Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Belangrijk
Deze functie is experimenteel.
In dit artikel wordt uitgelegd hoe u materialisatie gebruikt voor metrische weergaven om de queryprestaties te versnellen.
Materialisatie voor metrische weergaven versnelt query's met behulp van gerealiseerde weergaven. Met Lakeflow Spark Declarative Pipelines worden door gebruikers gedefinieerde gematerialiseerde weergaven georkestreerd voor een bepaalde metrische weergave. Tijdens het querymoment routeert de queryoptimizer op intelligente wijze gebruikersquery's van de metrische weergave naar de beste gematerialiseerde weergave, met behulp van automatische aggregatie-bewuste querymatching, ook wel bekend als het herschrijven van query's.
Deze benadering biedt de voordelen van pre-berekeningen en automatische incrementele updates, zodat u niet hoeft te bepalen welke aggregatietabel of Materialized View er moet worden opgevraagd voor verschillende prestatiedoelen, en elimineert de noodzaak om aparte productiepijplijnen te beheren.
Overzicht
In het volgende diagram wordt geïllustreerd hoe metrieken omgaan met het definiëren en uitvoeren van query's.
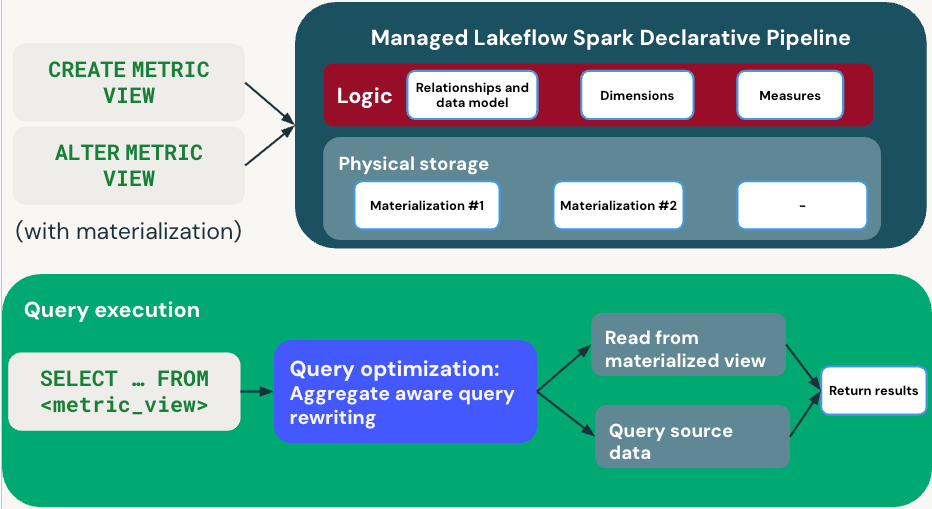
Definitiefase (fase waarin de definitie plaatsvindt)
Wanneer u een metrische weergave definieert met materialisatie CREATE METRIC VIEW of ALTER METRIC VIEW uw dimensies, metingen en vernieuwingsschema opgeeft. Databricks maakt een beheerde pijplijn die de gematerialiseerde weergaven onderhoudt.
Query uitvoeren
Wanneer u SELECT ... FROM <metric_view> uitvoert, gebruikt de query-optimizer het herschrijven van aggregaatbewuste query's om de prestaties te optimaliseren.
- Snelle route: leest uit vooraf berekende materiële weergaven indien van toepassing.
- Terugvalpad: leest rechtstreeks uit brongegevens wanneer materialisaties niet beschikbaar zijn.
De queryoptimalisatie zorgt automatisch voor een balans tussen prestaties en nieuwheid door te kiezen tussen gerealiseerde en brongegevens. U ontvangt transparant resultaten, ongeacht welk pad wordt gebruikt.
Requirements
Materialisatie gebruiken voor metrische weergaven:
- Voor uw werkruimte moet serverloze rekenkracht zijn ingeschakeld. Dit is vereist voor het uitvoeren van Lakeflow Spark-declaratieve pijplijnen.
- Databricks Runtime 17.2 of hoger.
Configuratiegids
Alle informatie met betrekking tot materialisatie wordt gedefinieerd in een veld op het hoogste niveau met de naam materialization in de YAML-definitie van de metrische weergave.
Het materialization veld bevat de volgende vereiste velden:
- schema: ondersteunt dezelfde syntaxis als de schema clausule voor gematerialiseerde weergaven.
-
modus: moet worden ingesteld op
relaxed. -
materialized_views: een lijst met gerealiseerde weergaven die moeten worden gerealiseerd.
- name: De naam van de materialisatie.
- dimensies: Een lijst met dimensies die moeten worden gerealiseerd. Alleen directe verwijzingen naar dimensienamen zijn toegestaan; expressies worden niet ondersteund.
