Voorbeeld van het register van werkruimtemodel
Opmerking
Deze documentatie heeft betrekking op het werkruimtemodelregister. Azure Databricks raadt het gebruik van Modellen in Unity Catalog aan. Modellen in Unity Catalog bieden gecentraliseerd modelbeheer, toegang tot meerdere werkruimten, herkomst en implementatie. Werkruimtemodelregister wordt in de toekomst afgeschaft.
In dit voorbeeld ziet u hoe u het werkruimtemodelregister gebruikt om een machine learning-toepassing te bouwen waarmee de dagelijkse stroomuitvoer van een windpark wordt voorspeld. In het voorbeeld ziet u het volgende:
- Modellen bijhouden en registreren met MLflow
- Modellen registreren bij het modelregister
- Modellen beschrijven en overgangen van modelversiefasen maken
- Geregistreerde modellen integreren met productietoepassingen
- Modellen zoeken en detecteren in het modelregister
- Modellen archiveren en verwijderen
In het artikel wordt beschreven hoe u deze stappen uitvoert met behulp van de register-API's en API's voor MLflow-tracering en MLflow-model.
Zie het voorbeeldnotitieblok Modelregister voor een notebook dat al deze stappen uitvoert met behulp van de MLflow Tracking- en Register-API's.
Gegevensset laden, model trainen en bijhouden met MLflow Tracking
Voordat u een model kunt registreren in het modelregister, moet u het model eerst trainen en registreren tijdens de uitvoering van een experiment. In deze sectie wordt beschreven hoe u de gegevensset van het windmolenpark laadt, een model traint en de trainingsuitvoering bij MLflow vaststelt.
Gegevensset laden
Met de volgende code wordt een gegevensset geladen met weergegevens en stroomuitvoerinformatie voor een windpark in de Verenigde Staten. De gegevensset bevat , en air temperature functies die elke zes uur worden bemonsterd (eenmaal om 00:00, eenmaal om 08:00en eenmaal om 16:00), evenals de dagelijkse cumulatieve stroomuitvoer (power), gedurende meerdere wind speedjaren.wind direction
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Model trainen
Met de volgende code wordt een neuraal netwerk getraind met behulp van TensorFlow Keras om de energie-uitvoer te voorspellen op basis van de weerfuncties in de gegevensset. MLflow wordt gebruikt om de hyperparameters, metrische prestatiegegevens, broncode en artefacten van het model bij te houden.
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
Het model registreren en beheren met behulp van de gebruikersinterface van MLflow
In deze sectie:
- Een nieuw geregistreerd model maken
- De gebruikersinterface van het modelregister verkennen
- Modelbeschrijvingen toevoegen
- Een modelversie overzetten
Een nieuw geregistreerd model maken
Navigeer naar de zijbalk MLflow Experiment Runs door te klikken op het pictogram Experiment
 in de rechterzijbalk van het Azure Databricks-notebook.
in de rechterzijbalk van het Azure Databricks-notebook.
Zoek de MLflow-uitvoering die overeenkomt met de trainingssessie van het TensorFlow Keras-model en open deze in de gebruikersinterface van MLflow Run door op het pictogram Details van uitvoering weergeven te klikken.
Schuif in de gebruikersinterface van MLflow omlaag naar de sectie Artefacten en klik op de map met de naam model. Klik op de knop Model registreren die wordt weergegeven.

