Het identificeren van een dure leesbewerking in Spark's DAG
Naar de DAG
Ervan uitgaande dat u naar een dure taak kijkt, hebben we eerst de id nodig van de fase die de leesbewerking uitvoert. Hier ziet u dat de fase-id 194 is:

Nu moeten we naar de SQL DAG gaan. Schuif omhoog naar de bovenkant van de pagina van de taak en klik op de gekoppelde SQL-query:

U zou nu de DAG moeten zien. Als dat niet het geval is, schuift u even rond en ziet u het volgende:
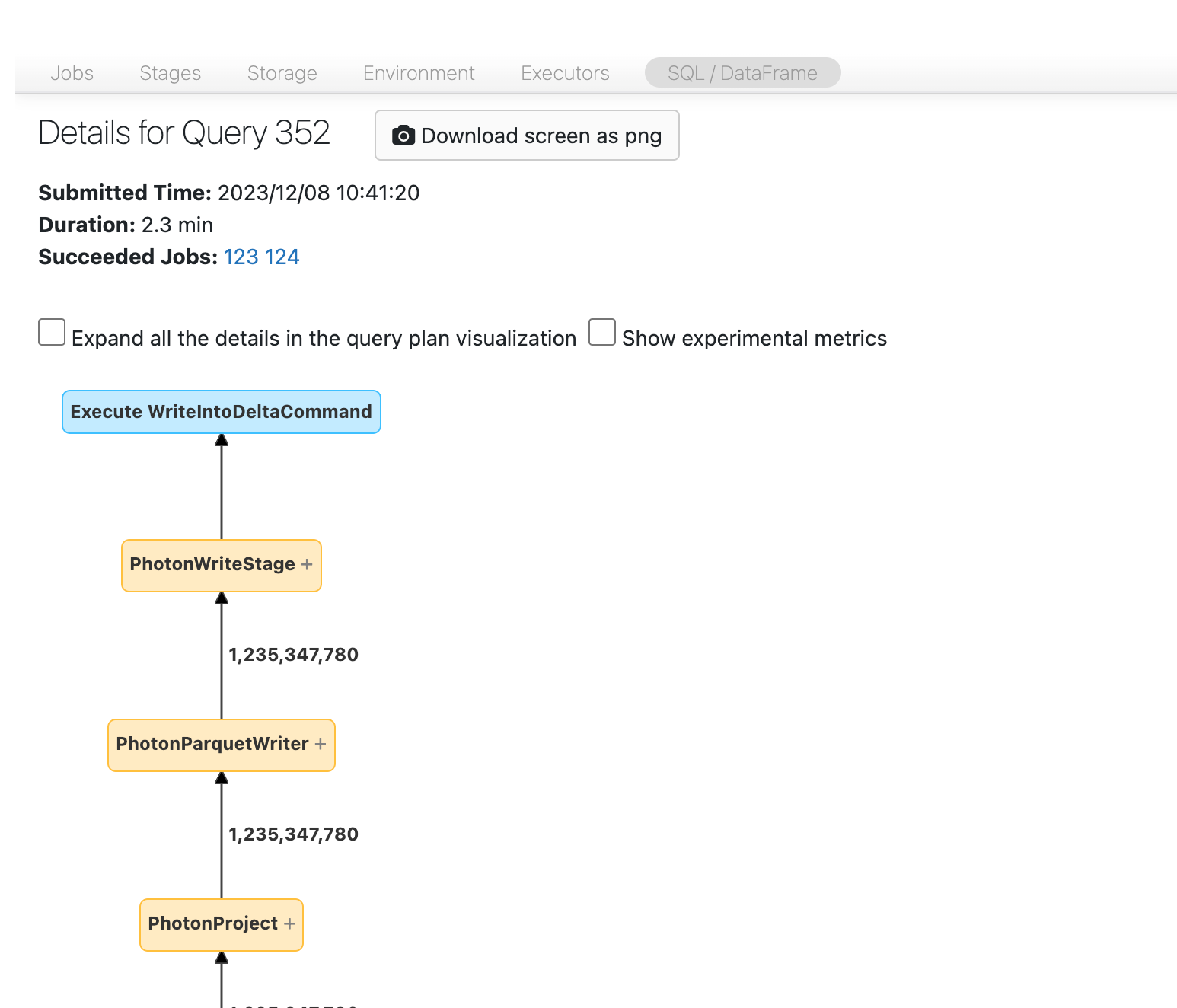
In sommige gevallen kunt u de DAG volgen en zien waar de gegevens vandaan komen. Zoek in andere gevallen naar de fase-id die u hebt genoteerd:

Vervolgens moet u zoeken naar het knooppunt Scannen. In dit geval is het vrij eenvoudig om te zeggen dat we een tabel met de naam transactionslezen:

In sommige gevallen moet u mogelijk op het knooppunt klikken of het knooppunt overrollen om de locatie op te halen van de gegevens die u leest.