Waarom gegevenspijplijnen?
Azure DevOps Services
U kunt gegevenspijplijnen gebruiken voor het volgende:
- Gegevens uit verschillende gegevensbronnen opnemen
- De gegevens verwerken en transformeren
- De verwerkte gegevens opslaan op een faseringslocatie zodat anderen deze kunnen gebruiken
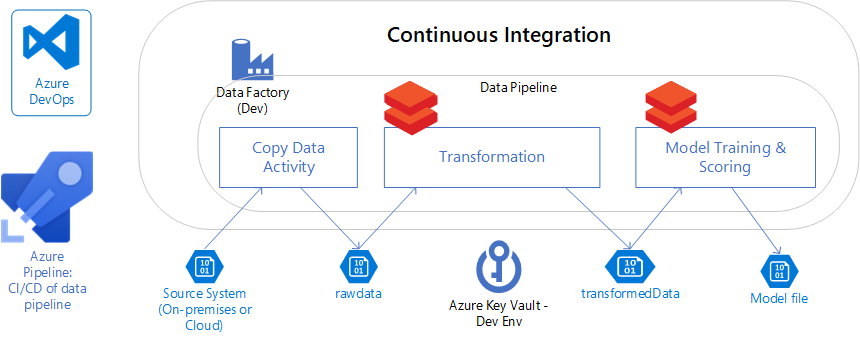
Gegevenspijplijnen in de onderneming kunnen zich ontwikkelen tot complexere scenario's met meerdere bronsystemen en ondersteuning voor verschillende downstreamtoepassingen.
Gegevenspijplijnen bieden:
- Consistentie: gegevenspijplijnen transformeren gegevens in een consistente indeling die gebruikers kunnen gebruiken
- Foutreductie: Geautomatiseerde gegevenspijplijnen elimineren menselijke fouten bij het bewerken van gegevens
- Efficiëntie: Gegevensprofessionals besparen tijd aan gegevensverwerkingstransformatie. Door tijd te besparen, kunnen ze zich richten op hun kerntaakfunctie: het inzicht krijgen in de gegevens en het bedrijf helpen betere beslissingen te nemen
Wat is CI/CD?
Continue integratie en continue levering (CI/CD) is een benadering voor softwareontwikkeling waarbij alle ontwikkelaars samenwerken aan een gedeelde opslagplaats met code. Als er wijzigingen worden aangebracht, is er een geautomatiseerd buildproces voor het detecteren van codeproblemen. Het resultaat is een snellere ontwikkelingslevenscyclus en een lager foutenpercentage.
Wat is een CI/CD-gegevenspijplijn en waarom is dit belangrijk voor gegevenswetenschap?
Het bouwen van machine learning-modellen is vergelijkbaar met traditionele softwareontwikkeling, in die zin dat de data scientist code moet schrijven om machine learning-modellen te trainen en scoren.
In tegenstelling tot traditionele softwareontwikkeling waarbij het product is gebaseerd op code, zijn machine learning-modellen voor data science gebaseerd op zowel de code (algoritme, hyperparameters) als de gegevens die worden gebruikt om het model te trainen. Daarom zullen de meeste gegevenswetenschappers u vertellen dat ze 80% van de tijd bezig zijn met gegevensvoorbereiding, opschoning en functie-engineering.
Om de zaak nog ingewikkelder te maken: om de kwaliteit van de machine learning-modellen te garanderen, worden technieken zoals A/B-testen gebruikt. Met A/B-tests kunnen er meerdere machine learning-modellen tegelijk worden gebruikt. Er zijn meestal één controlemodel en een of meer behandelmodellen ter vergelijking, zodat de prestaties van het model kunnen worden vergeleken en behouden. Als u meerdere modellen hebt, voegt u nog een laag complexiteit toe voor de CI/CD van machine learning-modellen.
Het hebben van een CI/CD-gegevenspijplijn is van cruciaal belang voor het data science-team om de machine learning-modellen tijdig en op een kwaliteitsmatige manier aan het bedrijf te leveren.
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor