Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel worden verouderde Azure Databricks-visualisaties beschreven. Zie Visualisaties in Databricks-notebooks en SQL-editor voor ondersteuning voor huidige visualisaties bij het maken van visualisaties in de SQL-editor of een notebook. Zie AI/BI-dashboardvisualisatietypen voor informatie over werken met visualisaties in AI/BI-dashboards.
Azure Databricks biedt ook systeemeigen ondersteuning voor visualisatiebibliotheken in Python en R en laat u bibliotheken van derden installeren en gebruiken.
Een verouderde visualisatie maken
Als u een verouderde visualisatie wilt maken vanuit een resultatencel, klikt u op + en selecteert u Verouderde visualisatie.
Verouderde visualisaties ondersteunen een uitgebreide set plottypen:
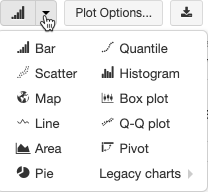
Een verouderd grafiektype kiezen en configureren
Als u een staafdiagram wilt kiezen, klikt u op het staafdiagrampictogram  :
:
Als u een ander tekentype wilt kiezen, klikt u ![]() rechts van het staafdiagram en kiest u het tekentype.
rechts van het staafdiagram en kiest u het tekentype.
Verouderde grafiekwerkbalk
Zowel lijn- als staafdiagrammen hebben een ingebouwde werkbalk die ondersteuning biedt voor een uitgebreide set interacties aan de clientzijde.
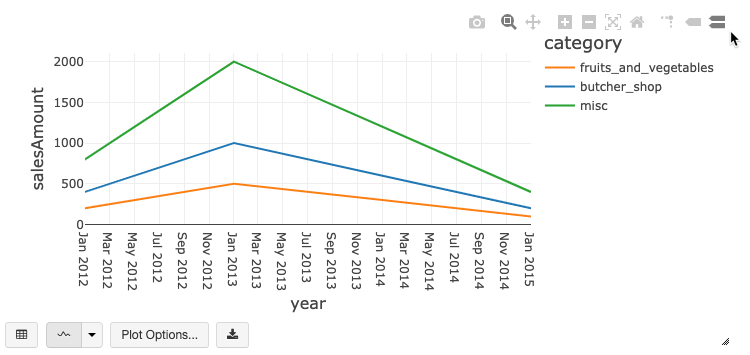
Als u een grafiek wilt configureren, klikt u op Plotopties….
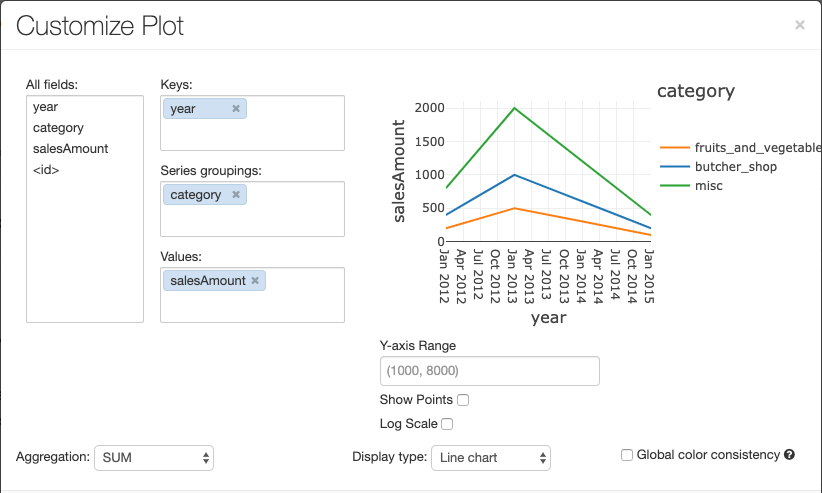
Het lijndiagram heeft een aantal aangepaste grafiekopties: een bereik voor de y-as instellen, punten weergeven en verbergen, en de y-as met een logaritmische schaal weergeven.