Selecteer Nieuw model maken in de vervolgkeuzelijst en voer de volgende modelnaam in:
power-forecasting-model.Klik op Registreren. Hiermee wordt een nieuw model met de naam geregistreerd
power-forecasting-modelen wordt een nieuwe modelversie gemaakt:Version 1.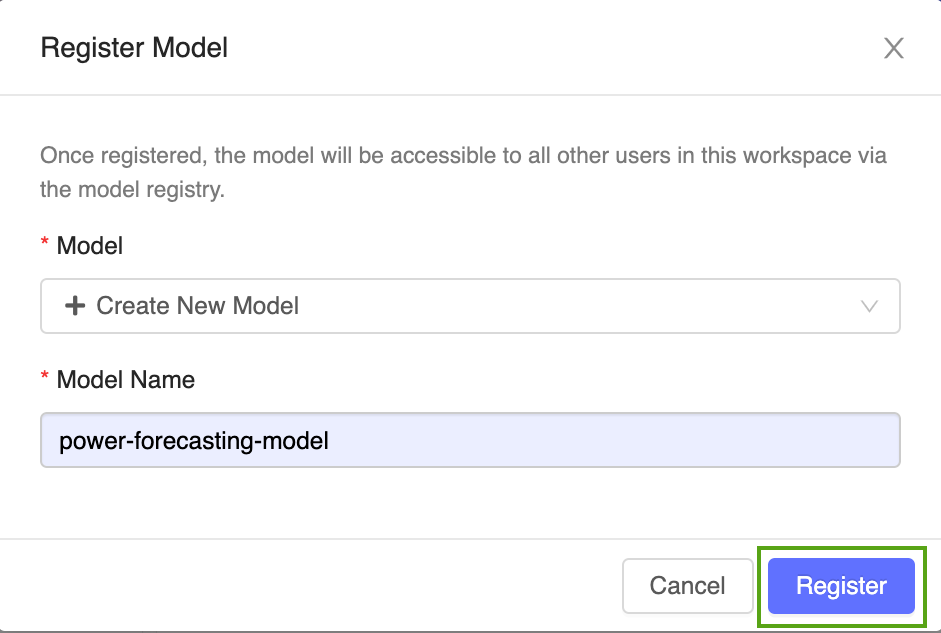
Na enkele ogenblikpen wordt in de gebruikersinterface van MLflow een koppeling naar het nieuwe geregistreerde model weergegeven. Volg deze koppeling om de nieuwe modelversie te openen in de gebruikersinterface van het MLflow-modelregister.
De gebruikersinterface van het modelregister verkennen
De pagina modelversie in de gebruikersinterface van het MLflow-modelregister bevat informatie over Version 1 het geregistreerde prognosemodel, waaronder de auteur, de aanmaaktijd en de huidige fase.
