sparklyr
Azure Databricks ondersteunt sparklyr in notebooks, taken en RStudio Desktop. In dit artikel wordt beschreven hoe u sparklyr kunt gebruiken en voorbeeldscripts kunt gebruiken die u kunt uitvoeren. Zie de R-interface voor Apache Spark voor meer informatie.
Vereisten
Azure Databricks distribueert de nieuwste stabiele versie van sparklyr met elke Databricks Runtime-release. U kunt sparklyr gebruiken in Azure Databricks R-notebooks of in RStudio Server die wordt gehost op Azure Databricks door de geïnstalleerde versie van sparklyr te importeren.
In RStudio Desktop kunt u met Databricks Connect sparklyr vanaf uw lokale computer verbinden met Azure Databricks-clusters en Apache Spark-code uitvoeren. Zie Sparklyr en RStudio Desktop gebruiken met Databricks Connect.
Sparklyr verbinden met Azure Databricks-clusters
Als u een sparklyr-verbinding tot stand wilt brengen, kunt u deze gebruiken "databricks" als de verbindingsmethode in spark_connect().
Er zijn geen extra parameters nodig voor spark_connect() en er worden ook geen spark_install() aangeroepen omdat Spark al is geïnstalleerd op een Azure Databricks-cluster.
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
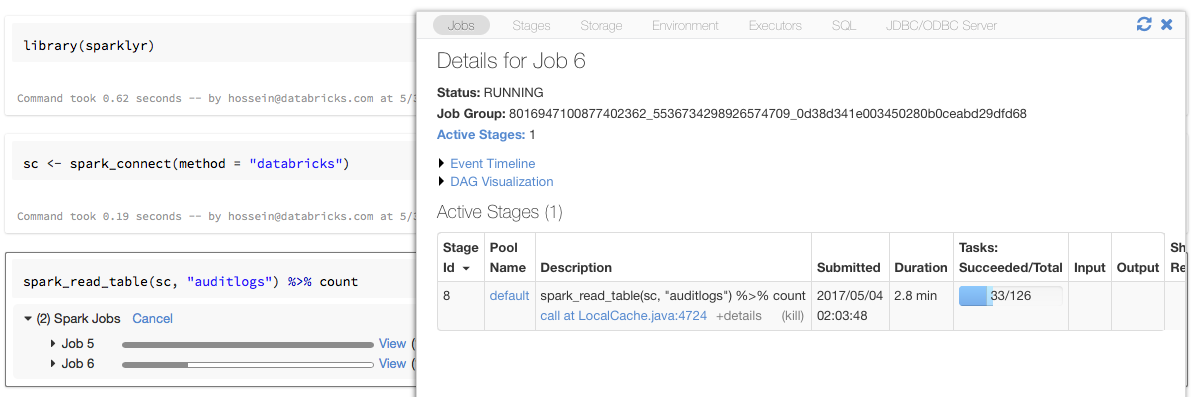
Voortgangsbalken en Spark-gebruikersinterface met sparklyr
Als u het sparklyr-verbindingsobject toewijst aan een variabele met de naam sc in het bovenstaande voorbeeld, ziet u de voortgangsbalken van Spark in het notebook na elke opdracht waarmee Spark-taken worden geactiveerd.
Daarnaast kunt u op de koppeling naast de voortgangsbalk klikken om de Spark-gebruikersinterface weer te geven die is gekoppeld aan de opgegeven Spark-taak.
Sparklyr gebruiken
Nadat u sparklyr hebt geïnstalleerd en de verbinding tot stand hebt gebracht, werken alle andere sparklyr-API's zoals ze normaal gesproken doen. Zie het voorbeeldnotitieblok voor enkele voorbeelden.
sparklyr wordt meestal samen met andere tidyverse-pakketten zoals dplyr gebruikt. De meeste van deze pakketten zijn voor uw gemak vooraf geïnstalleerd op Databricks. U kunt ze gewoon importeren en de API gaan gebruiken.
Sparklyr en SparkR samen gebruiken
SparkR en sparklyr kunnen samen worden gebruikt in één notebook of taak. U kunt SparkR samen met sparklyr importeren en de functionaliteit ervan gebruiken. In Azure Databricks-notebooks is de SparkR-verbinding vooraf geconfigureerd.
Sommige functies in SparkR maskeren een aantal functies in dplyr:
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
Als u SparkR importeert nadat u dplyr hebt geïmporteerd, kunt u verwijzen naar de functies in dplyr met behulp van de volledig gekwalificeerde namen, bijvoorbeeld dplyr::arrange().
Als u dplyr na SparkR importeert, worden de functies in SparkR gemaskeerd door dplyr.
U kunt ook selectief een van de twee pakketten loskoppelen, terwijl u deze niet nodig hebt.
detach("package:dplyr")
Zie ook SparkR en sparklyr vergelijken.
Sparklyr gebruiken in spark-submit-taken
U kunt scripts uitvoeren die sparklyr in Azure Databricks gebruiken als spark-submit-taken, met kleine codewijzigingen. Sommige van de bovenstaande instructies zijn niet van toepassing op het gebruik van sparklyr in spark-submit-taken in Azure Databricks. In het bijzonder moet u de SPARK-hoofd-URL opgeven voor spark_connect. Voorbeeld:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
Niet-ondersteunde functies
Azure Databricks biedt geen ondersteuning voor sparklyr-methoden, zoals spark_web() en spark_log() waarvoor een lokale browser is vereist. Omdat de Spark-gebruikersinterface echter is ingebouwd in Azure Databricks, kunt u Spark-taken en -logboeken eenvoudig inspecteren.
Zie de logboeken van het rekenstuurprogramma en de werkrol.
Voorbeeldnotebook: Sparklyr-demonstratie
Sparklyr-notebook
Zie Werken met DataFrames en tabellen in Rvoor meer voorbeelden.