Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure DevOps Services | Azure DevOps Server | Azure DevOps Server 2022
Variabelen bieden een handige manier om belangrijke gegevens op te nemen in verschillende onderdelen van de pijplijn. Het meest voorkomende gebruik van variabelen is het definiëren van een waarde die u in uw pijplijn kunt gebruiken. Alle variabelen zijn tekenreeksen en zijn veranderlijk. De waarde van een variabele kan veranderen van uitvoering naar uitvoering of taak in uw pijplijn.
Wanneer u dezelfde variabele op meerdere plaatsen met dezelfde naam definieert, heeft de meest lokaal bereikvariabele voorrang. Een variabele die op taakniveau is gedefinieerd, kan dus een variabele die is ingesteld op faseniveau overschrijven. Een variabele die op faseniveau is gedefinieerd, overschrijft een variabele die is ingesteld op het hoofdniveau van de pijplijn. Een variabele die is ingesteld op het hoofdniveau van de pijplijn overschrijft een variabele die is ingesteld in de gebruikersinterface voor pijplijninstellingen. Zie Variabele scope voor meer informatie over het werken met variabelen die zijn gedefinieerd op job-, stage- en rootniveau.
U kunt variabelen gebruiken met expressies om waarden voorwaardelijk toe te wijzen en pipelines verder aan te passen.
Variabelen verschillen van runtimeparameters. Runtime parameters worden getypt en zijn beschikbaar tijdens het parseren van sjablonen.
Door de gebruiker gedefinieerde variabelen
Wanneer u een variabele definieert, gebruikt u verschillende syntaxisen (macro, sjabloonexpressie of runtime). De syntaxis die u kiest, bepaalt waar in de pijplijn uw variabele wordt weergegeven.
Stel in YAML-pipelines variabelen in op de hoofd-, fase- en taakniveaus. U kunt ook variabelen opgeven buiten een YAML-pijplijn in de gebruikersinterface. Wanneer u een variabele instelt in de gebruikersinterface, kunt u de variabele versleutelen en instellen als geheim.
Door de gebruiker gedefinieerde variabelen kunnen worden ingesteld als alleen-lezen. Er zijn naamgevingsbeperkingen voor variabelen (bijvoorbeeld: u kunt niet gebruiken secret aan het begin van een variabelenaam).
U kunt een variabelegroep gebruiken om variabelen beschikbaar te maken voor meerdere pipelines.
Als u variabelen in één bestand wilt definiëren voor gebruik in meerdere pipelines, gebruikt u templates.
Door de gebruiker gedefinieerde variabelen met meerdere regels
Azure DevOps ondersteunt variabelen met meerdere regels, maar er zijn enkele beperkingen.
Downstreamonderdelen zoals pijplijntaken verwerken mogelijk niet correct de variabelewaarden.
Azure DevOps wijzigt geen door de gebruiker gedefinieerde variabele waarden. U moet variabelewaarden correct opmaken voordat u ze doorgeeft als variabelen met meerdere regels. Wanneer u de variabele opmaakt, vermijdt u speciale tekens, gebruikt u geen beperkte namen en zorgt u ervoor dat u een regeleindindeling gebruikt die geschikt is voor het besturingssysteem van uw agent.
Variabelen met meerdere regels gedragen zich anders, afhankelijk van het besturingssysteem. Om dit probleem te voorkomen, moet u ervoor zorgen dat u meerregelige variabelen correct formatteert voor het doelbesturingssysteem.
Azure DevOps wijzigt nooit variabele waarden, zelfs als u niet-ondersteunde opmaak opgeeft.
Systeemvariabelen
Naast door de gebruiker gedefinieerde variabelen heeft Azure Pipelines systeemvariabelen met vooraf gedefinieerde waarden. De vooraf gedefinieerde variabele Build.BuildId geeft bijvoorbeeld de id van elke build en kan worden gebruikt om verschillende pijplijnuitvoeringen te identificeren. U kunt de Build.BuildId variabele in scripts of taken gebruiken wanneer u een unieke waarde nodig hebt.
Als u YAML of klassieke build-pipelines gebruikt, raadpleegt u predefined variables voor een uitgebreide lijst met systeemvariabelen.
Als u klassieke release-pipelines gebruikt, raadpleegt u releasevariabelen.
Wanneer u de pijplijn uitvoert, stellen de systeemvariabelen hun huidige waarde in. Sommige variabelen worden automatisch ingesteld. Als auteur van een pijplijn of eindgebruiker kunt u de waarde van een systeemvariabele wijzigen voordat de pijplijn wordt uitgevoerd.
Systeemvariabelen zijn alleen lezen.
Omgevingsvariabelen
Omgevingsvariabelen zijn specifiek voor het besturingssysteem dat u gebruikt. U injecteert ze in een pijplijn op platformspecifieke manieren. De indeling komt overeen met hoe omgevingsvariabelen worden opgemaakt voor uw specifieke scriptplatform.
Op UNIX-systemen (macOS en Linux) hebben omgevingsvariabelen de indeling $NAME. Op Windows is %NAME% de indeling voor batch en is $env:NAME in PowerShell.
Systeem- en door de gebruiker gedefinieerde variabelen (behalve geheime variabelen) worden ook opgenomen als omgevingsvariabelen voor uw platform. Wanneer variabelen worden omgezet in omgevingsvariabelen, worden de variabelennamen omgezet in hoofdletters en worden punten omgezet in onderstrepingstekens. De naam any.variable van de variabele wordt bijvoorbeeld de naam van $ANY_VARIABLEde variabele.
Er zijn beperkingen voor naamgeving van variabelen voor omgevingsvariabelen (bijvoorbeeld: u kunt niet gebruiken secret aan het begin van een variabelenaam).
Beperkingen voor naamgeving van variabelen
Door de gebruiker gedefinieerde en omgevingsvariabelen kunnen bestaan uit letters, .cijfers en _ tekens. Gebruik geen variabele voorvoegsels die door het systeem zijn gereserveerd. Deze voorvoegsels zijn: endpoint, input, secret, pathen securefile. Elke variabele die begint met een van deze tekenreeksen (ongeacht hoofdlettergebruik) is niet beschikbaar voor uw taken en scripts. Gebruik geen spaties in variabelen. Zie Azure Pipelines naamgevingsbeperkingen voor aanvullende beperkingen.
Inzicht in de syntaxis van variabelen
Azure Pipelines ondersteunt drie verschillende manieren om te verwijzen naar variabelen: macro, sjabloonexpressie en runtime-expressie. U kunt elke syntaxis voor een ander doel gebruiken en elke syntaxis heeft enkele beperkingen.
In een pijplijn worden sjabloonexpressievariabelen (${{ variables.var }}) verwerkt tijdens het compileren, voordat runtime wordt gestart. Macrosyntaxisvariabelen ($(var)) worden tijdens runtime verwerkt voordat een taak wordt uitgevoerd. Runtime-expressies ($[variables.var]) worden ook verwerkt tijdens runtime, maar zijn bedoeld voor gebruik met voorwaarden en expressies. Wanneer u een runtime-expressie gebruikt, moet deze de volledige rechterkant van een definitie in beslag nemen.
In dit voorbeeld ziet u dat de sjabloonexpressie nog steeds de oorspronkelijke waarde van de variabele heeft nadat de variabele is bijgewerkt. De waarde van de variabele macrosyntaxis wordt bijgewerkt. De waarde van de sjabloonexpressie verandert niet omdat de pijplijn alle sjabloonexpressievariabelen tijdens het compileren verwerkt voordat taken worden uitgevoerd. Macrosyntaxisvariabelen worden daarentegen geëvalueerd voordat elke taak wordt uitgevoerd.
variables:
- name: one
value: initialValue
steps:
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one)
displayName: First variable pass
- bash: echo "##vso[task.setvariable variable=one]secondValue"
displayName: Set new variable value
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one) # outputs secondValue
displayName: Second variable pass
Macrosyntaxisvariabelen
In de meeste documentatievoorbeelden wordt gebruikgemaakt van macrosyntaxis ($(var)). Gebruik macrosyntaxis om variabele waarden te interpoleren in taakinvoer en in andere variabelen.
Het systeem verwerkt variabelen met macrosyntaxis voordat een taak tijdens runtime wordt uitgevoerd. Runtime vindt plaats na sjabloonuitbreiding. Wanneer het systeem een macro-expressie tegenkomt, wordt de expressie vervangen door de inhoud van de variabele. Als er geen variabele is op basis van die naam, verandert de macro-expressie niet. Als $(var) niet kan worden vervangen, blijft het als $(var).
Macrosyntaxisvariabelen blijven ongewijzigd wanneer ze geen waarde hebben, omdat een lege waarde, zoals $() iets kan betekenen voor de taak die u uitvoert en de agent mag er niet van uitgaan dat u die waarde wilt vervangen. Als u bijvoorbeeld met $(foo) naar variabele foo verwijst in een Bash-taak, kan het vervangen van alle $()-expressies in de invoer voor de taak uw Bash-scripts breken.
Macrovariabelen worden alleen uitgevouwen wanneer ze worden gebruikt voor een waarde, niet als trefwoord. Waarden worden rechts van een pijplijndefinitie weergegeven. Het volgende is geldig: key: $(value). Het volgende is niet geldig: $(key): value. Macrovariabelen worden niet uitgevouwen wanneer deze worden gebruikt om een taaknaam inline weer te geven. In plaats daarvan moet u de displayName eigenschap gebruiken.
Notitie
Het systeem breidt alleen macrosyntaxisvariabelen uit voor taakinvoer binnen stages, jobsen steps.
Ze worden niet uitgebreid in pijplijntrefwoorden die tijdens het compileren worden omgezet, zoals resources, triggerof de referentiewaarde van de opslagplaats van de checkout stap (werkt bijvoorbeeld checkout: git://MyProject/MyRepo@$(var) niet).
Als u deze waarden wilt parameteriseren, gebruikt u in plaats daarvan sjabloonexpressies (${{ }}) of runtimeparameters .
In dit voorbeeld worden macrosyntaxis gebruikt met Bash, PowerShell en een scripttaak. De syntaxis voor het aanroepen van een variabele met behulp van macrosyntaxis is hetzelfde voor alle drie.
variables:
- name: projectName
value: contoso
steps:
- bash: echo $(projectName)
- powershell: echo $(projectName)
- script: echo $(projectName)
Syntaxis van sjabloonexpressie
Gebruik de syntaxis van de sjabloonexpressie om zowel sjabloonparameters als variabelen (${{ variables.var }}) uit te vouwen. Het systeem verwerkt sjabloonvariabelen tijdens het compileren en vervangt deze voordat de runtime wordt gestart. Gebruik sjabloonexpressies voor het hergebruik van onderdelen van YAML als sjablonen.
Sjabloonvariabelen worden op de achtergrond gekoppeld aan lege tekenreeksen wanneer er geen vervangingswaarde wordt gevonden. Sjabloonexpressies, in tegenstelling tot macro- en runtime-expressies, kunnen worden weergegeven als sleutels (links) of waarden (rechterkant). Het volgende is geldig: ${{ variables.key }} : ${{ variables.value }}.
Syntaxis van runtime-expressie
Gebruik de syntaxis van runtime-expressies voor variabelen die tijdens runtime ($[variables.var]) worden uitgebreid. Runtime-expressievariabelen samenvoegen op de achtergrond tot lege tekenreeksen wanneer er geen vervangingswaarde wordt gevonden. Gebruik runtime-expressies in taakvoorwaarden ter ondersteuning van voorwaardelijke uitvoering van taken of hele fasen.
Runtime-expressievariabelen worden alleen uitgebreid wanneer ze worden gebruikt voor een waarde, niet als trefwoord. Waarden worden rechts van een pijplijndefinitie weergegeven. Het volgende is geldig: key: $[variables.value]. Het volgende is niet geldig: $[variables.key]: value. De runtime-expressie moet de volledige rechterkant van een sleutel-waardepaar in beslag nemen. Een voorbeeld: key: $[variables.value] is geldig, maar key: $[variables.value] foo is dat niet.
| Syntaxis | Voorbeeld | Wanneer wordt het verwerkt? | Waar breidt het zich uit in een pijplijndefinitie? | Hoe wordt deze weergegeven wanneer deze niet wordt gevonden? |
|---|---|---|---|---|
| macro | $(var) |
runtime voordat een taak wordt uitgevoerd | waarde (rechterkant) | Afdrukken $(var) |
| sjabloonexpressie | ${{ variables.var }} |
compilatietijd | sleutel of waarde (linker- of rechterzijde) | lege tekenreeks |
| uitvoeringstijd-expressie | $[variables.var] |
looptijd | waarde (rechterkant) | lege tekenreeks |
Welke syntaxis moet ik gebruiken?
Gebruik macrosyntaxis als u een beveiligde tekenreeks of een voorgedefinieerde variabele invoer voor een taak opgeeft.
Kies een runtime-expressie als u met voorwaarden en expressies werkt. Gebruik echter geen runtime-expressie als u niet wilt dat uw lege variabele wordt afgedrukt (bijvoorbeeld: $[variables.var]). Als u bijvoorbeeld voorwaardelijke logica hebt die afhankelijk is van een variabele met een specifieke waarde of geen waarde, gebruikt u een macro-expressie.
Normaal gesproken is een sjabloonvariabele de standaard die moet worden gebruikt. Door gebruik te maken van sjabloonvariabelen, injecteert uw pijplijn de variabele waarde volledig in uw pijplijn bij het compileren van pijplijnen. Deze injectie is handig bij het opsporen van fouten in pipelines. U kunt de logboekbestanden downloaden en de volledig uitgebreide waarde evalueren die wordt vervangen. Omdat de variabele wordt vervangen, maakt u geen gebruik van sjabloonsyntaxis voor gevoelige waarden.
AI gebruiken om problemen met de syntaxis van variabelen te identificeren
In dit voorbeeld voor Copilot Chat wordt geïdentificeerd welke typen variabelen in een pijplijn worden gebruikt en wanneer de variabelen worden opgelost. Markeer uw YAML-code en voer vervolgens de volgende Copilot-chatprompt in.
What types of Azure DevOps variables are used in this YAML pipeline? Give specific examples.
When does each variable process in the pipeline?
How will each variable render when not found?
What stages and jobs will the variables be available for?
Pas uw prompt aan om zo nodig specifieke gegevens toe te voegen.
Copilot wordt mogelijk gemaakt door AI, dus verrassingen en fouten zijn mogelijk. Zie Copilot veelgestelde vragen voor meer informatie.
Variabelen instellen in de pijplijn
Stel in het meest voorkomende geval de variabelen in en gebruik ze in het YAML-bestand. Met deze methode kunt u wijzigingen in de variabele in uw versiebeheersysteem bijhouden. U kunt ook variabelen definiëren in de gebruikersinterface voor pijplijninstellingen (zie het tabblad Klassiek) en ernaar verwijzen in uw YAML.
In het volgende voorbeeld ziet u hoe u twee variabelen configuration instelt en platformlater in stappen gebruikt. Als u een variabele in een YAML-instructie wilt gebruiken, verpakt u deze in $(). U kunt variabelen niet gebruiken om een repository in een YAML-instructie te definiëren.
# Set variables once
variables:
configuration: debug
platform: x64
steps:
# Use them once
- task: MSBuild@1
inputs:
solution: solution1.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
# Use them again
- task: MSBuild@1
inputs:
solution: solution2.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
Bereiken van variabelen
Stel in het YAML-bestand een variabele in op verschillende niveaus:
- Op basisniveau kunt u dit beschikbaar maken voor alle taken in de pijplijn.
- Op faseniveau kunt u deze alleen beschikbaar maken voor een specifieke fase.
- Op taakniveau kunt u deze alleen beschikbaar maken voor een specifieke taak.
Wanneer u boven aan een YAML een variabele definieert, is de variabele beschikbaar voor alle taken en fasen in de pijplijn en is dit een globale variabele. Globale variabelen die zijn gedefinieerd in een YAML, zijn niet zichtbaar in de gebruikersinterface voor pijplijninstellingen.
Variabelen op taakniveau overschrijven variabelen op hoofd- en faseniveau. Variabelen op faseniveau overschrijven variabelen op het hoofdniveau.
variables:
global_variable: value # this is available to all jobs
jobs:
- job: job1
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable1: value1 # this is only available in job1
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable1)
- bash: echo $JOB_VARIABLE1 # variables are available in the script environment too
- job: job2
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable2: value2 # this is only available in job2
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable2)
- bash: echo $GLOBAL_VARIABLE
De uitvoer van beide taken ziet er als volgt uit:
# job1
value
value1
value1
# job2
value
value2
value
Variabelen opgeven
In de voorgaande voorbeelden wordt het variables trefwoord gevolgd door een lijst met sleutel-waardeparen.
De sleutels zijn de namen van variabelen en de waarden zijn de variabelewaarden.
Een andere syntaxis is handig als u sjablonen wilt gebruiken voor variabelen of variabelegroepen.
Met behulp van sjablonen kunt u variabelen definiëren in het ene YAML-bestand en deze opnemen in een ander YAML-bestand.
Variabelegroepen zijn een set variabelen die u kunt gebruiken voor meerdere pipelines. Met behulp van variabelegroepen kunt u variabelen beheren en organiseren die gebruikelijk zijn voor verschillende fasen op één plaats.
Gebruik deze syntaxis voor variabelesjablonen en variabelegroepen op het hoofdniveau van een pijplijn.
In deze alternatieve syntaxis gebruikt het variables trefwoord een lijst met variabele aanduidingen.
De variabeleaanduidingen zijn name voor een reguliere variabele, group voor een variabelegroep en template voor het opnemen van een variabelesjabloon.
In het volgende voorbeeld ziet u alle drie.
variables:
# a regular variable
- name: myvariable
value: myvalue
# a variable group
- group: myvariablegroup
# a reference to a variable template
- template: myvariabletemplate.yml
Zie voor meer informatie het hergebruik van variabelen met sjablonen.
Toegang krijgen tot variabelen via de omgeving
U ziet dat variabelen ook beschikbaar worden gesteld voor scripts via omgevingsvariabelen. De syntaxis voor het gebruik van deze omgevingsvariabelen is afhankelijk van de scripttaal.
De naam is in hoofdletters en de . wordt vervangen door de _. Dit wordt automatisch ingevoegd in de procesomgeving. Hieronder volgen een aantal voorbeelden:
- Batchscript:
%VARIABLE_NAME% - PowerShell-script:
$env:VARIABLE_NAME - Bash-script:
$VARIABLE_NAME
Belangrijk
Vooraf gedefinieerde variabelen die bestandspaden bevatten, worden vertaald naar de juiste stijl (Windows-stijl C:\foo\ versus Unix-stijl /foo/) op basis van het hosttype van de agent en het shell-type. Als u bash-scripttaken uitvoert in Windows, moet u de omgevingsvariabelemethode gebruiken voor toegang tot deze variabelen in plaats van de methode van de pijplijnvariabele om ervoor te zorgen dat u over de juiste stijl van het bestandspad beschikt.
Geheime variabelen instellen
Tip
Geheime variabelen worden niet automatisch geëxporteerd als omgevingsvariabelen. Als u geheime variabelen in uw scripts wilt gebruiken, wijst u deze expliciet toe aan omgevingsvariabelen. Zie Geheime variabelen instellen voor meer informatie.
Stel geen geheime variabelen in uw YAML-bestand in. Besturingssystemen registreren vaak opdrachten voor de processen die ze uitvoeren en u wilt niet dat het logboek een geheim bevat dat u hebt doorgegeven als invoer. Gebruik de omgeving van het script of koppel de variabele binnen het variables blok om geheimen door te sturen naar uw pijplijn.
Notitie
Azure Pipelines probeert geheimen te maskeren bij het verzenden van gegevens naar pijplijnlogboeken, zodat er mogelijk extra variabelen en gegevens worden gemaskeerd in uitvoer en logboeken die niet als geheimen zijn ingesteld.
U moet geheime variabelen instellen in de gebruikersinterface voor pijplijninstellingen voor uw pijplijn. Deze variabelen behoren tot de pipeline waarin ze zijn ingesteld. U kunt ook geheime variabelen instellen in variabelegroepen.
Voer de volgende stappen uit om geheimen in te stellen in de webinterface:
- Ga naar de pagina Pipelines, selecteer de juiste pijplijn en selecteer vervolgens Edit.
- Zoek de variabelen voor deze pijplijn.
- Voeg de variabele toe of werk deze bij.
- Selecteer de optie om deze waarde geheim te houden om de variabele op een versleutelde manier op te slaan.
- Sla de pijplijn op.
Geheime variabelen worden in rust versleuteld met een 2048-bits RSA-sleutel. Geheimen zijn beschikbaar op de agent voor het gebruik in taken en scripts. Wees voorzichtig met wie toegang heeft tot het wijzigen van uw pijplijn.
Belangrijk
We spannen ons in om geheimen te verbergen in de output van Azure Pipelines, maar u moet nog steeds extra voorzorgsmaatregelen nemen. Echo geheimen nooit als uitvoer. Sommige besturingssystemen registreren opdrachtregelargumenten. Geef nooit geheimen door op de opdrachtregel. In plaats daarvan raden we u aan uw geheimen toe te wijzen aan omgevingsvariabelen.
We maskeren nooit deelreeksen van geheimen. Als 'abc123' bijvoorbeeld is ingesteld als geheim, wordt 'abc' niet gemaskeerd uit de logboeken. Dit is om te voorkomen dat geheimen te gedetailleerd worden gemaskeerd, waardoor de logboeken onleesbaar worden. Daarom mogen geheimen geen gestructureerde gegevens bevatten. Als bijvoorbeeld '{ "foo": "bar" }' is ingesteld als een geheime waarde, wordt 'bar' niet gemaskeerd uit de logboeken.
In tegenstelling tot een normale variabele worden ze niet automatisch ontsleuteld in omgevingsvariabelen voor scripts. U moet expliciet geheime variabelen toewijzen.
In het volgende voorbeeld ziet u hoe u een geheime variabele kunt toewijzen en gebruiken die wordt aangeroepen mySecret in PowerShell- en Bash-scripts. Er worden twee globale variabelen gedefinieerd.
GLOBAL_MYSECRET wordt de waarde van een geheime variabele mySecrettoegewezen en GLOBAL_MY_MAPPED_ENV_VAR wordt de waarde van een niet-geheime variabele nonSecretVariabletoegewezen. In tegenstelling tot een normale pijplijnvariabele is er geen omgevingsvariabele met de naam MYSECRET.
Met de PowerShell-taak wordt een script uitgevoerd om de variabelen af te drukken.
-
$(mySecret): Dit is een directe verwijzing naar de geheime variabele en werkt. -
$env:MYSECRET: hiermee wordt geprobeerd de geheime variabele als een omgevingsvariabele te access. Dit werkt niet omdat geheime variabelen niet automatisch worden toegewezen aan omgevingsvariabelen. -
$env:GLOBAL_MYSECRET: Dit is een poging om toegang te krijgen tot de geheime variabele via een globale variabele, wat ook niet werkt omdat geheime variabelen niet op deze manier kunnen worden toegewezen. -
$env:GLOBAL_MY_MAPPED_ENV_VAR: Hiermee opent u de niet-geheime variabele via een globale variabele, die werkt. -
$env:MY_MAPPED_ENV_VAR: Hiermee opent u de geheime variabele via een taakspecifieke omgevingsvariabele. Dit is de aanbevolen manier om geheime variabelen toe te wijzen aan omgevingsvariabelen.
variables:
GLOBAL_MYSECRET: $(mySecret) # this will not work because the secret variable needs to be mapped as env
GLOBAL_MY_MAPPED_ENV_VAR: $(nonSecretVariable) # this works because it's not a secret.
steps:
- powershell: |
Write-Host "Using an input-macro works: $(mySecret)"
Write-Host "Using the env var directly does not work: $env:MYSECRET"
Write-Host "Using a global secret var mapped in the pipeline does not work either: $env:GLOBAL_MYSECRET"
Write-Host "Using a global non-secret var mapped in the pipeline works: $env:GLOBAL_MY_MAPPED_ENV_VAR"
Write-Host "Using the mapped env var for this task works and is recommended: $env:MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
- bash: |
echo "Using an input-macro works: $(mySecret)"
echo "Using the env var directly does not work: $MYSECRET"
echo "Using a global secret var mapped in the pipeline does not work either: $GLOBAL_MYSECRET"
echo "Using a global non-secret var mapped in the pipeline works: $GLOBAL_MY_MAPPED_ENV_VAR"
echo "Using the mapped env var for this task works and is recommended: $MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
De uitvoer van beide taken in het voorgaande script ziet er als volgt uit:
Using an input-macro works: ***
Using the env var directly does not work:
Using a global secret var mapped in the pipeline does not work either:
Using a global non-secret var mapped in the pipeline works: foo
Using the mapped env var for this task works and is recommended: ***
U kunt ook geheime variabelen buiten scripts gebruiken. U kunt bijvoorbeeld geheime variabelen toewijzen aan taken met behulp van de variables definitie. In dit voorbeeld ziet u hoe u geheime variabelen gebruikt $(vmsUser) en $(vmsAdminPass) in een Azure bestandskopietaak.
variables:
VMS_USER: $(vmsUser)
VMS_PASS: $(vmsAdminPass)
pool:
vmImage: 'ubuntu-latest'
steps:
- task: AzureFileCopy@6
inputs:
SourcePath: 'my/path' # Specify the source path
azureSubscription: 'my-subscription' # Azure subscription name
Destination: 'AzureVMs' # Destination type
storage: 'my-storage' # Azure storage account name
resourceGroup: 'my-resource-group' # Resource group name
vmsAdminUserName: $(VMS_USER) # Admin username for the VM
vmsAdminPassword: $(VMS_PASS) # Admin password for the VM
CleanTargetBeforeCopy: false # Do not clean the target before copying
Referentiegeheimvariabelen in variabelegroepen
In dit voorbeeld ziet u hoe u naar een variabelegroep in uw YAML-bestand verwijst en hoe u ook variabelen toevoegt in de YAML. In het voorbeeld worden twee variabelen uit de variabelegroep gebruikt: user en token. De token variabele is geheim en is toegewezen aan de omgevingsvariabele $env:MY_MAPPED_TOKEN , zodat u ernaar kunt verwijzen in de YAML.
Met deze YAML wordt een REST-aanroep uitgevoerd om een lijst met releases op te halen en wordt het resultaat uitgevoerd.
variables:
- group: 'my-var-group' # variable group
- name: 'devopsAccount' # new variable defined in YAML
value: 'contoso'
- name: 'projectName' # new variable defined in YAML
value: 'contosoads'
steps:
- task: PowerShell@2
inputs:
targetType: 'inline'
script: |
# Encode the Personal Access Token (PAT)
# $env:USER is a normal variable in the variable group
# $env:MY_MAPPED_TOKEN is a mapped secret variable
$base64AuthInfo = [Convert]::ToBase64String([Text.Encoding]::ASCII.GetBytes(("{0}:{1}" -f $env:USER,$env:MY_MAPPED_TOKEN)))
# Get a list of releases
$uri = "https://vsrm.dev.azure.com/$(devopsAccount)/$(projectName)/_apis/release/releases?api-version=5.1"
# Invoke the REST call
$result = Invoke-RestMethod -Uri $uri -Method Get -ContentType "application/json" -Headers @{Authorization=("Basic {0}" -f $base64AuthInfo)}
# Output releases in JSON
Write-Host $result.value
env:
MY_MAPPED_TOKEN: $(token) # Maps the secret variable $(token) from my-var-group
Belangrijk
Standaard kunnen builds van pull-aanvragen van forks in GitHub-opslagplaatsen geen toegang krijgen tot geheime variabelen die zijn gekoppeld aan uw pijplijn. Zie Contributions from forks voor meer informatie.
Variabelen delen over verschillende pipelines
Als u variabelen in meerdere pipelines in uw project wilt delen, gebruikt u de webinterface. Gebruik onder Bibliotheek variabelengroepen.
Uitvoervariabelen van taken gebruiken
Sommige taken definiëren uitvoervariabelen, die u kunt gebruiken in downstreamstappen, taken en fasen. In YAML kunt u met behulp van afhankelijkheden toegang krijgen tot variabelen over taken en fasen heen.
Wanneer u naar matrixtaken in downstreamtaken verwijst, gebruikt u een andere syntaxis. Zie Een uitvoervariabele voor meerdere taken instellen. U moet ook een andere syntaxis gebruiken voor variabelen in implementatietaken. Zie Ondersteuning voor uitvoervariabelen in implementatietaken.
- Als u wilt verwijzen naar een variabele van een andere taak binnen dezelfde taak, gebruikt u
TASK.VARIABLE. - Als u wilt verwijzen naar een variabele van een taak uit een andere taak, gebruikt u
dependencies.JOB.outputs['TASK.VARIABLE'].
Notitie
Standaard is elke fase in een pijplijn afhankelijk van de fase vlak voordat deze zich in het YAML-bestand bevindt. Als u wilt verwijzen naar een fase die zich niet direct vóór de huidige fase bevindt, kunt u deze automatische standaardinstelling overschrijven door een dependsOn sectie toe te voegen aan de fase.
Notitie
In de volgende voorbeelden wordt standaard pijplijnsyntaxis gebruikt. Als u implementatie-pipelines gebruikt, verschillen zowel de syntaxis van de variabele als de voorwaardelijke variabele. Zie Implementatietaken voor meer informatie over de specifieke syntaxis die u wilt gebruiken.
Voor deze voorbeelden wordt ervan uitgegaan dat u een taak hebt met de naam MyTask, waarmee een uitvoervariabele met de naam MyVarwordt ingesteld.
Meer informatie over de syntaxis in Expressies - Afhankelijkheden.
Uitvoer in dezelfde taak gebruiken
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- script: echo $(ProduceVar.MyVar) # this step uses the output variable
Uitvoer in een andere taak gebruiken
jobs:
- job: A
steps:
# assume that MyTask generates an output variable called "MyVar"
# (you would learn that from the task's documentation)
- task: MyTask@1
name: ProduceVar # because we're going to depend on it, we need to name the step
- job: B
dependsOn: A
variables:
# map the output variable from A into this job
varFromA: $[ dependencies.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
Uitvoer in een andere fase gebruiken
Als u de uitvoer uit een andere fase wilt gebruiken, gebruikt u de indeling stageDependencies.STAGE.JOB.outputs['TASK.VARIABLE'] om te verwijzen naar variabelen. Op faseniveau, maar niet op taakniveau, kunt u deze variabelen in voorwaarden gebruiken.
Uitvoervariabelen zijn alleen beschikbaar in de volgende downstreamfase. Als meerdere fasen dezelfde uitvoervariabele gebruiken, gebruikt u de dependsOn voorwaarde.
stages:
- stage: One
jobs:
- job: A
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- stage: Two
dependsOn:
- One
jobs:
- job: B
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
- stage: Three
dependsOn:
- One
- Two
jobs:
- job: C
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
U kunt ook variabelen tussen fasen doorgeven met behulp van een bestandsinvoer. Daarvoor moet u variabelen definiëren in de tweede fase op taakniveau en vervolgens de variabelen doorgeven als env: input.
## script-a.sh
echo "##vso[task.setvariable variable=sauce;isOutput=true]crushed tomatoes"
## script-b.sh
echo 'Hello file version'
echo $skipMe
echo $StageSauce
## azure-pipelines.yml
stages:
- stage: one
jobs:
- job: A
steps:
- task: Bash@3
inputs:
filePath: 'script-a.sh'
name: setvar
- bash: |
echo "##vso[task.setvariable variable=skipsubsequent;isOutput=true]true"
name: skipstep
- stage: two
jobs:
- job: B
variables:
- name: StageSauce
value: $[ stageDependencies.one.A.outputs['setvar.sauce'] ]
- name: skipMe
value: $[ stageDependencies.one.A.outputs['skipstep.skipsubsequent'] ]
steps:
- task: Bash@3
inputs:
filePath: 'script-b.sh'
name: fileversion
env:
StageSauce: $(StageSauce) # predefined in variables section
skipMe: $(skipMe) # predefined in variables section
- task: Bash@3
inputs:
targetType: 'inline'
script: |
echo 'Hello inline version'
echo $(skipMe)
echo $(StageSauce)
De uitvoer van stappen in de eerder genoemde pijplijn ziet er als volgt uit:
Hello inline version
true
crushed tomatoes
Variabelen weergeven
Geef alle variabelen in uw pijplijn weer met behulp van de opdracht az pipelines variable list. Zie Aan de slag met Azure DevOps CLI om te beginnen.
az pipelines variable list [--org]
[--pipeline-id]
[--pipeline-name]
[--project]
Parameters
-
org: url van Azure DevOps-organisatie. Configureer de standaardorganisatie met behulp van
az devops configure -d organization=ORG_URL. Vereist indien niet geconfigureerd als standaard of opgehaald met behulp vangit config. Voorbeeld:--org https://dev.azure.com/MyOrganizationName/. - pijplijn-id: vereist als er geen pijplijnnaam is opgegeven. Id van de pijplijn.
- pijplijnnaam: vereist als er geen pijplijn-id is opgegeven, maar genegeerd als er een pijplijn-id wordt opgegeven. Naam van de pijplijn.
-
project: naam of id van de project. Configureer de standaard-project met behulp van
az devops configure -d project=NAME_OR_ID. Vereist indien niet geconfigureerd als standaard of opgehaald met behulp vangit config.
Voorbeeld
Met de volgende opdracht worden alle variabelen in de pijplijn weergegeven met id 12 en wordt het resultaat in tabelindeling weergegeven.
az pipelines variable list --pipeline-id 12 --output table
Name Allow Override Is Secret Value
------------- ---------------- ----------- ------------
MyVariable False False platform
NextVariable False True platform
Configuration False False config.debug
Variabelen instellen in scripts
Scripts kunnen variabelen definiëren die latere stappen in de pijplijn verbruiken. Alle variabelen die door deze methode worden ingesteld, worden behandeld als tekenreeksen. Als u een variabele wilt instellen vanuit een script, gebruikt u een opdrachtsyntaxis en drukt u af op stdout.
Een variabele met taakbereik instellen op basis van een script
Als u een variabele vanuit een script wilt instellen, gebruikt u de task.setvariableopdracht voor logboekregistratie. Met deze opdracht worden de omgevingsvariabelen bijgewerkt voor volgende taken. Vervolgopdrachten kunnen de nieuwe variabele toestaan met behulp van macrosyntaxis en taken als omgevingsvariabelen gebruiken.
Wanneer u deze waarde instelt issecret op true, wordt de waarde van de variabele opgeslagen als geheim en gemaskeerd uit het logboek. Zie logboekregistratieopdrachten voor meer informatie over geheime variabelen.
steps:
# Create a variable
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes" # remember to use double quotes
# Use the variable
# "$(sauce)" is replaced by the contents of the `sauce` variable by Azure Pipelines
# before handing the body of the script to the shell.
- bash: |
echo my pipeline variable is $(sauce)
Volgende stappen bevatten ook de pijplijnvariabele die aan hun omgeving is toegevoegd. U kunt de variabele niet gebruiken in de stap die deze heeft gedefinieerd.
steps:
# Create a variable
# Note that this does not update the environment of the current script.
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes"
# An environment variable called `SAUCE` has been added to all downstream steps
- bash: |
echo "my environment variable is $SAUCE"
- pwsh: |
Write-Host "my environment variable is $env:SAUCE"
De uitvoer van de vorige pijplijn.
my environment variable is crushed tomatoes
my environment variable is crushed tomatoes
Een uitvoervariabele met meerdere taken instellen
Als u een variabele beschikbaar wilt maken voor toekomstige taken, moet u deze markeren als een uitvoervariabele met behulp van isOutput=true. Vervolgens kunt u deze toewijzen aan toekomstige taken met behulp van de $[] syntaxis en de naam van de stap waarmee de variabele is ingesteld. Uitvoervariabelen met meerdere taken werken alleen voor taken in dezelfde fase.
Als u variabelen wilt doorgeven aan taken in verschillende fasen, gebruikt u de syntaxis van faseafhankelijkheden .
Notitie
Standaard is elke fase in een pijplijn afhankelijk van de fase vlak voordat deze zich in het YAML-bestand bevindt. Daarom kan elke fase uitvoervariabelen uit de vorige fase gebruiken. Om toegang te krijgen tot verdere fasen, moet u de afhankelijkheidsgrafiek wijzigen. Bijvoorbeeld, als fase 3 een variabele van fase 1 vereist, moet u een expliciete afhankelijkheid voor fase 1 aangeven.
Wanneer u een uitvoervariabele met meerdere taken maakt, moet u de expressie toewijzen aan een variabele. In deze YAML wordt $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] toegewezen aan de variabele $(myVarFromJobA).
jobs:
# Set an output variable from job A
- job: A
pool:
vmImage: 'windows-latest'
steps:
- powershell: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable into job B
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] # map in the variable
# remember, expressions require single quotes
steps:
- script: echo $(myVarFromJobA)
name: echovar
De uitvoer van de vorige pijplijn.
this is the value
this is the value
Als u een variabele van de ene fase naar de andere instelt, gebruikt u stageDependencies.
stages:
- stage: A
jobs:
- job: A1
steps:
- bash: echo "##vso[task.setvariable variable=myStageOutputVar;isOutput=true]this is a stage output var"
name: printvar
- stage: B
dependsOn: A
variables:
myVarfromStageA: $[ stageDependencies.A.A1.outputs['printvar.myStageOutputVar'] ]
jobs:
- job: B1
steps:
- script: echo $(myVarfromStageA)
Als u een variabele instelt op basis van een matrix of slice, moet u naar de variabele verwijzen wanneer u er vanuit een downstreamtaak toegang toe krijgt. U moet het volgende opnemen:
- De naam van de taak.
- De stap.
jobs:
# Set an output variable from a job with a matrix
- job: A
pool:
vmImage: 'ubuntu-latest'
strategy:
maxParallel: 2
matrix:
debugJob:
configuration: debug
platform: x64
releaseJob:
configuration: release
platform: x64
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the $(configuration) value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the debug job
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobADebug: $[ dependencies.A.outputs['debugJob.setvarStep.myOutputVar'] ]
steps:
- script: echo $(myVarFromJobADebug)
name: echovar
jobs:
# Set an output variable from a job with slicing
- job: A
pool:
vmImage: 'ubuntu-latest'
parallel: 2 # Two slices
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the slice $(system.jobPositionInPhase) value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobsA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ]
steps:
- script: "echo $(myVarFromJobsA)"
name: echovar
Zorg ervoor dat u de taaknaam voorvoegt voor de uitvoervariabelen van een implementatietaak . In dit geval is Ade taaknaam:
jobs:
# Set an output variable from a deployment
- deployment: A
pool:
vmImage: 'ubuntu-latest'
environment: staging
strategy:
runOnce:
deploy:
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the deployment variable value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromDeploymentJob: $[ dependencies.A.outputs['A.setvarStep.myOutputVar'] ]
steps:
- bash: "echo $(myVarFromDeploymentJob)"
name: echovar
 Stel de variabelen
Stel de variabelen  Stel de variabelen
Stel de variabelen  Stel de variabelen
Stel de variabelen Variabelen instellen met behulp van expressies
U kunt een variabele instellen met behulp van een expressie. U hebt al één geval van deze benadering aangetroffen wanneer u een variabele instelt op de uitvoer van een andere variabele uit een vorige taak.
- job: B
dependsOn: A
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ] # remember to use single quotes
U kunt een van de ondersteunde expressies gebruiken voor het instellen van een variabele. Hier volgt een voorbeeld van het instellen van een variabele om te fungeren als een teller die begint bij 100, wordt verhoogd met 1 voor elke uitvoering en wordt elke dag opnieuw ingesteld op 100.
jobs:
- job:
variables:
a: $[counter(format('{0:yyyyMMdd}', pipeline.startTime), 100)]
steps:
- bash: echo $(a)
Voor meer informatie over tellers, afhankelijkheden en andere expressies, zie expressies.
Instelbare variabelen configureren voor stappen
U kunt binnen een stap definiëren settableVariables of opgeven dat er geen variabelen kunnen worden ingesteld.
In dit voorbeeld kan het script geen variabele instellen.
steps:
- script: echo This is a step
target:
settableVariables: none
In het volgende voorbeeld kan het script de variabele sauce instellen, maar kan de variabele secretSauceniet worden ingesteld. U ziet een waarschuwing op de uitvoeringspagina van de pijplijn.

steps:
- bash: |
echo "##vso[task.setvariable variable=Sauce;]crushed tomatoes"
echo "##vso[task.setvariable variable=secretSauce;]crushed tomatoes with garlic"
target:
settableVariables:
- sauce
name: SetVars
- bash:
echo "Sauce is $(sauce)"
echo "secretSauce is $(secretSauce)"
name: OutputVars
Toestaan tijdens wachtrijtijd
Als een variabele wordt weergegeven in het variables blok van een YAML-bestand, is de waarde ervan vast en kunnen gebruikers deze niet overschrijven tijdens de wachtrij. Definieer uw variabelen in een YAML-bestand, maar er zijn momenten waarop deze benadering niet zinvol is. U kunt bijvoorbeeld een geheime variabele definiëren en deze niet beschikbaar maken in uw YAML. Of mogelijk moet u handmatig een variabelewaarde instellen tijdens de pijplijnuitvoering.
U hebt twee opties voor het definiëren van waarden voor wachtrijtijd. U kunt een variabele definiëren in de gebruikersinterface en de optie selecteren om gebruikers deze waarde te laten overschrijven bij het uitvoeren van deze pijplijn of u kunt in plaats daarvan runtimeparameters gebruiken. Als uw variabele geen geheim is, kunt u het beste runtimeparameters gebruiken.
Als u een variabele tijdens de wachtrij wilt instellen, voegt u een nieuwe variabele toe in uw pijplijn en selecteert u de overschrijfoptie. Alleen gebruikers met de machtiging configuratie van de wachtrij bewerken kunnen de waarde van een variabele wijzigen.
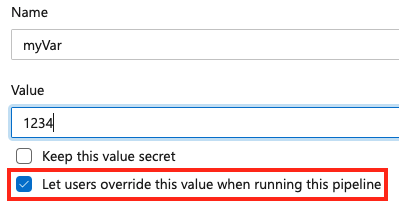
Als u wilt toestaan dat een variabele tijdens de wachtrij wordt ingesteld, moet u ervoor zorgen dat de variabele niet ook wordt weergegeven in het variables blok van een pijplijn of taak. Als u een variabele definieert in zowel het variabelenblok van een YAML als in de gebruikersinterface, heeft de waarde in de YAML prioriteit.
Voor extra beveiliging gebruikt u een vooraf gedefinieerde set waarden voor settable in wachtrijtijdvariabelen en veilige typen, zoals booleaanse waarden en gehele getallen. Gebruik voor tekenreeksen een vooraf gedefinieerde set waarden.

Uitbreiding van variabelen
Wanneer u een variabele met dezelfde naam in meerdere bereiken instelt, is de volgende prioriteit van toepassing (hoogste prioriteit eerst):
- Variabele voor het niveau van de taak ingesteld in het YAML-bestand
- In het YAML-bestand ingestelde variabele op faseniveau
- In het YAML-bestand ingestelde variabele op pijplijnniveau
- Op wachtrijtijd ingestelde variabele
- In de gebruikersinterface voor pijplijninstellingen ingestelde pijplijnvariabele
In het volgende voorbeeld wordt dezelfde variabele a ingesteld op pijplijnniveau en taakniveau in het YAML-bestand. Deze wordt ook ingesteld in een variabelegroep Gen als een variabele in de gebruikersinterface voor pijplijninstellingen.
variables:
a: 'pipeline yaml'
stages:
- stage: one
displayName: one
variables:
- name: a
value: 'stage yaml'
jobs:
- job: A
variables:
- name: a
value: 'job yaml'
steps:
- bash: echo $(a) # This will be 'job yaml'
Wanneer u een variabele met dezelfde naam in hetzelfde bereik instelt, heeft de waarde van de laatste set voorrang.
stages:
- stage: one
displayName: Stage One
variables:
- name: a
value: alpha
- name: a
value: beta
jobs:
- job: I
displayName: Job I
variables:
- name: b
value: uno
- name: b
value: dos
steps:
- script: echo $(a) #outputs beta
- script: echo $(b) #outputs dos
Notitie
Wanneer u een variabele instelt in het YAML-bestand, definieer deze dan niet als instelbaar tijdens de wachtrij in de webeditor. U kunt momenteel geen variabelen wijzigen die zijn ingesteld in het YAML-bestand tijdens de wachtrij. Als u een variabele in de wachtrij wilt instellen, moet u deze niet instellen in het YAML-bestand.
Variabelen worden eenmaal uitgebreid wanneer de uitvoering wordt gestart en opnieuw aan het begin van elke stap. Voorbeeld:
jobs:
- job: A
variables:
a: 10
steps:
- bash: |
echo $(a) # This will be 10
echo '##vso[task.setvariable variable=a]20'
echo $(a) # This will also be 10, since the expansion of $(a) happens before the step
- bash: echo $(a) # This will be 20, since the variables are expanded just before the step
Het voorgaande voorbeeld bevat twee stappen. De uitbreiding $(a) vindt één keer plaats aan het begin van de taak en eenmaal aan het begin van elk van de twee stappen.
Omdat variabelen aan het begin van een taak worden uitgebreid, kunt u deze niet gebruiken in een strategie. In het volgende voorbeeld kunt u de variabele a niet gebruiken om de taakmatrix uit te vouwen, omdat de variabele alleen beschikbaar is aan het begin van elke uitgevouwen taak.
jobs:
- job: A
variables:
a: 10
strategy:
matrix:
x:
some_variable: $(a) # This does not work
Als de variabele een uitvoervariabele a van een vorige taak is, kunt u deze in een toekomstige taak gebruiken.
- job: A
steps:
- powershell: echo "##vso[task.setvariable variable=a;isOutput=true]10"
name: a_step
# Map the variable into job B
- job: B
dependsOn: A
variables:
some_variable: $[ dependencies.A.outputs['a_step.a'] ]
Recursieve uitbreiding
Op de agent worden variabelen waarnaar wordt verwezen met behulp van $( ) syntaxis recursief uitgevouwen.
Voorbeeld:
variables:
myInner: someValue
myOuter: $(myInner)
steps:
- script: echo $(myOuter) # prints "someValue"
displayName: Variable is $(myOuter) # display name is "Variable is someValue"