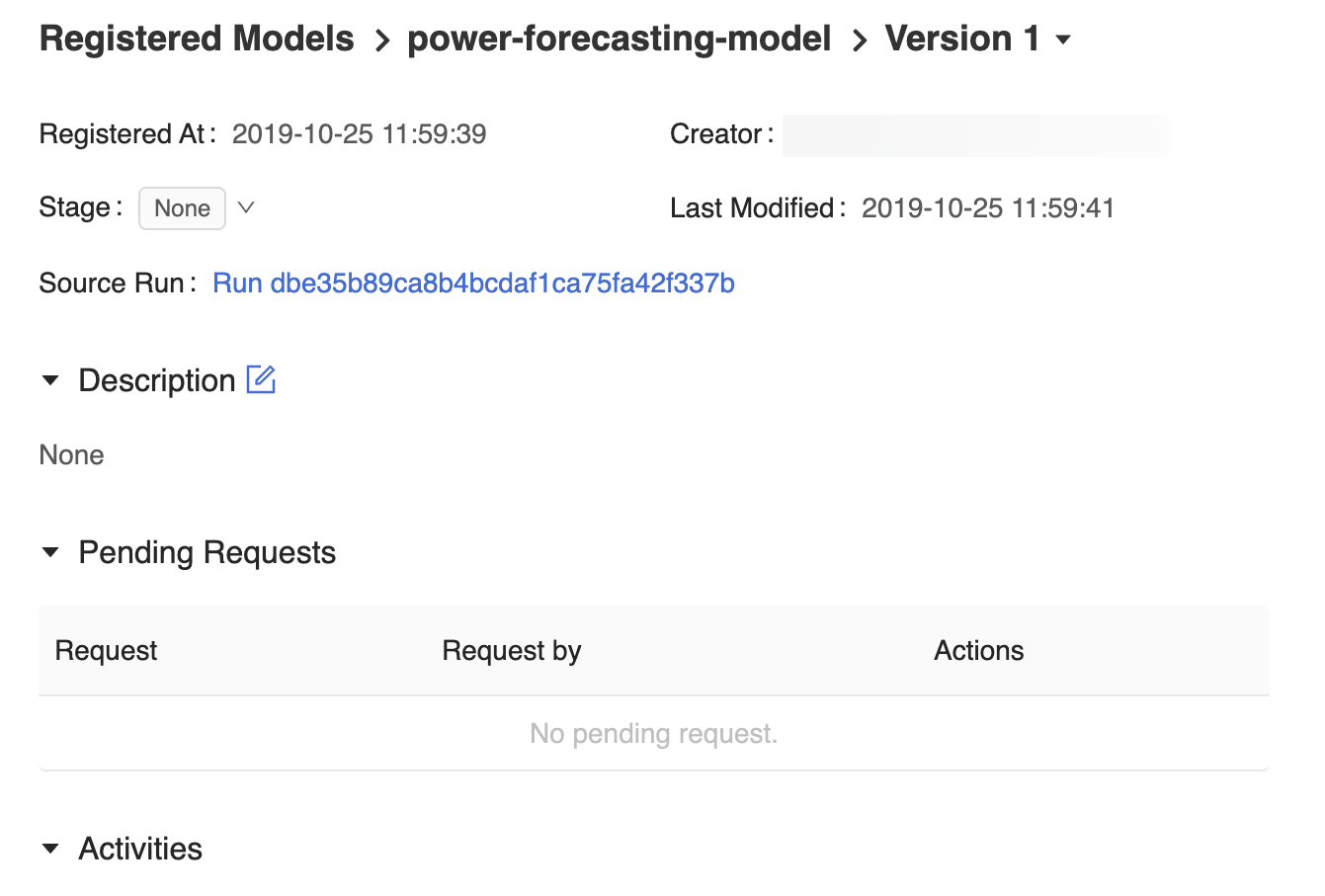
De pagina modelversie bevat ook een koppeling Bronuitvoering , waarmee de MLflow-uitvoering wordt geopend die is gebruikt om het model te maken in de gebruikersinterface van MLflow Run. Vanuit de gebruikersinterface van MLflow Run kunt u de koppeling Bronnotitieblok openen om een momentopname weer te geven van het Azure Databricks-notebook dat is gebruikt om het model te trainen.


Als u terug wilt gaan naar het MLflow-modelregister, klikt u op ![]() in de zijbalk.
in de zijbalk.
Op de resulterende startpagina van het MLflow-modelregister wordt een lijst weergegeven met alle geregistreerde modellen in uw Azure Databricks-werkruimte, inclusief hun versies en fasen.
