Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
De General Data Protection Regulation (AVG) en California Consumer Privacy Act (CCPA) zijn privacy- en gegevensbeveiligingsregels die bedrijven verplichten alle persoonlijk identificeerbare informatie (PII) die op hun expliciete verzoek is verzameld over een klant definitief en volledig te verwijderen. Ook wel bekend als het "recht om te vergeten" (RTBF) of "recht op gegevensverwijdering", moeten verwijderingsaanvragen worden uitgevoerd tijdens een opgegeven periode (bijvoorbeeld binnen één kalendermaand).
In dit artikel wordt uitgelegd hoe u RTBF implementeert op gegevens die zijn opgeslagen in Databricks. Het voorbeeld in dit artikel modelleert gegevenssets voor een e-commercebedrijf en laat zien hoe u gegevens in brontabellen verwijdert en deze wijzigingen doorgeeft aan downstreamtabellen.
Blauwdruk voor het implementeren van het 'recht om te vergeten'
In het volgende diagram ziet u hoe u het 'recht om te vergeten' implementeert.
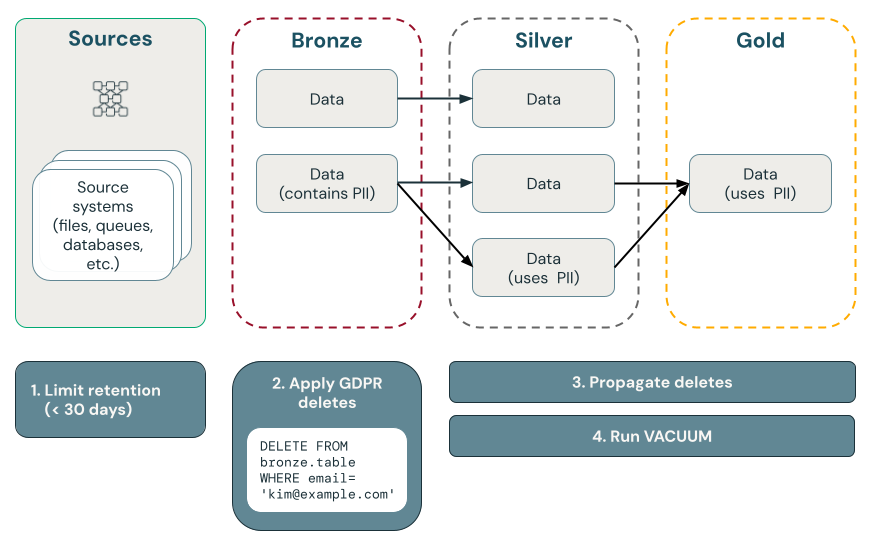
punt wordt verwijderd met Delta Lake
Delta Lake versnelt het verwijderen van punten in grote data lakes met ACID-transacties, zodat u persoonlijke idenfiable informatie (PII) kunt vinden en verwijderen als reactie op AVG- of CCPA-aanvragen van de consument.
Delta Lake behoudt de tabelgeschiedenis en maakt deze beschikbaar voor point-in-time-query's en terugdraaiacties. Met de functie VACUUM worden gegevensbestanden verwijderd waarnaar niet meer wordt verwezen door een Delta-tabel en die ouder zijn dan een opgegeven retentiedrempel, waardoor de gegevens permanent worden verwijderd. Zie Werken met Delta Lake-tabelgeschiedenisvoor meer informatie over standaardinstellingen en aanbevelingen.
Zorg ervoor dat gegevens worden verwijderd bij het gebruik van verwijderingsvectoren
Voor tabellen waarvoor verwijderingsvectoren zijn ingeschakeld, moet u na het verwijderen van records ook uitvoeren REORG TABLE ... APPLY (PURGE) om onderliggende records permanent te verwijderen. Dit omvat Delta Lake-tabellen, gematerialiseerde weergaven en streaming-tabellen. Zie Wijzigingen toepassen op Parquet-gegevensbestanden.
Gegevens in upstream-bronnen verwijderen
AVG en CCPA zijn van toepassing op alle gegevens, inclusief gegevens in bronnen buiten Delta Lake, zoals Kafka, bestanden en databases. Naast het verwijderen van gegevens in Databricks, moet u ook gegevens verwijderen in upstream-bronnen, zoals wachtrijen en cloudopslag.
