Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
U kunt een queryprofiel gebruiken om de details van een queryuitvoering te visualiseren. Met het queryprofiel kunt u prestatieknelpunten oplossen tijdens de uitvoering van de query. Voorbeeld:
- U kunt elke queryoperator en gerelateerde metrische gegevens visualiseren, zoals de tijd die is besteed, het aantal verwerkte rijen, de verwerkte rijen en het geheugenverbruik.
- U kunt in één oogopslag het langzaamste deel van een queryuitvoering identificeren en de gevolgen van wijzigingen in de query beoordelen.
- U kunt veelvoorkomende fouten in SQL-instructies ontdekken en oplossen, zoals exploderende joins of volledige tabelscans.
Vereisten
Als u een queryprofiel wilt weergeven, moet u de eigenaar van de query zijn of moet u ten minste de machtiging CAN MONITOR hebben voor het SQL-warehouse dat de query heeft uitgevoerd.
Een queryprofiel weergeven
U kunt het queryprofiel in de querygeschiedenis weergeven met behulp van de volgende stappen:
Klik op
 Querygeschiedenis in de zijbalk.
Querygeschiedenis in de zijbalk.Klik op de naam van een query. Aan de rechterkant van het scherm wordt een deelvenster met querydetails weergegeven.
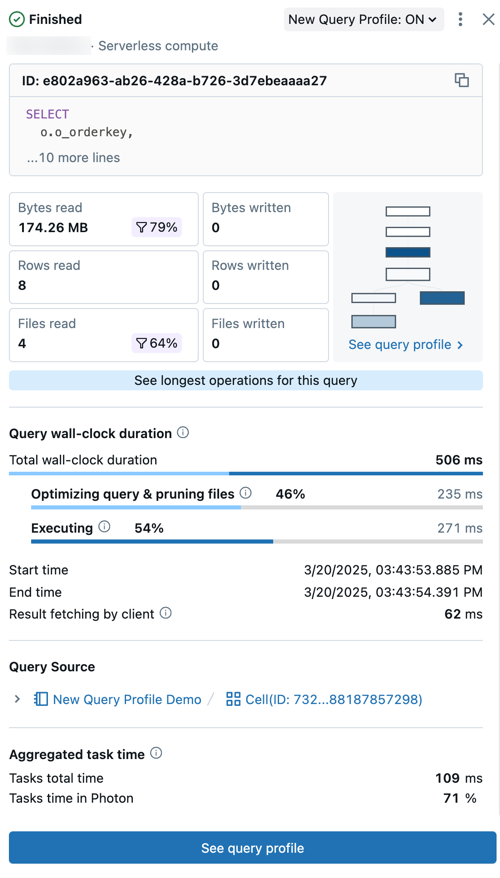
De querysamenvatting bevat:
- Querystatus: De query is getagd met de huidige status: In wachtrij, Bezig, Voltooid, Mislukt, of Geannuleerd.
- Gebruiker- en computergegevens: Bekijk de gebruikersnaam, het computertype en de runtime-gegevens voor deze query-uitvoering.
- ID: Dit is de universeel unieke identificator (UUID) geassocieerd met de gegeven query-uitvoering.
- Query statement: Deze sectie bevat de volledige queryverklaring. Als de query te lang is om in de preview te worden weergegeven, klik dan op ... meer regels om de volledige tekst te bekijken.
- Query metrics: Populaire statistieken voor queryanalyse worden onder de querytekst weergegeven. De filterpictogrammen die worden weergegeven met bepaalde metrische gegevens geven het percentage van de gegevens aan dat tijdens het scannen is verwijderd.
- Bekijk het queryprofiel: In deze samenvatting ziet u een voorbeeld van het queryprofiel gericht op een acyclische grafiek (DAG). Dit kan handig zijn voor het snel inschatten van de complexiteit van queries en de uitvoeringsstroom. Klik op Zie queryprofiel om de gedetailleerde DAG te openen.
