Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Gegevensgeschiedenis is een integratiefunctie van Azure Digital Twins. Hiermee kunt u een Azure Digital Twins-exemplaar verbinden met een Azure Data Explorer-cluster , zodat grafiekupdates automatisch worden historiseerd naar Azure Data Explorer. Deze als historisch opgeslagen updates omvatten "twin"-eigenschapsupdates, "twin"-levenscyclusgebeurtenissen en levenscyclusgebeurtenissen voor relaties.
Zodra grafiekupdates zijn historiseerd naar Azure Data Explorer, kunt u gezamenlijke query's uitvoeren met behulp van de Azure Digital Twins-invoegtoepassing voor Azure Data Explorer om redeneren over digitale dubbels, hun relaties en tijdreeksgegevens. Dit kan worden gebruikt om terug te kijken naar wat de status van de grafiek was of om inzicht te krijgen in het gedrag van gemodelleerde omgevingen. U kunt deze query's ook gebruiken om operationele dashboards te stimuleren, 2D- en 3D-webtoepassingen te verrijken en meeslepende augmented/mixed reality-ervaringen te stimuleren om de huidige en historische status van assets, processen en personen die zijn gemodelleerd in Azure Digital Twins, over te brengen.
Bekijk de volgende IoT-showvideo voor meer informatie over gegevensgeschiedenis, inclusief een korte demo:
Berichten die door de gegevensgeschiedenis worden verzonden, worden gemeten onder de dimensie Berichtprijzen.
Vereisten: Bronnen en toestemmingen
Voor gegevensgeschiedenis zijn de volgende resources vereist:
- Azure Digital Twins-exemplaar, waarbij een door het systeem toegewezen beheerde identiteit is ingeschakeld.
- Event Hubs-naamruimte met een Event Hub.
- Azure Data Explorer-cluster met een database. Voor het cluster moet openbare netwerktoegang zijn ingeschakeld.
Deze resources zijn verbonden met de volgende stroom:
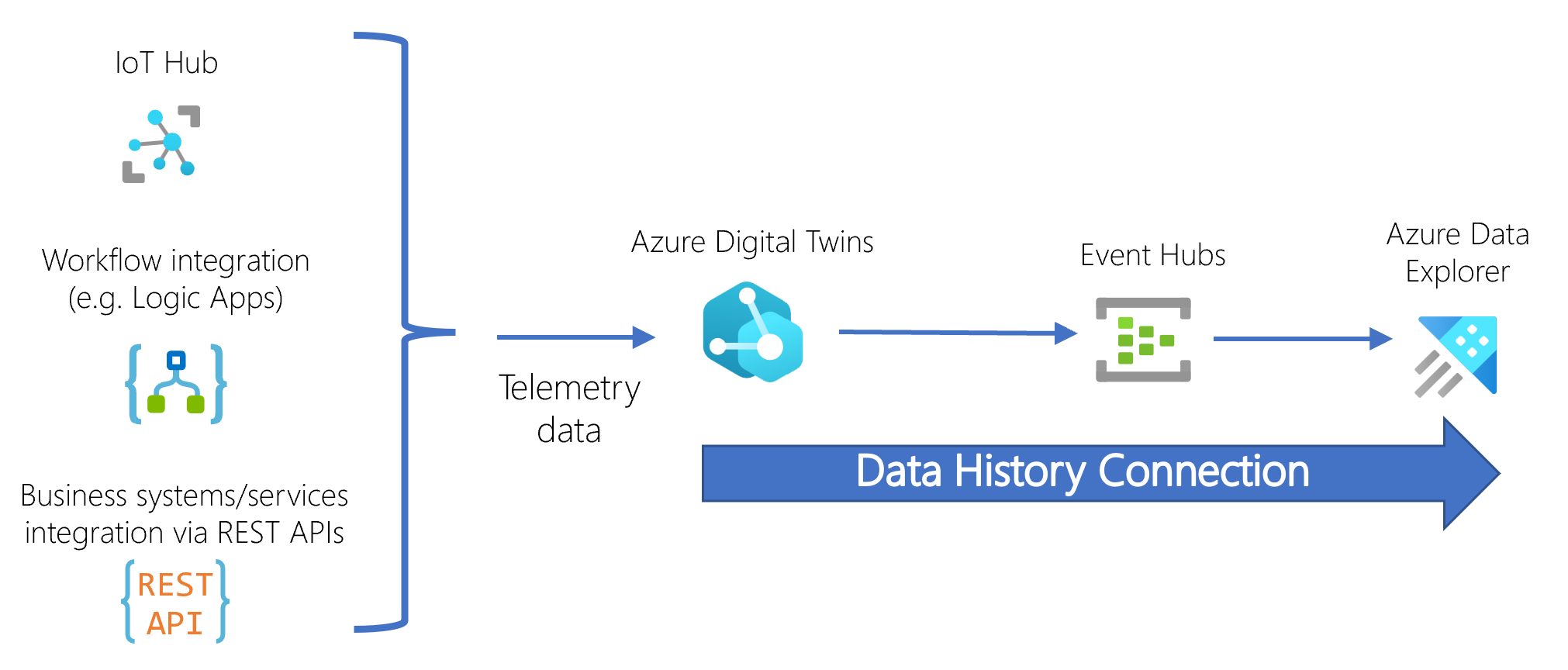
Wanneer de digitale dubbelgrafiek wordt bijgewerkt, wordt de informatie via de Event Hub doorgegeven aan het Azure Data Explorer-doelcluster, waarbij Azure Data Explorer de gegevens opslaat als een tijdstempelrecord in de bijbehorende tabel.
