Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Databricks Git-mappen kunnen worden gebruikt in uw CI/CD-stromen. Door Databricks Git-mappen in de werkruimte te configureren, kunt u broncodebeheer gebruiken voor werk in Git-opslagplaatsen en deze integreren in uw data engineering-werkstromen. Zie CI/CD in Azure Databricks voor een uitgebreider overzicht van CI/CD met Azure Databricks.
Gebruiksstromen
Het grootste deel van het werk bij het ontwikkelen van automatisering voor Git-mappen bevindt zich in de eerste configuratie voor uw mappen en het begrijpen van de Repos REST API van Azure Databricks, die u gebruikt om Git-bewerkingen vanuit Azure Databricks-taken te automatiseren. Voordat u begint met het bouwen van uw automatisering en het instellen van mappen, bekijkt u de externe Git-opslagplaatsen die u in uw automatiseringsstromen gaat opnemen en selecteert u de juiste voor de verschillende fasen van uw automatisering, waaronder ontwikkeling, integratie, fasering en productie.
- Beheerstroom: Voor productiestromen stelt een Beheerder van de Azure Databricks-werkruimte mappen op het hoogste niveau in uw werkruimte in om de git-mappen voor productie te hosten. De beheerder kloont een Git-opslagplaats en vertakking bij het maken ervan en kan deze mappen betekenisvolle namen geven, zoals 'Productie', 'Testen' of 'Fasering', die overeenkomen met het doel van de externe Git-opslagplaatsen in uw ontwikkelstromen. Zie de map Productie git voor meer informatie.
-
Gebruikersstroom: Een gebruiker kan een Git-map maken op
/Workspace/Users/<email>/basis van een externe Git-opslagplaats. Een gebruiker maakt een lokale gebruikersspecifieke vertakking voor het werk dat de gebruiker doorvoert en pusht naar de externe opslagplaats. Zie Samenwerken met Behulp van Git-mappen voor informatie over samenwerken in gebruikersspecifieke Git-mappen. - Samenvoegstroom: gebruikers kunnen pull-aanvragen (PULL's) maken na het pushen vanuit een Git-map. Wanneer de pull request wordt samengevoegd, kan automatisering de wijzigingen in de Git-productiemappen ophalen met behulp van de Azure Databricks Repos API.
Samenwerken met Behulp van Git-mappen
U kunt eenvoudig samenwerken met anderen met behulp van Git-mappen, updates ophalen en wijzigingen rechtstreeks vanuit de Gebruikersinterface van Azure Databricks pushen. Gebruik bijvoorbeeld een functie- of ontwikkelingsbranch om wijzigingen in meerdere vertakkingen samen te voegen.
In de volgende stroom wordt beschreven hoe u kunt samenwerken met behulp van een functiebranch:
- Kloon uw bestaande Git-opslagplaats naar uw Databricks-werkruimte.
- Gebruik de gebruikersinterface van Git-mappen om een functiebranch te maken vanuit de hoofdbranch . U kunt meerdere functiebranches maken en gebruiken om uw werk te doen.
- Breng uw wijzigingen aan in Azure Databricks-notebooks en andere bestanden in de opslagplaats.
- Voer uw wijzigingen door en push deze naar de externe Git-opslagplaats.
- Inzenders kunnen nu de Git-opslagplaats klonen in hun eigen gebruikersmap.
- Een collega werkt aan een nieuwe vertakking en brengt wijzigingen aan in de notebooks en andere bestanden in de Git-map.
- De inzender doorvoert en pusht de wijzigingen naar de externe Git-opslagplaats.
- Wanneer u of andere bijdragers klaar zijn om de code samen te voegen, maakt u een pull request aan op de website van de Git-provider. Controleer uw code met uw team voordat u de wijzigingen samenvoegt in de implementatiebranch.
Opmerking
Databricks raadt aan dat elke ontwikkelaar aan een eigen vertakking werkt. Zie Samenvoegingsconflicten oplossen voor informatie over het oplossen van samenvoegingsconflicten.
Een CI/CD-benadering kiezen
Databricks raadt het gebruik van Databricks Asset Bundles aan om uw CI/CD-werkstromen te verpakken en te implementeren. Als u liever alleen broncodebeheerde code in de werkruimte implementeert, kunt u een Git-productiemap instellen. Zie CI/CD in Azure Databricks voor een uitgebreider overzicht van CI/CD met Azure Databricks.
Aanbeveling
Definieer resources zoals taken en pijplijnen in bronbestanden met behulp van bundels, en maak, implementeer en beheer bundels in Git-mappen in werkruimten. Zie Samenwerken aan bundels in de werkruimte.
Git productie-map
Productie-Git-mappen hebben een ander doel dan Git-mappen op gebruikersniveau in uw gebruikersmap in /Workspace/Users/. Git-mappen op gebruikersniveau fungeren als lokale kassa's, waar gebruikers wijzigingen in code ontwikkelen en pushen. Daarentegen worden productie-Git-mappen gemaakt door Databricks-beheerders buiten gebruikersmappen en bevatten ze productie-implementatiebranches. Git-mappen voor productie bevatten de broncode voor geautomatiseerde workflows en moeten alleen programmatig worden bijgewerkt wanneer pull-verzoeken (PR's) worden samengevoegd in de implementatiebranches. Voor Git-mappen in productie beperkt u de gebruikersrechten tot alleen uitvoeren en moeten alleen beheerders en Azure Databricks-service-principals kunnen bewerken.
Een Git-productiemap maken:
Kies een Git-opslagplaats en -vertakking voor de implementatie.
Haal een service-principal op en configureer een Git-referentie voor de service-principal voor toegang tot deze Git-opslagplaats.
Maak een Azure Databricks Git-map voor de Git-opslagplaats en de branch in een submap onder
Workspace, die gewijd is aan een project, team, en ontwikkelingsfase.Selecteer Delen nadat u de map of Share (Machtigingen) hebt geselecteerd door met de rechtermuisknop op de map onder de werkruimtestructuur te klikken. Configureer de Git-map met de volgende machtigingen:
- Kan worden uitgevoerd instellen voor alle projectgebruikers
- Stel Kan Runnen in voor elke service-principalaccount van Azure Databricks die automatisering daarvoor zal uitvoeren.
- Indien van toepassing op uw project, stelt u Kan weergeven in voor alle gebruikers in de werkruimte om detectie en delen aan te moedigen.
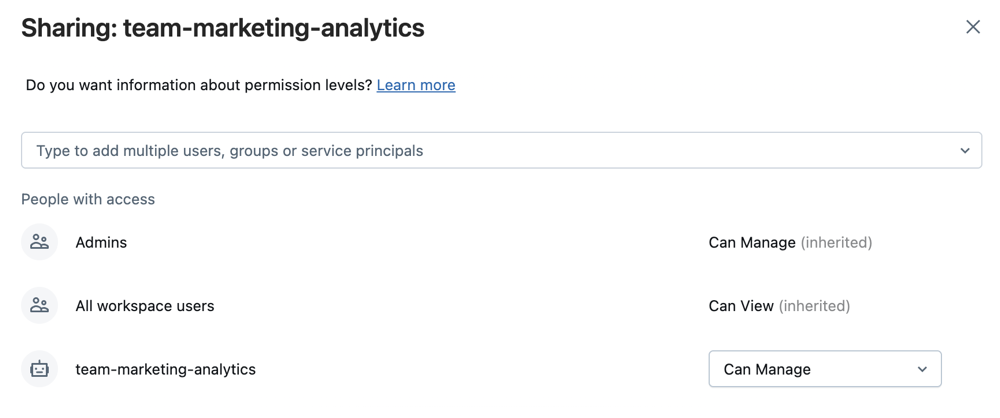
Selecteer Toevoegen.
Automatische updates voor Databricks Git-mappen instellen. U kunt automatisering gebruiken om een Git-productiemap synchroon te houden met de externe vertakking door een van de volgende handelingen uit te voeren:
- Gebruik externe CI/CD-hulpprogramma's zoals GitHub Actions om de meest recente commits naar een productie-Git-map te halen wanneer een pull request wordt samengevoegd in de implementatietak. Zie voor een voorbeeld van GitHub Actions Een CI/CD-werkstroom uitvoeren om een productie-Git-map bij te werken.
- Als u geen toegang hebt tot externe CI/CD-tools, maakt u een geplande taak om een Git-map in uw werkruimte bij te werken met de externe vertakking. Plan een eenvoudig notebook met de volgende code die periodiek moet worden uitgevoerd:
from databricks.sdk import WorkspaceClient w = WorkspaceClient() w.repos.update(w.workspace.get_status(path=”<git-folder-workspace-full-path>”).object_id, branch=”<branch-name>”)
Zie de Documentatie van de Databricks REST API voor Repos voor meer informatie over automatisering met de Azure Databricks Repos API.