- Bekijk de langste operators voor deze query: Klik op deze knop om het Top operators paneel te openen. Dit paneel toont de langst lopende operators in de query.
- Looptijd van de query: De totale verstreken tijd tussen het begin van de planning en het einde van de uitvoering van de query wordt als overzicht gegeven. Een gedetailleerd overzicht van de planning, query-optimalisatie en bestandssnoeiing, en de uitvoeringstijd verschijnt onder de samenvatting.
- Querybron: Klik op de naam van het vermelde object om naar de querybron te gaan.
- Geaggregeerde taakduur: Bekijk de gecombineerde tijd die nodig was om de query uit te voeren over alle cores van alle knooppunten. Het kan aanzienlijk langer duren dan de wandklokduur als meerdere taken parallel worden uitgevoerd. Het kan korter zijn dan de kloktijd als taken hebben gewacht op beschikbare knooppunten.
- Input/Output (IO): Bekijk details over de gegevens die zijn gelezen en geschreven tijdens de uitvoering van de query.
Klik op Queryprofiel weergeven. Aan de rechterkant van het scherm wordt een detailvenster geopend.
Notitie
Als er geen queryprofiel beschikbaar is, is er geen profiel beschikbaar voor deze query. Een queryprofiel is niet beschikbaar voor query's die worden uitgevoerd vanuit de querycache. Als u de querycache wilt omzeilen, moet u een triviale wijziging aanbrengen in de query, zoals het wijzigen of verwijderen van de
LIMITquery.
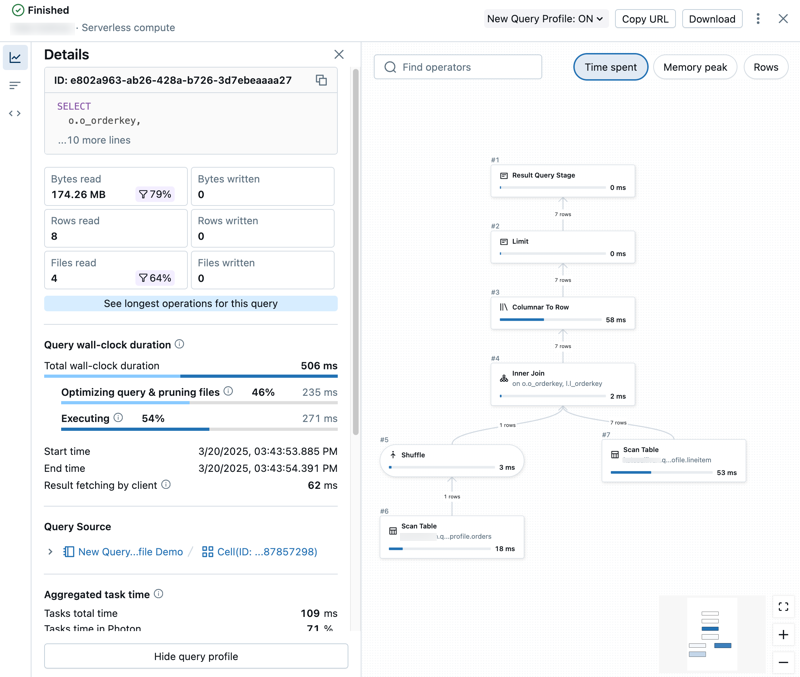
Details van queryprofiel weergeven
Het gedetailleerde queryprofiel bevat samenvattingsgegevens aan de linkerkant van het deelvenster en een grafiekweergave van operators aan de rechterkant.
Querystatistieken verkennen
De linkerkant van het queryprofiel heeft de volgende tabbladen:
 : Details hiermee opent u het deelvenster Details waarin de overzichtsstatistieken van de query zullen worden weergegeven.
: Details hiermee opent u het deelvenster Details waarin de overzichtsstatistieken van de query zullen worden weergegeven. Topoperators: hiermee opent u het deelvenster Topoperators waarin de duurste operators worden weergegeven die in uw query worden gebruikt. Dit kan handig zijn voor het identificeren van optimalisatiekansen.