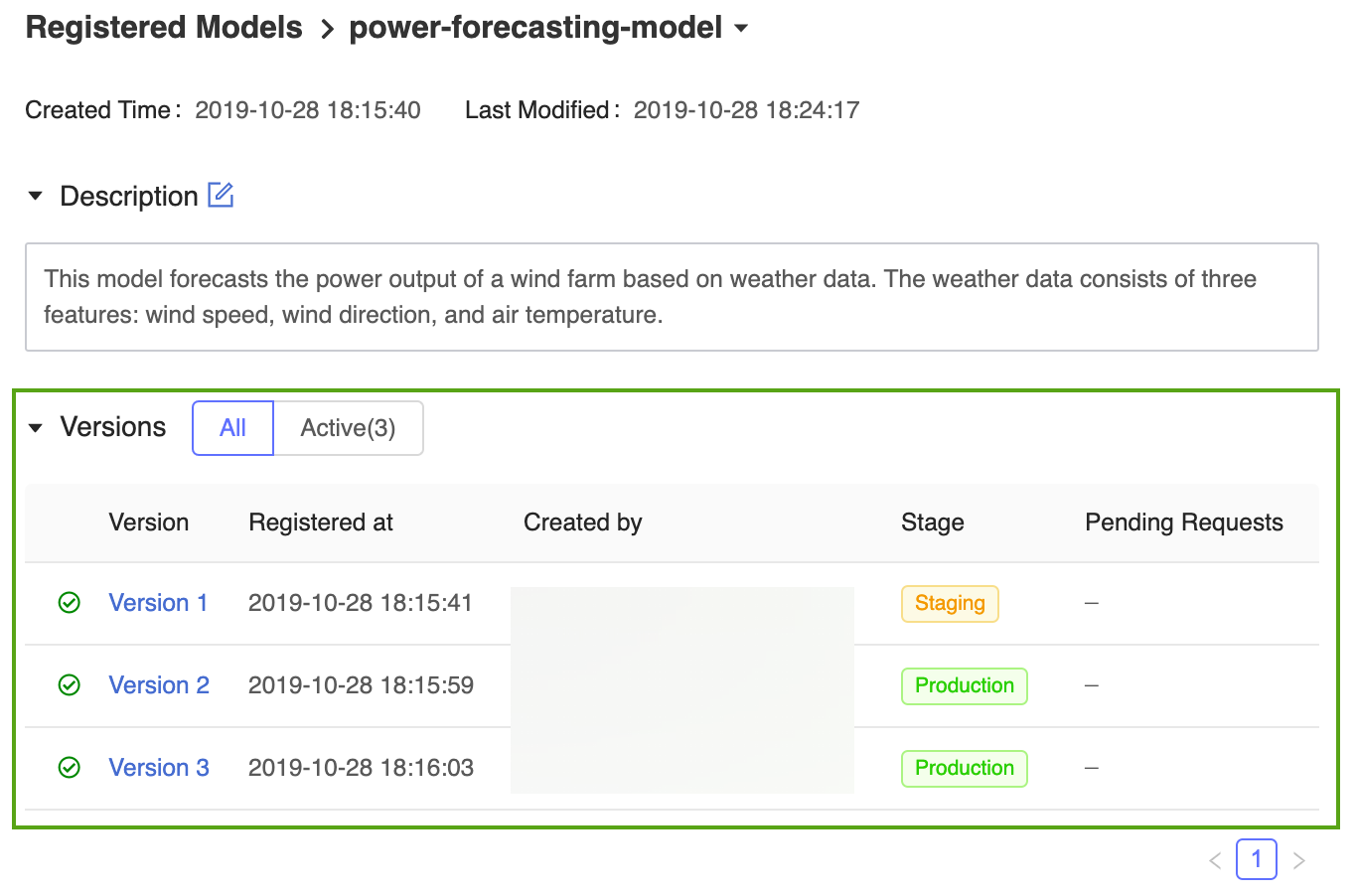
Klik op de koppeling power-forecasting-model om de geregistreerde modelpagina te openen, waarop alle versies van het prognosemodel worden weergegeven.
Modelbeschrijvingen toevoegen
U kunt beschrijvingen toevoegen aan geregistreerde modellen en modelversies. Beschrijvingen van geregistreerde modellen zijn handig voor het vastleggen van informatie die van toepassing is op meerdere modelversies (bijvoorbeeld een algemeen overzicht van het modelleringsprobleem en de gegevensset). Beschrijvingen van modelversies zijn handig voor het beschrijven van de unieke kenmerken van een bepaalde modelversie (bijvoorbeeld de methodologie en het algoritme die worden gebruikt om het model te ontwikkelen).
