Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel wordt beschreven hoe u model voor eindpunten maakt die aangepaste modellen leveren met behulp van Databricks Model Serving.
Model Serving biedt de volgende opties voor endpoint-aanmaak:
- De ondersteunende gebruikersinterface
- REST-API
- MLflow Deployments SDK
Zie Basismodel maken voor eindpuntenvoor het maken van eindpunten die gebruikmaken van generatieve AI-modellen.
Eisen
- Uw werkruimte moet zich in een ondersteunde regio bevinden.
- Als u aangepaste bibliotheken of bibliotheken van een privéspiegelserver met uw model gebruikt, raadpleegt u Aangepaste Python-bibliotheken gebruiken met Model Serving voordat u het modeleindpunt aanmaakt.
- Voor het maken van eindpunten met behulp van de MLflow Deployments SDK moet u de MLflow Deployment-client installeren. Voer de volgende opdracht uit om deze te installeren:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Toegangsbeheer
Zie Machtigingen beheren voor een eindpunt voor modellevering voor meer informatie over toegangsbeheer opties voor model-serve eindpunten.
De identiteit waaronder een model voor eindpunten wordt uitgevoerd, is gekoppeld aan de oorspronkelijke maker van het eindpunt. Nadat het eindpunt is gemaakt, kan de bijbehorende identiteit niet worden gewijzigd of bijgewerkt op het eindpunt. Deze identiteit en de bijbehorende machtigingen worden gebruikt voor toegang tot Unity Catalog-resources voor implementaties. Als de identiteit niet over de juiste machtigingen beschikt om toegang te krijgen tot de benodigde Unity Catalog-resources, moet u het eindpunt verwijderen en opnieuw maken onder een gebruiker of service-principal die toegang heeft tot deze Unity Catalog-resources.
U kunt ook omgevingsvariabelen toevoegen om referenties op te slaan voor het leveren van modellen. Zie Toegang tot middelen configureren vanaf modelservereindpunten