Volledige verwijdering verdient de voorkeur boven verdoezeling
U moet kiezen tussen het verwijderen van gegevens en het verduisteren ervan. Verdoofing kan worden geïmplementeerd met behulp van gepseudonimisering, gegevensmaskering, enzovoort. De veiligste optie is echter volledige verwijdering, omdat in de praktijk het risico van heridentificatie wordt geëlimineerd, vaak een volledige verwijdering van PII-gegevens vereist.
Gegevens in bronslaag verwijderen en verwijderingen vervolgens doorgeven aan zilveren en gouden lagen
We raden u aan de AVG- en CCPA-naleving te starten door eerst gegevens in de bronslaag te verwijderen, op basis van een geplande taak die een query uitvoert op een controletabel met verwijderingsaanvragen. Nadat gegevens uit de bronslaag zijn verwijderd, kunnen wijzigingen worden doorgegeven aan zilveren en gouden lagen.
Tabellen regelmatig onderhouden om gegevens uit historische bestanden te verwijderen
Delta Lake behoudt standaard de tabelgeschiedenis, inclusief verwijderde records, gedurende 30 dagen en maakt deze beschikbaar voor tijdreizen en terugdraaiacties. Maar zelfs als eerdere versies van de gegevens worden verwijderd, blijven de gegevens behouden in de cloudopslag. Daarom moet u regelmatig tabellen en weergaven onderhouden om eerdere versies van gegevens te verwijderen. De aanbevolen manier is Voorspellende optimalisatie voor beheerde tabellen van Unity Catalog, die op intelligente wijze zowel streamingtabellen als gerealiseerde weergaven onderhouden.
- Voor tabellen die worden beheerd door voorspellende optimalisatie, onderhoudt Lakeflow declaratieve pijplijnen op intelligente wijze zowel streamingtabellen als gerealiseerde weergaven, op basis van gebruikspatronen.
- Voor tabellen zonder ingeschakelde voorspellende optimalisatie voert Lakeflow Declaratieve Pijplijnen automatisch onderhoudstaken uit binnen 24 uur na het bijwerken van streamingtabellen en gerealiseerde weergaven.
Als u geen voorspellende optimalisatie of Lakeflow Declarative Pipelines gebruikt, moet u een VACUUM opdracht uitvoeren in Delta-tabellen om eerdere versies van gegevens permanent te verwijderen. Dit vermindert standaard de reismogelijkheden tot 7 dagen. Dit is een configureerbare instellingen verwijdert ook historische versies van de betreffende gegevens uit de cloudopslag.
PII-gegevens verwijderen uit de bronslaag
Afhankelijk van het ontwerp van uw lakehouse, kunt u mogelijk de koppeling tussen PII- en niet-PII-gebruikersgegevens verbreken. Als u bijvoorbeeld een niet-natuurlijke sleutel gebruikt, zoals user_id in plaats van een natuurlijke sleutel, zoals e-mail, kunt u PII-gegevens verwijderen, waardoor niet-PII-gegevens aanwezig blijven.
De rest van dit artikel behandelt RTBF door gebruikersgegevens volledig te verwijderen uit alle bronze-tabellen. U kunt gegevens verwijderen door een DELETE opdracht uit te voeren, zoals wordt weergegeven in de volgende code:
spark.sql("DELETE FROM bronze.users WHERE user_id = 5")
Wanneer u een groot aantal records tegelijk verwijdert, wordt u aangeraden de opdracht MERGE te gebruiken. In de onderstaande code wordt ervan uitgegaan dat u een besturingstabel hebt met de naam gdpr_control_table die een user_id kolom bevat. U voegt een record in deze tabel in voor elke gebruiker die het 'recht om te vergeten' heeft aangevraagd in deze tabel.
Met de opdracht MERGE geeft u de voorwaarde voor overeenkomende rijen op. In dit voorbeeld komen records uit target_table overeen met records in gdpr_control_table op basis van de user_id. Als er een overeenkomst is (bijvoorbeeld een user_id in zowel de target_table als de gdpr_control_table), wordt de rij in de target_table verwijderd. Nadat deze MERGE opdracht is geslaagd, werkt u de besturingstabel bij om te bevestigen dat de aanvraag is verwerkt.
spark.sql("""
MERGE INTO target
USING (
SELECT user_id
FROM gdpr_control_table
) AS source
ON target.user_id = source.user_id
WHEN MATCHED THEN DELETE
""")
Wijzigingen doorvoeren van brons naar de zilver- en goudlagen
Nadat gegevens in de bronslaag zijn verwijderd, moet u de wijzigingen doorgeven aan tabellen in de zilveren en gouden lagen.