Voeg een beschrijving op hoog niveau toe aan het geregistreerde model voor energieprognose. Klik op het pictogram
 en voer de volgende beschrijving in:
en voer de volgende beschrijving in:This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.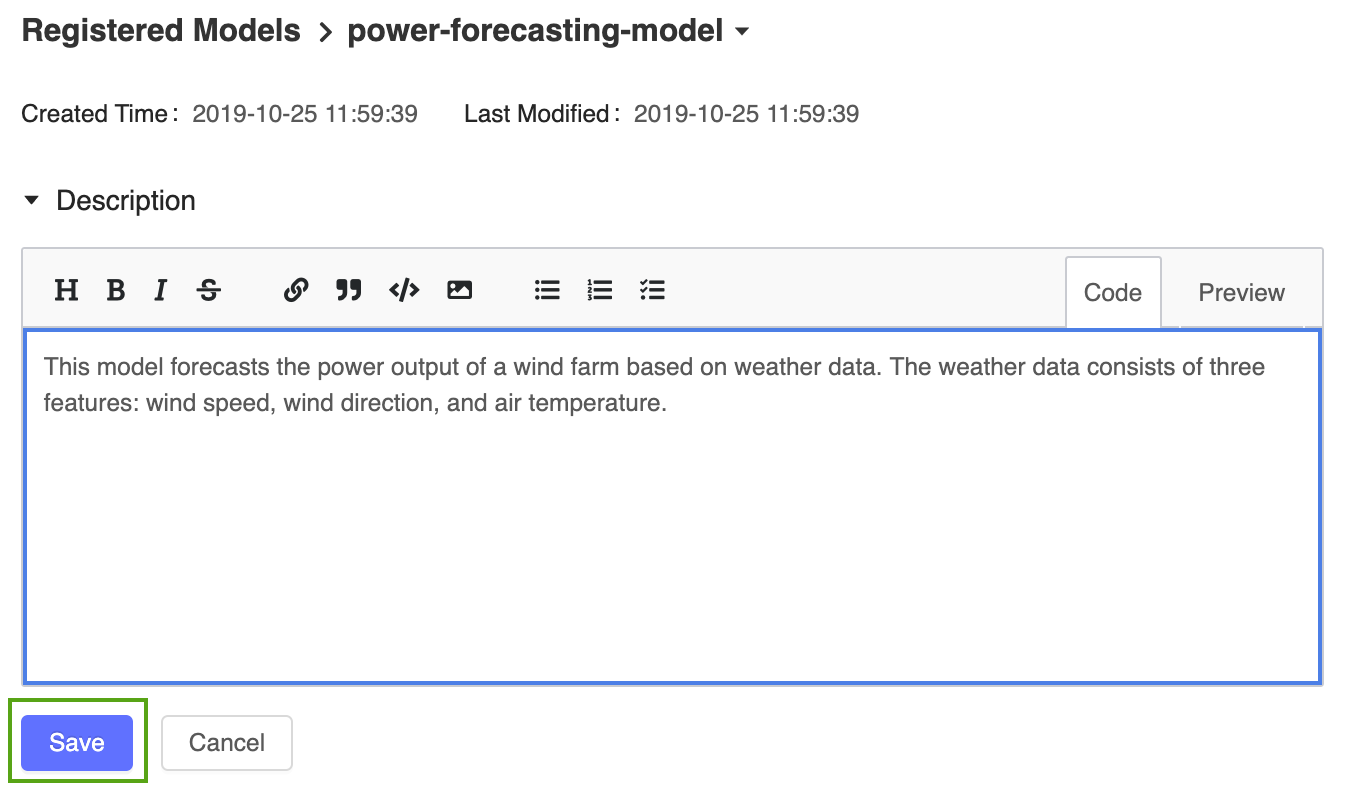
Klik op Opslaan.
Klik op de koppeling Versie 1 op de geregistreerde modelpagina om terug te gaan naar de pagina met de modelversie.
Klik op het pictogram
en voer de volgende beschrijving in:This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.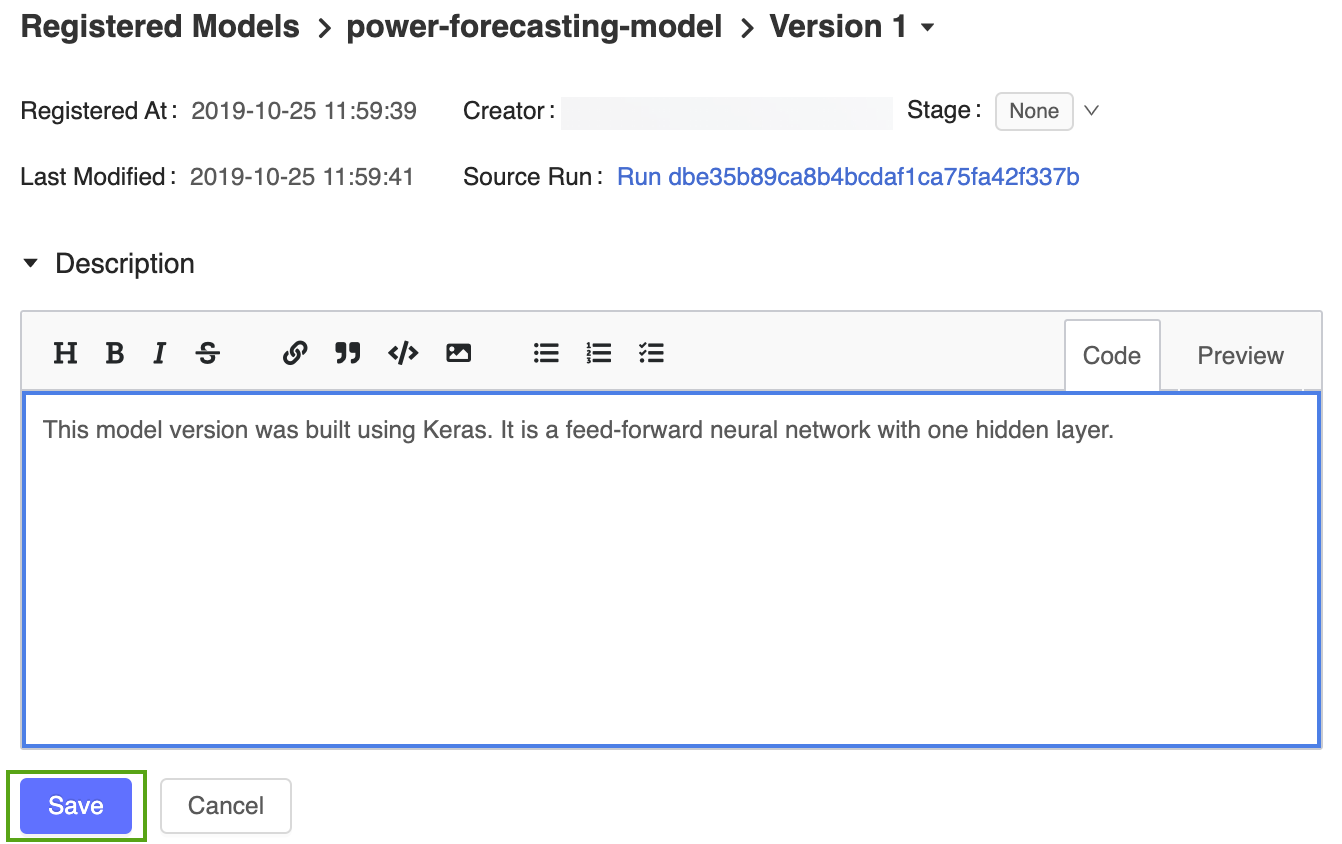
Klik op Opslaan.
Een modelversie overzetten