Topoperators: hiermee opent u het deelvenster Topoperators waarin de duurste operators worden weergegeven die in uw query worden gebruikt. Dit kan handig zijn voor het identificeren van optimalisatiekansen. Querytekst: Hiermee opent u het deelvenster Querytekst, waarin de volledige tekst van de query wordt weergegeven.
Querytekst: Hiermee opent u het deelvenster Querytekst, waarin de volledige tekst van de query wordt weergegeven.
Notitie
Sommige niet-Photon-bewerkingen worden uitgevoerd als een groep en delen algemene metrische gegevens. In dit geval hebben alle bewerkingen dezelfde waarde als de bovenliggende operator voor een bepaalde metrische waarde.
De DAG verkennen
In de rechter helft van het queryprofiel ziet u de gerichte acyclische grafiek (DAG) van de query. In de grafiekweergave ziet u statistieken zoals Tijd besteed, Geheugenpiek en Rijen. Klik op elke metriek om de weergegeven rapportagegegevens te wijzigen.
U kunt op de volgende manieren met de DAG werken:
- Gebruik de zoekbalk om verschillende operators of kolommen te markeren.
- Zoom in of uit om te focussen op verschillende onderdelen van de DAG.
- Klik op operators om gedetailleerde metrische gegevens en beschrijvingen weer te geven. In een deelvenster aan de rechterkant van de grafiek ziet u de details van de bewerking.
Voor Databricks SQL-query's kunt u ook het queryprofiel weergeven in de Spark-gebruikersinterface. Klik op het ![]() Kebabmenu bij de bovenkant van de pagina en klik vervolgens op Openen in Spark UI.
Kebabmenu bij de bovenkant van de pagina en klik vervolgens op Openen in Spark UI.
Standaard worden metrische gegevens voor sommige bewerkingen verborgen. Deze bewerkingen zijn waarschijnlijk niet de oorzaak van prestatieknelpunten. Als u informatie voor alle bewerkingen en aanvullende metrische gegevens wilt zien, klikt u bovenaan de pagina op het ![]() Klik daarna op Uitgebreide modus inschakelen.
Klik daarna op Uitgebreide modus inschakelen.
Algemene bewerkingen
De meest voorkomende bewerkingen zijn:
- Scan: Gegevens zijn gelezen uit een gegevensbron, en als rijen uitgevoerd.
- Join: rijen uit meerdere relaties zijn gecombineerd (verweven) in één rijenset.
- Union: rijen uit meerdere relaties die hetzelfde schema gebruiken, zijn samengevoegd in één set rijen.
- Shuffle: gegevens zijn opnieuw gedistribueerd of opnieuw gepartitioneerd. Shuffle-operaties zijn duur in termen van middelen, omdat ze gegevens verplaatsen tussen uitvoerders in het cluster.
-
Hash/sort: Rijen zijn gegroepeerd op een sleutel en geëvalueerd met behulp van een aggregatiefunctie zoals
SUM,COUNTofMAXbinnen elke groep. -
Filter: Invoer wordt gefilterd op basis van een criterium, zoals door een
WHEREcomponent, en er wordt een subset van rijen geretourneerd.
Prestatie-inzichten
Important
Deze functie bevindt zich in de bètaversie. Werkruimtebeheerders kunnen de toegang tot deze functie beheren vanaf de pagina Previews . Zie Azure Databricks previews beheren.
Wanneer query's worden uitgevoerd, kan Azure Databricks prestatieinzichten retourneren die mogelijkheden identificeren om de queryprestaties te verbeteren. In het queryprofiel worden inzichten op twee plaatsen weergegeven:
- In het deelvenster met querydetails ziet u een overzicht van de meest impactvolle inzichten, gerangschikt op het verwachte effect op de totale duur van de taak.
