Trage Spark-fase met weinig I/O
Als u een trage fase hebt met niet veel I/O, kan dit worden veroorzaakt door:
- Veel kleine bestanden lezen
- Veel kleine bestanden schrijven
- Trage UDF('s)
- Cartesisch lid
- Uitploingsdeelname
Bijna al deze problemen kunnen worden geïdentificeerd met behulp van de SQL DAG.
De SQL DAG openen
Als u de SQL DAG wilt openen, schuift u omhoog naar de bovenkant van de pagina van de taak en klikt u op Gekoppelde SQL-query:

U zou nu de DAG moeten zien. Als dat niet het geval is, schuift u even rond en ziet u het volgende:
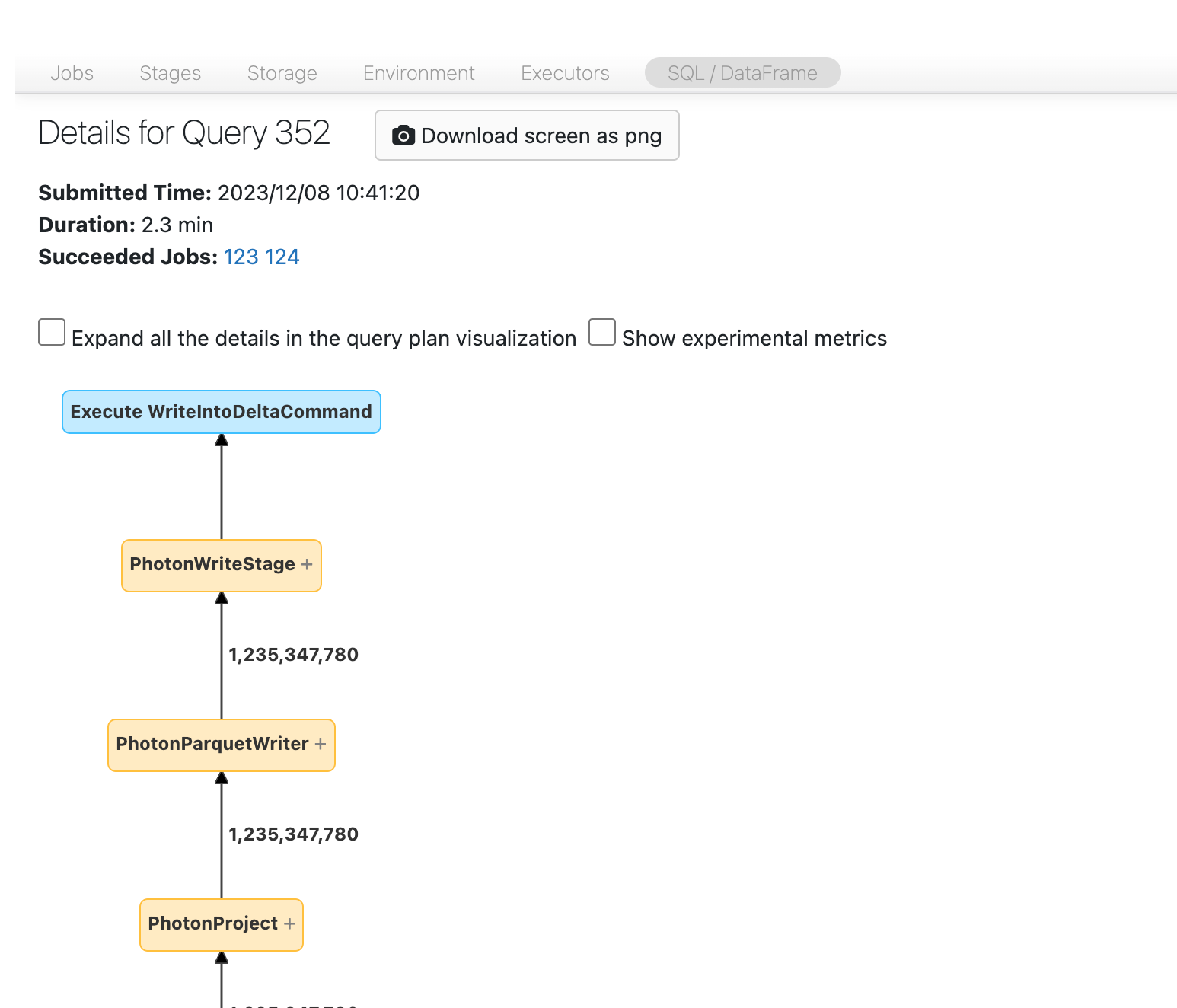
Voordat u verdergaat, moet u vertrouwd raken met de DAG en waar de tijd wordt besteed. Sommige knooppunten in de DAG hebben nuttige tijdinformatie en andere niet. Dit blok duurde bijvoorbeeld 2,1 minuten en biedt zelfs de fase-id:

Voor dit knooppunt moet u het openen om te zien dat het 1,4 minuten duurde:
Deze tijden zijn cumulatief, dus het is de totale tijd die is besteed aan alle taken, niet de kloktijd. Maar het is nog steeds erg nuttig omdat ze zijn gecorreleerd met tijd en kosten van de klok.
Het is handig om vertrouwd te raken met waar in de DAG de tijd wordt besteed.
Veel kleine bestanden lezen
Als een van uw scanoperators veel tijd in beslag neemt, opent u deze en zoekt u het aantal bestanden dat wordt gelezen:
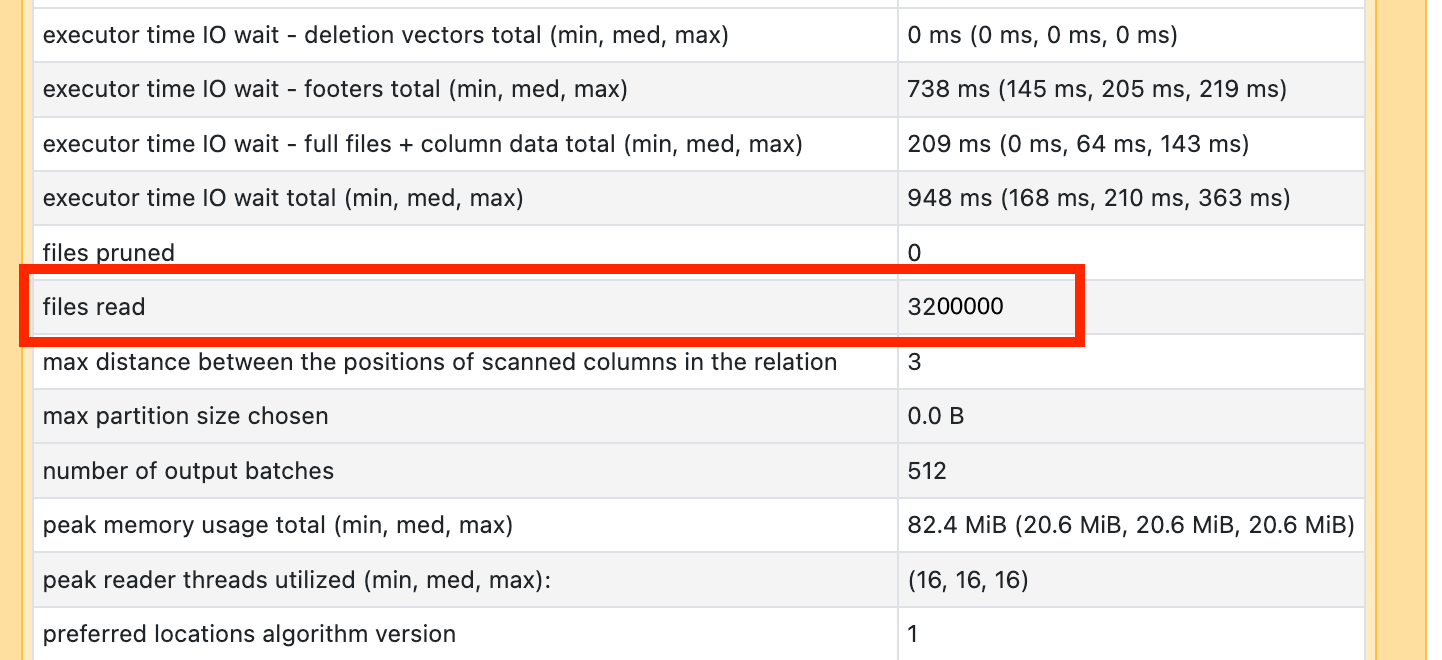
Als u tienduizenden bestanden of meer leest, is er mogelijk een probleem met een klein bestand. Uw bestanden mogen niet minder dan 8 MB zijn. Het probleem met het kleine bestand wordt meestal veroorzaakt door partitionering op te veel kolommen of een kolom met hoge kardinaliteit.
Als u geluk hebt, moet u mogelijk alleen OPTIMIZE uitvoeren. Ongeacht of u de bestandsindeling opnieuw moet bekijken.
Veel kleine bestanden schrijven
Als het lang duurt voordat uw schrijfbewerking duurt, opent u deze en zoekt u het aantal bestanden en hoeveel gegevens er zijn geschreven:
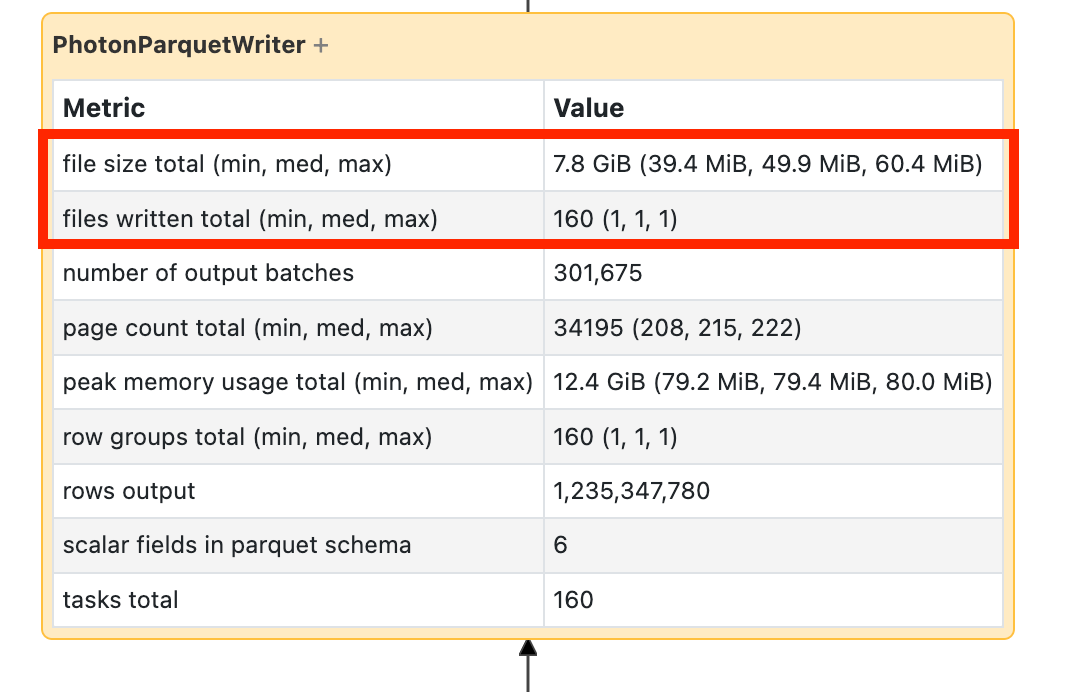
Als u tienduizenden bestanden of meer schrijft, is er mogelijk een klein probleem met het bestand. Uw bestanden mogen niet minder dan 8 MB zijn. Het probleem met het kleine bestand wordt meestal veroorzaakt door partitionering op te veel kolommen of een kolom met hoge kardinaliteit. U moet de indeling van uw bestand herzien of geoptimaliseerde schrijfbewerkingen inschakelen.
Langzame UDF's
Als u weet dat u UDF's hebt of zoiets ziet in uw DAG, hebt u mogelijk last van trage UDF's:
Als u denkt dat u last hebt van dit probleem, kunt u uw UDF commentaar geven om te zien hoe dit van invloed is op de snelheid van uw pijplijn. Als de UDF inderdaad is waar de tijd wordt besteed, kunt u het beste de UDF herschrijven met behulp van systeemeigen functies. Als dat niet mogelijk is, moet u rekening houden met het aantal taken in de fase waarin uw UDF wordt uitgevoerd. Als dit minder is dan het aantal kernen in uw cluster, repartition() gebruikt u het dataframe voordat u de UDF gebruikt:
(df
.repartition(num_cores)
.withColumn('new_col', udf(...))
)
UDF's kunnen ook last hebben van geheugenproblemen. Houd er rekening mee dat elke taak mogelijk alle gegevens in de partitie in het geheugen moet laden. Als deze gegevens te groot zijn, kunnen dingen erg traag of instabiel worden. U kunt dit probleem ook oplossen door elke taak kleiner te maken.
Cartesisch lid
Als u een cartesische join of geneste lus in uw DAG ziet, moet u weten dat deze joins erg duur zijn. Zorg ervoor dat dat is wat u bedoelde en kijk of er een andere manier is.
Ontploffende join of exploderen
Als u een paar rijen ziet die naar een knooppunt gaan en er meer grootten komen, hebt u mogelijk last van een ontploffende join of explode():

Lees meer over exploderen in de Handleiding voor Databricks Optimization.