Materiële weergaven: verwijderingen automatisch afhandelen
Gematerialiseerde weergaven verwerken automatisch verwijderingen in bronnen. Daarom hoeft u niets speciaals te doen om ervoor te zorgen dat een gerealiseerde weergave geen gegevens bevat die uit een bron zijn verwijderd. U moet een gerealiseerde weergave vernieuwen en onderhoud uitvoeren om ervoor te zorgen dat verwijderingen volledig worden verwerkt.
Een gerealiseerde weergave retourneert altijd het juiste resultaat omdat er incrementele berekeningen worden gebruikt als deze goedkoper is dan volledige hercomputatie, maar nooit ten koste van de juistheid. Met andere woorden, het verwijderen van gegevens uit een bron kan ertoe leiden dat een gerealiseerde weergave volledig opnieuw wordt gecomputeerd.
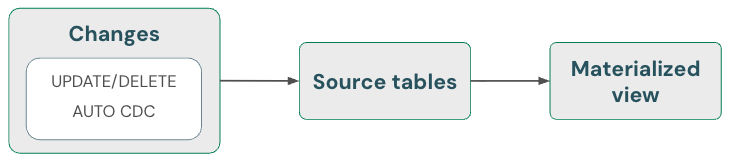
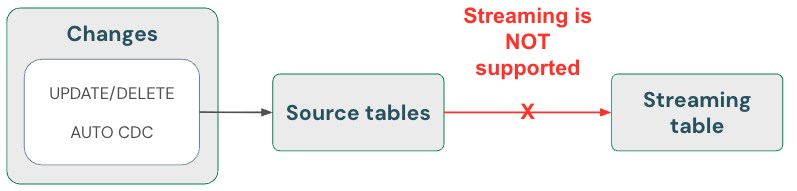
Streamingtabellen: gegevens verwijderen en streamingbron lezen met skipChangeCommits
Streamingtabellen kunnen alleen gegevens verwerken die alleen kunnen worden toegevoegd. Streamingtabellen verwachten dus alleen nieuwe rijen met gegevens die in de streamingbron worden weergegeven. Elke andere bewerking, zoals het bijwerken of verwijderen van een record uit een brontabel die wordt gebruikt voor streaming, wordt niet ondersteund en onderbreekt de stroom.
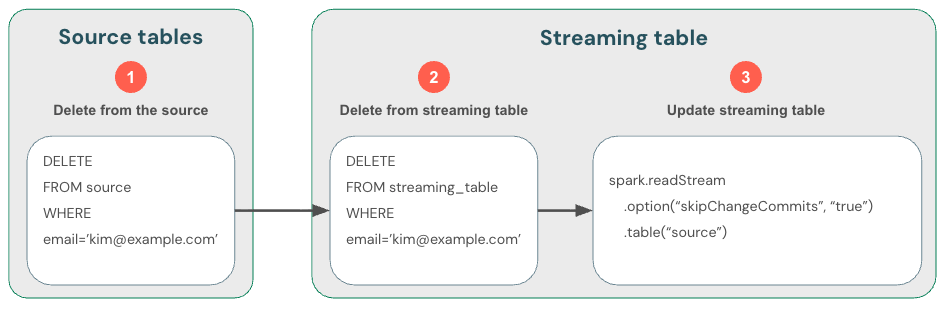
Omdat streaming alleen nieuwe gegevens verwerkt, moet u zelf wijzigingen in gegevens afhandelen. De aanbevolen methode is om: (1) gegevens in de streamingbron te verwijderen, (2) gegevens uit de streamingtabel te verwijderen en vervolgens (3) de streaming-leesbewerking bij te werken om skipChangeCommitste gebruiken. De vlag geeft aan Databricks dat de streamingtabel alles behalve invoegingen moet overslaan, zoals updates of verwijderingen.
U kunt ook (1) gegevens uit de bron verwijderen(2) uit de streamingtabel en vervolgens (3) de streamingtabel volledig vernieuwen. Wanneer u een streamingtabel volledig vernieuwt, wordt de streamingstatus van de tabel gewist en worden alle gegevens opnieuw verwerkt. Een upstream-gegevensbron die zich buiten de bewaarperiode bevindt (bijvoorbeeld een Kafka-onderwerp dat gegevens na 7 dagen veroudert), wordt niet opnieuw verwerkt, wat gegevensverlies kan veroorzaken. We raden deze optie alleen aan voor streamingtabellen in het scenario waarin historische gegevens beschikbaar zijn en het opnieuw verwerken ervan niet kostbaar is.
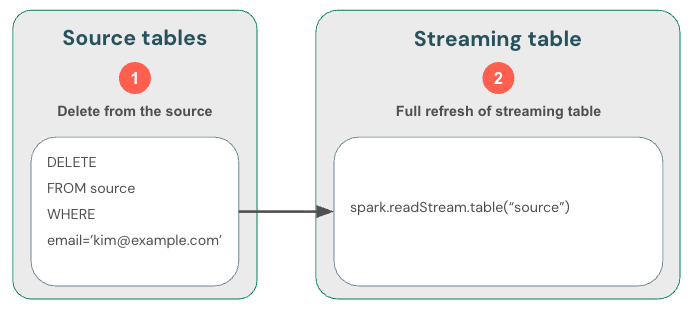
Delta-tabellen: verwijderingen verwerken met readChangeFeed
Reguliere Delta-tabellen bevatten geen speciale verwerking van upstream deletes. In plaats daarvan moet u uw eigen code schrijven om verwijderacties door te geven (bijvoorbeeld spark.readStream.option("readChangeFeed", true).table("source_table")).
Voorbeeld: AVG- en CCPA-naleving voor een e-commercebedrijf
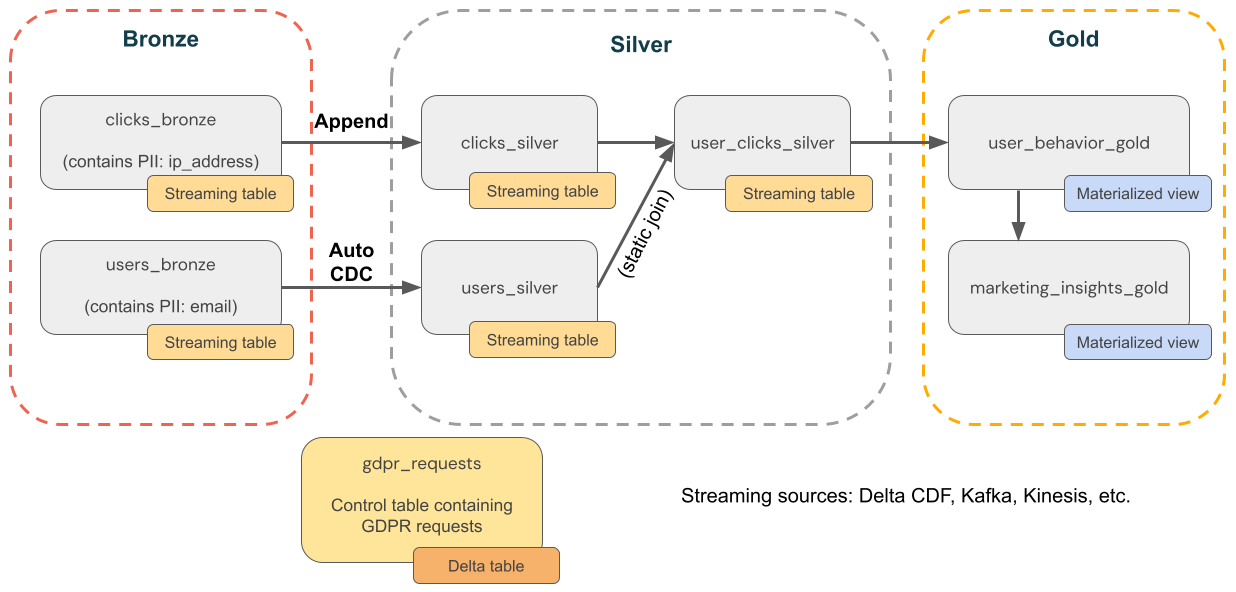
In het volgende diagram ziet u een medaille-architectuur voor een e-commercebedrijf waar AVG-& CCPA-naleving moet worden geïmplementeerd. Hoewel de gegevens van een gebruiker worden verwijderd, wilt u mogelijk hun activiteiten in downstreamaggregaties tellen.