Wanneer u met gegevensgeschiedenis werkt, is het raadzaam om de versie 2023-01-31 of hoger van de API's te gebruiken. Met versie 2022-05-31 kunnen alleen tweelingeigenschappen (niet de levenscyclus van tweelingen of levenscyclusgebeurtenissen van relaties) worden gearchiveerd. Met eerdere versies is de gegevensgeschiedenis niet beschikbaar.
Vereiste toestemmingen
Als u een gegevensgeschiedenisverbinding wilt instellen, moet uw Azure Digital Twins-exemplaar over de volgende machtigingen beschikken om toegang te krijgen tot de Event Hubs- en Azure Data Explorer-resources. Met deze rollen kan Azure Digital Twins namens u de Event Hub en de Azure Data Explorer-database configureren (bijvoorbeeld het maken van een tabel in de database). Deze machtigingen kunnen eventueel worden verwijderd nadat de gegevensgeschiedenis is ingesteld.
- Event Hubs-resource: Azure Event Hubs-gegevenseigenaar
- Azure Data Explorer-cluster: Inzender (beperkt tot het hele cluster of de specifieke database)
- Toewijzing van Azure Data Explorer-database-principal: Beheerder (met betrekking tot de database die wordt gebruikt)
Later moet uw Azure Digital Twins-exemplaar de volgende machtiging hebben voor de Event Hubs-resource terwijl de gegevensgeschiedenis wordt gebruikt: Azure Event Hubs Data Sender (u kunt er ook voor kiezen om Azure Event Hubs Data Owner te behouden vanuit de installatie van de gegevensgeschiedenis).
Deze machtigingen kunnen worden toegewezen met behulp van de Azure CLI of Azure Portal.
Als u de netwerktoegang wilt beperken tot de resources die betrokken zijn bij de gegevensgeschiedenis (uw Azure Digital Twins-exemplaar, Event Hub of Azure Data Explorer-cluster), moet u deze beperkingen instellen nadat u de gegevensgeschiedenisverbinding hebt ingesteld. Zie Netwerktoegang tot gegevensgeschiedenisresources beperken voor meer informatie over dit proces.
Gegevensgeschiedenisverbinding maken en beheren
Deze sectie bevat informatie voor het maken, bijwerken en verwijderen van een gegevensgeschiedenisverbinding.
Een gegevensgeschiedenisverbinding maken
Zodra alle resources en machtigingen zijn ingesteld, kunt u de Azure CLI, Azure Portal of de Azure Digital Twins SDK gebruiken om de gegevensgeschiedenisverbinding tussen deze resources te maken. De CLI-opdrachtenset is az dt data-history.
