Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Op deze pagina wordt beschreven hoe u Delta-tabellen gebruikt als bronnen en sinks voor Spark Structured Streaming met readStream en writeStream. Delta Lake lost veelvoorkomende prestatie- en betrouwbaarheidsproblemen op voor streamingsystemen en bestanden. Tot de voordelen behoren onder meer:
- Voeg kleine bestanden samen die worden geproduceerd door invoer met lage latentie en verbeter de prestaties.
- Handhaaf "exactly-once" verwerking met meer dan één datastream (of gelijktijdige "batch jobs").
- Efficiënt nieuwe bestanden detecteren bij het gebruik van bestanden als een stroombron.
Zie Streamingtabellen gebruiken in Databricks SQL voor meer informatie over het laden van gegevens met behulp van streamingtabellen in Databricks SQL.
Zie Stream-static joins voor stream-static joins met Delta Lake.
Delta-tabellen gebruiken als sink
U kunt gegevens naar een Delta-tabel schrijven met structured streaming. Het Delta Lake-transactielogboek garandeert eenmalige verwerking, zelfs wanneer er andere streams of batchquery's gelijktijdig tegen de tabel worden uitgevoerd.
Wanneer u naar een Delta-tabel schrijft met behulp van een Structured Streaming-sink, kunt u mogelijk lege commits met epochId = -1 zien. Deze worden verwacht en treden meestal op:
- In de eerste batch van elke uitvoering van de streamingquery (dit gebeurt elke batch voor
Trigger.AvailableNow). - Wanneer een schema wordt gewijzigd (zoals het toevoegen van een kolom).
Deze lege commits zijn opzettelijk en duiden niet op een fout. Ze hebben geen invloed op de juistheid of prestaties van de query op een significante manier.
Note
De functie Delta Lake VACUUM verwijdert alle bestanden die niet worden beheerd door Delta Lake, maar slaat alle mappen over die beginnen met _. U kunt controlepunten veilig opslaan naast andere gegevens en metagegevens voor een Delta-tabel met behulp van een mapstructuur zoals <table-name>/_checkpoints.
Achterstand bewaken met metrische gegevens
Gebruik de volgende metrische gegevens om de achterstand van een streamingqueryproces te bewaken:
-
numBytesOutstanding: Aantal bytes dat nog moet worden verwerkt in de wachtrij. -
numFilesOutstanding: Het aantal bestanden dat nog moet worden verwerkt in de achterstand. -
numNewListedFiles: Het aantal Delta Lake-bestanden dat wordt vermeld om de achterstand voor deze batch te berekenen. -
backlogEndOffset: De Delta-tabelversie die wordt gebruikt om de achterstand te berekenen.
Bekijk deze metrische gegevens in een notebook op het tabblad Onbewerkte gegevens in het voortgangsdashboard voor streamingquery's:
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Toevoegmodus
Streams worden standaard uitgevoerd in de toevoegmodus en voegen alleen nieuwe records toe aan de tabel.
Gebruik de toTable methode bij het streamen naar tabellen:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Volledige modus
Gebruik Structured Streaming met de volledige modus om de hele tabel na elke batch te vervangen. U kunt bijvoorbeeld continu een samengevoegde samenvattingstabel van gebeurtenissen per klant bijwerken:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
Voor toepassingen zonder strikte latentievereisten kunt u rekenresources en -kosten besparen met eenmalige triggers, zoals AvailableNow. Gebruik deze trigger bijvoorbeeld om samenvattingsaggregatietabellen volgens een bepaalde planning bij te werken, waarbij alleen nieuwe gegevens worden verwerkt die sinds de laatste update zijn aangekomen. Zie AvailableNow: Incrementele batchverwerking.
Wijzigingen in bron-Delta-tabellen verwerken
Gestructureerde streaming leest Delta-tabellen incrementeel. Wanneer een streamingquery uit een Delta-tabel leest, worden nieuwe records idempotent verwerkt als nieuwe tabelversies doorvoeren naar de brontabel. Structured Streaming accepteert alleen toevoeginvoer en genereert een uitzondering als er wijzigingen optreden in de Delta-brontabel. Als een UPDATE, DELETEMERGE INTOof OVERWRITE bewerking bijvoorbeeld een delta-brontabel wijzigt die wordt gelezen door een streamingquery, mislukt de stream met een fout.
Er zijn vier gebruikelijke benaderingen voor het verwerken van upstream-wijzigingen in bron-Delta-tabellen, afhankelijk van uw use-case. Hieronder vindt u een referentietabel en details:
| Methode | Pros | Cons |
|---|---|---|
skipChangeCommits |
Eenvoudig, vereist niet dat u complexe logica schrijft. Handig voor het verwerken van alleen toevoegbewerkingen waarbij upstream-wijzigingen afzonderlijk worden verwerkt, of voor het tijdelijk verwerken van een ongeldige record. | Voert geen wijzigingen door en verwerkt enkel toevoegingen. |
| Volledig vernieuwen | Ook eenvoudig, hoeft u geen complexe logica te schrijven. Handig voor kleine gegevenssets met zeldzame upstream-wijzigingen. | Duur voor grote gegevenssets. Vereist dat alle downstreamtabellen opnieuw worden verwerkt. |
| Gegevensfeed wijzigen | Alle wijzigingstypen verwerken (invoegingen, updates en verwijderingen). Databricks raadt het streamen vanuit de CDC-feed van een Delta-tabel aan in plaats van waar mogelijk rechtstreeks vanuit de tabel. | Vereist dat u complexere logica schrijft om elk wijzigingstype te verwerken. |
| Gematerealiseerde weergaven | Eenvoudig alternatief voor Structured Streaming met automatische wijzigingsdoorgifte. | Hogere latentie. Alleen beschikbaar in Lakeflow Spark-declaratieve pijplijnen en Databricks SQL. |
Upstream-wijzigingscommits overslaan metskipChangeCommits
Ingesteld skipChangeCommits op het negeren van transacties die bestaande records verwijderen of wijzigen en om alleen toevoegbewerkingen te verwerken. Dit is handig wanneer wijzigingen in bestaande gegevens niet hoeven te worden doorgegeven via de stream of wanneer u liever afzonderlijke logica gebruikt om deze wijzigingen af te handelen. U kunt wijzigingen in- en uitschakelen skipChangeCommits als u eenmalige wijzigingen tijdelijk wilt negeren.
Databricks raadt het gebruik skipChangeCommits aan voor de meeste workloads die geen gebruik maken van change data feeds.
Python
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
Scala
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Important
Als het schema voor een Delta-tabel wordt gewijzigd nadat een streaming-leesbewerking voor de tabel is gestart, mislukt de query. Voor de meeste schemawijzigingen kunt u de stream opnieuw starten om niet-overeenkomende schema's op te lossen en door te gaan met de verwerking.
In Databricks Runtime 12.2 LTS en hieronder kunt u niet streamen vanuit een Delta-tabel waarvoor kolomtoewijzing is ingeschakeld die niet-additieve schemaontwikkeling heeft ondergaan, zoals het wijzigen of verwijderen van kolommen. Zie Kolomtoewijzing en streaming voor meer informatie.
Note
Vanaf Databricks Runtime 12.2 LTS en hoger vervangt skipChangeCommitsignoreChanges. In Databricks Runtime 11.3 LTS en lager ignoreChanges is dit de enige ondersteunde optie. Zie de optie Verouderd: ignoreChanges voor meer informatie.
Verouderde optie: ignoreDeletes
ignoreDeletes is een verouderde optie die alleen transacties verwerkt die gegevens op partitiegrenzen verwijderen (dat wil gezegd, volledige partities worden verwijderd). Als u niet-partitie verwijderingen, updates of andere wijzigingen moet afhandelen, gebruikt u skipChangeCommits in plaats daarvan.
Python
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
Scala
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Verouderde optie: ignoreChanges
ignoreChanges is beschikbaar in Databricks Runtime 11.3 LTS en lager. In Databricks Runtime 12.2 LTS en hoger wordt deze vervangen door skipChangeCommits.
Met ignoreChanges ingeschakelde, herschreven gegevensbestanden in de brontabel worden opnieuw verzonden na een bewerking voor het wijzigen van gegevens, zoals UPDATE, MERGE INTODELETE(binnen partities) of OVERWRITE. Ongewijzigde rijen worden vaak samen met nieuwe rijen verzonden, dus downstreamgebruikers moeten dubbele waarden kunnen verwerken. Verwijderingen worden niet aan de volgende fase doorgegeven.
ignoreChanges heeft voorrang op ignoreDeletes.
Daarentegen negeert skipChangeCommits alle bewerkingen voor het wijzigen van bestanden volledig. Herschreven gegevensbestanden in de brontabel vanwege bewerkingen voor gegevenswijziging, zoals UPDATE, MERGE INTODELETEen OVERWRITE worden volledig genegeerd. Als u wijzigingen in stroombrontabellen wilt weergeven, moet u afzonderlijke logica implementeren om deze wijzigingen door te geven.
Databricks raadt het gebruik skipChangeCommits aan voor alle nieuwe workloads. Als u een workload wilt migreren van ignoreChanges naar skipChangeCommits, herstructureert u de streaminglogica.
Volledige vernieuwing van downstreamtabellen
Als upstream-wijzigingen zeldzaam zijn en de gegevens klein genoeg zijn om opnieuw te worden verwerkt, kunt u het streaming-controlepunt en de uitvoertabel verwijderen en de stream vervolgens opnieuw starten vanaf het begin. Hierdoor worden alle gegevens uit de brontabel opnieuw verwerkt door de stroom. Houd er rekening mee dat voor deze aanpak ook alle downstreamtabellen moeten worden verwerkt die afhankelijk zijn van de uitvoer van deze stroom.
Deze benadering is het meest geschikt voor kleinere gegevenssets of workloads waarbij upstream-wijzigingen niet vaak worden gewijzigd en de kosten van een volledige vernieuwing acceptabel zijn.
Wijzigingenfeed gebruiken
Voor workloads die alle soorten wijzigingen verwerken (invoegingen, updates en verwijderingen), gebruikt u de Delta Lake-gegevensfeed voor wijzigingen. In de wijzigingenfeed worden wijzigingen op rijniveau vastgelegd in een Delta-tabel, zodat u deze wijzigingen kunt streamen en logica kunt schrijven om elk wijzigingstype in downstreamtabellen te verwerken. Dit is de meest robuuste benadering omdat uw code elk type wijzigingsevenement expliciet verwerkt. Zie Het gebruik van de wijzigingsgegevensfeed van Delta Lake op Azure Databricks.
Als u declaratieve pijplijnen van Lakeflow Spark gebruikt, raadpleegt u de AUTO CDC-API's: Het vastleggen van wijzigingsgegevens vereenvoudigen met pijplijnen.
Important
In Databricks Runtime 12.2 LTS en hieronder kunt u niet streamen vanuit de wijzigingengegevensfeed voor een Delta-tabel waarvoor kolomtoewijzing is ingeschakeld die niet-additieve schemaontwikkeling heeft ondergaan, zoals het wijzigen of verwijderen van kolommen. Zie Kolomtoewijzing en streaming.
Gematerialiseerde weergaven gebruiken
Gerealiseerde weergaven verwerken automatisch upstreamwijzigingen door resultaten opnieuw te berekenen wanneer de brongegevens worden gewijzigd. Als u de laagst mogelijke latentie niet nodig hebt en streamingcomplexiteit wilt voorkomen, kan een gerealiseerde weergave uw architectuur vereenvoudigen. Gerealiseerde weergaven zijn beschikbaar in Lakeflow Spark-declaratieve pijplijnen en in Databricks SQL. Bekijk gematerialiseerde weergaven.
Example
Stel dat u een tabel hebt user_events met date, user_emailen action kolommen die zijn gepartitioneerd door date. U haalt gegevens uit de user_events tabel en u moet gegevens uit de user_events tabel verwijderen vanwege de AVG.
skipChangeCommits hiermee kunt u gegevens in meerdere partities verwijderen (in dit voorbeeld filteren op user_email). Gebruik de volgende syntaxis:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
Als u een user_email bijwerkt met de UPDATE-instructie, wordt het bestand met de user_email in kwestie herschreven. Gebruik skipChangeCommits dit om de gewijzigde gegevensbestanden te negeren.
Databricks raadt aan om skipChangeCommits in plaats van ignoreDeletes te gebruiken, tenzij u zeker weet dat verwijderingen altijd volledige partitie-verwijderingen zijn.
Gebruiken foreachBatch voor idempotente tabelschrijfbewerkingen
Note
Databricks raadt u aan een afzonderlijke streaming-schrijfbewerking te configureren voor elke sink die u wilt bijwerken in plaats van foreachBatchte gebruiken. Schrijfbewerkingen naar meerdere sinks in foreachBatch verminderen de parallellisatie en verhogen de algehele latentie omdat schrijfbewerkingen naar meerdere tabellen worden geserialiseerd in foreachBatch.
Delta-tabellen ondersteunen de volgende DataFrameWriter opties om schrijfbewerkingen naar meerdere tabellen binnen foreachBatch idempotent te maken:
-
txnAppId: Een unieke tekenreeks die u kunt meegaven bij elke bewerking van een DataFrame. U kunt bijvoorbeeld de StreamingQuery-id gebruiken alstxnAppId.txnAppIdkan elke door de gebruiker gegenereerde unieke tekenreeks zijn en hoeft niet gerelateerd te zijn aan de stream-id. -
txnVersion: Een monotonisch toenemend getal dat fungeert als transactieversie.
Delta Lake gebruikt txnAppId en txnVersion om dubbele schrijfbewerkingen te identificeren en te negeren. Als een fout bijvoorbeeld een batch-schrijfbewerking onderbreekt, kunt u de batch opnieuw uitvoeren met dezelfde txnAppId en txnVersion om duplicaten correct te identificeren en te negeren. Zie foreachBatch gebruiken om naar willekeurige gegevens-sinks te schrijven.
Warning
Als u het streamingcontrolepunt verwijdert en de query opnieuw start met een nieuw controlepunt, moet u een ander txnAppIditem opgeven. Nieuwe controlepunten beginnen met een batch-id van 0. Delta Lake gebruikt de batch-id en txnAppId als een unieke sleutel en slaat batches met al geziene waarden over.
In het volgende codevoorbeeld ziet u dit patroon:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
Upsert van streamingquery's met behulp van foreachBatch
U kunt merge en foreachBatch gebruiken om complexe upserts van een streamingquery in een Delta-tabel te schrijven. Zie foreachBatch gebruiken om naar willekeurige gegevens-sinks te schrijven.
Deze aanpak heeft veel toepassingen:
- Verbeter de schrijfprestaties met
updatede uitvoermodus, terwijlcompletein de uitvoermodus de volledige resultaattabel voor elke microbatch opnieuw moet worden geschreven. - Pas continu een stroom wijzigingen toe op een Delta-tabel met behulp van een samenvoegquery om wijzigingsgegevens in
foreachBatchte schrijven. Zie Langzaam veranderende gegevens (SCD) en change data capture (CDC) met Delta Lake. - Ontdubbeling verwerken tijdens het verwerken van stromen. U kunt in
foreachBatcheen alleen-invoegen merge-query gebruiken om continu gegevens naar een Delta-tabel te schrijven met automatische ontdubbeling. Zie Gegevensontdubbeling bij het schrijven naar Delta-tabellen.
Note
Controleer of uw
mergeverklaringforeachBatchidempotent is. Anders kan het opnieuw opstarten van de streamingquery de bewerking meerdere keren toepassen op dezelfde batch met gegevens. Zie GebruikforeachBatchvoor idempotente tabelschrijvingen.Wanneer
mergewordt gebruikt inforeachBatch, kan de invoergegevenssnelheid een veelvoud van de werkelijke snelheid retourneren waarmee gegevens bij de bron worden gegenereerd.mergeleest invoergegevens meerdere keren, waarmee de metrische gegevens worden vermenigvuldigd. Om metrische vermenigvuldiging te voorkomen, slaat u het batch-DataFrame in de cache op voormergeen verwijdert u het daarna uit de cachemerge.De invoergegevenssnelheid is beschikbaar via
StreamingQueryProgressen in de grafiek voor de streamingsnelheid van het notebook. Zie Monitoring van Structured Streaming-queries op Azure Databricks.