-
bronslaag
-
users- Gebruikersdimensies. Bevat PII (bijvoorbeeld e-mailadres). -
clickstream- Klik op gebeurtenissen. Bevat PII (bijvoorbeeld IP-adres). -
gdpr_requests- Controletabel met gebruikers-id's onderworpen aan het recht om vergeten te worden.
-
-
Zilverlaag
-
clicks_hourly- Totaal aantal klikken per uur. Als u een gebruiker verwijdert, wilt u nog steeds hun klikken tellen. -
clicks_by_user- Totaal aantal klikken per gebruiker. Als u een gebruiker verwijdert, wilt u hun klikken niet tellen.
-
-
Goudlaag
-
revenue_by_user: totale uitgaven per gebruiker.
-
Stap 1: Tabellen vullen met voorbeeldgegevens
Met de volgende code worden deze twee tabellen gemaakt:
-
source_usersbevat dimensionale gegevens over gebruikers. Deze tabel bevat een PII-kolom met de naamemail. -
source_clicksbevat gebeurtenisgegevens over activiteiten die door gebruikers worden uitgevoerd. Het bevat een PII-kolom met de naamip_address.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, MapType, DateType
catalog = "users"
schema = "name"
# Create table containing sample users
users_schema = StructType([
StructField('user_id', IntegerType(), False),
StructField('username', StringType(), True),
StructField('email', StringType(), True),
StructField('registration_date', StringType(), True),
StructField('user_preferences', MapType(StringType(), StringType()), True)
])
users_data = [
(1, 'alice', 'alice@example.com', '2021-01-01', {'theme': 'dark', 'language': 'en'}),
(2, 'bob', 'bob@example.com', '2021-02-15', {'theme': 'light', 'language': 'fr'}),
(3, 'charlie', 'charlie@example.com', '2021-03-10', {'theme': 'dark', 'language': 'es'}),
(4, 'david', 'david@example.com', '2021-04-20', {'theme': 'light', 'language': 'de'}),
(5, 'eve', 'eve@example.com', '2021-05-25', {'theme': 'dark', 'language': 'it'})
]
users_df = spark.createDataFrame(users_data, schema=users_schema)
users_df.write..mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_users")
# Create table containing clickstream (i.e. user activities)
from pyspark.sql.types import TimestampType
clicks_schema = StructType([
StructField('click_id', IntegerType(), False),
StructField('user_id', IntegerType(), True),
StructField('url_clicked', StringType(), True),
StructField('click_timestamp', StringType(), True),
StructField('device_type', StringType(), True),
StructField('ip_address', StringType(), True)
])
clicks_data = [
(1001, 1, 'https://example.com/home', '2021-06-01T12:00:00', 'mobile', '192.168.1.1'),
(1002, 1, 'https://example.com/about', '2021-06-01T12:05:00', 'desktop', '192.168.1.1'),
(1003, 2, 'https://example.com/contact', '2021-06-02T14:00:00', 'tablet', '192.168.1.2'),
(1004, 3, 'https://example.com/products', '2021-06-03T16:30:00', 'mobile', '192.168.1.3'),
(1005, 4, 'https://example.com/services', '2021-06-04T10:15:00', 'desktop', '192.168.1.4'),
(1006, 5, 'https://example.com/blog', '2021-06-05T09:45:00', 'tablet', '192.168.1.5')
]
clicks_df = spark.createDataFrame(clicks_data, schema=clicks_schema)
clicks_df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_clicks")
Stap 2: Een pijplijn maken waarmee PII-gegevens worden verwerkt
Met de volgende code worden brons-, zilver- en gouden lagen gemaakt van de medaille-architectuur die hierboven wordt weergegeven.
