Een Apache Hive-fout met onvoldoende geheugen in Azure HDInsight oplossen
Meer informatie over het oplossen van een OOM-fout (Apache Hive out-of-memory) bij het verwerken van grote tabellen door hive-geheugeninstellingen te configureren.
Een klant heeft een Hive-query uitgevoerd:
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
Enkele nuances van deze query:
- T1 is een alias voor een grote tabel, TABLE1, met veel kolomtypen TEKENREEKS.
- Andere tabellen zijn niet zo groot, maar hebben wel veel kolommen.
- Alle tabellen voegen elkaar samen, in sommige gevallen met meerdere kolommen in TABLE1 en andere.
Het duurt 26 minuten voordat de Hive-query is voltooid op een HDInsight-cluster met 24 knooppunten. De klant heeft de volgende waarschuwingsberichten opgemerkt:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
Met behulp van de Apache Tez-uitvoeringsengine. Dezelfde query is 15 minuten uitgevoerd en heeft vervolgens de volgende fout veroorzaakt:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
De fout blijft bestaan bij het gebruik van een grotere virtuele machine (bijvoorbeeld D12).
Onze ondersteunings- en technische teams hebben samen een van de problemen gevonden die de fout met onvoldoende geheugen veroorzaken, is een bekend probleem dat wordt beschreven in de Apache JIRA:
"Wanneer hive.auto.convert.join.noconditionaliask = true we check noconditionaliask.size en als de som van de grootten van tabellen in de toewijzingsdeelname kleiner is dan noconditionaliask.size, genereert het plan een toewijzingsdeelname, het probleem is dat de berekening niet rekening houdt met de overhead die wordt geïntroduceerd door een andere HashTable-implementatie als resultaten als de som van invoergrootten kleiner is dan de noconditionatisk-grootte door een kleine margequery's OOM."
De hive.auto.convert.join.noconditionwaardesk in het bestand hive-site.xml is ingesteld op true:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
Het is waarschijnlijk dat toewijzingsdeelname de oorzaak was van de Java Heap-ruimte van onvoldoende geheugen. Zoals uitgelegd in de blogpost Hadoop Yarn-geheugeninstellingen in HDInsight, wanneer tez-uitvoeringsengine de gebruikte heap-ruimte daadwerkelijk tot de Tez-container behoort. Zie de volgende afbeelding waarin het Tez-containergeheugen wordt beschreven.
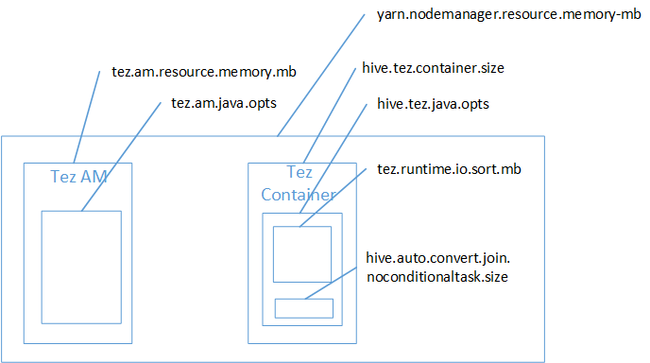
Zoals in het blogbericht wordt voorgesteld, definiëren de volgende twee geheugeninstellingen het containergeheugen voor de heap: hive.tez.container.size en hive.tez.java.opts. Uit onze ervaring betekent de uitzondering buiten het geheugen niet dat de containergrootte te klein is. Dit betekent dat de Grootte van de Java-heap (hive.tez.java.opts) te klein is. Dus wanneer u onvoldoende geheugen ziet, kunt u proberen om hive.tez.java.opts te verhogen. Indien nodig moet u mogelijk hive.tez.container.size verhogen. De instelling java.opts moet ongeveer 80% van container.size zijn.
Notitie
De instelling hive.tez.java.opts moet altijd kleiner zijn dan hive.tez.container.size.
Omdat een D12-machine 28 GB geheugen heeft, hebben we besloten om een containergrootte van 10 GB (10240 MB) te gebruiken en 80% toe te wijzen aan java.opts:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
Met de nieuwe instellingen is de query in minder dan 10 minuten uitgevoerd.
Het ophalen van een OOM-fout betekent niet noodzakelijkerwijs dat de containergrootte te klein is. In plaats daarvan moet u de geheugeninstellingen zo configureren dat de heap-grootte wordt verhoogd en ten minste 80% van de grootte van het containergeheugen is. Zie Apache Hive-query's optimaliseren voor Apache Hadoop in HDInsight voor het optimaliseren van Hive-query's.