Een eindpunt maken
UI leveren
U kunt een eindpunt maken voor modellenservering met de Serving-gebruikersinterface.
Klik op Serveren in de zijbalk om de gebruikersinterface van de server weer te geven.
Klik op Een service-eindpunt maken.
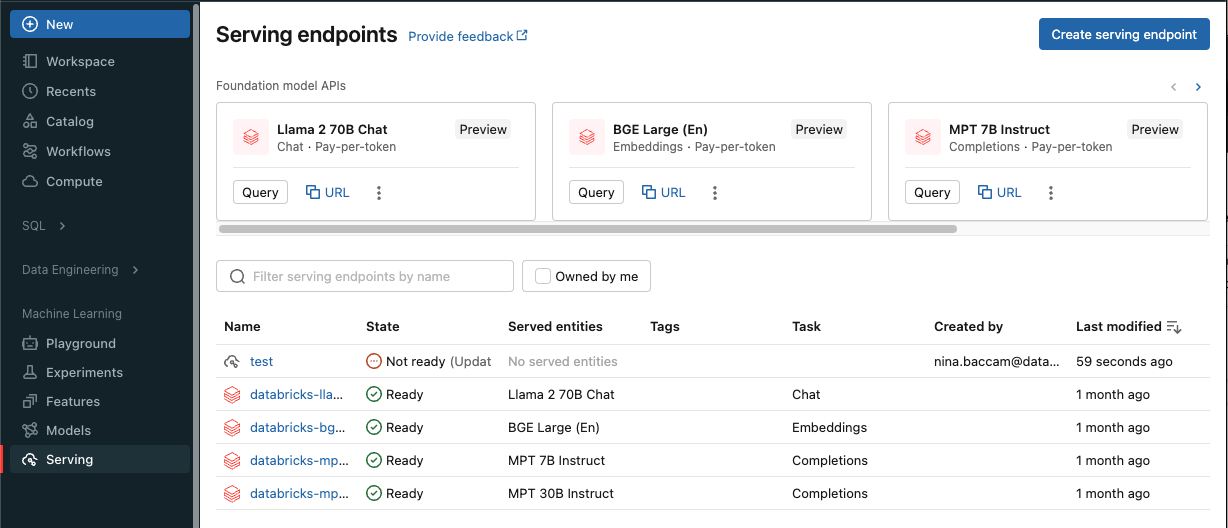
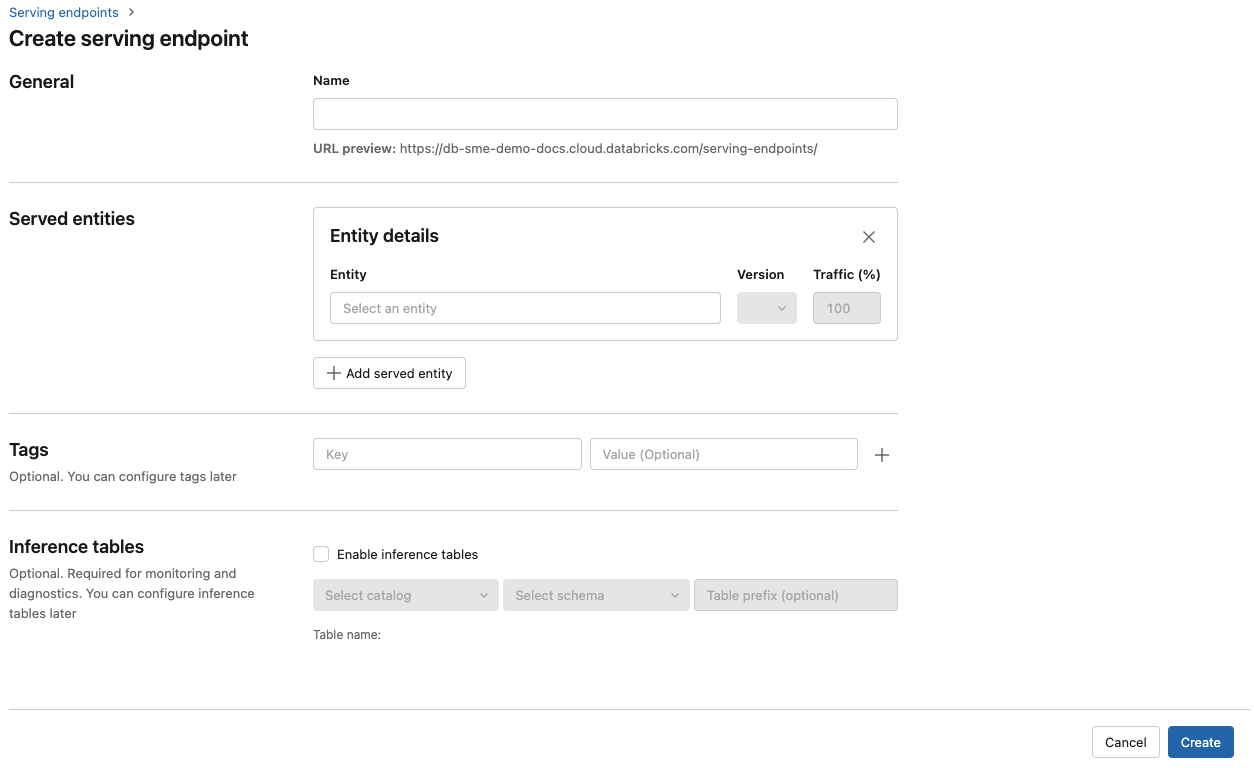
Voor modellen die zijn geregistreerd in het werkruimtemodelregister of -modellen in Unity Catalog:
Geef in het veld Naam een naam op voor uw eindpunt.
- Eindpuntnamen kunnen het
databricks-voorvoegsel niet gebruiken. Dit voorvoegsel is gereserveerd voor vooraf geconfigureerde Databricks-eindpunten.
- Eindpuntnamen kunnen het
In de sectie Geserveerde entiteiten
- Klik in het veld Entiteit om het formulier Bediende entiteit selecteren te openen.
- Selecteer Mijn modellen- Unity Catalog of Mijn modellen- Modelregister op basis van de locatie waar uw model is geregistreerd. Het formulier wordt dynamisch bijgewerkt op basis van uw selectie.
- Niet alle modellen zijn aangepaste modellen. Modellen kunnen basismodellen of functies zijn voor het leveren van functies.
- Selecteer welk model en welke modelversie u wilt gebruiken.
- Selecteer het percentage verkeer dat u naar uw geleverd model wilt routeren.
- Selecteer welke grootte rekenkracht u wilt gebruiken. U kunt CPU- of GPU-berekeningen gebruiken voor uw workloads. Zie GPU-workloadtypen voor meer informatie over beschikbare GPU-berekeningen.
- Selecteer onder Compute Scale-outde grootte van de rekenschaal die overeenkomt met het aantal aanvragen dat dit gediende model tegelijk kan verwerken. Dit getal moet ongeveer gelijk zijn aan de uitvoeringstijd van het QPS x-model. Zie voor door de klant gedefinieerde rekeninstellingen de limieten voor het leveren van modellen.
- De beschikbare grootten zijn klein voor 0-4 aanvragen, gemiddeld 8-16 aanvragen en groot voor 16-64 aanvragen.
- Geef op of het eindpunt moet worden geschaald naar nul wanneer het niet in gebruik is. Schaal naar nul wordt niet aanbevolen voor productie-eindpunten, omdat de capaciteit niet wordt gegarandeerd wanneer deze naar nul wordt geschaald. Wanneer een eindpunt naar nul wordt geschaald, is er extra latentie, ook wel een koude start genoemd, wanneer het eindpunt weer wordt geschaald om aanvragen te verwerken.
- Onder Geavanceerde configuratie kunt u het volgende doen:
- Wijzig de naam van de aangeboden entiteit om aan te passen hoe deze wordt weergegeven in het eindpunt.
- Voeg omgevingsvariabelen toe om vanuit uw eindpunt verbinding te maken met resources of registreer uw feature lookup DataFrame in de voorspellingstabel van het eindpunt. Voor het vastleggen van de DataFrame voor kenmerkopzoeking is MLflow 2.14.0 of hoger vereist.
- (Optioneel) Als u extra serverentiteiten aan uw eindpunt wilt toevoegen, klikt u op Een entiteit toevoegen en herhaalt u de bovenstaande configuratiestappen. U kunt meerdere modellen of modelversies van één eindpunt bedienen en het verkeer tussen deze modellen beheren. Zie meerdere modellen bedienen voor meer informatie.
In de sectie Routeoptimalisatie kunt u routeoptimalisatie inschakelen voor uw eindpunt. Routeoptimalisatie wordt aanbevolen voor eindpunten met hoge QPS- en doorvoervereisten. Zie Routeoptimalisatie voor het leveren van eindpunten.
In de sectie AI Gateway kunt u selecteren welke beheerfuncties u op uw eindpunt wilt inschakelen. Zie Unity AI Gateway.
Klik op Create. De pagina Serverende eindpunten wordt weergegeven met de status van het servereindpunt als Niet gereed.
REST-API
U kunt eindpunten maken met behulp van de REST API. Zie POST /api/2.0/serving-endpoints voor eindpuntconfiguratieparameters.
In het volgende voorbeeld wordt een eindpunt gemaakt dat fungeert voor de derde versie van het my-ads-model-model dat is geregistreerd in het Unity Catalog-modelregister. Als u een model uit Unity Catalog wilt opgeven, geeft u de volledige modelnaam op, inclusief bovenliggende catalogus en schema, zoals catalog.schema.example-model. In dit voorbeeld wordt gebruikgemaakt van aangepaste gedefinieerde gelijktijdigheid met min_provisioned_concurrency en max_provisioned_concurrency. Gelijktijdigheidswaarden moeten veelvouden van 4 zijn.
POST /api/2.0/serving-endpoints
{
"name": "uc-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false
}
]
}
}
Hier volgt een voorbeeld van een antwoord. De status van het eindpunt config_update is NOT_UPDATING en het bediende model bevindt zich in een READY status.
{
"name": "uc-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
MLflow Deployments SDK
MLflow Deployments biedt een API voor het maken, bijwerken en verwijderen van taken. De API's voor deze taken accepteren dezelfde parameters als de REST API voor het leveren van eindpunten. Zie POST /api/2.0/serving-endpoints voor eindpuntconfiguratieparameters.
In het volgende voorbeeld wordt een eindpunt gemaakt dat fungeert voor de derde versie van het my-ads-model-model dat is geregistreerd in het Unity Catalog-modelregister. U moet de volledige modelnaam opgeven, inclusief hoofdcatalogus en schema, zoals catalog.schema.example-model. In dit voorbeeld wordt gebruikgemaakt van aangepaste gedefinieerde gelijktijdigheid met min_provisioned_concurrency en max_provisioned_concurrency. Gelijktijdigheidswaarden moeten veelvouden van 4 zijn.
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": False
}
]
}
)
Werkruimteclient
In het volgende voorbeeld ziet u hoe u een eindpunt maakt met behulp van de Databricks Workspace Client SDK.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="uc-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
name="ads-entity",
entity_name="catalog.schema.my-ads-model",
entity_version="3",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
U kunt ook het volgende doen:
- Deductietabellen inschakelen om automatisch binnenkomende aanvragen en uitgaande antwoorden vast te leggen voor uw model voor eindpunten.
- Als u inferentietabellen hebt ingeschakeld op uw eindpunt, kunt u uw feature-lookup DataFrame registreren in de inferentietabel.
GPU-workloadtypen
GPU-implementatie is compatibel met de volgende pakketversies:
- PyTorch 1.13.0 - 2.0.1
- TensorFlow 2.5.0 - 2.13.0
- MLflow 2.4.0 en hoger
In de volgende voorbeelden ziet u hoe u GPU-eindpunten maakt met behulp van verschillende methoden.
UI leveren
Als u uw eindpunt wilt configureren voor GPU-workloads met de serverinterface , selecteert u het gewenste GPU-type in de vervolgkeuzelijst Compute-type bij het maken van uw eindpunt. Volg dezelfde stappen in Een eindpunt maken, maar selecteer een GPU-workloadtype in plaats van CPU.
REST-API
Als u uw modellen wilt implementeren met gpu's, neemt u het workload_type veld op in uw eindpuntconfiguratie.
POST /api/2.0/serving-endpoints
{
"name": "gpu-model-endpoint",
"config": {
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": false
}]
}
}
MLflow Deployments SDK
In het volgende voorbeeld ziet u hoe u een GPU-eindpunt maakt met behulp van de MLflow Deployments SDK.
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="gpu-model-endpoint",
config={
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": False
}]
}
)
Werkruimteclient
In het volgende voorbeeld ziet u hoe u een GPU-eindpunt maakt met behulp van de Databricks Workspace Client SDK.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="gpu-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="catalog.schema.my-gpu-model",
entity_version="1",
workload_type="GPU_SMALL",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
De volgende tabel bevat een overzicht van de beschikbare ondersteunde GPU-workloadtypen.
| Type GPU-werkbelasting | GPU-instantie | GPU-geheugen |
|---|---|---|
GPU_SMALL |
1xT4 | 16 GB |
GPU_LARGE |
1xA100 | 80 GB |
GPU_LARGE_2 |
2xA100 | 160 GB |
Een aangepast modeleindpunt wijzigen
Nadat u een aangepast modeleindpunt hebt ingeschakeld, kunt u de rekenconfiguratie naar wens bijwerken. Deze configuratie is met name handig als u aanvullende resources nodig hebt voor uw model. Workloadgrootte en rekenconfiguratie spelen een belangrijke rol in de resources die worden toegewezen voor het leveren van uw model.
Opmerking
Updates voor de eindpuntconfiguratie kunnen mislukken. Wanneer er fouten optreden, blijft de bestaande actieve configuratie effectief alsof de update niet is uitgevoerd.
Controleer of de update is toegepast door de status van uw eindpunt te controleren.
Totdat de nieuwe configuratie gereed is, blijft de oude configuratie voorspellingsverkeer leveren. Hoewel er een update wordt uitgevoerd, kan er geen andere update worden uitgevoerd. U kunt echter een lopende update annuleren vanuit de Serving-gebruikersinterface.
UI leveren
Nadat u een modeleindpunt hebt ingeschakeld, selecteert u Eindpunt bewerken om de rekenconfiguratie van uw eindpunt te wijzigen.
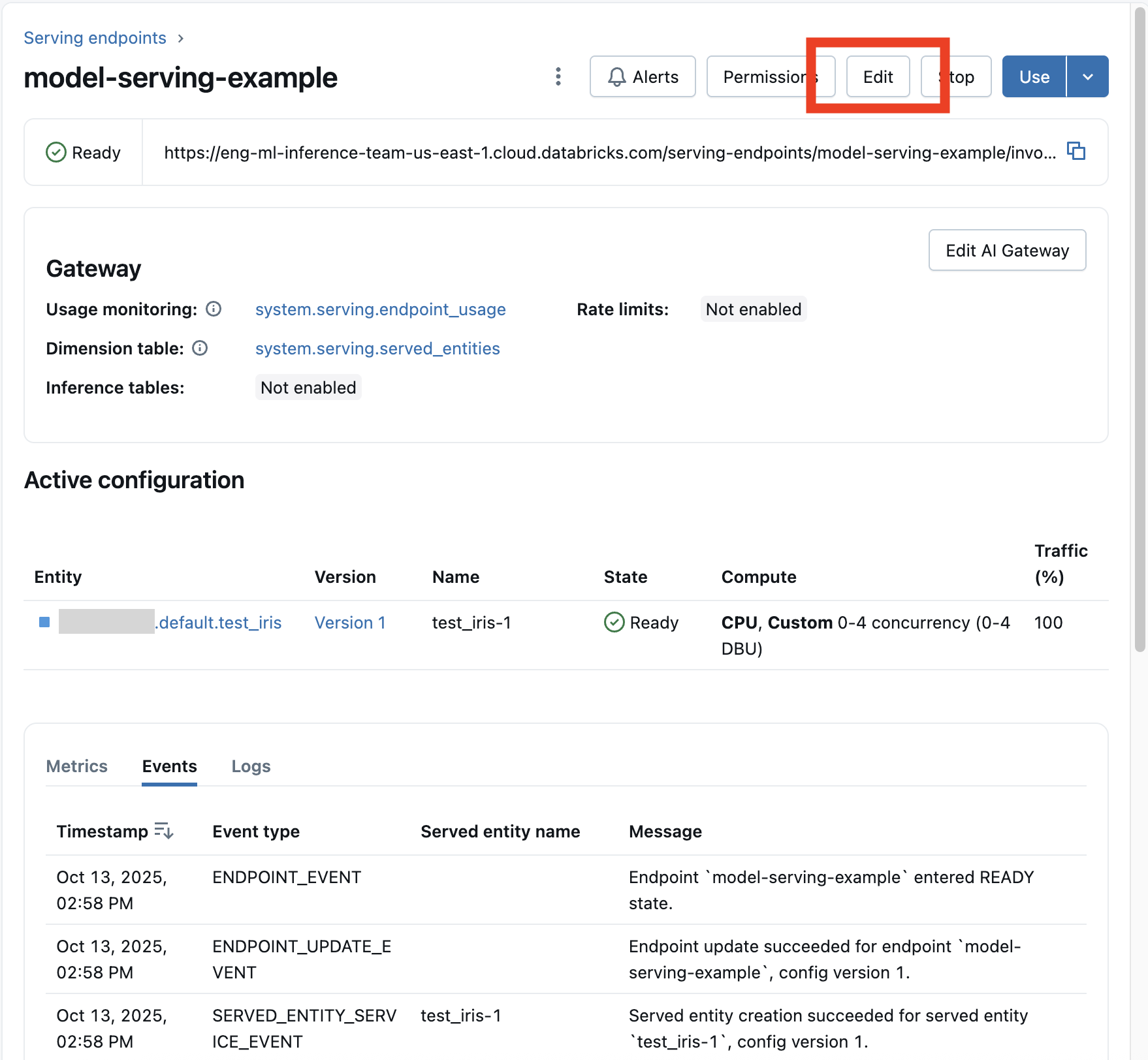
U kunt de meeste aspecten van de eindpuntconfiguratie wijzigen, met uitzondering van de eindpuntnaam en bepaalde onveranderbare eigenschappen.
U kunt een actieve configuratie-update annuleren door De update annuleren te selecteren op de pagina met details van het eindpunt.
REST-API
Hier volgt een voorbeeld van een update van de eindpuntconfiguratie met behulp van de REST API. Zie PUT /api/2.0/serving-endpoints/{name}/config.
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
MLflow Deployments SDK
De MLflow Deployments SDK gebruikt dezelfde parameters als de REST API. Zie PUT /api/2.0/serving-endpoints/{name}/config voor details van het aanvraag- en antwoordschema.
In het volgende codevoorbeeld wordt een model uit het Unity Catalog-modelregister gebruikt:
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
Een modeleindpunt scoren
Als u uw model wilt beoordelen, verzendt u aanvragen naar het eindpunt van het model.
Aanvullende bronnen
- Beheer het leveren van eindpunten voor modellen.
- Externe modellen in Mosaic AI Model Serving.
- Als u liever Python gebruikt, kunt u de Databricks real-time serving Python SDK gebruiken.
Notebook-voorbeelden
De volgende notebooks bevatten verschillende geregistreerde Databricks-modellen die u kunt gebruiken om aan de slag te gaan met eindpunten voor modellen. Zie Zelfstudie: Een aangepast model implementeren en er query's op uitvoerenvoor meer voorbeelden.
De modelvoorbeelden kunnen in de werkruimte worden geïmporteerd door de aanwijzingen in Een notebook importeren te volgen. Nadat u een model hebt gekozen en gemaakt van een van de voorbeelden, registreert u dit in de Unity Catalogen volgt u vervolgens de stappen van de UI-werkstroom voor het implementeren van modellen.