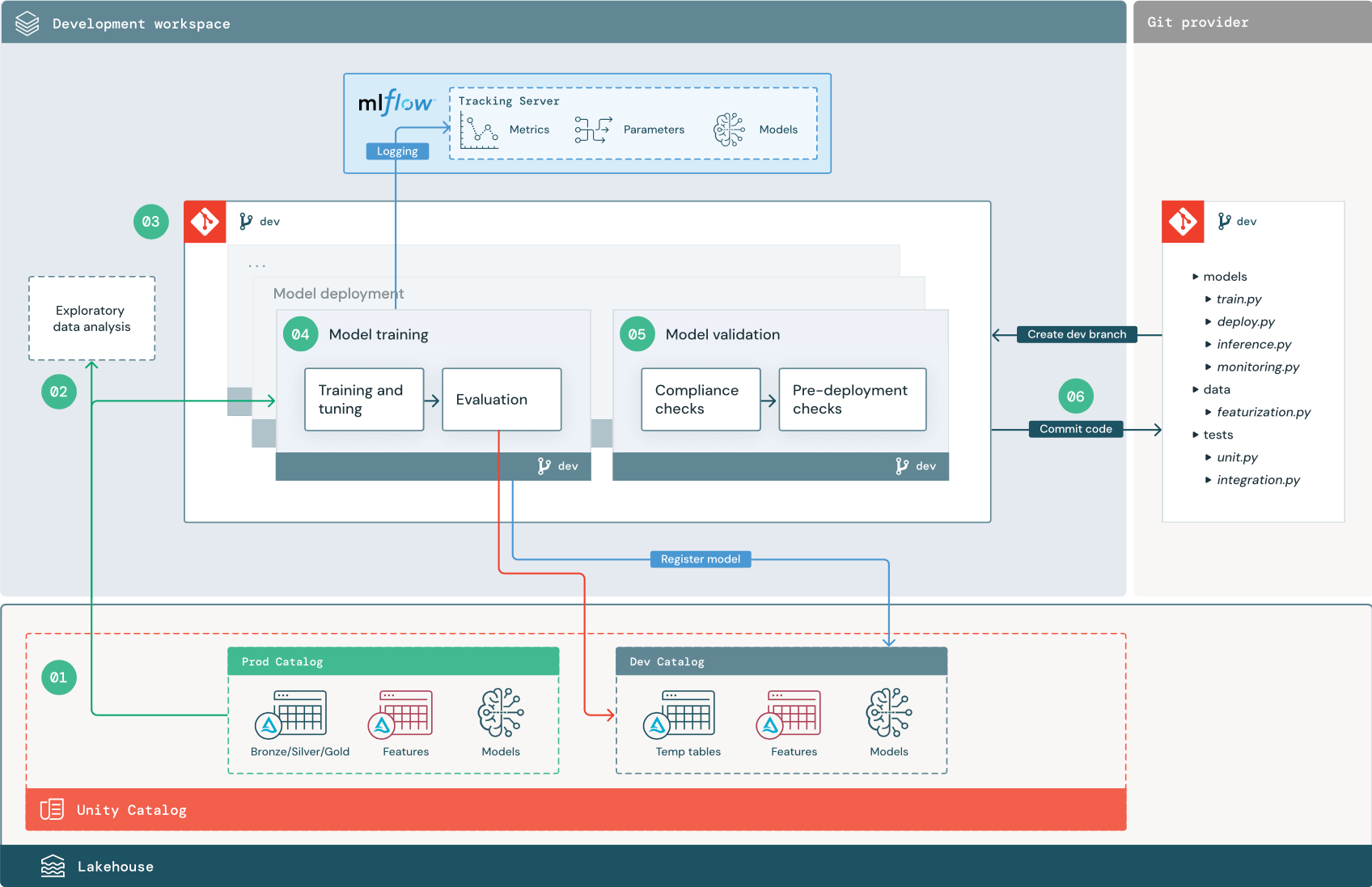
De genummerde stappen komen overeen met de getallen die in het diagram worden weergegeven.
1. Gegevensbronnen
De ontwikkelomgeving wordt vertegenwoordigd door de ontwikkelaarscatalogus in Unity Catalog. Gegevenswetenschappers hebben lees-/schrijftoegang tot de ontwikkelaarscatalogus wanneer ze tijdelijke gegevens en functietabellen maken in de ontwikkelwerkruimte. Modellen die in de ontwikkelingsfase zijn gemaakt, worden geregistreerd bij de ontwikkelaarscatalogus.