- metingen: Een lijst met metingen die moeten worden gerealiseerd. Alleen directe verwijzingen naar maateenheidnamen zijn toegestaan; expressies worden niet ondersteund.
-
type: Hiermee geeft u op of de gerealiseerde weergave wordt samengevoegd of niet. Accepteert twee mogelijke waarden:
aggregatedenunaggregated.- Als
typeisaggregated, moet er ten minste één dimensie of maatregel zijn. - Als
typeunaggregatedis, hoeven er geen dimensies of metingen gedefinieerd te worden.
- Als
Opmerking
De TRIGGER ON UPDATE component wordt niet ondersteund voor materialisatie voor metrische weergaven.
Voorbeelddefinitie
version: 1.1
source: prod.operations.orders_enriched_view
filter: revenue > 0
dimensions:
- name: category
expr: substring(category, 5)
- name: color
expr: color
measures:
- name: total_revenue
expr: SUM(revenue)
- name: number_of_suppliers
expr: COUNT(DISTINCT supplier_id)
materialization:
schedule: every 6 hours
mode: relaxed
materialized_views:
- name: baseline
type: unaggregated
- name: revenue_breakdown
type: aggregated
dimensions:
- category
- color
measures:
- total_revenue
- name: suppliers_by_category
type: aggregated
dimensions:
- category
measures:
- number_of_suppliers
Wijze
In de relaxed-modus controleert automatische query herschrijft alleen of kandidaat gematerialiseerde weergaven de benodigde dimensies en metingen hebben om aan de query te voldoen.
Dit betekent dat verschillende controles worden overgeslagen:
- Er wordt niet gecontroleerd of de gerealiseerde weergave up-to-date is.
- Er wordt niet gecontroleerd of u overeenkomende SQL-instellingen hebt (bijvoorbeeld
ANSI_MODEofTIMEZONE). - Er wordt niet gecontroleerd of de gerealiseerde weergave deterministische resultaten retourneert.
Als de query een van de volgende voorwaarden bevat, wordt het herschrijven van de query niet uitgevoerd en valt de query terug op de brontabellen:
- Beveiliging op rijniveau (RLS) of maskering op kolomniveau (CLM) in gematerialiseerde weergaven.
- Niet-deterministische functies, zoals
current_timestamp()in gerealiseerde weergaven. Deze kunnen worden weergegeven in de definitie van de metrische weergave of in een brontabel die wordt gebruikt door de metrische weergave.
Opmerking
Tijdens de experimentele releaseperiode relaxed is dit de enige ondersteunde modus. Als deze controles mislukken, valt de query terug op de brongegevens.
Soorten materialisaties voor metrische weergaven
In de volgende secties worden de typen gerealiseerde weergaven beschreven die beschikbaar zijn voor metrische weergaven.
Geaggregeerd type
Met dit type worden aggregaties vooraf berekend voor opgegeven combinaties van metingen en dimensies voor gerichte dekking.
Dit is nuttig voor het richten op specifieke veelvoorkomende patronen in aggregatiequeries of widgets. Databricks raadt aan potentiële filterkolommen als dimensies op te nemen in de configuratie van de gerealiseerde weergave. Mogelijke filterkolommen zijn kolommen die worden gebruikt tijdens het uitvoeren van query's in de WHERE component.
Niet-geaggregeerd type
Dit type materialiseert het volledige niet-samengevoegde gegevensmodel (bijvoorbeeld de velden source, join en filter) voor een bredere dekking met een lagere prestatieverbetering vergeleken met het geaggregeerde type.
Gebruik dit type als het volgende waar is:
- De bron is een dure weergave of SQL-query.
- Joins die zijn gedefinieerd in uw metrische weergave zijn duur.
Opmerking
Als uw bron een directe tabelverwijzing is zonder selectief filter toe te passen, biedt een niet-samengevoegde gerealiseerde weergave mogelijk geen voordelen.
Materialisatielevenscyclus
In deze sectie wordt uitgelegd hoe materialisaties gedurende hun levenscyclus worden gemaakt, beheerd en vernieuwd.
Aanmaken en aanpassen
Het maken of wijzigen van een metrische weergave (met behulp van CREATE, ALTERof Catalogusverkenner) gebeurt synchroon. De opgegeven gerealiseerde weergaven materialiseren asynchroon met behulp van Lakeflow Spark Declaratieve Pijplijnen.
Wanneer u een kengetalweergave maakt, creëert Databricks een Lakeflow Spark Declarative Pipelines-pijplijn en plant onmiddellijk een initiële update als er gematerialiseerde weergaven zijn opgegeven. De metrische weergave blijft bevraagbaar zonder materialisaties door terug te vallen op het bevragen van de brongegevens.
Wanneer u een metrische weergave wijzigt, worden er geen nieuwe updates gepland, tenzij u materialisatie voor het eerst inschakelt. Gerealiseerde weergaven worden pas gebruikt voor het automatisch herschrijven van query's als de volgende geplande update is voltooid.
Bij het wijzigen van het materialisatieschema wordt geen vernieuwing gestart.
Zie Handmatig vernieuwen voor een nauwkeurigere controle over het vernieuwingsgedrag.
Onderliggende pijplijn controleren
Materialisatie voor metrische weergaven wordt geïmplementeerd met behulp van declaratieve pijplijnen van Lakeflow Spark. Er is een koppeling naar de pijplijn aanwezig op het tabblad Overzicht in Catalog Explorer. Zie Wat is Catalog Explorer?voor meer informatie over toegang tot Catalog Explorer.
U kunt deze pijplijn ook openen door DESCRIBE EXTENDED uit te voeren in de metrieweergave. De sectie Informatie vernieuwen bevat een koppeling naar de pijplijn.
DESCRIBE EXTENDED my_metric_view;
Voorbeelduitvoer:
-- Returns additional metadata such as parent schema, owner, access time etc.
> DESCRIBE TABLE EXTENDED customer;
col_name data_type comment
------------------------------- ------------------------------ ----------
... ... ...
# Detailed Table Information
... ...
Language YAML
Table properties ...
# Refresh information
Latest Refresh status Succeeded
Latest Refresh https://...
Refresh Schedule EVERY 3 HOURS
Handmatig vernieuwen
Via de koppeling naar de pagina Declaratieve pijplijnen van Lakeflow Spark kunt u handmatig een pijplijnupdate starten om de materialisaties bij te werken. U kunt dit ook organiseren met behulp van een API-aanroep op basis van de pijplijn-id.
Met het volgende Python-script wordt bijvoorbeeld een pijplijnvernieuwing gestart:
from databricks.sdk import WorkspaceClient
client = WorkspaceClient()
pipeline_id = "01484540-0a06-414a-b10f-e1b0e8097f15"
client.pipelines.start_update(pipeline_id)
Als u een handmatige vernieuwing wilt uitvoeren als onderdeel van een Lakeflow-taak, maakt u een Python-script met de bovenstaande logica en voegt u het toe als een taak van het type Python-script. U kunt ook een notitieblok maken met dezelfde logica en een taak van het type Notebook toevoegen.
Incrementele vernieuwing
De gerealiseerde weergaven gebruiken waar mogelijk incrementel vernieuwen en hebben dezelfde beperkingen met betrekking tot gegevensbronnen en planstructuur.
Zie Incrementeel vernieuwen voor gerealiseerde weergaven voor details over voorwaarden en beperkingen.
Automatisch opnieuw schrijven van query's
Query's naar een metrische weergave met materialisatie proberen de materialisaties zoveel mogelijk te gebruiken. Er zijn twee strategieën voor het herschrijven van query's: exacte matching en ongesamengestelde matching.

Wanneer u een query uitvoert op een metrische weergave, analyseert de optimizer de query en de beschikbare door de gebruiker gedefinieerde materialisaties. De query wordt automatisch uitgevoerd op de beste materialisatie in plaats van de basistabellen met behulp van dit algoritme:
- Probeert eerst een exacte overeenkomst.
- Als er een niet-samengevoegde materialisatie bestaat, probeert men een niet-samengevoegde overeenkomst.
- Als het herschrijven van query's mislukt, wordt de query rechtstreeks uit de brontabellen gelezen.
Opmerking
Materialiseringen moeten voltooid zijn voordat het herschrijven van queries van kracht kan worden.
Controleren of query gebruikmaakt van gematerialiseerde weergaven
Als u wilt controleren of een query gebruikmaakt van een gerealiseerde weergave, voert u deze uit EXPLAIN EXTENDED op uw query om het queryplan te bekijken. Als de query gebruikmaakt van gematerialiseerde weergaven, bevat het leaf-knooppunt de naam van de materialisatie uit het YAML-bestand.
Het queryprofiel bevat ook dezelfde informatie.
Exacte overeenkomst
Als u in aanmerking wilt komen voor de exacte overeenkomende strategie, moeten de groeperingsexpressies van de query exact overeenkomen met de materialisatiedimensies. De aggregatie-expressies van de query moeten een subset van de materialisatiemetingen zijn.
Niet-geaggregeerde match
Als er een niet-samengevoegde materialisatie beschikbaar is, komt deze strategie altijd in aanmerking.
Billing
Voor het vernieuwen van materialized views worden kosten in rekening gebracht voor het gebruik van Lakeflow Spark Declarative Pipelines.
Bekende beperkingen
De volgende beperkingen gelden voor materialisatie voor metrische weergaven:
- Een metrische weergave met materialisatie die verwijst naar een andere metrische weergave als bron, kan geen niet-samengevoegde materialisatie hebben.