import dlt
from pyspark.sql.functions import col, concat_ws, count, countDistinct, avg, when, expr
catalog = "users"
schema = "name"
# ----------------------------
# Bronze Layer - Raw Data Ingestion
# ----------------------------
@dlt.table(
name=f"{catalog}.{schema}.users_bronze",
comment='Raw users data loaded from source'
)
def users_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_users")
)
@dlt.table(
name=f"{catalog}.{schema}.clicks_bronze",
comment='Raw clicks data loaded from source'
)
def clicks_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_clicks")
)
# ----------------------------
# Silver Layer - Data Cleaning and Enrichment
# ----------------------------
@dlt.table(
name=f"{catalog}.{schema}.users_silver",
comment='Cleaned and standardized users data'
)
@dlt.expect_or_drop('valid_email', "email IS NOT NULL")
def users_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.users_bronze")
.withColumn('registration_date', col('registration_date').cast('timestamp'))
.dropDuplicates(['user_id', 'registration_date'])
.select('user_id', 'username', 'email', 'registration_date', 'user_preferences')
)
@dlt.table(
name=f"{catalog}.{schema}.clicks_silver",
comment='Cleaned and standardized clicks data'
)
@dlt.expect_or_drop('valid_click_timestamp', "click_timestamp IS NOT NULL")
def clicks_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.clicks_bronze")
.withColumn('click_timestamp', col('click_timestamp').cast('timestamp'))
.withWatermark('click_timestamp', '10 minutes')
.dropDuplicates(['click_id'])
.select('click_id', 'user_id', 'url_clicked', 'click_timestamp', 'device_type', 'ip_address')
)
@dlt.table(
name=f"{catalog}.{schema}.user_clicks_silver",
comment='Joined users and clicks data on user_id'
)
def user_clicks_silver():
# Read users_silver as a static DataFrame
users = spark.read.table(f"{catalog}.{schema}.users_silver")
# Read clicks_silver as a streaming DataFrame
clicks = spark.readStream \
.table('clicks_silver')
# Perform the join
joined_df = clicks.join(users, on='user_id', how='inner')
return joined_df
# ----------------------------
# Gold Layer - Aggregated and Business-Level Data
# ----------------------------
@dlt.table(
name=f"{catalog}.{schema}.user_behavior_gold",
comment='Aggregated user behavior metrics'
)
def user_behavior_gold():
df = spark.read.table(f"{catalog}.{schema}.user_clicks_silver")
return (
df.groupBy('user_id')
.agg(
count('click_id').alias('total_clicks'),
countDistinct('url_clicked').alias('unique_urls')
)
)
@dlt.table(
name=f"{catalog}.{schema}.marketing_insights_gold",
comment='User segments for marketing insights'
)
def marketing_insights_gold():
df = spark.read.table(f"{catalog}.{schema}.user_behavior_gold")
return (
df.withColumn(
'engagement_segment',
when(col('total_clicks') >= 100, 'High Engagement')
.when((col('total_clicks') >= 50) & (col('total_clicks') < 100), 'Medium Engagement')
.otherwise('Low Engagement')
)
)
Stap 3: Gegevens verwijderen in brontabellen
In deze stap verwijdert u gegevens in alle tabellen waar PII is gevonden.
catalog = "users"
schema = "name"
def apply_gdpr_delete(user_id):
tables_with_pii = ["clicks_bronze", "users_bronze", "clicks_silver", "users_silver", "user_clicks_silver"]
for table in tables_with_pii:
print(f"Deleting user_id {user_id} from table {table}")
spark.sql(f"""
DELETE FROM {catalog}.{schema}.{table}
WHERE user_id = {user_id}
""")
Stap 4: SkipChangeCommits toevoegen aan definities van betrokken streamingtabellen
In deze stap moet u Lakeflow Declarative Pipelines instrueren om niet-toevoegrijen over te slaan. Voeg de optie skipChangeCommits toe aan de volgende methoden. U hoeft de definities van gematerialiseerde weergaven niet bij te werken, omdat ze updates en verwijderingen automatisch verwerken.
users_bronzeusers_silverclicks_bronzeclicks_silveruser_clicks_silver
De volgende code laat zien hoe u de methode users_bronze bijwerkt:
def users_bronze():
return (
spark.readStream.option('skipChangeCommits', 'true').table(f"{catalog}.{schema}.source_users")
)
Wanneer u de pijplijn opnieuw uitvoert, zal deze succesvol worden bijgewerkt.