Met de opdracht wordt altijd een tabel gemaakt voor gebeurtenissen van historized twin-eigenschappen, die de standaardnaam of een aangepaste naam kunnen gebruiken die u opgeeft. Verwijderingen van dubbele eigenschappen kunnen eventueel worden opgenomen in deze tabel. U kunt ook tabelnamen opgeven voor de levenscyclusgebeurtenissen van relaties en tweelingen, en de opdracht maakt tabellen met deze namen om deze gebeurtenistypen te registreren.
Zie Een gegevensgeschiedenisverbinding maken voor stapsgewijze instructies voor het instellen van een gegevensgeschiedenisverbinding.
Geschiedenis van meerdere Azure Digital Twins-exemplaren
Als u wilt, kunt u meerdere Azure Digital Twins-exemplaren hebben die updates historiseren voor hetzelfde Azure Data Explorer-cluster.
Elk Azure Digital Twins-exemplaar heeft een eigen gegevensgeschiedenisverbinding die gericht is op hetzelfde Azure Data Explorer-cluster. In het cluster kunnen instanties hun twin data verzenden naar één van beide...
- een afzonderlijke set tabellen in het Azure Data Explorer-cluster.
-
dezelfde set tabellen in het Azure Data Explorer-cluster. Hiervoor geeft u dezelfde Azure Data Explorer-tabelnamen op tijdens het maken van de gegevensgeschiedenisverbindingen. In de schema's van de gegevensgeschiedenistabel bevat de
ServiceIdkolom in elke tabel de URL van het Azure Digital Twins-bronexemplaar, zodat u dit veld kunt gebruiken om te achterhalen welke Azure Digital Twins-instantie elk record heeft uitgezonden in gedeelde tabellen.
Een verbinding met uitsluitend eigenschappen voor datahistorie bijwerken
Vóór februari 2023 werd de gegevensgeschiedenisfunctie alleen bijgehouden voor updates van twin-eigenschappen. Als u vanaf dat moment een gegevensgeschiedenisverbinding met alleen-eigenschappen hebt, kunt u deze bijwerken om alle grafiekupdates te historiseren naar Azure Data Explorer (inclusief eigenschappen van tweelingen, levenscyclusgebeurtenissen van tweelingen en levenscyclusgebeurtenissen van relaties).
Hiervoor is het nodig om nieuwe tabellen te maken in uw Azure Data Explorer-cluster voor de nieuwe typen gehistoriseerde updates (tweeling levenscyclusgebeurtenissen en relatie levenscyclusgebeurtenissen). Voor gebeurtenissen van dubbele eigenschappen kunt u bepalen of u wilt dat de nieuwe verbinding dezelfde tabel van de oorspronkelijke gegevensgeschiedenisverbinding blijft gebruiken om updates van de eigenschappen van dubbels in de toekomst op te slaan, of als u wilt dat de nieuwe verbinding een volledig nieuwe set tabellen gebruikt. Volg vervolgens de onderstaande instructies voor uw voorkeur.
Als u de bestaande tabel wilt blijven gebruiken voor updates van tweelingeigenschappen: Gebruik de instructies in Een gegevensgeschiedenisverbinding maken om een nieuwe gegevensgeschiedenisverbinding te maken met de nieuwe mogelijkheden. De naam van de verbinding met de gegevensgeschiedenis kan hetzelfde zijn als de oorspronkelijke naam of een andere naam. Gebruik de parameteropties om nieuwe namen op te geven voor de twee nieuwe gebeurtenistypetabellen en om de oorspronkelijke tabelnaam door te geven voor de tabel met updates van de tweelingeigenschap. De nieuwe verbinding zal de oude overschrijven en blijft de oorspronkelijke tabel gebruiken voor toekomstige updates van gehistoriseerde tweepolige eigenschappen.
Als u alle nieuwe tabellen wilt gebruiken: Verwijder eerst de oorspronkelijke gegevensgeschiedenisverbinding. Gebruik vervolgens de instructies in Een gegevensgeschiedenisverbinding maken om een nieuwe gegevensgeschiedenisverbinding te maken met de nieuwe mogelijkheden. De naam van de verbinding met de gegevensgeschiedenis kan hetzelfde zijn als de oorspronkelijke naam of een andere naam. Gebruik de parameteropties om nieuwe namen op te geven voor alle drie de gebeurtenistypetabellen.
Een gegevensgeschiedenisverbinding verwijderen
U kunt de Azure CLI, Azure Portal of Azure Digital Twins-API's en SDK's gebruiken om een gegevensgeschiedenisverbinding te verwijderen. De CLI-opdracht is az dt data-history connection delete.
Als u een verbinding verwijdert, kunt u ook resources opschonen die zijn gekoppeld aan de verbinding met de gegevensgeschiedenis (voor de CLI-opdracht is de optionele parameter die u wilt toevoegen --clean true). Als u deze optie gebruikt, verwijdert de opdracht de resources in Azure Data Explorer die worden gebruikt om uw cluster te koppelen aan uw Event Hub, inclusief gegevensverbindingen voor de database en de opnametoewijzingen die bij uw tabel horen. Met de optie Resources opschonen worden de werkelijke Event Hub en het Azure Data Explorer-cluster dat wordt gebruikt voor de verbinding met de gegevensgeschiedenis niet verwijderd.
Het opschonen is een best effort-poging en vereist dat het account waarop de opdracht wordt uitgevoerd, machtigingen voor verwijderen heeft voor deze resources.
Notitie
Als u meerdere gegevensgeschiedenisverbindingen hebt die hetzelfde Event Hub- of Azure Data Explorer-cluster delen, kan het verwijderen van een van deze verbindingen uw andere gegevensgeschiedenisverbindingen verstoren die afhankelijk zijn van deze resources.
Gegevenstypen en schema's
Gegevensgeschiedenis historiseert drie soorten gebeurtenissen van uw Azure Digital Twins-exemplaar in Azure Data Explorer: levenscyclusgebeurtenissen van relaties, levenscyclusgebeurtenissen van dubbels en updates van dubbele eigenschappen (die eventueel verwijderingen van dubbele eigenschappen kunnen bevatten). Elk van deze gebeurtenistypen wordt opgeslagen in een eigen tabel in de Azure Data Explorer-database, wat betekent dat de gegevensgeschiedenis drie tabellen in totaal bewaart. U kunt aangepaste namen voor de tabellen opgeven wanneer u de verbinding met de gegevensgeschiedenis instelt.
In de rest van deze sectie worden de drie Azure Data Explorer-tabellen gedetailleerd beschreven, inclusief het gegevensschema voor elke tabel.
Updates van tweeleigendom
De Azure Data Explorer-tabel voor updates van dubbeleigenschappen heeft een standaardnaam van AdtPropertyEvents. U kunt de standaardnaam laten staan wanneer u de verbinding maakt of een aangepaste tabelnaam opgeven.
De tijdreeksgegevens voor het bijwerken van tweelingeigenschappen worden opgeslagen volgens het volgende schema:
| Kenmerk | Typ | Beschrijving |
|---|---|---|
TimeStamp |
Datum/tijd | De datum/tijd waarop het bericht over het bijwerken van de eigenschap is verwerkt door Azure Digital Twins. Dit veld wordt ingesteld door het systeem en kan niet worden geschreven door gebruikers. |
SourceTimeStamp |
Datum/tijd | Een optionele, beschrijfbare eigenschap die de tijdstempel aangeeft toen de eigenschapsupdate werd waargenomen in de echte wereld. Deze eigenschap kan alleen worden geschreven met de versie 2022-05-31 van de Azure Digital Twins-API's/SDK's en de waarde moet voldoen aan de iso 8601-datum- en tijdnotatie. Zie De brontijd van een eigenschap bijwerken voor meer informatie over het bijwerken van deze eigenschap. |
ServiceId |
Touwtje | De service-instantie-id van de Azure IoT-service die de record registreert |
Id |
Touwtje | De tweeling-id |
ModelId |
Touwtje | De DTDL-model-id (DTMI) |
Key |
Touwtje | De naam van de bijgewerkte eigenschap |
Value |
Dynamisch | De waarde van de bijgewerkte eigenschap |
RelationshipId |
Touwtje | Wanneer een eigenschap die is gedefinieerd voor een relatie (in tegenstelling tot tweelingen of apparaten) wordt bijgewerkt, wordt dit veld gevuld met de id van de relatie. Wanneer een tweelingeigenschap wordt bijgewerkt, is dit veld leeg. |
RelationshipTarget |
Touwtje | Wanneer een eigenschap die is gedefinieerd voor een relatie (in tegenstelling tot tweelingen of apparaten) wordt bijgewerkt, wordt dit veld gevuld met de dubbel-id van de dubbel waarop de relatie is gericht. Wanneer een tweelingeigenschap wordt bijgewerkt, is dit veld leeg. |
Action |
Touwtje | Deze kolom bestaat alleen als u ervoor kiest om het historiseren van verwijderingsgebeurtenissen van eigenschappen in te schakelen. Als dit het geval is, bevat deze kolom het type evenement voor tweelingeigenschappen (bewerken of verwijderen). |
Hieronder ziet u een voorbeeldtabel met updates van dubbeleigenschappen die zijn opgeslagen in Azure Data Explorer.
TimeStamp |
SourceTimeStamp |
ServiceId |
Id |
ModelId |
Key |
Value |
RelationshipTarget |
RelationshipID |
|---|---|---|---|---|---|---|---|---|
| 2022-12-15 20:23:29.8697482 | 2022-12-15 20:22:14.3854859 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurisatieMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Uitvoer | 130 | ||
| 2022-12-15 20:23:39.3235925 | 2022-12-15 20:22:26.5837559 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurisatieMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Uitvoer | 140 | ||
| 2022-12-15 20:23:47.078367 | 2022-12-15 20:22:34.9375957 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurisatieMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Uitvoer | 130 | ||
| 2022-12-15 20:23:57.3794198 | 2022-12-15 20:22:50.1028562 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurisatieMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Uitvoer | 123 |
Eigenschappen weergeven met meerdere velden
Mogelijk moet u een eigenschap met meerdere velden opslaan. Deze eigenschappen worden weergegeven met een JSON-object in het Value kenmerk van het schema.
Als u bijvoorbeeld een eigenschap vertegenwoordigt met drie velden voor roll, pitch en yaw, worden in de gegevensgeschiedenis het volgende JSON-object opgeslagen als : Value. {"roll": 20, "pitch": 15, "yaw": 45}
Levenscyclusgebeurtenissen van tweelingen
De Azure Data Explorer-tabel voor levenscyclusgebeurtenissen van tweelingen heeft een aangepaste naam die u opgeeft bij het maken van de gegevenshistorieverbinding.
De tijdreeksgegevens voor levenscyclus-gebeurtenissen van tweelingen worden opgeslagen met het volgende schema.
| Kenmerk | Typ | Beschrijving |
|---|---|---|
TwinId |
Touwtje | De tweeling-id |
Action |
Touwtje | Het type levenscyclusgebeurtenis van tweeling (aanmaken of verwijderen) |
TimeStamp |
Datum/tijd | De datum/tijd waarop de tweeling levenscyclusgebeurtenis is verwerkt door Azure Digital Twins. Dit veld wordt ingesteld door het systeem en kan niet worden geschreven door gebruikers. |
ServiceId |
Touwtje | De service-instantie-id van de Azure IoT-service die de record registreert |
ModelId |
Touwtje | De DTDL-model-id (DTMI) |
Hieronder ziet u een voorbeeldtabel met lifecycle-updates van gekoppelde eenheden die zijn opgeslagen in Azure Data Explorer.