Het MLflow-modelregister definieert verschillende modelfasen: Geen, Fasering, Productie en Archived. Elke fase heeft een unieke betekenis. Fasering is bijvoorbeeld bedoeld voor modeltests, terwijl Productie is voor modellen die de test- of beoordelingsprocessen hebben voltooid en die zijn geïmplementeerd in toepassingen.
Klik op de knop Fase om de lijst met beschikbare modelfasen en de beschikbare overgangsopties voor fasen weer te geven.
Selecteer Overgang naar -> Productie en druk op OK in het bevestigingsvenster voor faseovergang om het model over te schakelen naar Productie.
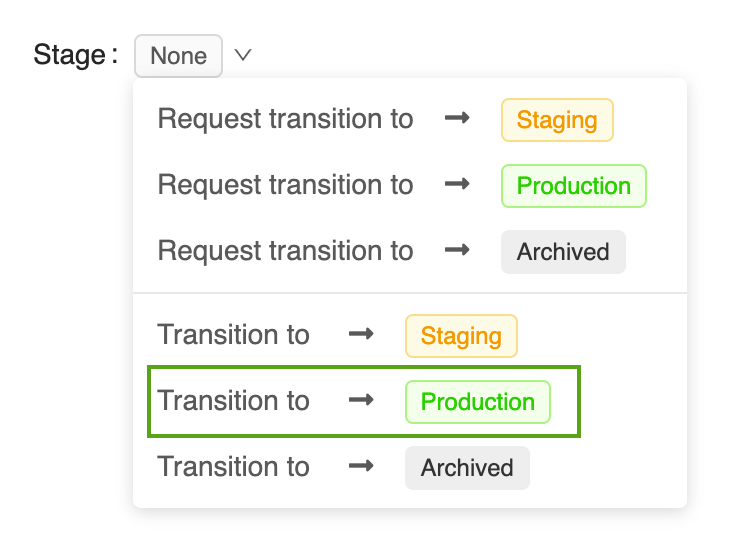
Nadat de modelversie is overgezet naar Productie, wordt de huidige fase weergegeven in de gebruikersinterface en wordt een vermelding toegevoegd aan het activiteitenlogboek om de overgang weer te geven.


Met het MLflow-modelregister kunnen meerdere modelversies dezelfde fase delen. Wanneer u per fase naar een model verwijst, gebruikt het modelregister de nieuwste modelversie (de modelversie met de grootste versie-id). Op de pagina geregistreerd model worden alle versies van een bepaald model weergegeven.
Het model registreren en beheren met behulp van de MLflow-API
In deze sectie:
- De naam van het model programmatisch definiëren
- Het model registreren
- Beschrijvingen van modellen en modelversies toevoegen met behulp van de API
- Een modelversie overzetten en details ophalen met behulp van de API
De naam van het model programmatisch definiëren
Nu het model is geregistreerd en is overgezet naar Productie, kunt u ernaar verwijzen met behulp van programmatische MLflow-API's. Definieer de naam van het geregistreerde model als volgt:
model_name = "power-forecasting-model"
Het model registreren
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
Beschrijvingen van modellen en modelversies toevoegen met behulp van de API
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
Een modelversie overzetten en details ophalen met behulp van de API
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
Versies van het geregistreerde model laden met behulp van de API
Het onderdeel MLflow Models definieert functies voor het laden van modellen uit verschillende machine learning-frameworks. Wordt bijvoorbeeld mlflow.tensorflow.load_model() gebruikt om TensorFlow-modellen te laden die zijn opgeslagen in MLflow-indeling en mlflow.sklearn.load_model() wordt gebruikt om scikit-learn-modellen te laden die zijn opgeslagen in MLflow-indeling.
Met deze functies kunnen modellen uit het register van het MLflow-model worden geladen.
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
Power Output voorspellen met het productiemodel
In deze sectie wordt het productiemodel gebruikt om de weersvoorspellingsgegevens voor het windpark te evalueren. De forecast_power() toepassing laadt de nieuwste versie van het prognosemodel uit de opgegeven fase en gebruikt deze om de stroomproductie in de komende vijf dagen te voorspellen.
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
Een nieuwe modelversie maken
Klassieke machine learning-technieken zijn ook effectief voor energieprognoses. Met de volgende code wordt een willekeurig forestmodel getraind met behulp van scikit-learn en wordt het via de mlflow.sklearn.log_model() functie geregistreerd bij het MLflow-modelregister.
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
De nieuwe modelversie-id ophalen met behulp van zoeken in het MLflow-modelregister
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
Een beschrijving toevoegen aan de nieuwe modelversie
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
De nieuwe modelversie overzetten naar Fasering en het model testen
Voordat u een model implementeert in een productietoepassing, is het vaak de best practice om het te testen in een faseringsomgeving. Met de volgende code wordt de nieuwe modelversie overgezet naar Fasering en worden de prestaties geëvalueerd.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
De nieuwe modelversie implementeren in Productie
Nadat is gecontroleerd of de nieuwe modelversie goed presteert in fasering, wordt met de volgende code het model overgezet naar Productie en wordt exact dezelfde toepassingscode uit de sectie Prognosevermogensuitvoer gebruikt met het productiemodel om een energieprognose te maken.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
Er zijn nu twee modelversies van het prognosemodel in de productiefase : de modelversie die is getraind in het Keras-model en de versie die is getraind in scikit-learn.