- Op het tabblad Prestatie-inzichten in het gedetailleerde queryprofiel ziet u de volledige details voor elk inzicht.
Zie Inzichten in queryprestaties voor de lijst met ondersteunde inzichten en hun betekenis.
Optimaliseren met Genie Code
Wanneer een query inzichten bevat waarop u kunt reageren, selecteert u Optimaliseren om Genie Code te openen. Voor een inzicht dat een querywijziging vereist, herschrijft Genie Code de query en worden de wijzigingen voor uw goedkeuring weergegeven. Voor een inzicht dat tabel- of rekenwijzigingen omvat, geeft Genie Code een overzicht van de aanbevolen acties als tekst zonder opmaak.
Zie Genie Code voor meer informatie over het werken met Genie Code.
Een queryprofiel delen
Een queryprofiel delen met een andere gebruiker:
- Querygeschiedenis weergeven.
- Klik op de naam van de query.
- Als u de query wilt delen, hebt u twee opties:
- Als de andere gebruiker de machtiging CAN MANAGE voor de query heeft, kunt u de URL voor het queryprofiel met hen delen. Klik op Delen. De URL wordt gekopieerd naar het Klembord.
- Als de andere gebruiker niet beschikt over de machtiging CAN MANAGE of geen lid is van de werkruimte, kunt u het queryprofiel downloaden als een JSON-object. downloaden. Het JSON-bestand wordt gedownload naar uw lokale systeem.
Een query-profiel importeren
De JSON importeren voor een queryprofiel:
Klik op het
 in de rechterbovenhoek en selecteer Queryprofiel importeren (JSON).
in de rechterbovenhoek en selecteer Queryprofiel importeren (JSON).Selecteer in de bestandsbrowser het JSON-bestand dat met u is gedeeld en klik op openen. Het JSON-bestand wordt geüpload en het queryprofiel wordt weergegeven.
Wanneer u een queryprofiel importeert, wordt het dynamisch geladen in uw browsersessie en blijft het niet behouden in uw werkruimte. U moet deze telkens opnieuw importeren wanneer u deze wilt bekijken.
Als u het geïmporteerde queryprofiel wilt sluiten, klikt u op X boven aan de pagina.
Toegang tot het queryprofiel
U kunt ook toegang krijgen tot het queryprofiel in de volgende onderdelen van de gebruikersinterface:
Vanuit de SQL-editor: Tijdens en na het uitvoeren van de query geeft een koppeling onder aan de pagina de verstreken tijd en het aantal geretourneerde rijen weer. Klik op die koppeling om het deelvenster met querydetails te openen. Klik op Queryprofiel weergeven.

Notitie
Als u de nieuwe SQL-editor hebt ingeschakeld (openbare preview), wordt uw koppeling weergegeven zoals in een notebook.
Vanuit een notebook: Als uw notebook is gekoppeld aan een SQL Warehouse of serverloze berekening, hebt u toegang tot het queryprofiel met behulp van de koppeling onder de cel die de query bevat. Klik op Prestaties weergeven om de uitvoeringsgeschiedenis te openen. Klik op een opmerking om het deelvenster met querydetails te openen.

Vanuit de gebruikersinterface van Lakeflow-pijplijnen: u hebt toegang tot de querygeschiedenis en het profiel via het tabblad Querygeschiedenis in de gebruikersinterface van de pijplijn. Raadpleeg de querygeschiedenis van toegang voor pijplijnen.
Vanuit de gebruikersinterface van jobs: U hebt toegang tot queryprofielen voor jobs die worden uitgevoerd op SQL-warehouses en serverloze computing. Bekijk querydetails voor taakuitvoeringen voor taken die worden uitgevoerd op serverloze compute om te leren hoe u querydetails kunt bekijken in de taken-UI.
Volgende stappen
- Meer informatie over het benaderen van querystatistieken met behulp van de querygeschiedenis-API
- Meer informatie over querygeschiedenis