Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Meer informatie over het gebruik van Apache Spark & Hive Tools voor Visual Studio Code. Gebruik de hulpprogramma's om Apache Hive-batchtaken, interactieve Hive-query's en PySpark-scripts te maken en te verzenden voor Apache Spark. Eerst wordt beschreven hoe u Spark & Hive Tools installeert in Visual Studio Code. Vervolgens wordt uitgelegd hoe u taken kunt verzenden naar Spark & Hive Tools.
Spark & Hive Tools kan worden geïnstalleerd op platforms die worden ondersteund door Visual Studio Code. Houd rekening met de volgende vereisten voor verschillende platforms.
Vereisten
De volgende items zijn vereist voor het voltooien van de stappen in dit artikel:
- Een Azure HDInsight-cluster. Zie Aan de slag met HDInsight om een cluster te maken. Of gebruik een Spark- en Hive-cluster dat ondersteuning biedt voor een Apache Livy-eindpunt.
- Visual Studio Code.
- Mono. Mono is alleen vereist voor Linux en macOS.
- Een interactieve PySpark-omgeving voor Visual Studio Code.
- Een lokale gids. In dit artikel wordt gebruikgemaakt van
C:\HD\HDexample.
Spark & Hive Tools installeren
Wanneer u aan de vereisten voldoet, kunt u Spark & Hive Tools voor Visual Studio Code installeren door de volgende stappen uit te voeren:
Open Visual Studio Code.
Navigeer op de menu balk naar Beeld>Uitbreidingen.
Voer in het zoekvak Spark & Hive in.
Selecteer Spark & Hive Tools in de zoekresultaten en selecteer vervolgens Installeren:
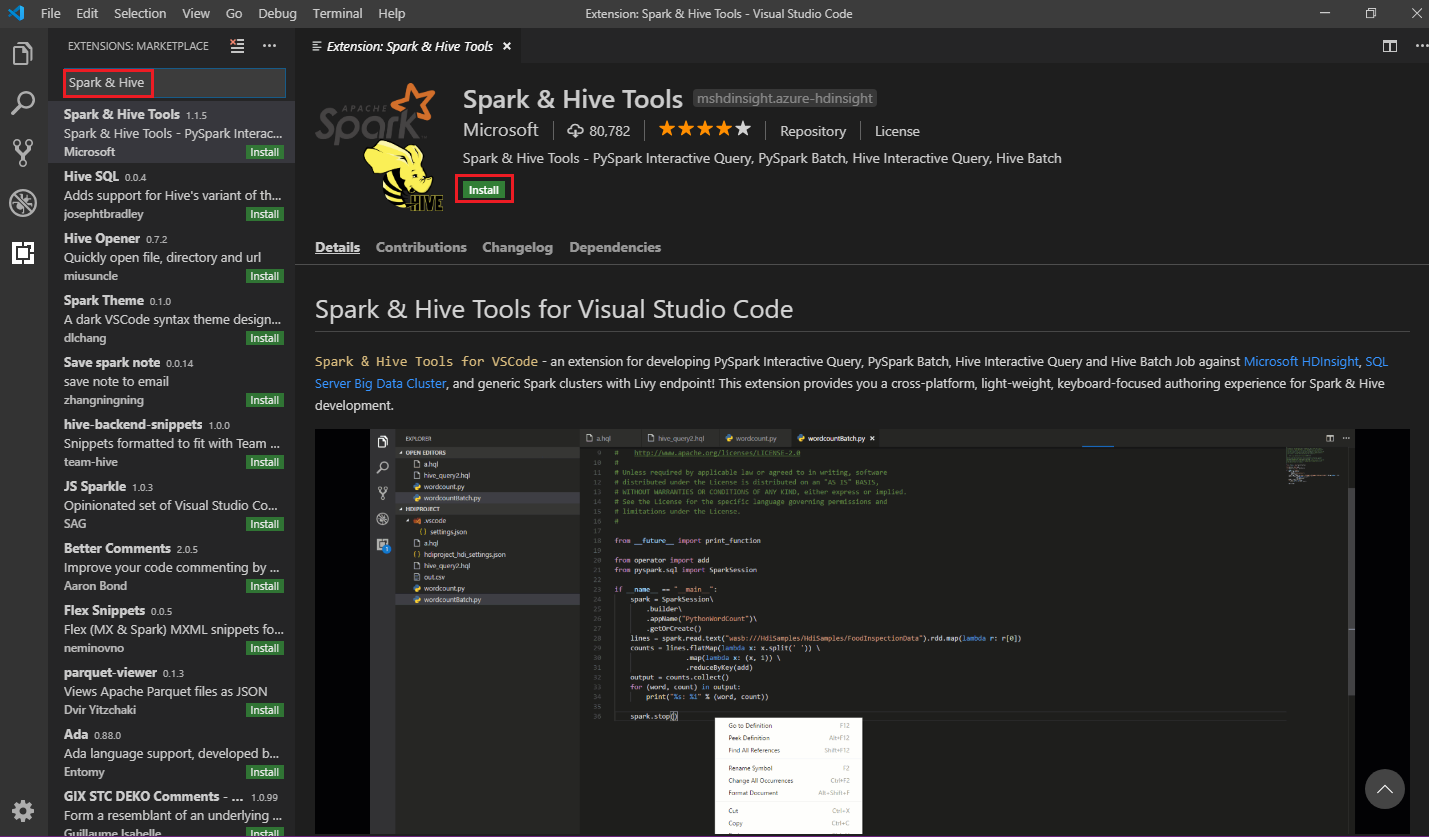
Selecteer zo nodig Opnieuw laden.
Een werkmap openen
Voer de volgende stappen uit om een werkmap te openen en een bestand te maken in Visual Studio Code:
Navigeer in de menubalk naar Bestand>Map openen...>
C:\HD\HDexample, en selecteer vervolgens de knop Map selecteren. De map wordt weergegeven in de weergave Explorer aan de linkerkant.Selecteer in de Verkenner-weergave de
HDexamplemap en selecteer vervolgens het pictogram Nieuw bestand naast de werkmap: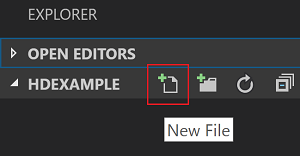
Geef het nieuwe bestand een naam met behulp van de
.hql(Hive-query's) of de.pybestandsextensie (Spark-script). In dit voorbeeld wordt HelloWorld.hql gebruikt.
De Azure-omgeving instellen
Voer voor een nationale cloudgebruiker de volgende stappen uit om eerst de Azure-omgeving in te stellen en gebruik vervolgens de Azure-opdracht: Aanmelden om u aan te melden bij Azure:
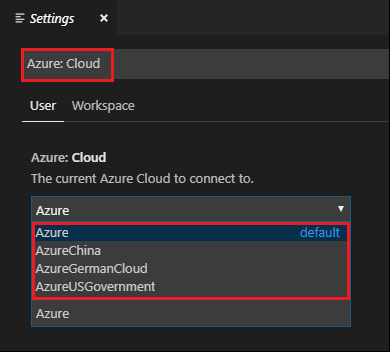
Navigeer naar Bestand>Voorkeuren>Instellingen.
Zoek op de volgende tekenreeks: Azure: Cloud.
Selecteer de nationale cloud in de lijst:
Verbinding maken met een Azure-account
Voordat u vanuit Visual Studio Code scripts naar uw clusters kunt verzenden, kan de gebruiker zich aanmelden bij een Azure-abonnement of een HDInsight-cluster koppelen. Gebruik de ambari-gebruikersnaam/-wachtwoord- of domeinreferentie voor esp-cluster om verbinding te maken met uw HDInsight-cluster. Volg deze stappen om verbinding te maken met Azure:
Navigeer in de menubalk naar Opdrachtpalet weergeven>...en voer Azure in: Aanmelden:
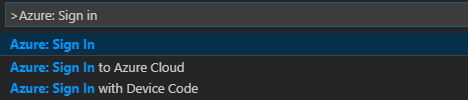
Volg de instructies om u aan te melden bij Azure. Nadat u verbinding hebt gemaakt, ziet u de naam van uw Azure-account op de statusbalk onder in het Visual Studio Code-venster.
Een cluster koppelen
Koppeling: Azure HDInsight
U kunt een normaal cluster koppelen met behulp van een door Apache Ambari beheerde gebruikersnaam of u kunt een Beveiligd Hadoop-cluster van Enterprise Security Pack koppelen met behulp van een domeinnaam (zoals: user1@contoso.com).
Navigeer in de menubalk naar Opdrachtpalet weergeven>...en voer Spark/Hive in: Een cluster koppelen.

Selecteer gekoppeld clustertype Azure HDInsight.
Voer de URL van het HDInsight-cluster in.
Voer uw Ambari-gebruikersnaam in; de standaardwaarde is beheerder.
Voer uw Ambari-wachtwoord in.
Selecteer het clustertype.
Stel de weergavenaam van het cluster in (optioneel).
Bekijk de UITVOERweergave voor verificatie.
Notitie
De gekoppelde gebruikersnaam en het wachtwoord worden gebruikt wanneer het cluster zowel is ingelogd bij het Azure-abonnement als een cluster heeft gekoppeld.
Koppeling: Algemeen Livy-eindpunt
Navigeer in de menubalk naar Opdrachtpalet weergeven>...en voer Spark/Hive in: Een cluster koppelen.
Selecteer gekoppeld clustertype Generic Livy Endpoint.
Voer het algemene Livy-eindpunt in. Bijvoorbeeld: http://10.172.41.42:18080.
Selecteer autorisatietype Basic of None. Als u Basic selecteert:
Voer uw Ambari-gebruikersnaam in; de standaardwaarde is beheerder.
Voer uw Ambari-wachtwoord in.
Bekijk de UITVOERweergave voor verificatie.
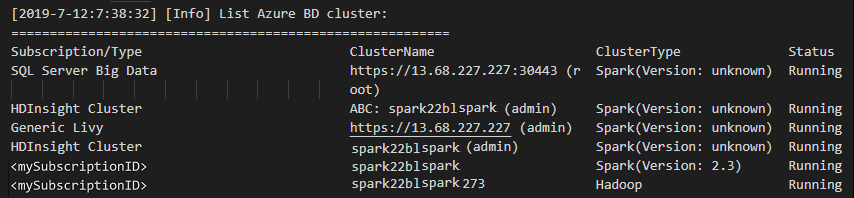
Clusters weergeven
Navigeer in de menubalk naar Weergave>Opdrachtpalet..., en voer Spark / Hive: Lijstcluster in.
Selecteer het gewenste abonnement.
Controleer de uitvoerweergave . In deze weergave ziet u uw gekoppelde cluster (of clusters) en alle clusters binnen uw abonnement voor Azure.
Het standaardcluster instellen
Open de
HDexamplemap die eerder is besproken opnieuw, indien gesloten.Selecteer het HelloWorld.hql-bestand dat eerder is gemaakt. Dit wordt geopend in de scripteditor.
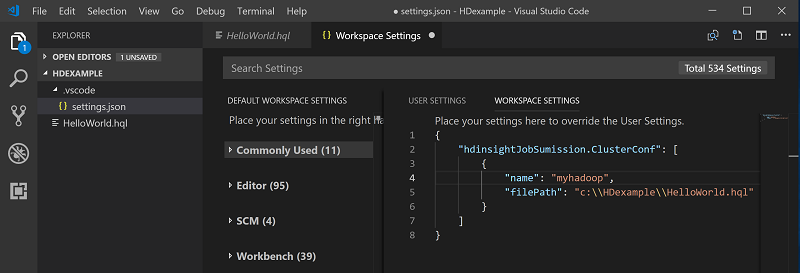
Klik met de rechtermuisknop op de scripteditor en selecteer Spark/Hive: Standaardcluster instellen.
Maak verbinding met uw Azure-account of koppel een cluster als u dit nog niet hebt gedaan.
Selecteer een cluster als het standaardcluster voor het huidige scriptbestand. Het configuratiebestand .VSCode\settings.json wordt automatisch bijgewerkt:
Interactieve Hive-queries en Hive-batchscripts indienen
Met Spark & Hive Tools voor Visual Studio Code kunt u interactieve Hive-query's en Hive-batchscripts verzenden naar uw clusters.
Open de
HDexamplemap die eerder is besproken opnieuw, indien gesloten.Selecteer het HelloWorld.hql-bestand dat eerder is gemaakt. Dit wordt geopend in de scripteditor.
Kopieer en plak de volgende code in uw Hive-bestand en sla deze op:
SELECT * FROM hivesampletable;Maak verbinding met uw Azure-account of koppel een cluster als u dit nog niet hebt gedaan.
Klik met de rechtermuisknop op de scripteditor en selecteer Hive: Interactief om de query in te dienen of gebruik de sneltoets Ctrl+Alt+I. Selecteer Hive: Batch om het script in te dienen of gebruik de sneltoets Ctrl+Alt+H.
Als u geen standaardcluster hebt opgegeven, selecteert u een cluster. Met de hulpprogramma's kunt u ook een codeblok indienen in plaats van het hele scriptbestand met behulp van het contextmenu. Na enkele ogenblikken worden de queryresultaten weergegeven op een nieuw tabblad:
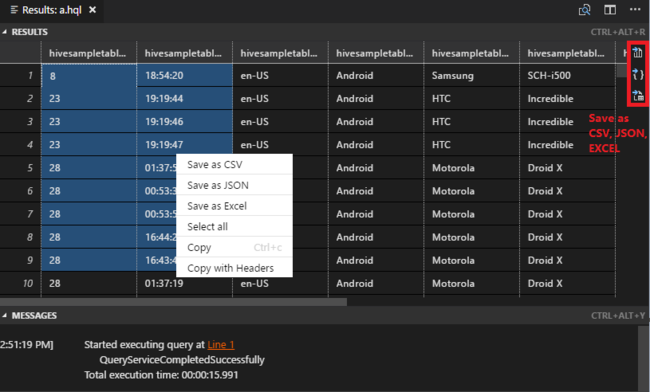
Resultatenvenster : U kunt het hele resultaat opslaan als een CSV-, JSON- of Excel-bestand op een lokaal pad of alleen meerdere regels selecteren.
DEELVENSTER BERICHTEN: Wanneer u een regelnummer selecteert, springt het naar de eerste regel van het lopende script.
Interactieve PySpark-query's verzenden
Vereisten voor Pyspark interactive
Houd er rekening mee dat de jupyter-extensieversie (ms-jupyter): v2022.1.1001614873 en python-extensie (ms-python): v2021.12.1559732655, Python 3.6.x en 3.7.x zijn vereist voor interactieve PYSpark-query's in HDInsight.
Gebruikers kunnen PySpark op de volgende manieren interactief uitvoeren.
De interactieve pySpark-opdracht gebruiken in het PY-bestand
Voer de volgende stappen uit om de query's te verzenden met de interactieve opdracht van PySpark:
Open de
HDexamplemap die eerder is besproken opnieuw, indien gesloten.Maak een nieuw HelloWorld.py-bestand en volg de eerdere stappen.
Kopieer en plak de volgende code in het scriptbestand:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])De prompt voor het installeren van PySpark/Synapse Pyspark-kernel wordt rechtsonder in het venster weergegeven. U kunt klikken op de knop Installeren om door te gaan met de installaties van PySpark/Synapse Pyspark. U kunt ook op de knop Overslaan klikken om deze stap over te slaan.
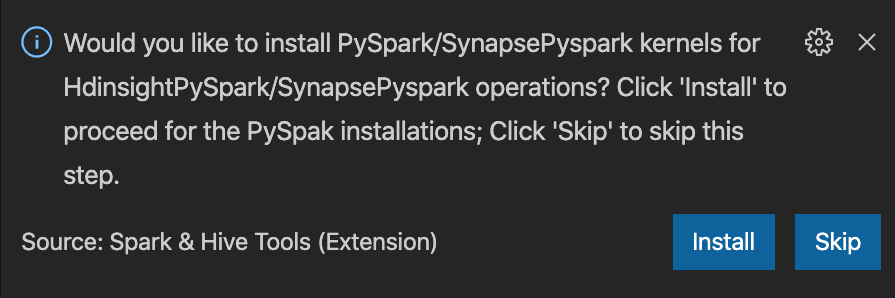
Als u het later wilt installeren, kunt u naar Bestand>Voorkeuren>Instellingen navigeren en HDInsight: Overslaan Pyspark-installatie uitschakelen in de instellingen.
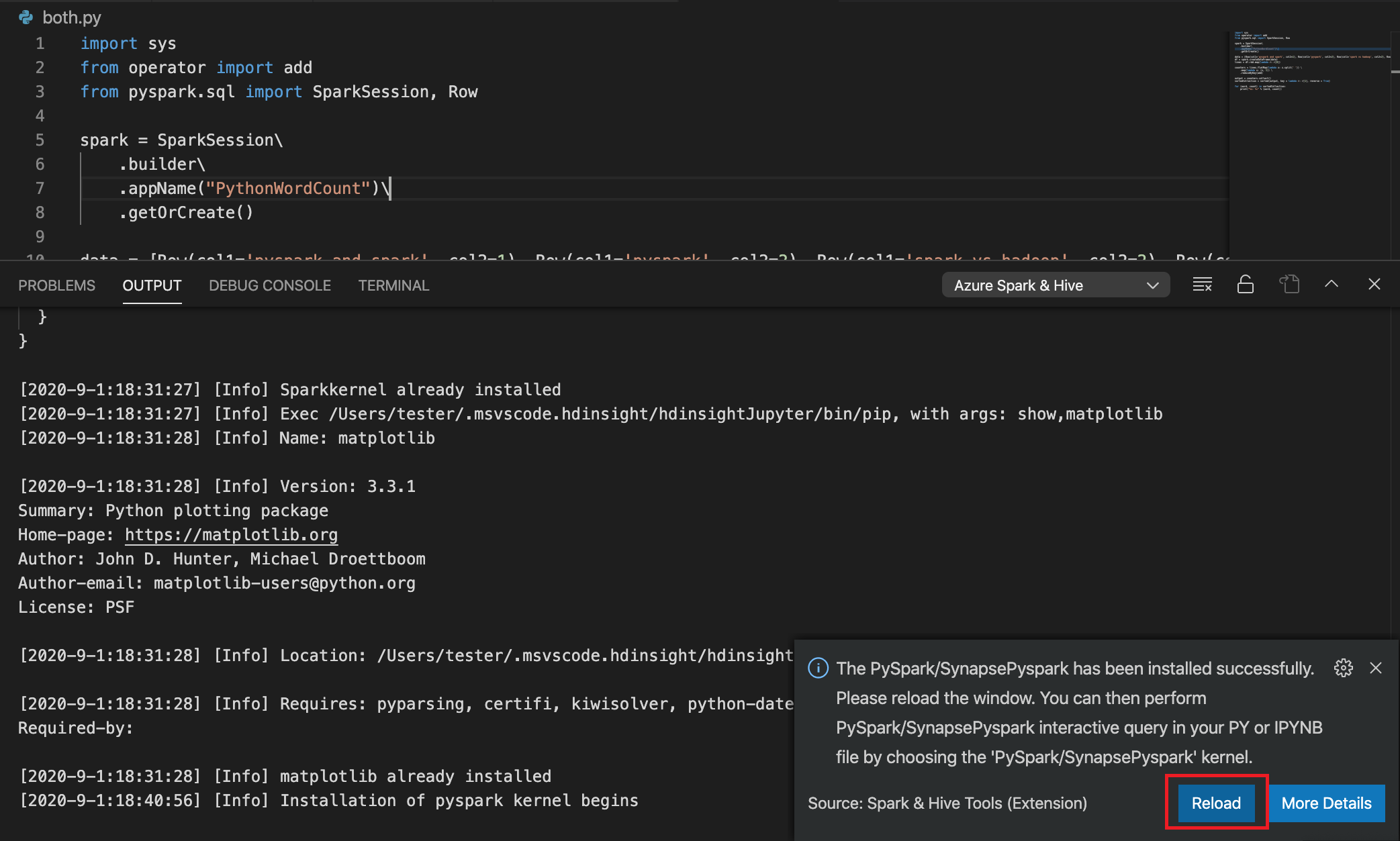
Als de installatie is geslaagd in stap 4, wordt het berichtvak 'PySpark installed successfully' weergegeven in de rechterbenedenhoek van het venster. Klik op de knop Opnieuw laden om het venster opnieuw te laden.
Ga in de menubalk naar opdrachtpalet weergeven>... of gebruik de sneltoets Shift + Ctrl + P en voer Python in: Interpreter selecteren om Jupyter Server te starten.

Selecteer de onderstaande Python-optie.

Navigeer in de menubalk naar Weergave>Opdrachtpalet... of gebruik de sneltoets Shift + Ctrl + P en voer Ontwikkelaar: Venster opnieuw laden in.

Maak verbinding met uw Azure-account of koppel een cluster als u dit nog niet hebt gedaan.
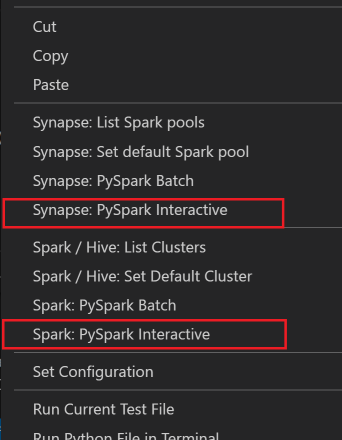
Selecteer alle code, klik met de rechtermuisknop op de scripteditor en selecteer Spark: PySpark Interactive /Synapse: Pyspark Interactive om de query in te dienen.
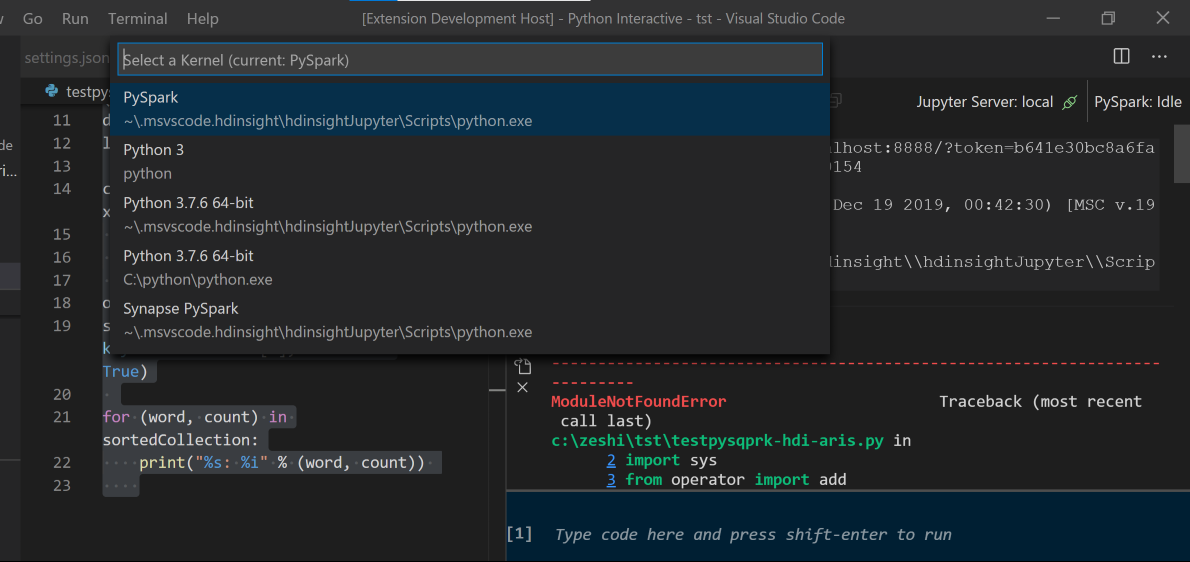
Selecteer het cluster als u geen standaardcluster hebt opgegeven. Na enkele ogenblikken worden de interactieve Python-resultaten weergegeven op een nieuw tabblad. Klik op PySpark om de kernel over te schakelen naar PySpark/Synapse Pyspark en de code wordt uitgevoerd. Als u wilt overschakelen naar de Synapse Pyspark-kernel, wordt het uitschakelen van automatische instellingen in Azure Portal aangeraden. Anders kan het lang duren voordat het cluster wordt geactiveerd en de Synapse-kernel wordt ingesteld voor het eerste gebruik. Als u met de hulpprogramma's ook een codeblok kunt verzenden in plaats van het hele scriptbestand met behulp van het contextmenu:
Voer %%-gegevens in en druk op Shift+Enter om de taakgegevens weer te geven (optioneel):
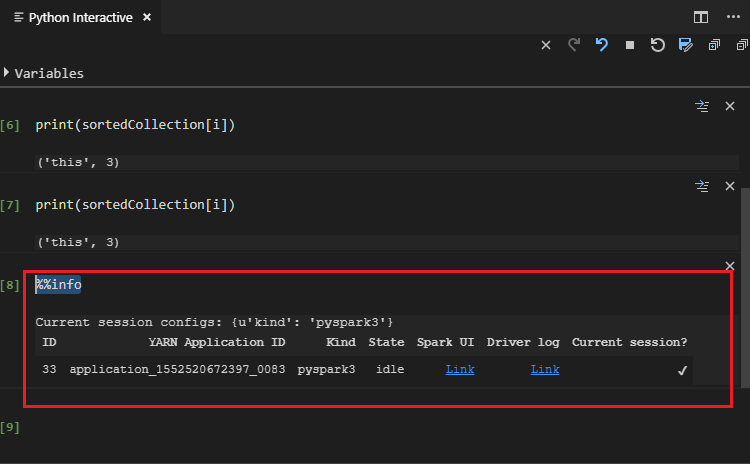
Het hulpprogramma ondersteunt ook de Spark SQL-query :
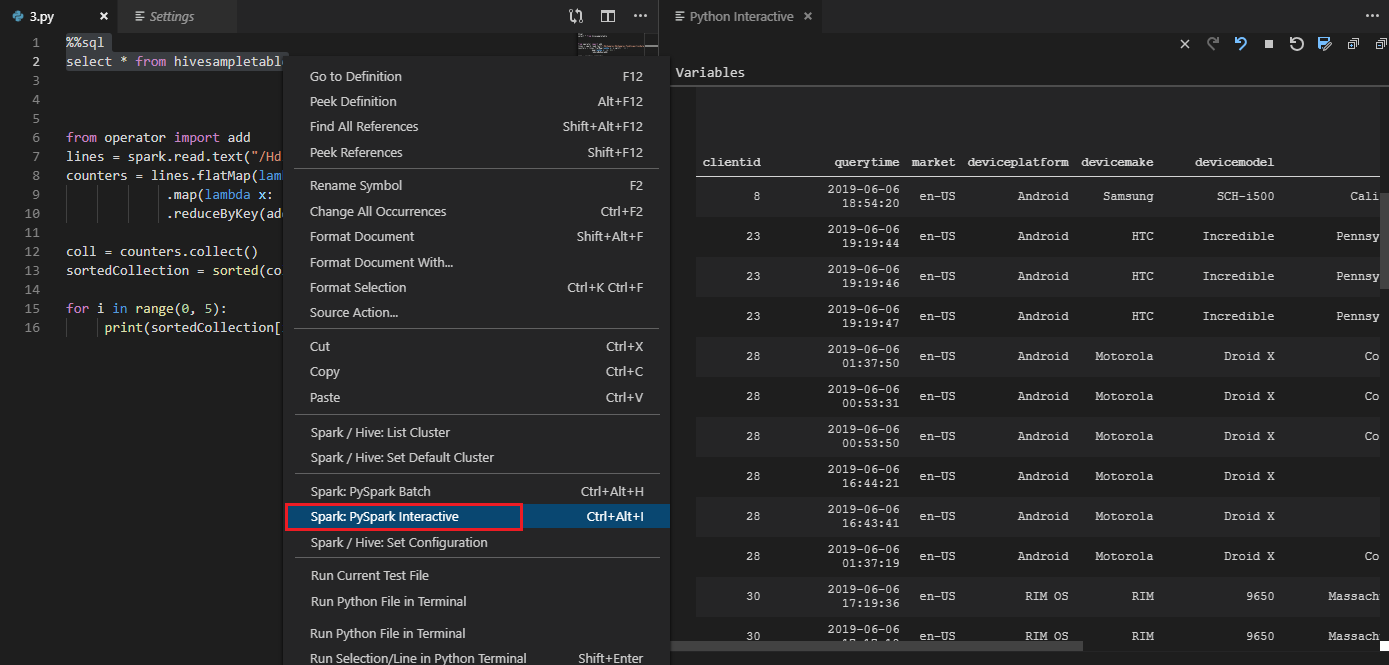
Interactieve query's uitvoeren in een PY-bestand met behulp van een #%%-opmerking
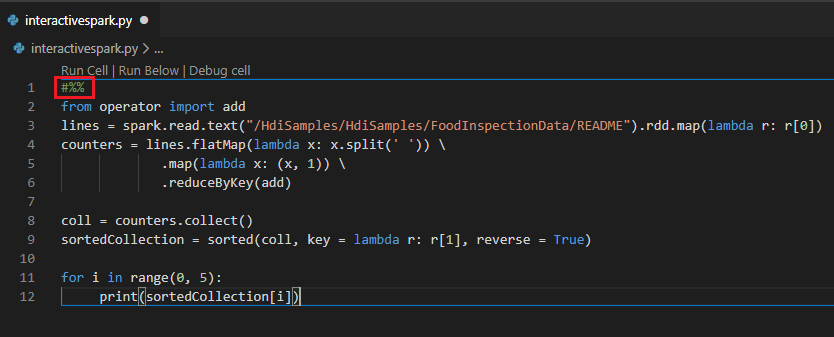
Voeg #%% toe vóór de Py-code om notebookervaring te krijgen.
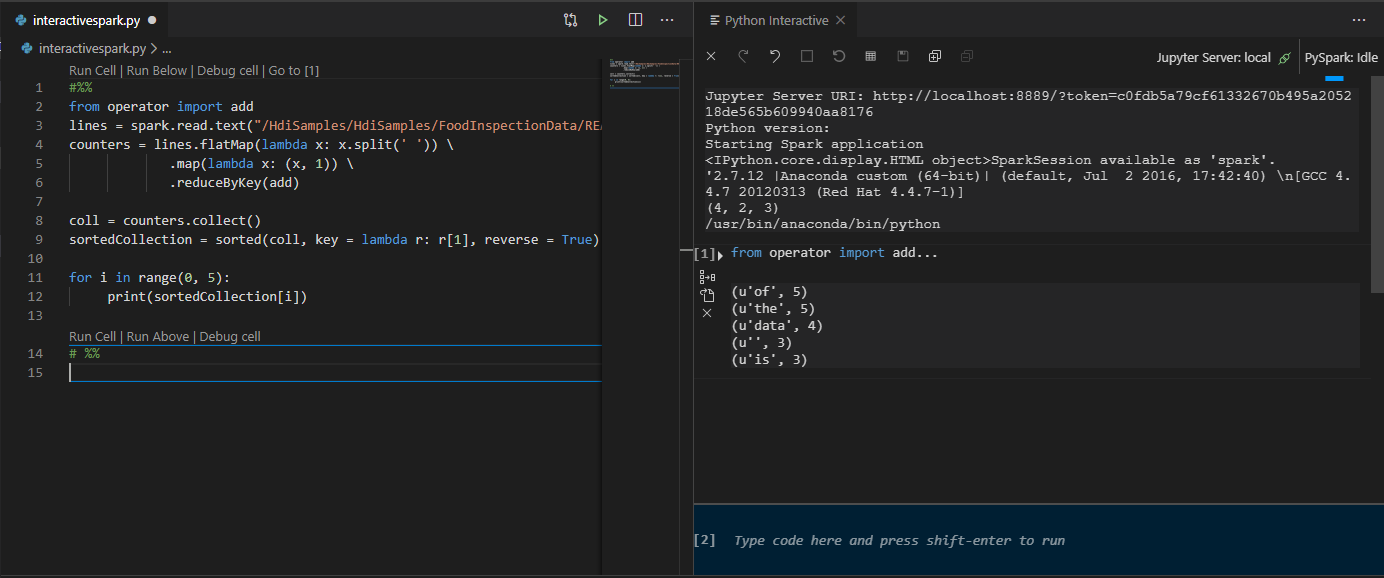
Klik op Voer cel uit. Na enkele ogenblikken worden de interactieve Python-resultaten weergegeven op een nieuw tabblad. Klik op PySpark om de kernel over te zetten naar PySpark/Synapse PySpark, klik vervolgens nogmaals op Cel uitvoeren en de code wordt uitgevoerd.
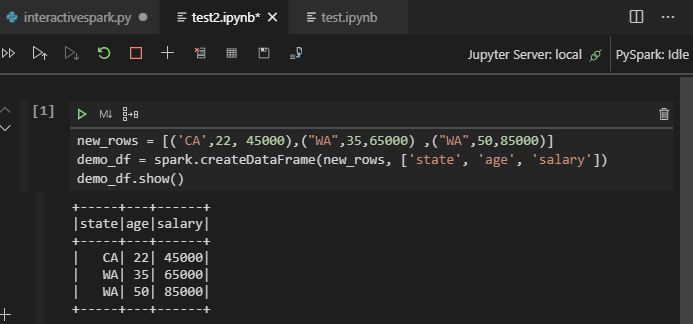
IPYNB-ondersteuning van Python-extensie gebruiken
U kunt een Jupyter Notebook maken op opdracht uit het opdrachtpalet of door een nieuw
.ipynbbestand in uw werkruimte te maken. Zie Werken met Jupyter Notebooks in Visual Studio Code voor meer informatieKlik op de knop Cel uitvoeren, volg de aanwijzingen om de standaard spark-pool in te stellen (we raden u aan om elke keer dat u een notebook opent, het standaardcluster/pool in te stellen) en vervolgens het venster opnieuw laden.
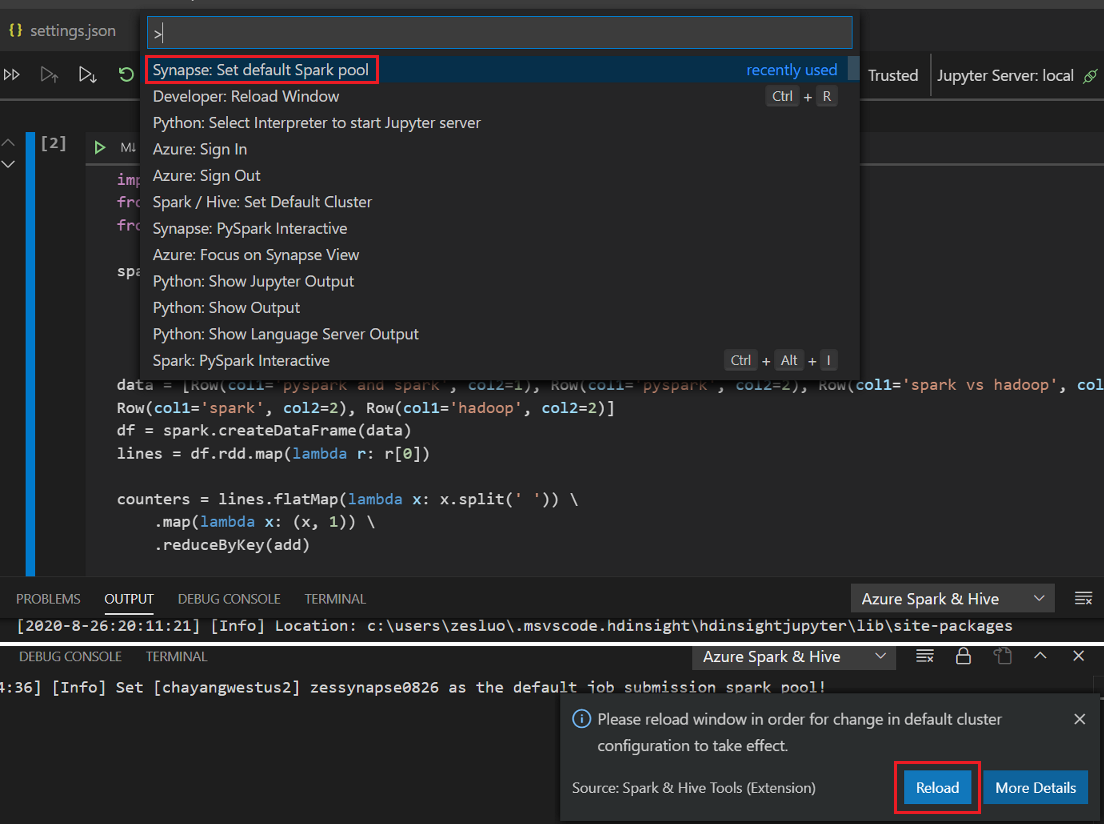
Klik op PySpark om de kernel over te schakelen naar PySpark/Synapse Pyspark en klik vervolgens op Cel uitvoeren. Het resultaat wordt na een tijdje weergegeven.
Notitie
Voor Synapse PySpark-installatiefout, omdat de afhankelijkheid niet meer wordt onderhouden door een ander team, zal dit ook niet meer worden onderhouden. Als u Synapse Pyspark interactive wilt gebruiken, schakelt u over naar Azure Synapse Analytics . En het is een verandering op lange termijn.
Een PySpark-batchtaak indienen.
Open de
HDexamplemap die u eerder hebt besproken opnieuw, indien gesloten.Maak een nieuw BatchFile.py-bestand en volg de eerdere stappen.
Kopieer en plak de volgende code in het scriptbestand:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Maak verbinding met uw Azure-account of koppel een cluster als u dit nog niet hebt gedaan.
Klik met de rechtermuisknop op de scripteditor en selecteer Spark: PySpark Batch of Synapse: PySpark Batch*.
Selecteer een cluster/spark-pool om uw PySpark-taak te verzenden naar:
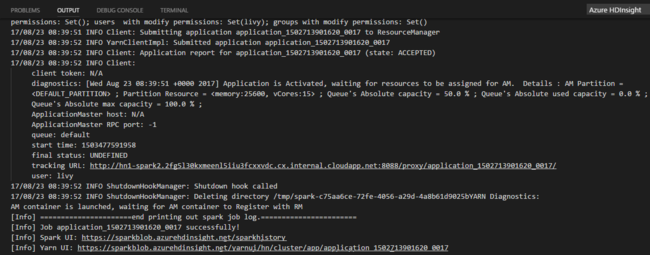
Nadat u een Python-taak hebt verzonden, worden indieningslogboeken weergegeven in het venster UITVOER in Visual Studio Code. De URL van de Spark-gebruikersinterface en de YARN-URL worden ook weergegeven. Als u de batchtaak naar een Apache Spark-pool verzendt, worden ook de URL van de gebruikersinterface van de Spark-historie en de URL van de gebruikersinterface van de Spark-taakapplicatie weergegeven. U kunt de URL openen in een webbrowser om de taakstatus bij te houden.
Integreren met HDInsight Identity Broker (HIB)
Verbinding maken met uw HDInsight ESP-cluster met ID Broker (HIB)
U kunt de normale stappen volgen om u aan te melden bij een Azure-abonnement om verbinding te maken met uw HDInsight ESP-cluster met ID Broker (HIB). Nadat u zich hebt aangemeld, ziet u de lijst met clusters in Azure Explorer. Zie Verbinding maken met uw HDInsight-cluster voor meer instructies.
Een Hive/PySpark-taak uitvoeren op een HDInsight ESP-cluster met ID Broker (HIB)
Voor het uitvoeren van een Hive-taak kunt u de normale stappen volgen om de taak naar het HDInsight ESP-cluster te verzenden met ID Broker (HIB). Raadpleeg Interactie Hive-query's en Hive-batchscripts verzenden voor meer instructies.
Voor het uitvoeren van een interactieve PySpark-taak kunt u de normale stappen volgen om de taak naar het HDInsight ESP-cluster te verzenden met ID Broker (HIB). Raadpleeg de documentatie voor het verzenden van interactieve PySpark-query's.
Voor het uitvoeren van een PySpark-batchtaak kunt u de normale stappen volgen om een taak naar het HDInsight ESP-cluster te verzenden met ID Broker (HIB). Raadpleeg PySpark-batchtaak verzenden voor meer instructies.
Apache Livy-configuratie
Apache Livy-configuratie wordt ondersteund. U kunt deze configureren in de . VSCode\settings.json-bestand in de werkruimtemap. Op dit moment ondersteunt Livy-configuratie alleen Python-scripts. Zie Livy README voor meer informatie.
Methode 1
- Navigeer in de menubalk naar Instellingen voor bestandsvoorkeuren>>.
- Voer in het vak Zoekinstellingen HDInsight-taakinzending in: Livy Conf.
- Selecteer Bewerken in settings.json voor het relevante zoekresultaat.
Methode 2
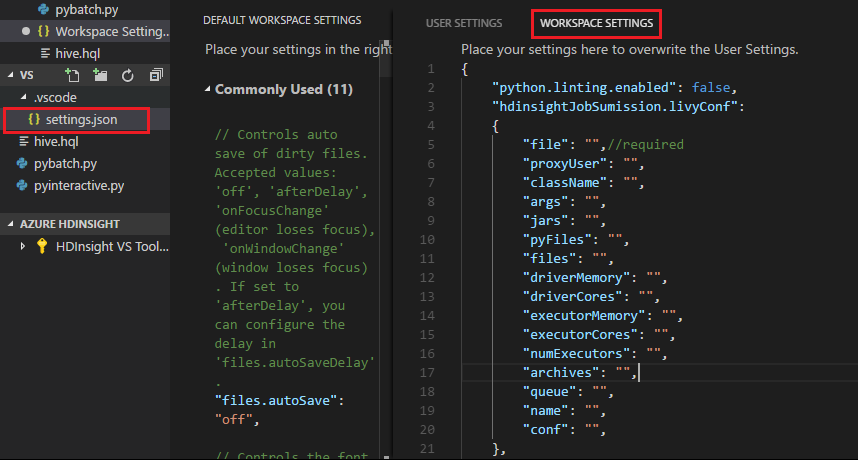
Dien een bestand in en u ziet dat de .vscode map automatisch wordt toegevoegd aan de werkmap. U kunt de Livy-configuratie zien door .vscode\settings.json te selecteren.
De projectinstellingen:
Notitie
Stel voor de driverMemory - en executorMemory-instellingen de waarde en eenheid in. Bijvoorbeeld: 1g of 1024m.
Ondersteunde Livy-configuraties:
POST/batches
Aanvraaginhoud
naam beschrijving soort bestand Bestand met de toepassing die moet worden uitgevoerd Pad (vereist) proxyUser Gebruiker die moet imiteren bij het uitvoeren van de taak String className Hoofdklasse van Toepassing Java/Spark String argumenten Commandoregelargumenten voor de toepassing Lijst van tekenreeksen Potten Jars die in deze sessie moeten worden gebruikt Lijst met tekenreeksen pyFiles Python-bestanden die in deze sessie moeten worden gebruikt Lijst met tekenreeksen bestanden Bestanden die in deze sessie moeten worden gebruikt Lijst met tekenreeksen driverMemory Hoeveelheid geheugen die moet worden gebruikt voor het stuurprogrammaproces String driverCores Aantal kerngeheugens dat moet worden gebruikt voor het stuurprogrammaproces Int executorMemory Hoeveelheid geheugen die per uitvoerproces moet worden gebruikt String executorCores Aantal kerngeheugens dat moet worden gebruikt voor elke uitvoerder Int aantalUitvoerders Aantal uitvoerders dat moet worden gestart voor deze sessie Int archieven Archieven die in deze sessie moeten worden gebruikt Lijst met tekenreeksen wachtrij Naam van de YARN-wachtrij die moet worden verzonden naar String naam Naam van deze sessie String Conferentie Spark-configuratie-eigenschappen Kaart van key=val Antwoordtekst Het gemaakte Batch-object.
naam beschrijving type Id Sessie-ID Int appId Toepassings-id van deze sessie String appInfo Gedetailleerde toepassingsgegevens Kaart voor key=val logboek Logboeklijnen Lijst met tekenreeksen staat Batchstatus Snaar / Tekenreeks Notitie
De toegewezen Livy-configuratie wordt weergegeven in het uitvoervenster wanneer u het script verzendt.
Integreren met Azure HDInsight vanuit Explorer
U kunt een voorbeeld van een Hive-tabel in uw clusters rechtstreeks bekijken op Azure HDInsight Explorer.
Maak verbinding met uw Azure-account als u dit nog niet hebt gedaan.
Selecteer het Azure-pictogram in de meest linkse kolom.
Vouw AZURE: HDINSIGHT uit in het linkerdeelvenster. De beschikbare abonnementen en clusters worden weergegeven.
Vouw het cluster uit om de Hive-metagegevensdatabase en het tabelschema weer te geven.
Klik met de rechtermuisknop op de Hive-tabel. Bijvoorbeeld: hivesampletable. Selecteer Voorbeeld.
Het venster Voorbeeldresultaten wordt geopend:
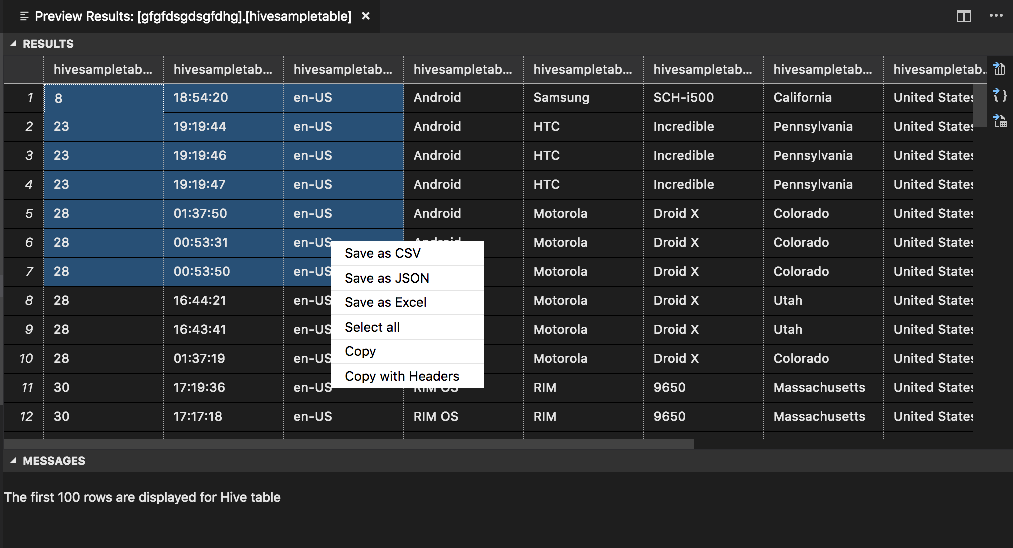
Deelvenster resultaten
U kunt het hele resultaat opslaan als een CSV-, JSON- of Excel-bestand in een lokaal pad of alleen meerdere regels selecteren.
Deelvenster BERICHTEN
Wanneer het aantal rijen in de tabel groter is dan 100, ziet u het volgende bericht: 'De eerste 100 rijen worden weergegeven voor Hive-tabel'.
Wanneer het aantal rijen in de tabel kleiner is dan of gelijk is aan 100, ziet u het volgende bericht: '60 rijen worden weergegeven voor Hive-tabel'.
Wanneer er geen inhoud in de tabel staat, ziet u het volgende bericht: '
0 rows are displayed for Hive table.'Notitie
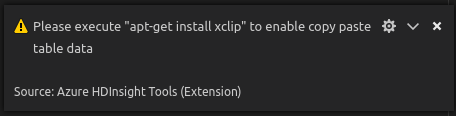
Installeer in Linux xclip om kopiëren van tabelgegevens in te schakelen.
Extra functies
Spark & Hive voor Visual Studio Code ondersteunt ook de volgende functies:
IntelliSense automatisch aanvullen. Suggesties worden weergegeven voor trefwoorden, methoden, variabelen en andere programmeerelementen. Verschillende pictogrammen vertegenwoordigen verschillende soorten objecten:
IntelliSense-foutmarkering. De taalservice onderstreept bewerkingsfouten in het Hive-script.
Syntaxis gemarkeerd. De taalservice gebruikt verschillende kleuren om variabelen, trefwoorden, gegevenstype, functies en andere programmeerelementen te onderscheiden:
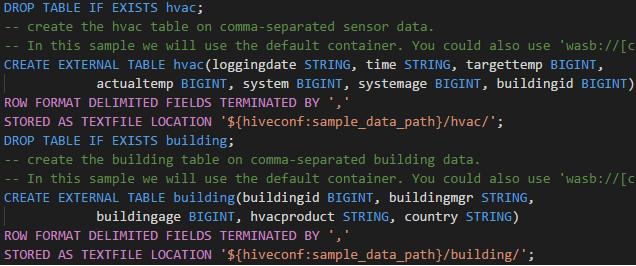
Rol alleen lezer
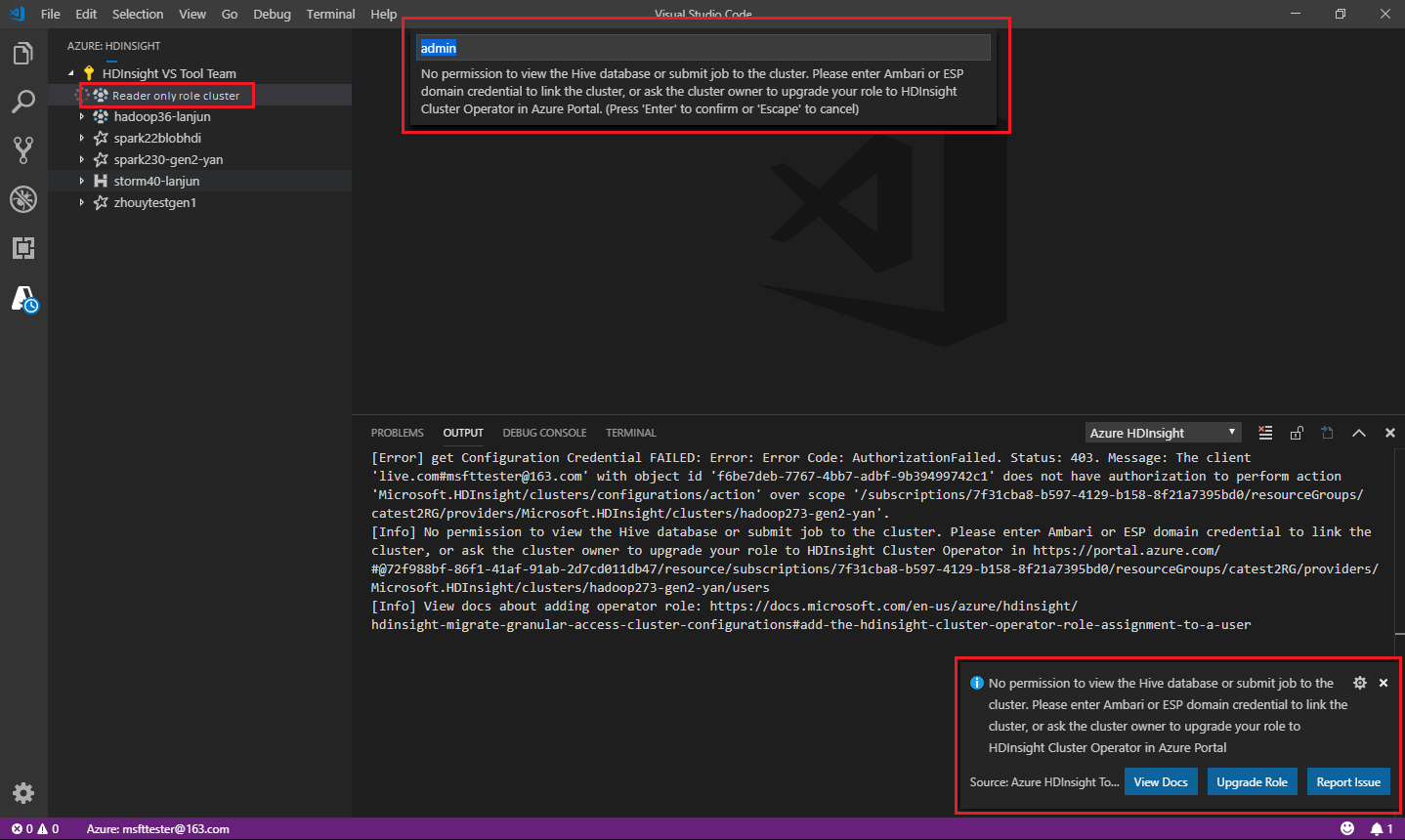
Gebruikers aan wie de rol alleen-lezer voor het cluster is toegewezen, kunnen geen taken verzenden naar het HDInsight-cluster en de Hive-database niet weergeven. Neem contact op met de clusterbeheerder om uw rol te upgraden naar HDInsight-clusteroperator in Azure Portal. Als u geldige Ambari-referenties hebt, kunt u het cluster handmatig koppelen met behulp van de volgende richtlijnen.
Bladeren in het HDInsight-cluster
Wanneer u Azure HDInsight Explorer selecteert om een HDInsight-cluster uit te vouwen, wordt u gevraagd het cluster te koppelen als u de rol alleen-lezer voor het cluster hebt. Gebruik de volgende methode om een koppeling naar het cluster te maken met behulp van uw Ambari-referenties.
De taak verzenden naar het HDInsight-cluster
Wanneer u een taak verzendt naar een HDInsight-cluster, wordt u gevraagd het cluster te koppelen als u de alleen-lezen rol voor het cluster hebt. Gebruik de volgende stappen om een koppeling naar het cluster te maken met behulp van Ambari-referenties.
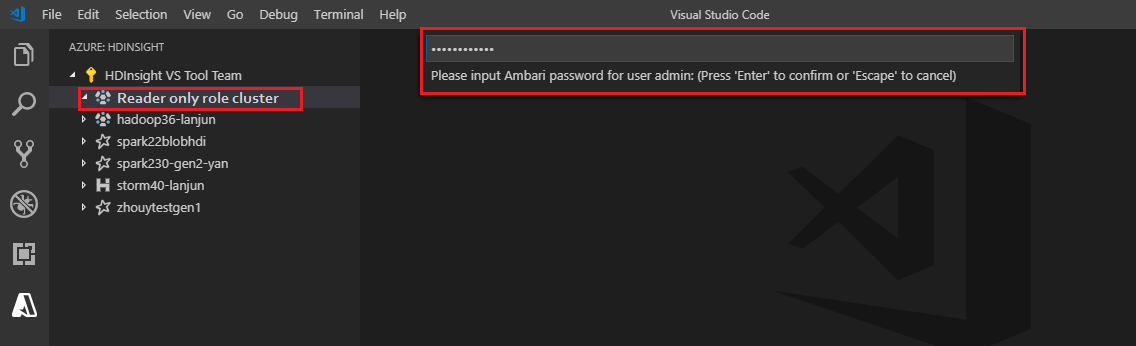
Koppeling naar het cluster
Voer een geldige Ambari-gebruikersnaam in.
Voer een geldig wachtwoord in.
Notitie
U kunt
Spark / Hive: List Clustergebruiken om het gekoppelde cluster te controleren.
Azure Data Lake Storage Gen2
Bladeren door een Data Lake Storage Gen2-account
Selecteer azure HDInsight Explorer om een Data Lake Storage Gen2-account uit te vouwen. U wordt gevraagd om de toegangssleutel voor opslag in te voeren als uw Azure-account geen toegang heeft tot Gen2-opslag. Nadat de toegangssleutel is gevalideerd, wordt het Data Lake Storage Gen2-account automatisch uitgebreid.
Taken indienen bij een HDInsight-cluster met Data Lake Storage Gen2
Dien een taak in bij een HDInsight-cluster met behulp van Data Lake Storage Gen2. U wordt gevraagd om de toegangssleutel voor opslag in te voeren als uw Azure-account geen schrijftoegang heeft tot Gen2-opslag. Nadat de toegangssleutel is gevalideerd, wordt de taak succesvol ingediend.

Notitie
U kunt de toegangssleutel voor het opslagaccount ophalen via Azure Portal. Zie Toegangssleutels voor een opslagaccount beheren voor meer informatie.
Cluster ontkoppelen
Ga in de menubalk naar >en voer spark/Hive in: Een cluster ontkoppelen.
Selecteer een cluster dat u wilt ontkoppelen.
Zie de UITVOERweergave voor verificatie.
Afmelden
Ga in de menubalk naar >en voer vervolgens Azure in: Afmelden.
Bekende problemen
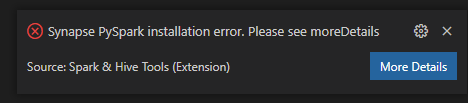
Synapse PySpark-installatiefout.
Voor synapse PySpark-installatiefout, omdat de afhankelijkheid niet meer wordt onderhouden door een ander team, wordt deze niet meer onderhouden. Als u Synapse Pyspark interactive probeert te gebruiken, gebruikt u in plaats daarvan Azure Synapse Analytics . En het is een verandering op lange termijn.
Volgende stappen
Zie Spark & Hive voor Visual Studio Code voor een video die laat zien hoe Spark & Hive voor Visual Studio Code wordt gebruikt.