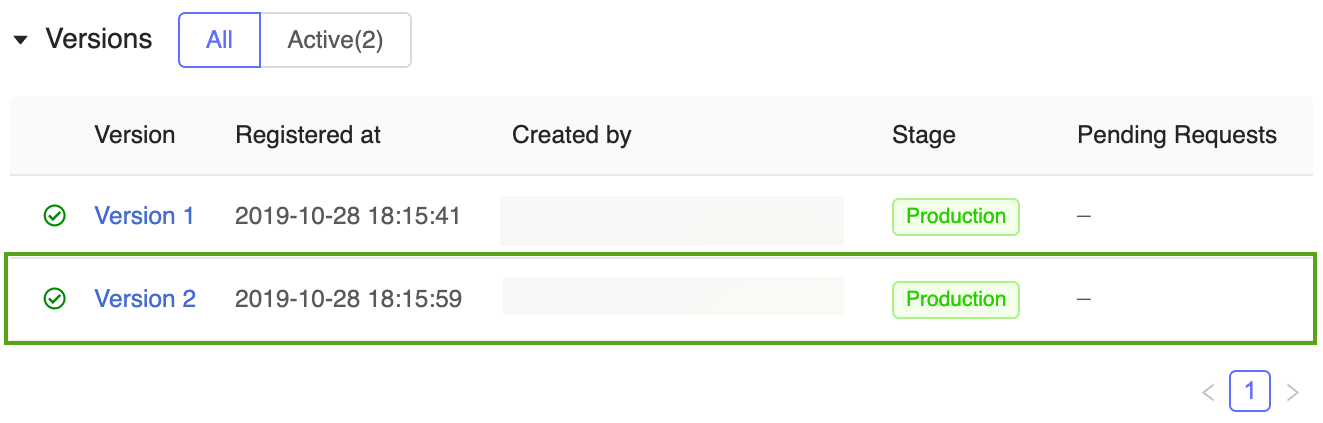
Opmerking
Wanneer u per fase naar een model verwijst, wordt in het MLflow-modelmodelregister automatisch de meest recente productieversie gebruikt. Hierdoor kunt u uw productiemodellen bijwerken zonder toepassingscode te wijzigen.
Modellen archiveren en verwijderen
Wanneer een modelversie niet meer wordt gebruikt, kunt u deze archiveren of verwijderen. U kunt ook een volledig geregistreerd model verwijderen; hiermee worden alle bijbehorende modelversies verwijderd.
Archief Version 1 van het model voor prognose van energie
Archief Version 1 van het energieprognosemodel omdat het niet meer wordt gebruikt. U kunt modellen archiveren in de gebruikersinterface van het MLflow-modelregister of via de MLflow-API.
Archiveren Version 1 in de gebruikersinterface van MLflow
Ga als volgende te werk om het model voor energieprognose te archiveren Version 1 :
Open de bijbehorende modelversiepagina in de gebruikersinterface van het MLflow-modelregister:
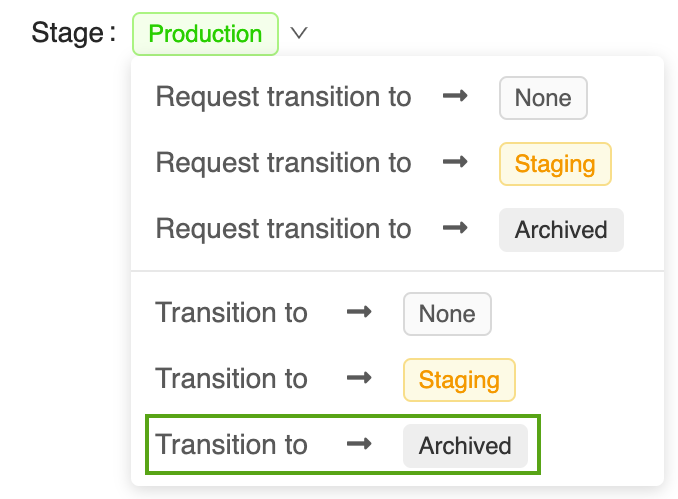
Klik op de knop Fase en selecteer Overgang naar -> Gearchiveerd:
Druk op OK in het bevestigingsvenster van de faseovergang.

Archiveren Version 1 met behulp van de MLflow-API
In de volgende code wordt de MlflowClient.update_model_version() functie gebruikt om het model voor prognose van energie te archiveren Version 1 .
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
Het model voor energieprognose verwijderen Version 1
U kunt ook de MLflow-gebruikersinterface of MLflow-API gebruiken om modelversies te verwijderen.
Waarschuwing
Het verwijderen van de modelversie is permanent en kan niet ongedaan worden gemaakt.
Verwijderen Version 1 in de gebruikersinterface van MLflow
Ga als volgende te werk om het model voor prognose van energie te verwijderen Version 1 :
Open de bijbehorende pagina met de modelversie in de registergebruikersinterface van het MLflow-model.
Selecteer de vervolgkeuzepijl naast de versie-id en klik op Verwijderen.
Verwijderen Version 1 met behulp van de MLflow-API
client.delete_model_version(
name=model_name,
version=1,
)
Het model verwijderen met behulp van de MLflow-API
U moet eerst alle resterende modelversiefasen overzetten naar Geen of Gearchiveerd.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)