Shiny in Azure Databricks
Shiny is een R-pakket, beschikbaar op CRAN, dat wordt gebruikt om interactieve R-toepassingen en -dashboards te bouwen. U kunt Shiny in RStudio Server gebruiken die wordt gehost op Azure Databricks-clusters. U kunt shiny-toepassingen ook rechtstreeks ontwikkelen, hosten en delen vanuit een Azure Databricks-notebook.
Zie de Shiny-tutorialsom aan de slag te gaan met Shiny. U kunt deze zelfstudies uitvoeren op Azure Databricks-notebooks.
In dit artikel wordt beschreven hoe u Shiny-toepassingen uitvoert in Azure Databricks en Apache Spark gebruikt in Shiny-toepassingen.
Glanzend binnen R-notebooks
Aan de slag met Shiny in R-notitieboekjes
Het Shiny-pakket is opgenomen in Databricks Runtime. U kunt shiny-toepassingen interactief ontwikkelen en testen in Azure Databricks R-notebooks, vergelijkbaar met gehoste RStudio.
Volg deze stappen om aan de slag te gaan:
Maak een R-notebook.
Importeer het Shiny-pakket en voer de voorbeeld-app
01_helloals volgt uit:library(shiny) runExample("01_hello")Wanneer de app klaar is, bevat de uitvoer de URL van de Shiny-app als een klikbare koppeling waarmee een nieuw tabblad wordt geopend. Als u deze app wilt delen met andere gebruikers, raadpleegt u de URL van de Shiny-app delen.

Notitie
- Logboekberichten worden weergegeven in het opdrachtresultaat, vergelijkbaar met het standaardlogboekbericht (
Listening on http://0.0.0.0:5150) dat in het voorbeeld wordt weergegeven. - Als u de Shiny-toepassing wilt stoppen, klikt u op Annuleren.
- De Shiny-toepassing maakt gebruik van het notebook R-proces. Als u het notebook loskoppelt van het cluster of als u de cel waarop de toepassing wordt uitgevoerd annuleert, wordt de Shiny-toepassing beëindigd. U kunt geen andere cellen uitvoeren terwijl de Shiny-toepassing wordt uitgevoerd.
Shiny-apps uitvoeren vanuit Git-mappen van Databricks
U kunt Shiny-apps uitvoeren die zijn ingecheckt in Databricks Git-mappen.
Voer de toepassing uit.
library(shiny) runApp("006-tabsets")
Shiny-apps uitvoeren vanuit bestanden
Als uw Shiny-toepassingscode deel uitmaakt van een project dat wordt beheerd door versiebeheer, kunt u deze uitvoeren in het notebook.
Notitie
U moet het absolute pad gebruiken of de werkmap met setwd()instellen.
Bekijk de code uit een opslagplaats met behulp van code die vergelijkbaar is met:
%sh git clone https://github.com/rstudio/shiny-examples.git cloning into 'shiny-examples'...Als u de toepassing wilt uitvoeren, voert u code in die lijkt op het volgende in een andere cel:
library(shiny) runApp("/databricks/driver/shiny-examples/007-widgets/")
URL van Shiny-app delen
De URL van de Shiny-app die wordt gegenereerd wanneer u een app start, kan worden gedeeld met andere gebruikers. Elke Azure Databricks-gebruiker met CAN ATTACH TO-machtiging voor het cluster kan de app bekijken en ermee werken, zolang zowel de app als het cluster worden uitgevoerd.
Als het cluster waarop de app wordt uitgevoerd, wordt beëindigd, is de app niet meer toegankelijk. U kunt automatische beëindiging uitschakelen in de clusterinstellingen.
Als u het notebook koppelt en uitvoert dat als host fungeert voor de Shiny-app op een ander cluster, wordt de Shiny-URL gewijzigd. Als u de app opnieuw opstart op hetzelfde cluster, kan Shiny ook een andere willekeurige poort kiezen. Als u een stabiele URL wilt garanderen, kunt u de optie shiny.port instellen of kunt u bij het opnieuw opstarten van de app in hetzelfde cluster het argument port opgeven.
Shiny op gehoste RStudio Server
Vereisten
Belangrijk
Met RStudio Server Pro moet u geproxiede verificatie uitschakelen.
Zorg ervoor dat auth-proxy=1 deze niet aanwezig is./etc/rstudio/rserver.conf
Aan de slag met Shiny op gehoste RStudio Server
Open RStudio in Azure Databricks.
Importeer in RStudio het Shiny-pakket en voer de voorbeeld-app
01_helloals volgt uit:> library(shiny) > runExample("01_hello") Listening on http://127.0.0.1:3203Er wordt een nieuw venster weergegeven met de Shiny-toepassing.
Een Shiny-app uitvoeren vanuit een R-script
Als u een Shiny-app wilt uitvoeren vanuit een R-script, opent u het R-script in de RStudio-editor en klikt u op de knop App uitvoeren in de rechterbovenhoek.
Apache Spark gebruiken in Shiny-apps
U kunt Apache Spark in Shiny-toepassingen gebruiken met SparkR of sparklyr.
SparkR gebruiken met Shiny in een notebook
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
Sparklyr gebruiken met Shiny in een notebook
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
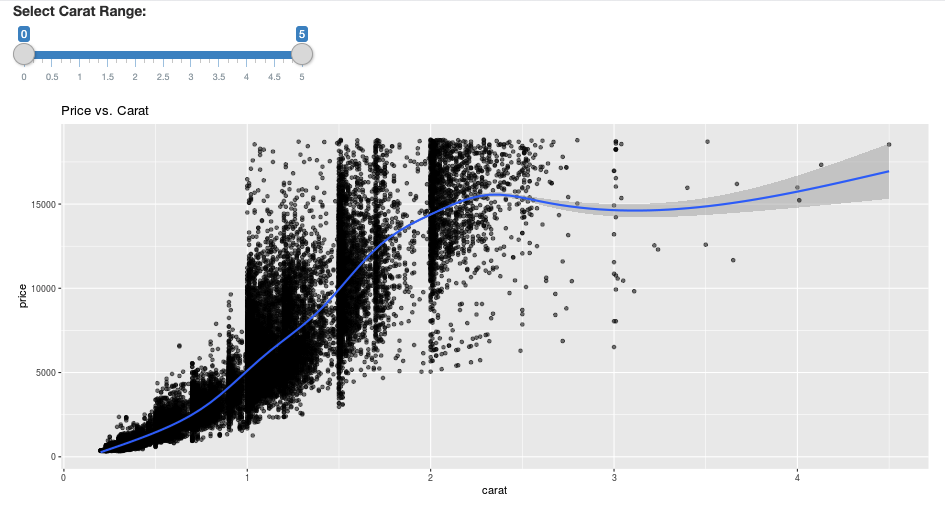
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
Veelgestelde vragen
- Waarom wordt mijn Shiny-app na enige tijd grijs weergegeven?
- Waarom verdwijnt mijn Shiny viewer-venster na een tijdje?
- Waarom retourneren lange Spark-taken nooit?
- Hoe kan ik de time-out vermijden?
- Mijn app loopt vast na het starten, maar de code lijkt correct te zijn. Wat gebeurt er?
- Hoeveel verbindingen kunnen tijdens de ontwikkeling worden geaccepteerd voor één Shiny-app-koppeling?
- Kan ik een andere versie van het Shiny-pakket gebruiken dan het pakket dat is geïnstalleerd in Databricks Runtime?
- Hoe kan ik een Shiny-toepassing ontwikkelen die kan worden gepubliceerd naar een Shiny-server en toegang kan krijgen tot gegevens in Azure Databricks?
- Kan ik een Shiny-toepassing ontwikkelen in een Azure Databricks-notebook?
- Hoe kan ik de Shiny-toepassingen opslaan die ik heb ontwikkeld op gehoste RStudio Server?
Waarom wordt mijn Shiny-app na enige tijd grijs weergegeven?
Als er geen interactie is met de Shiny-app, wordt de verbinding met de app na ongeveer 4 minuten gesloten.
Als u opnieuw verbinding wilt maken, vernieuwt u de shiny-app-pagina. De status van het dashboard wordt opnieuw ingesteld.
Waarom verdwijnt mijn Shiny viewer-venster na een tijdje?
Als het Shiny Viewer-venster verdwijnt na enkele minuten inactiviteit, wordt dit veroorzaakt door dezelfde time-out als het scenario waarbij het venster 'vergrijst'.
Waarom retourneren lange Spark-taken nooit?
Dit komt ook door de time-out voor inactiviteit. Een Spark-taak die langer wordt uitgevoerd dan de eerder genoemde time-outs, kan het resultaat niet weergeven omdat de verbinding wordt gesloten voordat de taak wordt geretourneerd.
Hoe kan ik de time-out vermijden?
Er is een tijdelijke oplossing die wordt voorgesteld in functieaanvraag: laat client keep alive-bericht verzenden om TCP-time-out op sommige load balancers op Github te voorkomen. De tijdelijke oplossing verzendt heartbeats om de WebSocket-verbinding actief te houden wanneer de app inactief is. Als de app echter wordt geblokkeerd door een langdurige berekening, werkt deze tijdelijke oplossing niet.
Shiny biedt geen ondersteuning voor langlopende taken. Een Shiny-blogbericht raadt aan om beloftes en futures te gebruiken om lange taken asynchroon uit te voeren en de app gedeblokkeerd te houden. Hier volgt een voorbeeld waarin heartbeats worden gebruikt om de Shiny-app actief te houden en een langlopende Spark-taak in een
futureconstructie uit te voeren.# Write an app that uses spark to access data on Databricks # First, install the following packages: install.packages(‘future’) install.packages(‘promises’) library(shiny) library(promises) library(future) plan(multisession) HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second # Define the long Spark job here run_spark <- function(x) { # Environment setting library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() irisDF <- createDataFrame(iris) collect(irisDF) Sys.sleep(3) x + 1 } run_spark_sparklyr <- function(x) { # Environment setting library(sparklyr) library(dplyr) library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() sc <- spark_connect(method = "databricks") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) collect(iris_tbl) x + 1 } ui <- fluidPage( sidebarLayout( # Display heartbeat sidebarPanel(textOutput("keep_alive")), # Display the Input and Output of the Spark job mainPanel( numericInput('num', label = 'Input', value = 1), actionButton('submit', 'Submit'), textOutput('value') ) ) ) server <- function(input, output) { #### Heartbeat #### # Define reactive variable cnt <- reactiveVal(0) # Define time dependent trigger autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS) # Time dependent change of variable observeEvent(autoInvalidate(), { cnt(cnt() + 1) }) # Render print output$keep_alive <- renderPrint(cnt()) #### Spark job #### result <- reactiveVal() # the result of the spark job busy <- reactiveVal(0) # whether the spark job is running # Launch a spark job in a future when actionButton is clicked observeEvent(input$submit, { if (busy() != 0) { showNotification("Already running Spark job...") return(NULL) } showNotification("Launching a new Spark job...") # input$num must be read outside the future input_x <- input$num fut <- future({ run_spark(input_x) }) %...>% result() # Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result() busy(1) # Catch exceptions and notify the user fut <- catch(fut, function(e) { result(NULL) cat(e$message) showNotification(e$message) }) fut <- finally(fut, function() { busy(0) }) # Return something other than the promise so shiny remains responsive NULL }) # When the spark job returns, render the value output$value <- renderPrint(result()) } shinyApp(ui = ui, server = server)Er is een vaste limiet van 12 uur sinds het laden van de eerste pagina waarna een verbinding, zelfs als actief, wordt beëindigd. U moet de Shiny-app vernieuwen om opnieuw verbinding te maken in deze gevallen. De onderliggende WebSocket-verbinding kan echter op elk gewenst moment worden gesloten door verschillende factoren, waaronder netwerkinstabiliteit of de slaapstand van de computer. Databricks raadt aan shiny-apps zodanig te herschrijven dat ze geen langdurige verbinding nodig hebben en niet te veel afhankelijk zijn van de sessiestatus.
Mijn app loopt vast na het starten, maar de code lijkt correct te zijn. Wat gebeurt er?
Er is een limiet van 50 MB voor de totale hoeveelheid gegevens die kan worden weergegeven in een Shiny-app in Azure Databricks. Als de totale gegevensgrootte van de toepassing deze limiet overschrijdt, loopt deze onmiddellijk na het starten vast. Om dit te voorkomen, raadt Databricks aan om de gegevensgrootte te verkleinen, bijvoorbeeld door de weergegeven gegevens te verkleinen of de resolutie van afbeeldingen te verminderen.
Hoeveel verbindingen kunnen tijdens de ontwikkeling worden geaccepteerd voor één Shiny-app-koppeling?
Databricks raadt maximaal 20 aan.
Kan ik een andere versie van het Shiny-pakket gebruiken dan het pakket dat is geïnstalleerd in Databricks Runtime?
Ja. Zie De versie van R-pakketten herstellen.
Hoe kan ik een Shiny-toepassing ontwikkelen die kan worden gepubliceerd naar een Shiny-server en toegang kan krijgen tot gegevens in Azure Databricks?
Hoewel u tijdens het ontwikkelen en testen op Azure Databricks op een natuurlijke manier toegang hebt tot de gegevens met SparkR of sparklyr, kan de toepassing niet rechtstreeks toegang krijgen tot de gegevens en tabellen in Azure Databricks nadat een Shiny-toepassing is gepubliceerd naar een zelfstandige hostingservice.
Als u wilt dat uw toepassing werkt buiten Azure Databricks, moet u opnieuw schrijven hoe u toegang krijgt tot gegevens. Er zijn enkele opties:
- Gebruik JDBC/ODBC om query's naar een Azure Databricks-cluster te verzenden.
- Databricks Connect gebruiken.
- Rechtstreeks toegang tot gegevens in objectopslag.
Databricks raadt u aan samen te werken met uw Azure Databricks-oplossingenteam om de beste benadering te vinden voor uw bestaande gegevens- en analysearchitectuur.
Kan ik een Shiny-toepassing ontwikkelen in een Azure Databricks-notebook?
Ja, u kunt een Shiny-toepassing ontwikkelen in een Azure Databricks-notebook.
Hoe kan ik de Shiny-toepassingen opslaan die ik heb ontwikkeld op gehoste RStudio Server?
U kunt uw toepassingscode opslaan in DBFS of uw code controleren in versiebeheer.