U kunt bijvoorbeeld SQL-instructies gebruiken MERGE in foreachBatch:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
U kunt ook de Delta Lake-API's gebruiken voor het streamen van upserts:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Initiële tabelversie instellen om wijzigingen te verwerken
Streams beginnen standaard met de nieuwste beschikbare Delta-tabelversie. Dit omvat een volledige momentopname van de tabel op dat moment en alle toekomstige wijzigingen. Databricks raadt u aan de standaardversie van de eerste tabel te gebruiken voor de meeste workloads.
U kunt eventueel de volgende opties gebruiken om het beginpunt van de Delta Lake-streamingbron op te geven zonder de hele tabel te verwerken.
startingVersion: de Delta-tabelversie waaruit u wilt beginnen met lezen. Alle tabelwijzigingen die zijn doorgevoerd op of na de opgegeven versie, worden gelezen door de stream. Als de opgegeven versie niet beschikbaar is, kan de stream niet worden gestart.Als u beschikbare doorvoerversies wilt zoeken, voert u de opdracht uit
DESCRIBE HISTORYen controleert u hetversion. Als u alleen de meest recente wijzigingen wilt retourneren, geeft u oplatest. Zie Werken met tabelgeschiedenis voor informatie over Delta-tabelversies.startingTimestamp: De tijdstempel om vanaf te lezen. Alle tabelwijzigingen die zijn doorgevoerd op of na de opgegeven tijdstempel, worden gelezen door de stream. Als de opgegeven tijdstempel voorafgaat aan alle tabeldoorvoeringen, begint de streaming-leesbewerking met de vroegste beschikbare tijdstempel. Stel een van de volgende opties in:- Een tijdstempeltekenreeks. Bijvoorbeeld:
"2019-01-01T00:00:00.000Z". - Een datumstring. Bijvoorbeeld:
"2019-01-01".
- Een tijdstempeltekenreeks. Bijvoorbeeld:
U kunt beide startingVersion en startingTimestamp tegelijkertijd niet instellen. Deze instellingen zijn alleen van toepassing op nieuwe streamingquery's. Als een streamingquery is gestart en de voortgang in het controlepunt is vastgelegd, worden deze instellingen genegeerd.
Important
Hoewel u de streamingbron vanuit een opgegeven versie of tijdstempel kunt starten, is het schema van de streamingbron altijd het meest recente schema van de Delta-tabel. U moet ervoor zorgen dat er geen incompatibele schemawijziging in de Delta-tabel is na de opgegeven versie of tijdstempel. Anders kan de streamingbron onjuiste resultaten retourneren bij het lezen van de gegevens met een onjuist schema.
Example
Stel u bijvoorbeeld voor dat u een tabel hebt user_events. Als u wijzigingen wilt lezen sinds versie 5, gebruikt u:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Als u wijzigingen wilt lezen sinds 2018-10-18, gebruikt u:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Eerste momentopname verwerken zonder gegevens te verwijderen
Deze functie is beschikbaar in Databricks Runtime 11.3 LTS en hoger.
In een stateful streamingquery met een gedefinieerd watermerk kunnen verwerkingsbestanden door de wijzigingstijd records in de verkeerde volgorde verwerken. Dit kan ertoe leiden dat het watermerk records onjuist markeert als late gebeurtenissen en ze neerlegt. Dit kan alleen gebeuren wanneer de eerste Delta-momentopname wordt verwerkt in de standaardvolgorde.
Voor streams met een Delta-brontabel verwerkt de query eerst alle gegevens die aanwezig zijn in de tabel en maakt een versie met de naam de eerste momentopname. Standaard worden de gegevensbestanden van de Delta-tabel verwerkt op basis van welk bestand het laatst is gewijzigd. De laatste wijzigingstijd vertegenwoordigt echter niet noodzakelijkerwijs de volgorde van de gebeurtenistijd van de record.
Schakel de withEventTimeOrder optie in om gegevensverlies te voorkomen tijdens de initiële momentopnameverwerking.
withEventTimeOrder verdeelt het tijdsbereik van de gebeurtenis van initiële momentopnamegegevens in tijdbuckets. Elke microbatch verwerkt een bucket door gegevens binnen het tijdsbereik te filteren. De maxFilesPerTrigger en maxBytesPerTrigger opties zijn nog steeds van toepassing om de micro-batchgrootte te beheren, maar alleen bij benadering vanwege de verwerkingsaanpak.
In het volgende diagram ziet u dit proces:
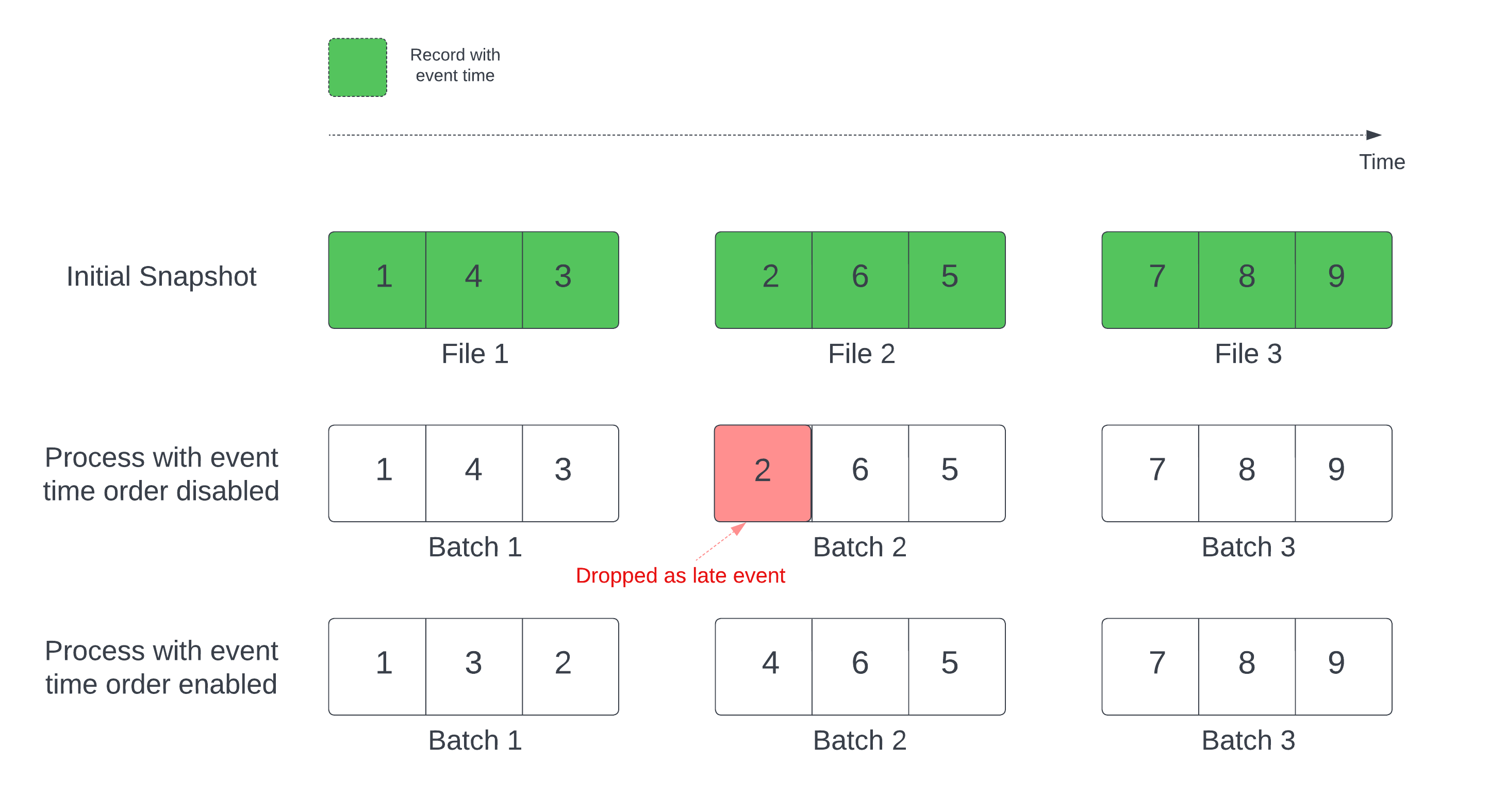
Constraints
- U kunt niet wijzigen
withEventTimeOrderals de streamquery is gestart en de eerste momentopname actief wordt verwerkt. Als u opnieuw wilt opstarten metwithEventTimeOrdergewijzigd, moet u het controlepunt verwijderen. - Als
withEventTimeOrderdeze optie is ingeschakeld, kunt u een stream niet downgraden naar een Databricks Runtime-versie die deze functie pas ondersteunt als de eerste momentopnameverwerking is voltooid. Als u een downgrade wilt uitvoeren, wacht u tot de eerste momentopname is voltooid of verwijdert u het controlepunt en start u de query opnieuw. - Deze functie wordt niet ondersteund in de volgende scenario's:
- De gebeurtenistijdkolom is een gegenereerde kolom en er zijn niet-projectietransformaties tussen de Delta-bron en het watermerk.
- Er is een watermerk met meer dan één Delta-bron in de stream query.
prestatie
Als withEventTimeOrder deze optie is ingeschakeld, zijn de prestaties van de eerste momentopnameverwerking mogelijk trager. Elke microbatch scant de eerste momentopname om gegevens binnen het bijbehorende tijdsbereik van de gebeurtenis te filteren. De filterprestaties verbeteren:
- Gebruik een Delta-bronkolom als gebeurtenistijd, zodat gegevensoverslaan kan worden toegepast. Zie Gegevens overslaan.
- Partitioneer de tabel langs de kolom gebeurtenistijd.
Gebruik de Spark-gebruikersinterface om te zien hoeveel Delta-bestanden worden gescand op een specifieke microbatch.
Example
Stel dat u een tabel hebt user_events met een event_time kolom. Uw streamingquery is een aggregatiequery. Als u er zeker van wilt zijn dat er geen gegevens worden wegvallen tijdens de eerste momentopnameverwerking, kunt u het volgende gebruiken:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
U kunt instellen withEventTimeOrder met een Spark-configuratie op het cluster om deze toe te passen op alle streamingquery's: spark.databricks.delta.withEventTimeOrder.enabled true.
Invoersnelheid beperken om de verwerkingsprestaties te verbeteren
Structured Streaming verwerkt standaard zoveel mogelijk bestanden in elke microbatch. Gebruik de volgende opties om de hoeveelheid gegevens te beperken die per batch worden verwerkt en geheugengebruik te beheren, latentie te stabiliseren of cloudopslagkosten te verlagen:
-
maxFilesPerTrigger: Het aantal nieuwe bestanden dat in elke microbatch moet worden overwogen. De standaardwaarde is 1000. -
maxBytesPerTrigger: De hoeveelheid gegevens die in elke microbatch wordt verwerkt. Met deze optie stelt u een 'voorlopig maximum' in, wat betekent dat een batch ongeveer deze hoeveelheid gegevens verwerkt en meer dan de limiet kan verwerken om de streamingquery verder te laten gaan in gevallen waarin de kleinste invoereenheid groter is dan deze limiet. Dit is niet standaard ingesteld.
Als u beide maxBytesPerTrigger gebruikt en maxFilesPerTrigger, verwerkt de microbatch gegevens totdat de maxFilesPerTrigger of maxBytesPerTrigger limiet is bereikt.
Note
Als logRetentionDuration transacties in de brontabel worden opgeschoond en de streamingquery deze versies probeert te verwerken, kan de query standaard geen gegevensverlies voorkomen. U kunt de optie failOnDataLoss instellen op false om verloren gegevens te negeren en door te gaan met verwerken. Zie Gegevensretentie configureren voor tijdreis-query's.
Kosten voor cloudopslag beheren
Streamingquery's hebben verschillende triggermodi beschikbaar waarmee u kosten en latentie kunt verdelen, waaronder processingTime, availableNowen realTime. Zie De kosten voor cloudopslag beheren.