Voor informatie over verouderde grafiektypen bekijkt u:
Kleurconsistentie in grafieken
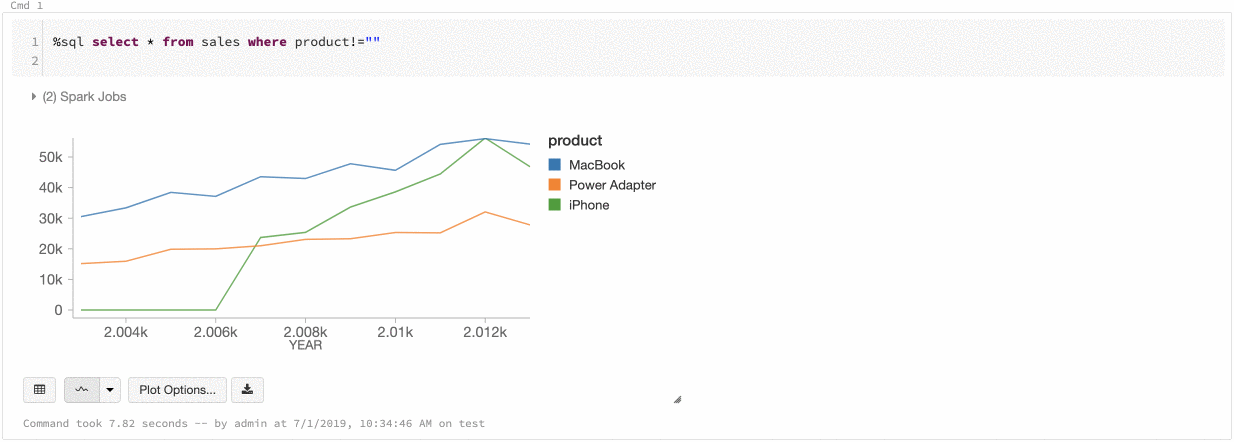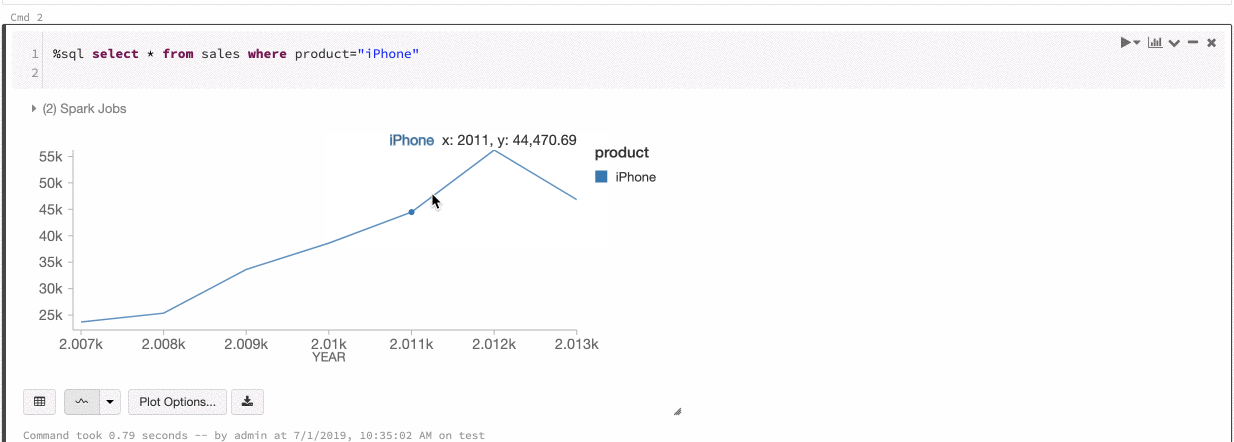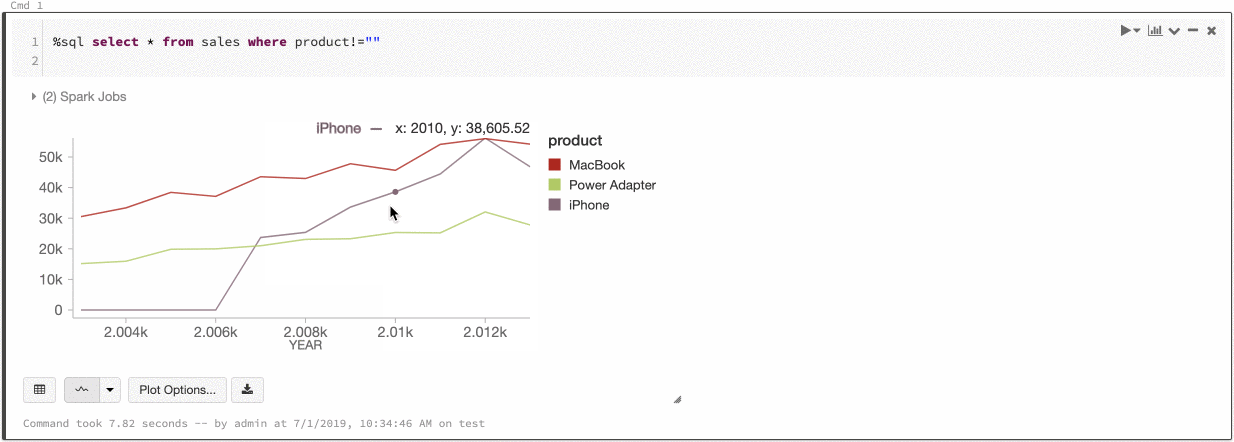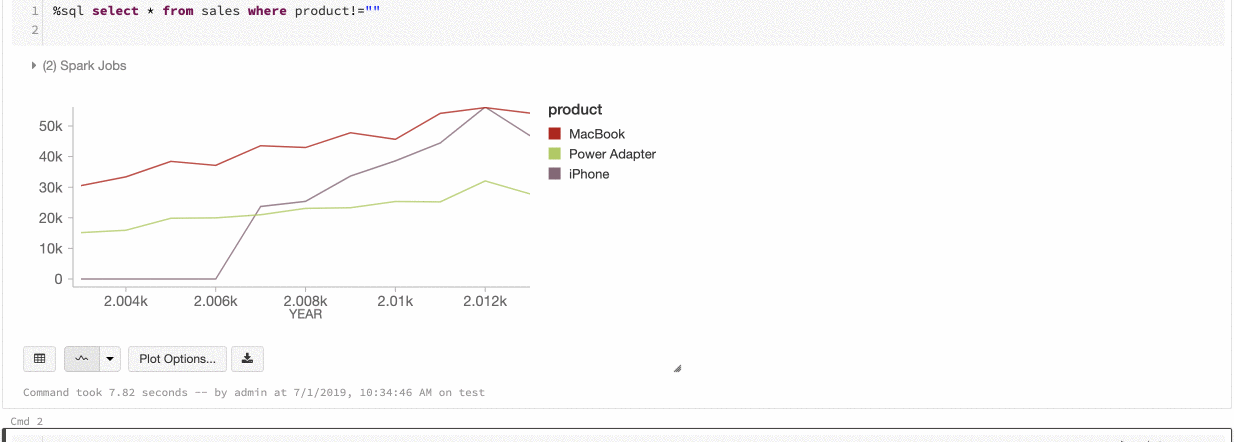
Azure Databricks ondersteunt twee soorten kleurconsistentie in verouderde grafieken: reeksenset en globaal.
De -reeks met-kleurconsistentie wijst dezelfde kleur toe aan dezelfde waarde wanneer u reeksen hebt met dezelfde waarden, maar in verschillende volgordes (bijvoorbeeld, A = ["Apple", "Orange", "Banana"] en B = ["Orange", "Banana", "Apple"]). De waarden worden gesorteerd voordat ze worden uitgezet, dus beide legenda's worden op dezelfde manier gesorteerd (["Apple", "Banana", "Orange"]) en dezelfde waarden krijgen dezelfde kleuren. Als u echter een reeks C = ["Orange", "Banana"]hebt, is het niet kleurconsistent met set A, omdat de set niet hetzelfde is. Het sorteeralgoritmen wijzen de eerste kleur toe aan 'Banaan' in set C, maar de tweede kleur aan 'Banaan' in set A. Als u wilt dat deze reeks kleurconsistent is, kunt u opgeven dat grafieken globale kleurconsistentie moeten hebben.
In globale kleurconsistentie wordt elke waarde altijd toegewezen aan dezelfde kleur, ongeacht welke waarden de reeks heeft. Als u dit wilt inschakelen voor elke grafiek, schakelt u het selectievakje Globale kleurconsistentie in.
Notitie
Om deze consistentie te bereiken, past Azure Databricks hashen direct toe van de waarden naar de kleuren. Om conflicten te voorkomen (waarbij twee waarden naar exact dezelfde kleur gaan), is de hash naar een grote verzameling kleuren, wat als bijwerking heeft dat mooie of gemakkelijk te onderscheiden kleuren niet kunnen worden gegarandeerd; met veel kleuren zijn er zeker enkele die erg op elkaar lijken.
Machine learning-visualisaties
Naast de standaardgrafiektypen ondersteunen verouderde visualisaties de volgende machine learning-trainingsparameters en -resultaten:
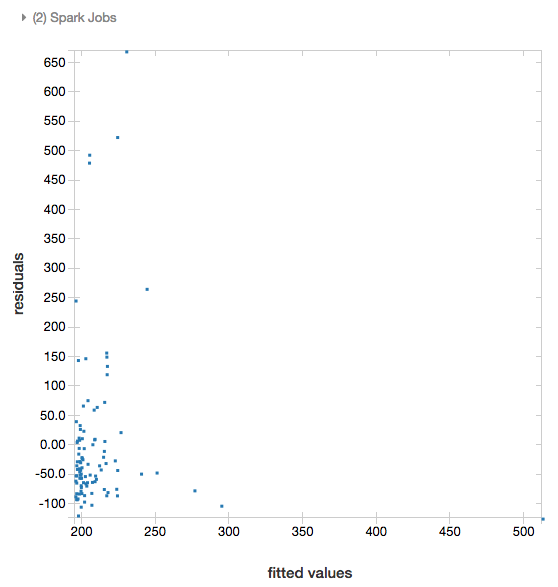
Residuen
Voor lineaire en logistieke regressies kunt u een gefitte versus residuenplot weergeven. Geef het model en DataFrame op om deze plot te verkrijgen.
Met het volgende voorbeeld wordt een lineaire regressie uitgevoerd op het verband tussen stadsbevolking en verkoopprijzen van huizen en worden vervolgens de residuen tegenover de aangepaste gegevens weergegeven.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
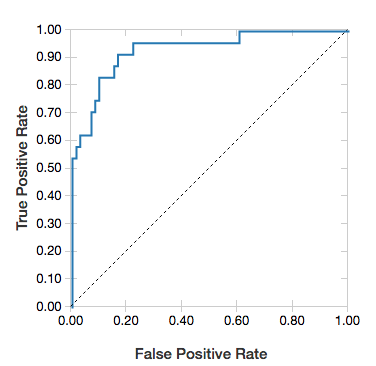
ROC-curves
Voor logistieke regressies kunt u een ROC-curve weergeven. Als u deze plot wilt verkrijgen, geeft u het model op, de vooraf gemaakte gegevens die worden ingevoerd voor de fit methode en de parameter "ROC".
In het volgende voorbeeld wordt een classificatie ontwikkeld die voorspelt of een persoon =50K of <50k per jaar verdient >op basis van verschillende kenmerken van het individu. De gegevensset Volwassen is afgeleid van censusgegevens en bestaat uit informatie over 48.842 individuen en hun jaarlijkse inkomen.
In de voorbeeldcode in dit gedeelte wordt one-hot encoding gebruikt.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
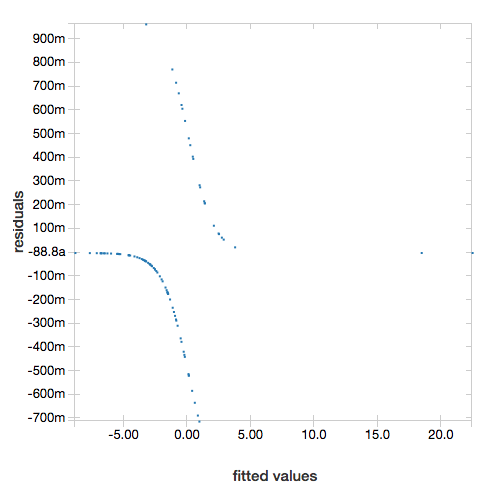
Om de residuen weer te geven, laat u de parameter "ROC" weg:
display(lrModel, preppedDataDF)
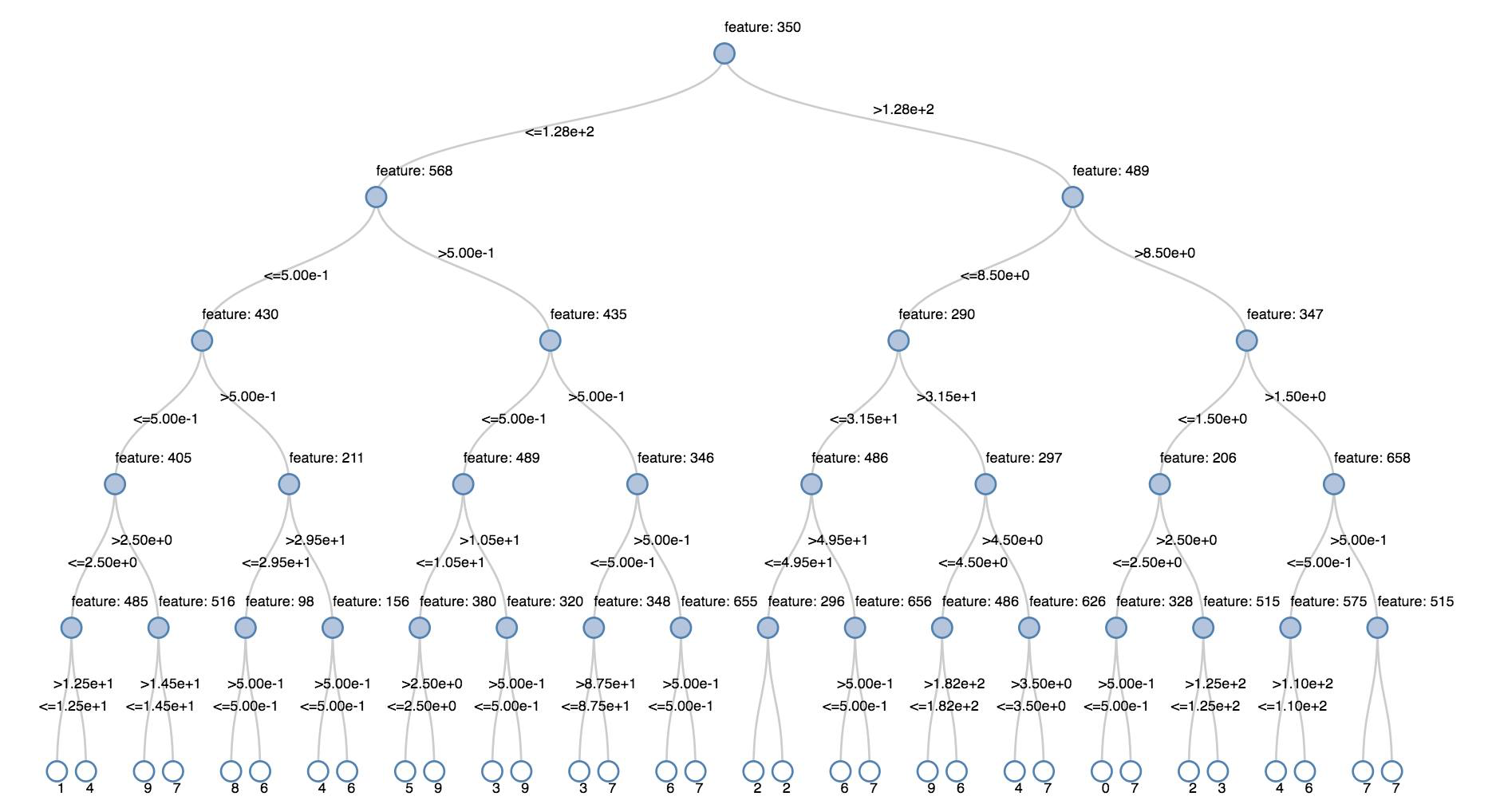
Beslissingsbomen
Verouderde visualisaties ondersteunen het weergeven van een beslissingsstructuur.
Geef het beslissingsstructuurmodel op om deze visualisatie te verkrijgen.
Met de volgende voorbeelden wordt een structuur getraind om cijfers (0-9) te herkennen uit de MNIST-gegevensset met afbeeldingen van handgeschreven cijfers en wordt de structuur vervolgens weergegeven.
Python
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
Gestructureerde Streaming DataFrames
Als u het resultaat van een streaming-query in realtime wilt visualiseren, kunt u een Gestructureerd Streaming-DataFrame display in Scala en Python.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display ondersteunt de volgende optionele parameters:
-
streamName: de naam van de streaming-query. -
trigger(Scala) enprocessingTime(Python): definieert hoe vaak de streaming-query wordt uitgevoerd. Als dit niet is opgegeven, controleert het systeem op beschikbaarheid van nieuwe gegevens zodra de vorige verwerking is voltooid. Om de kosten in productie te verlagen, raadt Databricks u aan altijd een triggerinterval in te stellen. Het standaardtriggerinterval is 500 ms. -
checkpointLocation: de locatie waar het systeem alle controlepuntgegevens schrijft. Als dit niet is opgegeven, genereert het systeem automatisch een tijdelijke controlepuntlocatie op DBFS. Als u wilt dat uw stream gegevens blijft verwerken vanaf waar deze was gebleven, moet u een controlepuntlocatie opgeven. Databricks raadt u aan om in productie altijd decheckpointLocation-optie op te geven.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Voor meer informatie over deze parameters, zie Starten van streamingquery's.
displayHTML-functie
Azure Databricks-programmeertaalnotebooks (Python, R en Scala) ondersteunen HTML-afbeeldingen met behulp van de displayHTML-functie; u kunt elke HTML-, CSS- of JavaScript-code aan de functie doorgeven. Deze functie ondersteunt interactieve afbeeldingen die gebruikmaken van JavaScript-bibliotheken zoals D3.
Voor voorbeelden van het gebruik van displayHTML bekijkt u:
Notitie
Het iframe displayHTML wordt aangeleverd vanuit het domein databricksusercontent.com, en de iframe-sandbox bevat het kenmerk allow-same-origin.
databricksusercontent.com moet toegankelijk zijn via uw browser. Als het momenteel wordt geblokkeerd door uw bedrijfsnetwerk, moet deze worden toegevoegd aan een acceptatielijst.
Beelden
Kolommen met afbeeldingsgegevenstypen worden weergegeven als uitgebreide HTML. Azure Databricks probeert afbeeldingsminiaturen weer te geven voor DataFrame kolommen die overeenkomen met het Spark ImageSchema.
Miniatuurweergave werkt voor afbeeldingen die succesvol zijn ingelezen via de spark.read.format('image')-functie. Voor afbeeldingswaarden die worden gegenereerd via andere middelen, ondersteunt Azure Databricks het weergeven van afbeeldingen van 1, 3 of 4 kanalen (waarbij elk kanaal uit één byte bestaat), met de volgende beperkingen:
-
1-kanaals afbeeldingen: het veld
modemoet gelijk zijn aan 0. De veldenheight,widthennChannelsmoeten de binaire afbeeldingsgegevens in het velddatanauwkeurig beschrijven. -
3-kanaals afbeeldingen: het veld
modemoet gelijk zijn aan 16. De veldenheight,widthennChannelsmoeten de binaire afbeeldingsgegevens in het velddatanauwkeurig beschrijven. Het velddatamoet pixelgegevens bevatten in stukken van 3 byte, waarbij de kanaalindeling(blue, green, red)voor elke pixel is. -
4-kanaals afbeeldingen: het veld
modemoet gelijk zijn aan 24. De veldenheight,widthennChannelsmoeten de binaire afbeeldingsgegevens in het velddatanauwkeurig beschrijven. Het velddatamoet pixelgegevens in chunks van 4 bytes bevatten, met de kanaalvolgorde(blue, green, red, alpha)voor elke pixel.