TwinId |
Action |
TimeStamp |
ServiceId |
ModelId |
|---|---|---|---|---|
| PasteurisatieMachine_A01 | Maak | 2022-12-15 07:14:12.4160 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
| PasteurizationMachine_A02 | Maak | 2022-12-15 07:14:12.4210 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
| SaltMachine_C0 | Maak | 2022-12-15 07:14:12.5480 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:SaltMachine;1 |
| PasteurizationMachine_A02 | Verwijderen | 2022-12-15 07:15:49.6050 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
Levenscyclus-gebeurtenissen voor relaties
De Azure Data Explorer-tabel voor levenscyclusgebeurtenissen van relaties heeft een aangepaste naam die u opgeeft bij het maken van de gegevensgeschiedenisverbinding.
De tijdreeksgegevens voor levenscyclus-gebeurtenissen voor relaties worden opgeslagen met het volgende schema:
| Kenmerk | Typ | Beschrijving |
|---|---|---|
RelationshipId |
Touwtje | De relatie-id. Dit veld wordt ingesteld door het systeem en kan niet worden geschreven door gebruikers. |
Name |
Touwtje | De naam van de relatie |
Action |
Het type evenement in de levenscyclus van een relatie (aanmaken of verwijderen) | |
TimeStamp |
Datum/tijd | De datum/tijd waarop de levenscyclusgebeurtenis van de relatie is verwerkt door Azure Digital Twins. Dit veld wordt ingesteld door het systeem en kan niet worden geschreven door gebruikers. |
ServiceId |
De service-instantie-id van de Azure IoT-service die de record registreert | |
Source |
De id van de brondubbel. Dit is de id van de tweeling waar de relatie vandaan komt. | |
Target |
De id van de doeldubbel. Dit is de id van de tweeling waar de relatie binnenkomt. |
Hieronder ziet u een voorbeeldtabel met updates voor de levenscyclus van relaties die zijn opgeslagen in Azure Data Explorer.
RelationshipId |
Name |
Action |
TimeStamp |
ServiceId |
Source |
Target |
|---|---|---|---|---|---|---|
| PasteurisatieMachine_A01_voedt_Relatie0 | nieuwsfeeds | Maak | 2022-12-15 07:16:12.7120 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurisatieMachine_A01 | SaltMachine_C0 |
| PasteurizationMachine_A02_feeds_Relationship0 | nieuwsfeeds | Maak | 2022-12-15 07:16:12.7160 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A02 | SaltMachine_C0 |
| PasteurizationMachine_A03_feeds_Relationship0 | nieuwsfeeds | Maak | 2022-12-15 07:16:12.7250 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A03 | SaltMachine_C1 |
| OsloFactory_contains_Relationship0 | bevat | Verwijderen | 2022-12-15 07:16:13.1780 | dairyadtinstance.api.wcus.digitaltwins.azure.net | OsloFactory | SaltMachine_C0 |
End-to-end gegevensinvoervertraging
De gegevensgeschiedenis van Azure Digital Twins is gebaseerd op het bestaande opnamemechanisme van Azure Data Explorer. Azure Digital Twins zorgt ervoor dat gebeurtenissen voor het bijwerken van grafieken binnen twee seconden beschikbaar worden gesteld aan Azure Data Explorer. Er kan extra latentie worden geïntroduceerd door Azure Data Explorer die de gegevens opneemt.
Er zijn twee methoden in Azure Data Explorer voor het opnemen van gegevens: batchopname en streamingopname. U kunt deze opnamemethoden configureren voor afzonderlijke tabellen op basis van uw behoeften en het specifieke scenario voor gegevensopname.
Streaming-inname heeft de laagste latentie. Vanwege de verwerkingsoverhead mag deze modus echter alleen worden gebruikt als er elk uur minder dan 4 GB aan gegevens wordt opgenomen. Batchverwerking werkt het beste als hoge datasnelheden bij opname worden verwacht. Azure Data Explorer maakt standaard gebruik van batchopname. De volgende tabel bevat een overzicht van de verwachte slechtste end-to-end latentie:
| Configuratie van Azure Data Explorer | Verwachte end-to-end-latentie | Aanbevolen gegevenssnelheid |
|---|---|---|
| Streaming-ingestie | <12 sec (<standaard 3 sec) | <4 GB per uur |
| Batchinvoer | Varieert (12 sec-15 m, afhankelijk van de configuratie) | >4 GB per uur |
De rest van deze sectie bevat details voor het activeren van elk type invoer.
Batchinname (standaard)
Als er geen andere configuratie is, gebruikt Azure Data Explorer batchverwerking. De standaardinstellingen kunnen ertoe leiden dat gegevens slechts 5-10 minuten na het uitvoeren van een update naar een digitale dubbel beschikbaar zijn voor query's. Het opnamebeleid kan worden gewijzigd, zodat de batchverwerking maximaal om de 10 seconden plaatsvindt (minimaal of maximaal 15 minuten). Als u het opnamebeleid wilt wijzigen, moet de volgende opdracht worden uitgegeven in de Azure Data Explorer-queryweergave:
.alter table <table_name> policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:10", "MaximumNumberOfItems": 500, "MaximumRawDataSizeMB": 1024}'
Zorg ervoor dat deze <table_name> wordt vervangen door de naam van de tabel die voor u is ingesteld. MaximumBatchingTimeSpan moet worden ingesteld op het voorkeursinterval voor batchverwerking. Het kan 5-10 minuten duren voordat het beleid van kracht wordt. Meer informatie over opnamebatches vindt u op de volgende koppeling: Kusto IngestionBatching-beleidsbeheeropdracht.
Streaming-ingestie
Het inschakelen van streaming-invoer is een proces in twee stappen.
- Streamingopname inschakelen voor uw cluster. Deze actie hoeft slechts eenmaal te worden uitgevoerd. (Waarschuwing: Dit heeft gevolgen voor de hoeveelheid opslagruimte die beschikbaar is voor hot cache en kan extra beperkingen veroorzaken). Voor instructies, zie Streaming-opname configureren in uw Azure Data Explorer-cluster.
- Voeg een streamingopnamebeleid toe voor de gewenste tabel. Meer informatie over het inschakelen van streaming-ingestie voor uw cluster vindt u in de Azure Data Explorer-documentatie: Kusto IngestionBatching beleidsbeheersopdracht.
Als u streamingopname voor uw Azure Digital Twins-gegevensgeschiedenistabel wilt inschakelen, moet de volgende opdracht worden uitgegeven in het queryvenster van Azure Data Explorer:
.alter table <table_name> policy streamingingestion enable
Zorg ervoor dat deze <table_name> wordt vervangen door de naam van de tabel die voor u is ingesteld. Het kan 5-10 minuten duren voordat het beleid van kracht wordt.
Gehistoriseerde eigenschappen visualiseren
Azure Digital Twins Explorer, een hulpprogramma voor ontwikkelaars voor het visualiseren en interactie met Azure Digital Twins-gegevens, biedt een gegevensgeschiedenisverkennerfunctie voor het bekijken van gegevenshistorie in een grafiek of een tabel. Deze functie is ook beschikbaar in 3D Scenes Studio, een meeslepende 3D-omgeving voor het geven van Azure Digital Twins de visuele context van 3D-assets.

Zie voor meer gedetailleerde informatie over het gebruik van de datahistorieverkenner Historized eigenschappen valideren en verkennen.
Notitie
Als u problemen ondervindt bij het selecteren van een eigenschap in de ervaring van visual data history Explorer, kan dit betekenen dat er een fout optreedt in een bepaald model in uw exemplaar. Als u bijvoorbeeld niet-unieke enumwaarden in de kenmerken van een model hebt, wordt deze visualisatiefunctie verbroken. Als dit gebeurt, controleert u de modeldefinities en controleert u of alle eigenschappen geldig zijn.
Volgende stappen
Zodra twingegevens zijn gehistoriseerd in Azure Data Explorer, kunt u de Azure Digital Twins-plugin voor Azure Data Explorer gebruiken om queries op de gegevens uit te voeren. Lees hier meer over de invoegtoepassing: Query's uitvoeren met de Azure Data Explorer-invoegtoepassing.
U kunt ook dieper ingaan op de gegevensgeschiedenis met instructies voor het maken en een voorbeeldscenario: Een gegevensgeschiedenisverbinding maken.