In het ideale ideaal hebben gegevenswetenschappers die in de ontwikkelwerkruimte werken ook alleen-lezentoegang tot productiegegevens in de prod-catalogus. Door gegevenswetenschappers toegang te geven tot productiegegevens, deductietabellen en metrische tabellen in de prod-catalogus, kunnen ze voorspellingen en prestaties van het huidige productiemodel analyseren. Gegevenswetenschappers moeten ook productiemodellen kunnen laden voor experimenten en analyses.
Als het niet mogelijk is om alleen-lezentoegang te verlenen tot de prod-catalogus, kan een momentopname van productiegegevens worden geschreven naar de ontwikkelaarscatalogus om gegevenswetenschappers in staat te stellen projectcode te ontwikkelen en te evalueren.
2. Experimentele gegevensanalyse (EDA)
Gegevenswetenschappers verkennen en analyseren gegevens in een interactief, iteratief proces met behulp van notebooks. Het doel is om te beoordelen of de beschikbare gegevens het bedrijfsprobleem kunnen oplossen. In deze stap begint de data scientist met het identificeren van gegevensvoorbereiding en featurisatiestappen voor modeltraining. Dit ad-hocproces maakt doorgaans geen deel uit van een pijplijn die wordt geïmplementeerd in andere uitvoeringsomgevingen.
Met AutoML wordt dit proces versneld door basislijnmodellen voor een gegevensset te genereren. AutoML voert een reeks proefversies uit en registreert een Python-notebook met de broncode voor elke proefuitvoering, zodat u de code kunt bekijken, reproduceren en wijzigen. AutoML berekent ook samenvattingsstatistieken voor uw gegevensset en slaat deze informatie op in een notebook die u kunt bekijken.
3. Programmacode
De codeopslagplaats bevat alle pijplijnen, modules en andere projectbestanden voor een ML-project. Gegevenswetenschappers maken nieuwe of bijgewerkte pijplijnen in een ontwikkelingsbranch ('dev') van de projectopslagplaats. Vanaf EDA en de eerste fasen van een project moeten gegevenswetenschappers in een opslagplaats werken om code te delen en wijzigingen bij te houden.
4. Model trainen (ontwikkeling)
Gegevenswetenschappers ontwikkelen de pijplijn voor modeltraining in de ontwikkelomgeving met behulp van tabellen uit de dev- of prod-catalogi.
Deze pijplijn bevat twee taken:
Training en fijnstelling. Het trainingsproces registreert modelparameters, metrische gegevens en artefacten naar de MLflow Tracking-server. Na het trainen en afstemmen van hyperparameters wordt het uiteindelijke modelartefact geregistreerd bij de traceringsserver om een koppeling tussen het model, de invoergegevens op te nemen waarop het is getraind en de code die wordt gebruikt om het te genereren.
Evaluatie. Evalueer de kwaliteit van het model door te testen op achtergehouden gegevens. De resultaten van deze tests worden vastgelegd op de MLflow Tracking-server. Het doel van de evaluatie is om te bepalen of het nieuw ontwikkelde model beter presteert dan het huidige productiemodel. Met voldoende machtigingen kan elk productiemodel dat is geregistreerd bij de prod-catalogus, in de ontwikkelwerkruimte worden geladen en vergeleken met een nieuw getraind model.
Als de governancevereisten van uw organisatie aanvullende informatie over het model bevatten, kunt u het opslaan met behulp van MLflow-tracering. Typische artefacten zijn beschrijvingen van tekst zonder opmaak en modelinterpretaties, zoals plots die door SHAP worden geproduceerd. Specifieke governancevereisten kunnen afkomstig zijn van een data governance officer of zakelijke belanghebbenden.
De uitvoer van de modeltrainingspijplijn is een ML-modelartefact dat is opgeslagen op de MLflow Tracking-server voor de ontwikkelomgeving. Als de pijplijn wordt uitgevoerd in de faserings- of productiewerkruimte, wordt het modelartefact opgeslagen in de MLflow Tracking-server voor die werkruimte.
Wanneer de modeltraining is voltooid, registreert u het model bij Unity Catalog. Stel uw pijplijncode in om het model te registreren bij de catalogus die overeenkomt met de omgeving waarin de modelpijplijn is uitgevoerd; in dit voorbeeld is de ontwikkelaarscatalogus.
Met de aanbevolen architectuur implementeert u een Databricks-werkstroom met meerdere taken waarin de eerste taak de pijplijn voor modeltraining is, gevolgd door modelvalidatie en modelimplementatietaken. De modeltrainingstaak levert een model-URI op die door de modelvalidatietaak kan worden gebruikt. U kunt taakwaarden gebruiken om deze URI door te geven aan het model.
5. Model valideren en implementeren (ontwikkeling)
Naast de pijplijn voor modeltraining worden andere pijplijnen, zoals modelvalidatie en modelimplementatiepijplijnen, ontwikkeld in de ontwikkelomgeving.
Modelvalidatie. De modelvalidatiepijplijn neemt de model-URI van de modeltrainingspijplijn, laadt het model uit Unity Catalog en voert validatiecontroles uit.
Validatiecontroles zijn afhankelijk van de context. Ze kunnen fundamentele controles bevatten, zoals het bevestigen van indeling en vereiste metagegevens, en complexere controles die mogelijk vereist zijn voor sterk gereglementeerde branches, zoals vooraf gedefinieerde nalevingscontroles en het bevestigen van modelprestaties voor geselecteerde gegevenssegmenten.
De primaire functie van de modelvalidatiepijplijn is om te bepalen of een model naar de implementatiestap moet gaan. Als het model de controles vóór de inzet doorstaat, kan het de alias 'Challenger' in Unity Catalog krijgen. Als de controles mislukken, wordt het proces beëindigd. U kunt uw werkstroom configureren om gebruikers op de hoogte te stellen van een validatiefout. Zie Meldingen toevoegen aan een taak.
Modelimplementatie. De pijplijn voor modelimplementatie bevordert doorgaans het zojuist getrainde 'Challenger'-model naar de status 'Champion' met behulp van een aliasupdate, of vereenvoudigt een vergelijking tussen het bestaande 'Champion'-model en het nieuwe 'Challenger'-model. Met deze pijplijn kunt u ook alle vereiste deductie-infrastructuur instellen, zoals Model Serving-eindpunten. Zie Productie voor een gedetailleerde bespreking van de stappen die betrokken zijn bij de pijplijn voor modelimplementatie.
6. Doorvoercode
Na het ontwikkelen van code voor training, validatie, implementatie en andere pijplijnen, voert de data scientist of ML-engineer de wijzigingen in de dev-vertakking door in broncodebeheer.
Voorbereidingsfase
De focus van deze fase is het testen van de ML-pijplijncode om ervoor te zorgen dat deze gereed is voor productie. Alle ML-pijplijncode wordt in deze fase getest, inclusief code voor modeltraining en functie-engineeringpijplijnen, deductiecode, enzovoort.
ML-technici maken een CI-pijplijn voor het implementeren van de eenheids- en integratietests die in deze fase worden uitgevoerd. De uitvoer van het faseringsproces is een release-branch die het CI/CD-systeem activeert om de productiestap te starten.
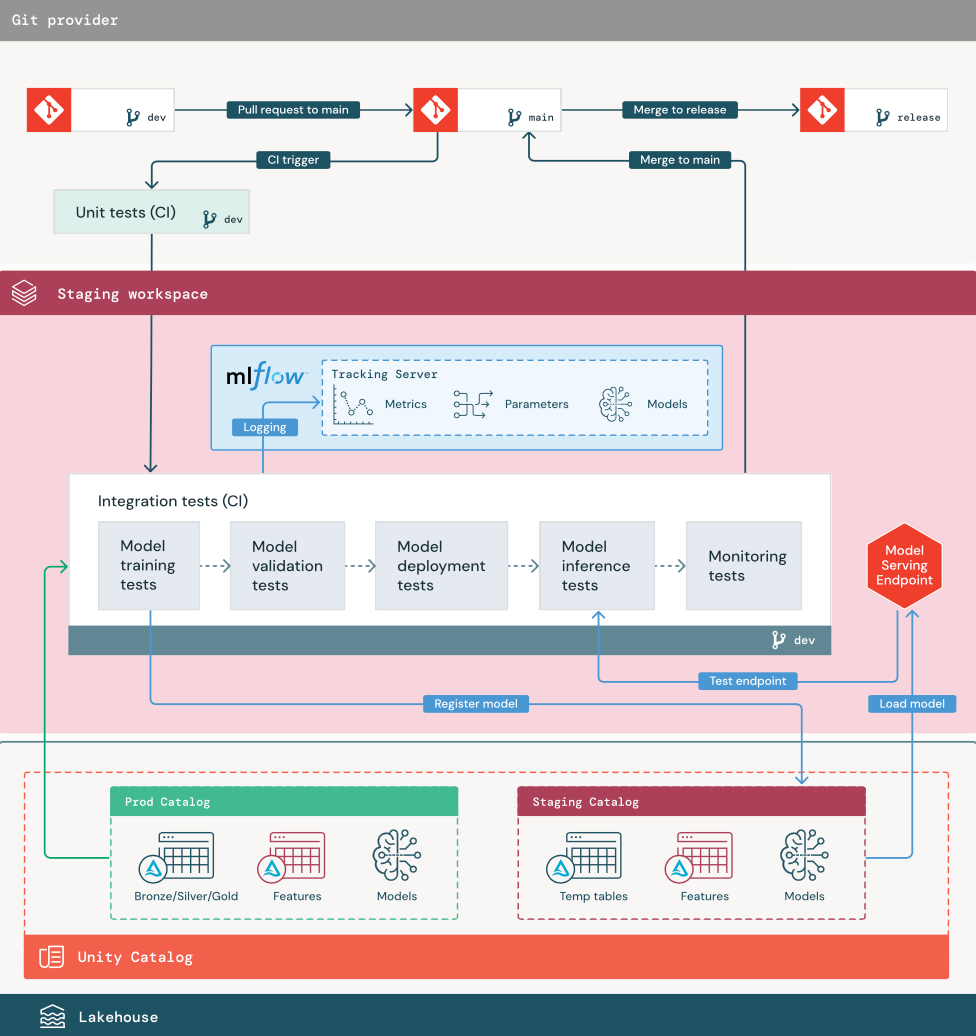
1. Gegevens
De faseringsomgeving moet een eigen catalogus in Unity Catalog hebben voor het testen van ML-pijplijnen en het registreren van modellen bij Unity Catalog. Deze catalogus wordt weergegeven als de staging-catalogus in het diagram. Assets die naar deze catalogus worden geschreven, zijn over het algemeen tijdelijk en blijven alleen bewaard tot de tests zijn afgerond. De ontwikkelomgeving vereist mogelijk ook toegang tot de faseringscatalogus voor foutopsporingsdoeleinden.
2. Code samenvoegen
Gegevenswetenschappers ontwikkelen de pijplijn voor modeltraining in de ontwikkelomgeving met behulp van tabellen uit de ontwikkelings- of productiecatalogus.
Pull-aanvraag. Het implementatieproces begint wanneer een pull-aanvraag wordt gemaakt op basis van de hoofdbranch van het project in broncodebeheer.
Eenheidstests (CI). De pull-aanvraag bouwt automatisch broncode en activeert eenheidstests. Als eenheidstests mislukken, wordt de pull-aanvraag geweigerd.
Eenheidstests maken deel uit van het softwareontwikkelingsproces en worden continu uitgevoerd en toegevoegd aan de codebasis tijdens de ontwikkeling van code. Het uitvoeren van eenheidstests als onderdeel van een CI-pijplijn zorgt ervoor dat wijzigingen in een ontwikkelingsbranch de bestaande functionaliteit niet verstoren.
3. Integratietests (CI)
Het CI-proces voert vervolgens de integratietests uit. Integratietests voeren alle pijplijnen uit (inclusief feature engineering, modeltraining, inferentie en bewaking) om ervoor te zorgen dat ze correct samenwerken. De faseringsomgeving moet zo dicht mogelijk overeenkomen met de productieomgeving.
Als u een ML-toepassing implementeert met real-time inference, moet u de infrastructuur maken en testen in de staging-omgeving. Dit omvat het activeren van de pijplijn voor modelimplementatie, waarmee een dienend eindpunt in de faseringsomgeving wordt gemaakt en een model wordt geladen.
Om de tijd die nodig is om integratietests uit te voeren te verminderen, kunnen sommige stappen afwegingen maken tussen de nauwkeurigheid van testen en snelheid of kosten. Als modellen bijvoorbeeld duur of tijdrovend zijn om te trainen, kunt u kleine subsets van gegevens gebruiken of minder trainingsiteraties uitvoeren. Voor het leveren van modellen, afhankelijk van de productievereisten, kunt u volledige belastingstests uitvoeren als onderdeel van integratietesten, of kleine batchverwerkingen of verzoeken testen via een tijdelijk eindpunt.
4. Samenvoegen naar staging-tak
Als alle tests slagen, wordt de nieuwe code samengevoegd in de hoofdbranch van het project. Als tests mislukken, moet het CI/CD-systeem gebruikers op de hoogte stellen en resultaten posten op de pull-aanvraag.
U kunt periodieke integratietests plannen op de hoofdbranch. Dit is een goed idee als de branch regelmatig wordt bijgewerkt met gelijktijdige pull requests van meerdere gebruikers.
5. Een releasebranch maken
Nadat de CI-tests zijn geslaagd en de dev-vertakking is samengevoegd in de hoofdvertakking, maakt de ML-engineer een release-vertakking, waardoor het CI/CD-systeem de productietaken kan bijwerken.
Productiefase
ML-technici zijn eigenaar van de productieomgeving waarin ML-pijplijnen worden geïmplementeerd en uitgevoerd. Deze pijplijnen activeren modeltraining, valideren en implementeren van nieuwe modelversies, publiceren voorspellingen naar downstreamtabellen of toepassingen en bewaken het hele proces om prestatievermindering en instabiliteit te voorkomen.
Gegevenswetenschappers hebben doorgaans geen schrijf- of rekentoegang in de productieomgeving. Het is echter belangrijk dat ze inzicht hebben in het testen van resultaten, logboeken, modelartefacten, status van productiepijplijn en bewakingstabellen. Met deze zichtbaarheid kunnen ze problemen in productie identificeren en diagnosticeren en de prestaties van nieuwe modellen vergelijken met modellen die momenteel in productie zijn. Voor deze doeleinden kunt u gegevenswetenschappers alleen-lezentoegang verlenen tot assets in de productiecatalogus.
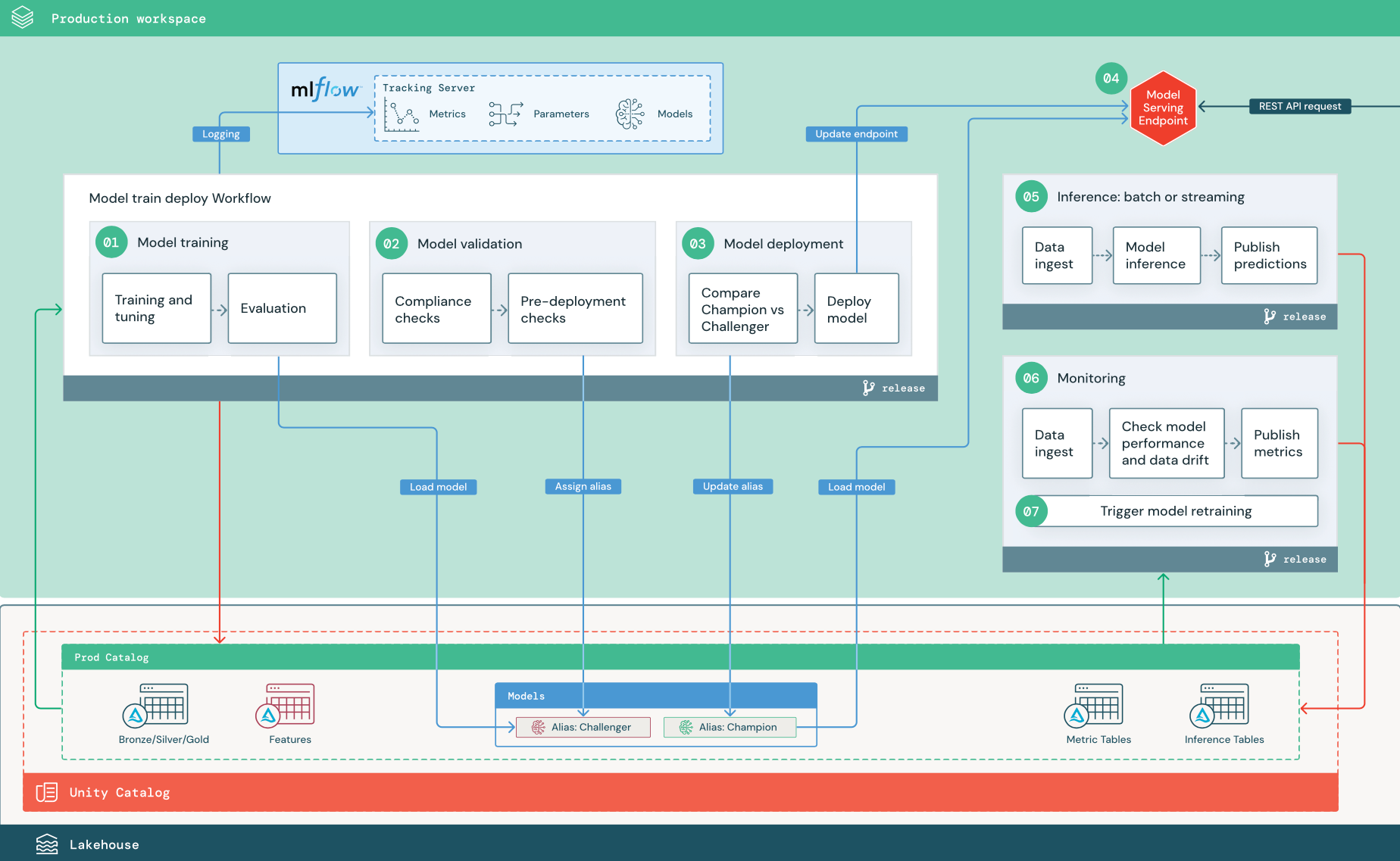
De genummerde stappen komen overeen met de getallen die in het diagram worden weergegeven.
1. Model trainen
Deze pijplijn kan worden geactiveerd door codewijzigingen of door geautomatiseerde hertrainingstaken. In deze stap worden tabellen uit de productiecatalogus gebruikt voor de volgende stappen.
Training en fijnstelling. Tijdens het trainingsproces worden logboeken vastgelegd op de MLflow Tracking-server van de productieomgeving. Deze logboeken omvatten metrische modelgegevens, parameters, tags en het model zelf. Als u kenmerkentabellen gebruikt, wordt het model geregistreerd bij MLflow met behulp van de Databricks Feature Store-client, die het model verpakt met informatie over het opzoeken van kenmerken die in het inferentieproces worden gebruikt.
Tijdens de ontwikkeling kunnen gegevenswetenschappers veel algoritmen en hyperparameters testen. In de productietrainingscode is het gebruikelijk om alleen rekening te houden met de best presterende opties. Door het afstemmen op deze manier te beperken, bespaart u tijd en kunt u de variantie van het afstemmen in geautomatiseerde hertraining verminderen.
Als gegevenswetenschappers alleen-lezentoegang hebben tot de productiecatalogus, kunnen ze mogelijk de optimale set hyperparameters voor een model bepalen. In dit geval kan de modeltrainingspijplijn die in productie is geïmplementeerd, worden uitgevoerd met behulp van de geselecteerde set hyperparameters, meestal opgenomen in de pijplijn als een configuratiebestand.
Evaluatie. De kwaliteit van het model wordt geëvalueerd door test uit te voeren op achtergehouden productiegegevens. De resultaten van deze tests worden vastgelegd op de MLflow-traceringsserver. In deze stap worden de metrische evaluatiegegevens gebruikt die zijn opgegeven door gegevenswetenschappers in de ontwikkelingsfase. Deze metrische gegevens kunnen aangepaste code bevatten.
Model registreren. Wanneer de modeltraining is voltooid, wordt het modelartefact opgeslagen als een geregistreerde modelversie op het opgegeven modelpad in de productiecatalogus in Unity Catalog. De modeltrainingstaak levert een model-URI op die door de modelvalidatietaak kan worden gebruikt. U kunt taakwaarden gebruiken om deze URI door te geven aan het model.
2. Model valideren
Deze pijplijn maakt gebruik van de model-URI uit stap 1 en laadt het model uit Unity Catalog. Vervolgens wordt een reeks validatiecontroles uitgevoerd. Deze controles zijn afhankelijk van uw organisatie en use-case en kunnen zaken omvatten zoals basisindeling en metagegevensvalidaties, prestatieevaluaties voor geselecteerde gegevenssegmenten en naleving van organisatievereisten, zoals nalevingscontroles voor tags of documentatie.
Als het model alle validatiecontroles heeft doorstaan, kunt u de alias 'Challenger' toewijzen aan de modelversie in Unity Catalog. Als het model niet alle validatiecontroles doorstaat, wordt het proces afgesloten en kunnen gebruikers automatisch op de hoogte worden gesteld. U kunt tags gebruiken om sleutel-waardekenmerken toe te voegen, afhankelijk van het resultaat van deze validatiecontroles. U kunt bijvoorbeeld een tag 'model_validation_status' maken en de waarde instellen op 'IN BEHANDELING' wanneer de tests worden uitgevoerd en deze vervolgens bijwerken naar 'GESLAAGD' of 'MISLUKT' wanneer de pijplijn is voltooid.
Omdat het model is geregistreerd bij Unity Catalog, kunnen gegevenswetenschappers die in de ontwikkelomgeving werken, deze modelversie laden vanuit de productiecatalogus om te onderzoeken of het model niet kan worden gevalideerd. Ongeacht het resultaat worden resultaten vastgelegd op het geregistreerde model in de productiecatalogus met behulp van aantekeningen in de modelversie.
3. Model implementeren
Net als de validatiepijplijn is de pijplijn voor modelimplementatie afhankelijk van uw organisatie en use-case. In deze sectie wordt ervan uitgegaan dat u het zojuist gevalideerde model de alias 'Challenger' hebt toegewezen en dat aan het bestaande productiemodel de alias 'Champion' is toegewezen. Is de eerste stap voordat u het nieuwe model implementeert, om te bevestigen dat het ten minste zo goed presteert als het huidige productiemodel.
Vergelijk 'CHALLENGER' met 'CHAMPION'-model. U kunt deze vergelijking offline of online uitvoeren. Een offlinevergelijking evalueert beide modellen op basis van een gegevensset die is opgeslagen en houdt resultaten bij met behulp van de MLflow Tracking-server. Voor het leveren van realtime modellen wilt u mogelijk langere online vergelijkingen uitvoeren, zoals A/B-tests of een geleidelijke implementatie van het nieuwe model. Als de 'Challenger'-modelversie beter presteert in de vergelijking, vervangt deze de huidige "Kampioen"-alias.
Met Mozaïek AI-model serveren en gegevensprofilering kunt u automatisch deductietabellen verzamelen en bewaken die aanvraag- en antwoordgegevens voor een eindpunt bevatten.
Als er geen bestaand model 'Champion' is, kunt u het model 'Challenger' vergelijken met een zakelijke heuristiek of een andere drempelwaarde als basislijn.
Het hier beschreven proces is volledig geautomatiseerd. Als handmatige goedkeuringsstappen vereist zijn, kunt u deze instellen met behulp van werkstroommeldingen of CI/CD-callbacks vanuit de pijplijn voor modelimplementatie.
Model implementeren. Batch- of streamingdeductiepijplijnen kunnen worden ingesteld om het model te gebruiken met de alias Champion. Voor realtime gebruiksscenario's moet u de infrastructuur instellen om het model te implementeren als een REST API-eindpunt. U kunt dit eindpunt maken en beheren met behulp van Mosaic AI Model Serving. Als een eindpunt al in gebruik is voor het huidige model, kunt u het eindpunt bijwerken met het nieuwe model. Mozaïek AI Model Serving voert een update zonder downtime uit door de bestaande configuratie actief te houden totdat de nieuwe gereed is.
4. Model serveren
Wanneer u een eindpunt voor modelverdiening configureert, geeft u de naam op van het model in Unity Catalog en de versie die moet worden gebruikt. Als de modelversie is getraind met behulp van functies uit tabellen in Unity Catalog, slaat het model de afhankelijkheden op voor de functies en functies. Model Serving gebruikt deze afhankelijkheidsgrafiek automatisch om kenmerken uit de juiste online opslaglocaties op te zoeken tijdens inferentietijd. Deze aanpak kan ook worden gebruikt om functies toe te passen voor het vooraf verwerken van gegevens of om functies op aanvraag te berekenen tijdens het scoren van modellen.
U kunt één eindpunt maken met meerdere modellen en het eindpuntverkeer tussen deze modellen opgeven, zodat u online 'Kampioen' versus 'Challenger'-vergelijkingen kunt uitvoeren.
5. Inferentie: batch of streaming
De deductiepijplijn leest de meest recente gegevens uit de productiecatalogus, voert functies uit om functies te berekenen op aanvraag, laadt het model 'Kampioen', beoordeelt de gegevens en retourneert voorspellingen. Batch- of streaminginferentie is over het algemeen de meest rendabele optie voor gebruiksscenario's met een hogere doorvoer en hogere latentie. Voor scenario's waarbij voorspellingen met lage latentie vereist zijn, maar voorspellingen offline kunnen worden berekend, kunnen deze batchvoorspellingen worden gepubliceerd naar een online sleutelwaardearchief, zoals DynamoDB of Cosmos DB.
Er wordt naar het geregistreerde model in Unity Catalog verwezen door de alias. De deductiepijplijn is geconfigureerd voor het laden en toepassen van de modelversie 'Champion'. Als de versie 'Champion' wordt bijgewerkt naar een nieuwe modelversie, gebruikt de deductiepijplijn automatisch de nieuwe versie voor de volgende uitvoering. Op deze manier wordt de implementatiestap van het model losgekoppeld van deductiepijplijnen.
Batchtaken publiceren doorgaans voorspellingen naar tabellen in de productiecatalogus, naar platte bestanden of via een JDBC-verbinding. Streamingtaken publiceren doorgaans voorspellingen in Unity Catalog-tabellen of in berichtenwachtrijen zoals Apache Kafka.
6. Gegevensprofilering
Gegevensprofilering bewaakt statistische eigenschappen, zoals gegevensdrift en modelprestaties, van invoergegevens en modelvoorspellingen. U kunt waarschuwingen maken op basis van deze metrische gegevens of deze publiceren in dashboards.
- Gegevensopname. Deze pijplijn leest logs in van batch-, streaming- of online-inferentie.
- Controleer de nauwkeurigheid en gegevensdrift. De pijplijn berekent metrische gegevens over de invoergegevens, de voorspellingen van het model en de prestaties van de infrastructuur. Gegevenswetenschappers geven gegevens en modelmetrieken op tijdens de ontwikkeling en ML-technici geven metrische gegevens over de infrastructuur op. U kunt ook aangepaste metrische gegevens definiëren.
- Publiceer metrische gegevens en stel waarschuwingen in. De pijplijn schrijft gegevens naar tabellen in de productiecatalogus voor analyse en rapportage. U moet deze tabellen zo configureren dat ze leesbaar zijn vanuit de ontwikkelomgeving, zodat gegevenswetenschappers toegang hebben tot analyse. U kunt Databricks SQL gebruiken om bewakingsdashboards te maken om modelprestaties bij te houden en de bewakingstaak of het dashboardhulpprogramma in te stellen om een melding uit te geven wanneer een metrische waarde een opgegeven drempelwaarde overschrijdt.
- Hertraining van model activeren. Wanneer het bewaken van metrieke gegevens prestatieproblemen of veranderingen in de invoergegevens aangeeft, moet de data scientist mogelijk een nieuwe modelversie ontwikkelen. U kunt SQL-waarschuwingen instellen om gegevenswetenschappers op de hoogte te stellen wanneer dit gebeurt.
7. Opnieuw trainen
Deze architectuur biedt ondersteuning voor automatisch opnieuw trainen met behulp van dezelfde modeltrainingspijplijn hierboven. Databricks raadt aan om te beginnen met geplande, periodieke hertraining en overschakelen naar geactiveerde hertraining wanneer dat nodig is.
- Gepland. Als er regelmatig nieuwe gegevens beschikbaar zijn, kunt u een geplande taak maken om de modeltrainingscode uit te voeren op de meest recente beschikbare gegevens. Zie Taken automatiseren met planningen en triggers
- Geactiveerd. Als de bewakingspijplijn problemen met modelprestaties kan identificeren en waarschuwingen kan verzenden, kan het ook het opnieuw trainen starten. Als de distributie van binnenkomende gegevens bijvoorbeeld aanzienlijk verandert of als de modelprestaties afnemen, kan automatische hertraining en herdistributie de modelprestaties verbeteren met minimale menselijke tussenkomst. Dit kan worden bereikt via een SQL-waarschuwing om te controleren of een metrische waarde afwijkend is (bijvoorbeeld drift of modelkwaliteit controleren op basis van een drempelwaarde). De waarschuwing kan worden geconfigureerd voor het gebruik van een webhookbestemming, die vervolgens de trainingswerkstroom kan activeren.
Als de retraining pijplijn of andere pijplijnen prestatieproblemen vertonen, kan de data scientist mogelijk terugkeren naar de ontwikkelomgeving voor aanvullende experimenten om de problemen op te lossen.