Voorbeeld
Stel dat u een map hebt die wat afbeeldingen bevat:

Als u de afbeeldingen in een DataFrame leest en vervolgens het DataFrame weergeeft, geeft Azure Databricks miniaturen weer van de afbeeldingen:
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Visualisaties in Python
In deze sectie:
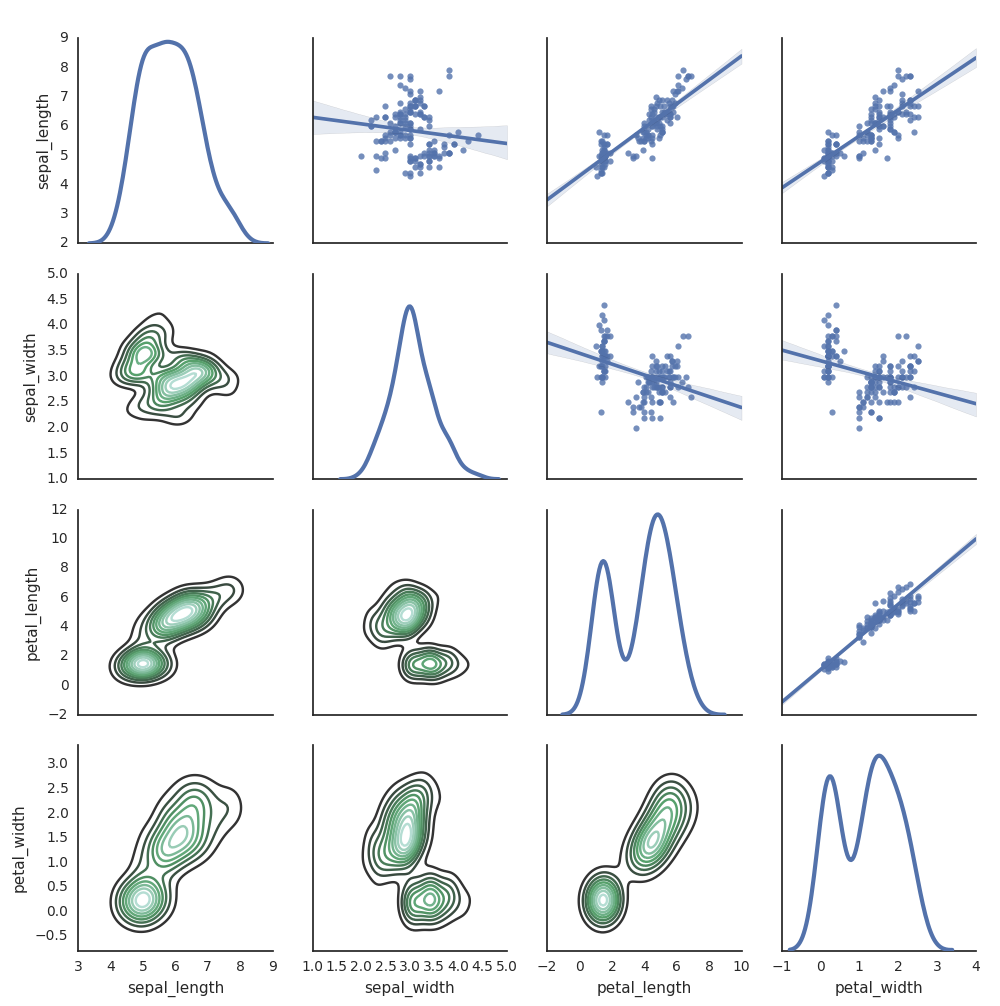
Seaborn
U kunt ook andere Python-bibliotheken gebruiken om plots te genereren. De Databricks Runtime bevat de visualisatiebibliotheek Seaborn. Als u een Seaborn-grafiek wilt maken, importeert u de bibliotheek, maakt u een grafiek en geeft u de grafiek door aan de display-functie.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
Andere Python-bibliotheken
Visualisaties in R
Als u gegevens wilt tekenen in R, gebruikt u de display-functie als volgt:
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
U kunt de standaard grafiek-functie van R gebruiken.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
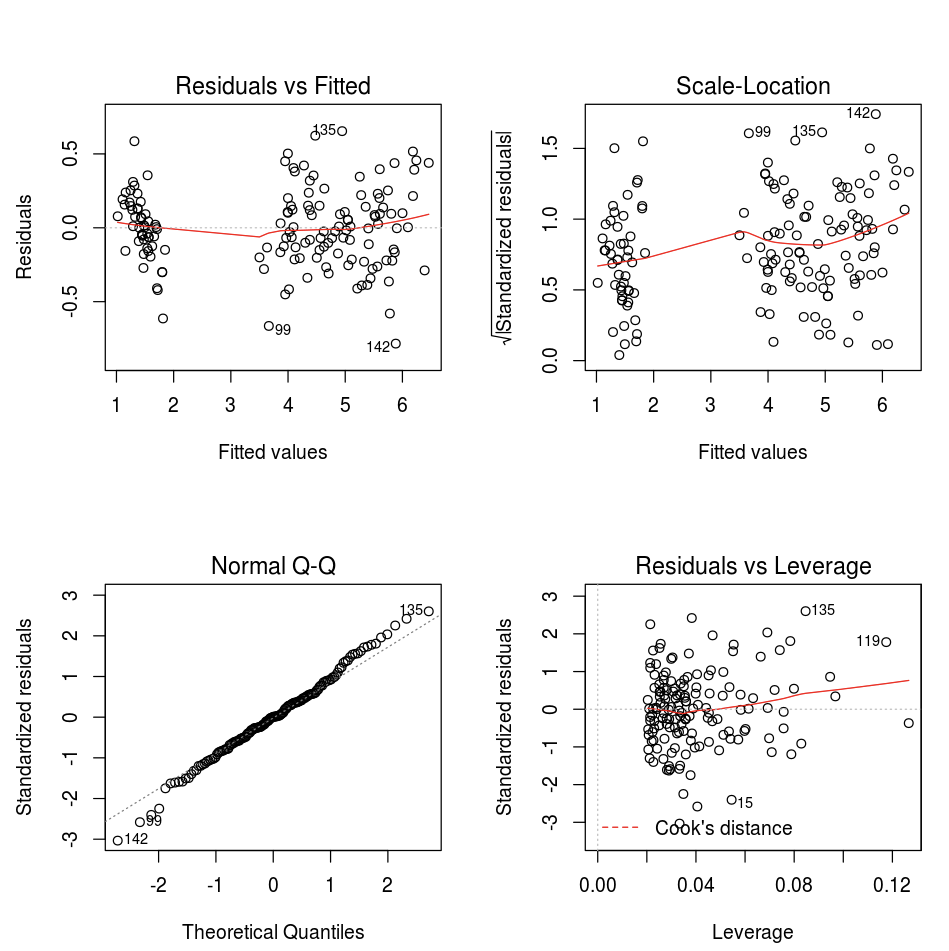
U kunt ook elk R-visualisatiepakket gebruiken. Met het R-notebook wordt de resulterende grafiek als een .png vastgelegd en inline weergegeven.
In deze sectie:
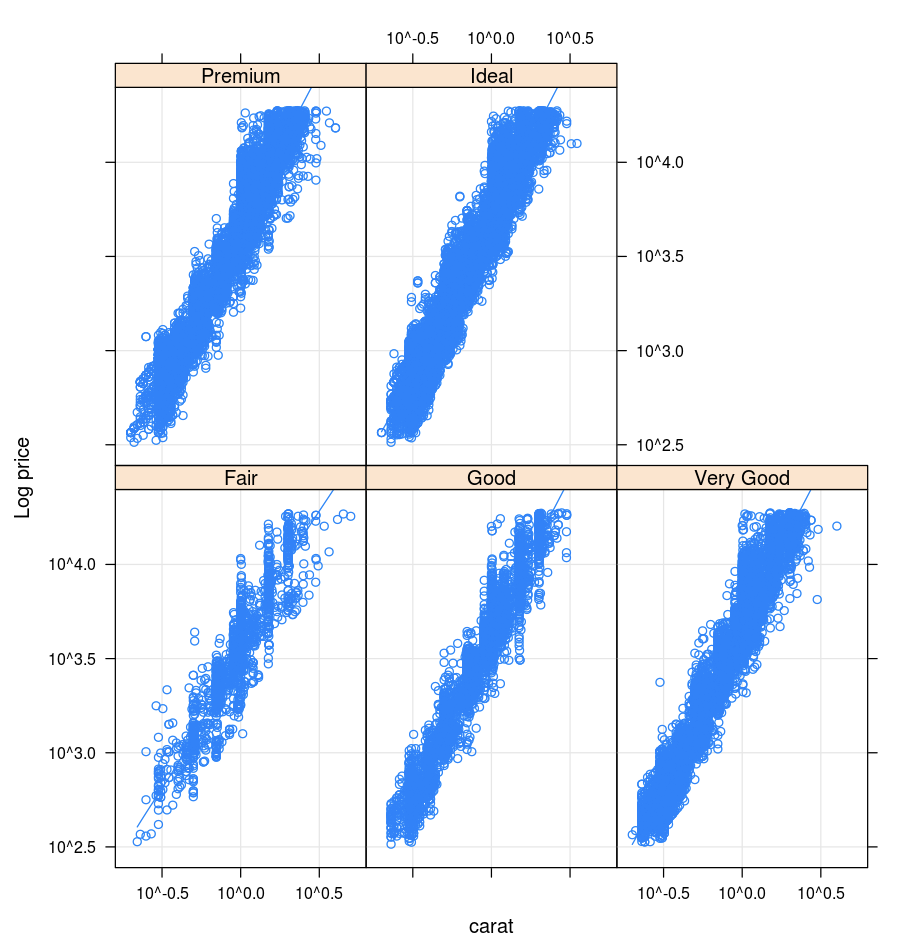
Latwerk
Het Lattice-pakket ondersteunt latwerkgrafieken: grafieken die een variabele of de relatie tussen variabelen weergeven, met een of meer andere variabelen als voorwaarde.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
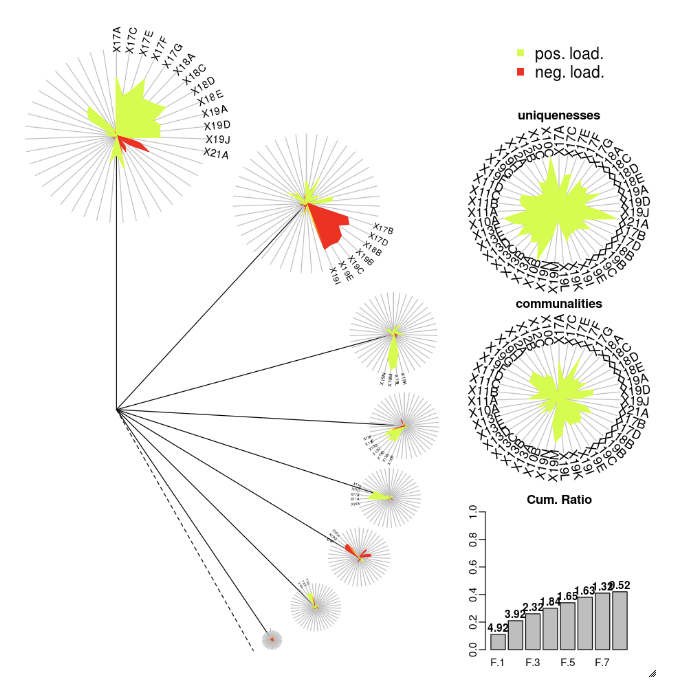
DandEFA
Het DandEFA-pakket ondersteunt dandelion-diagrammen.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
Plotly
Het Plotly R-pakket is afhankelijk van htmlwidgets voor R. Zie htmlwidgets voor installatie-instructies en een notebook.
Andere R-bibliotheken
Visualisaties in Scala
Als u gegevens wilt tekenen in Scala, gebruikt u de display-functie als volgt:
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Diepgaand onderzoek naar notebooks voor Python en Scala
Zie het notebook voor meer informatie over Python-visualisaties:
Zie het notebook voor uitgebreide informatie over Scala-visualisaties: