Services met hoge beschikbaarheid die worden ondersteund door Azure HDInsight
Om u optimale beschikbaarheidsniveaus voor uw analyseonderdelen te bieden, is HDInsight ontwikkeld met een unieke architectuur om hoge beschikbaarheid (HA) van kritieke services te garanderen. Microsoft heeft enkele onderdelen van deze architectuur ontwikkeld om automatische failover te bieden. Andere onderdelen zijn standaard Apache-onderdelen die worden geïmplementeerd ter ondersteuning van specifieke services. In dit artikel wordt de architectuur van het HA-servicemodel in HDInsight uitgelegd, hoe HDInsight failover voor HA-services ondersteunt en aanbevolen procedures voor het herstellen van andere serviceonderbrekingen.
Notitie
Dit artikel bevat verwijzingen naar de term slave, een term die Microsoft niet meer gebruikt. Zodra de term uit de software wordt verwijderd, verwijderen we deze uit dit artikel.
Infrastructuur voor hoge beschikbaarheid
HDInsight biedt aangepaste infrastructuur om ervoor te zorgen dat vier primaire services hoge beschikbaarheid hebben met automatische failovermogelijkheden:
- Apache Ambari-server
- Application Timeline Server voor Apache YARN
- Taakgeschiedenisserver voor Hadoop MapReduce
- Apache Livy
Deze infrastructuur bestaat uit veel services en softwareonderdelen, waarvan sommige zijn ontworpen door Microsoft. De volgende onderdelen zijn uniek voor het HDInsight-platform:
- Slave-failovercontroller
- Hoofdfailovercontroller
- Slaaf hoge beschikbaarheidsservice
- Hoofdservice voor hoge beschikbaarheid
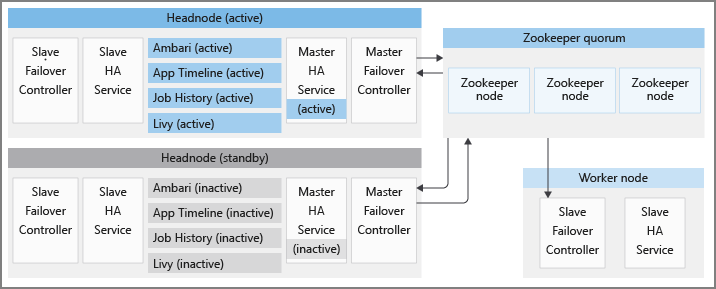
Er zijn ook andere services voor hoge beschikbaarheid, die worden ondersteund door opensource Apache-betrouwbaarheidsonderdelen. Deze onderdelen zijn ook aanwezig op HDInsight-clusters:
- Hadoop File System (HDFS) NameNode
- YARN ResourceManager
- HBase-master
In de volgende secties vindt u meer informatie over hoe deze services samenwerken.
HDInsight-services voor hoge beschikbaarheid
Microsoft biedt ondersteuning voor de vier Apache-services in de volgende tabel in HDInsight-clusters. Om ze te onderscheiden van services met hoge beschikbaarheid die worden ondersteund door onderdelen van Apache, worden ze HDInsight HA-services genoemd.
| Service | Clusterknooppunten | Clustertypen | Doel |
|---|---|---|---|
| Apache Ambari-server | Actief hoofdknooppunt | Alle | Bewaakt en beheert het cluster. |
| Application Timeline Server voor Apache YARN | Actief hoofdknooppunt | Alles behalve Kafka | Onderhoudt foutopsporingsinformatie over YARN-taken die worden uitgevoerd op het cluster. |
| Taakgeschiedenisserver voor Hadoop MapReduce | Actief hoofdknooppunt | Alles behalve Kafka | Onderhoudt foutopsporingsgegevens voor MapReduce-taken. |
| Apache Livy | Actief hoofdknooppunt | Spark | Maakt eenvoudige interactie met een Spark-cluster mogelijk via een REST-interface |
Notitie
HDInsight Enterprise Security Package-clusters (ESP) bieden momenteel alleen hoge beschikbaarheid van de Ambari-server. Application Timeline Server, Job History Server en Livy worden allemaal alleen uitgevoerd op headnode0 en ze maken geen failover naar headnode1 wanneer Ambari een failover uitvoert. De database van de toepassingstijdlijn bevindt zich ook op headnode0 en niet op ambari SQL-server.
Architectuur
Elk HDInsight-cluster heeft respectievelijk twee hoofdknooppunten in de actieve en stand-bymodus. De HDInsight HA-services worden alleen uitgevoerd op hoofdknooppunten. Deze services moeten altijd worden uitgevoerd op het actieve hoofdknooppunt en worden gestopt en in de onderhoudsmodus op het stand-byhoofdknooppunt geplaatst.
HdInsight maakt gebruik van Apache ZooKeeper, een coördinatieservice voor gedistribueerde toepassingen, om de juiste statussen van HA-services te behouden en een snelle failover te bieden, om actieve hoofdknooppuntverkiezing uit te voeren. HDInsight richt ook enkele achtergrond Java-processen in, die de failoverprocedure voor HDInsight HA-services coördineren. Deze services zijn: de masterfailovercontroller, de slave-failovercontroller, de master-ha-service en de slave-ha-service.
Apache ZooKeeper
Apache ZooKeeper is een hoogwaardige coördinatieservice voor gedistribueerde toepassingen. In productie wordt ZooKeeper meestal uitgevoerd in de gerepliceerde modus waarbij een gerepliceerde groep ZooKeeper-server een quorum vormt. Elk HDInsight-cluster heeft drie ZooKeeper-knooppunten waarmee drie ZooKeeper-servers een quorum kunnen vormen. HDInsight heeft twee ZooKeeper-quorums die parallel met elkaar worden uitgevoerd. Eén quorum bepaalt het actieve hoofdknooppunt in een cluster waarop HDInsight HA-services moeten worden uitgevoerd. Een ander quorum wordt gebruikt om HA-services van Apache te coördineren, zoals beschreven in latere secties.
Slave-failovercontroller
De slave-failovercontroller wordt uitgevoerd op elk knooppunt in een HDInsight-cluster. Deze controller is verantwoordelijk voor het starten van de Ambari-agent en slave-ha-service op elk knooppunt. Er wordt periodiek een query uitgevoerd op het eerste ZooKeeper-quorum over het actieve hoofdknooppunt. Wanneer de actieve en stand-byhoofdknooppunten veranderen, voert de slave-failovercontroller de volgende stappen uit:
- Werkt het hostconfiguratiebestand bij.
- Start de Ambari-agent opnieuw.
De slave-ha-service is verantwoordelijk voor het stoppen van de HDInsight HA-services (behalve Ambari-server) op het stand-by-hoofdknooppunt.
Hoofdfailovercontroller
Een hoofdfailovercontroller wordt uitgevoerd op beide hoofdknooppunten. Beide hoofdfailovercontrollers communiceren met het eerste ZooKeeper-quorum om het hoofdknooppunt te nomineren waarop ze worden uitgevoerd als het actieve hoofdknooppunt.
Als de masterfailovercontroller op headnode 0 bijvoorbeeld de verkiezing wint, vinden de volgende wijzigingen plaats:
- Hoofdknooppunt 0 wordt actief.
- De masterfailovercontroller start de Ambari-server en de master-ha-service op headnode 0.
- De andere masterfailovercontroller stopt de Ambari-server en de master-ha-service op headnode 1.
De master-ha-service wordt alleen uitgevoerd op het actieve hoofdknooppunt, het stopt de HDInsight HA-services (behalve Ambari-server) op stand-by headnode en start ze op actieve headnode.
Het failoverproces
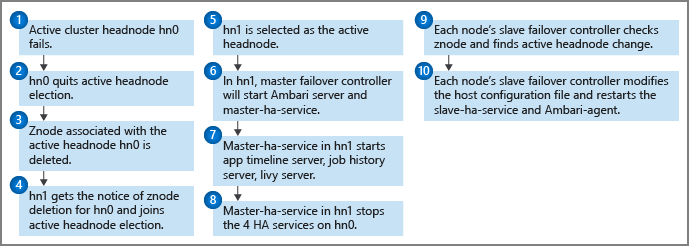
Een statusmonitor wordt uitgevoerd op elk hoofdknooppunt, samen met de masterfailovercontroller om heartbeatmeldingen te verzenden naar het Zookeeper-quorum. Het hoofdknooppunt wordt in dit scenario beschouwd als een HA-service. De statusmonitor controleert of elke service met hoge beschikbaarheid in orde is en of deze klaar is om deel te nemen aan de leiderschapsverkiezingen. Zo ja, dan concurreren deze hoofdknooppunten bij de verkiezing. Zo niet, dan sluit het de verkiezing totdat het weer klaar is.
Als het stand-byhoofdknooppunt ooit leiderschap bereikt en actief wordt (zoals in het geval van een fout met het vorige actieve knooppunt), worden alle HDInsight HA-services gestart op de hoofdfailovercontroller. De hoofdfailovercontroller stopt deze services op het andere hoofdknooppunt.
Voor HDInsight HA-servicefouten, zoals een service die niet in orde is, moet de hoofdfailovercontroller de services automatisch opnieuw opstarten of stoppen op basis van de status van het hoofdknooppunt. Gebruikers moeten HDInsight HA-services niet handmatig starten op beide hoofdknooppunten. In plaats daarvan kunt u automatische of handmatige failover toestaan om de service te helpen herstellen.
Onbedoeld handmatige interventie
HDInsight HA-services mogen alleen worden uitgevoerd op het actieve hoofdknooppunt en worden indien nodig automatisch opnieuw opgestart. Omdat afzonderlijke HA-services geen eigen statusmonitor hebben, kan failover niet worden geactiveerd op het niveau van de afzonderlijke service. Failover wordt gegarandeerd op knooppuntniveau en niet op serviceniveau.
Enkele bekende problemen
Wanneer u handmatig een HA-service start op het stand-byhoofdknooppunt, stopt deze pas wanneer de volgende failover plaatsvindt. Wanneer HA-services op beide hoofdknooppunten worden uitgevoerd, zijn er enkele mogelijke problemen: ambari-gebruikersinterface is niet toegankelijk, Ambari genereert fouten, YARN-, Spark- en Oozie-taken kunnen vastlopen.
Wanneer een HA-service op het actieve hoofdknooppunt stopt, wordt deze pas opnieuw opgestart als de volgende failover plaatsvindt of de masterfailovercontroller/master-ha-service opnieuw wordt opgestart. Wanneer een of meer HA-services stoppen op het actieve hoofdknooppunt, met name wanneer de Ambari-server stopt, is de Ambari-gebruikersinterface niet toegankelijk, andere mogelijke problemen zijn yarn-, Spark- en Oozie-takenfouten.
Apache-services voor hoge beschikbaarheid
Apache biedt hoge beschikbaarheid voor HDFS NameNode, YARN ResourceManager en HBase Master, die ook beschikbaar zijn in HDInsight-clusters. In tegenstelling tot HDInsight HA-services worden ze ondersteund in ESP-clusters. Apache HA-services communiceren met het tweede ZooKeeper-quorum (beschreven in de bovenstaande sectie) om actieve/stand-bystatussen te kiezen en automatische failover uit te voeren. In de volgende secties wordt beschreven hoe deze services werken.
Hadoop Distributed File System (HDFS) NameNode
HDInsight-clusters op basis van Apache Hadoop 2.0 of hoger bieden hoge beschikbaarheid van NameNode. Er worden twee NameNodes uitgevoerd op de hoofdknooppunten, die zijn geconfigureerd voor automatische failover. De NameNodes gebruiken de ZKFailoverController om te communiceren met Zookeeper om te kiezen voor de actieve/stand-bystatus. De ZKFailoverController wordt op beide hoofdknooppunten uitgevoerd en werkt op dezelfde manier als de masterfailovercontroller.
Het tweede Zookeeper-quorum is onafhankelijk van het eerste quorum, dus de actieve NameNode wordt mogelijk niet uitgevoerd op het actieve hoofdknooppunt. Wanneer de actieve NameNode dood of beschadigd is, wint de stand-by NameNode de verkiezing en wordt actief.
YARN ResourceManager
HDInsight-clusters op basis van Apache Hadoop 2.4 of hoger ondersteunen yarn ResourceManager hoge beschikbaarheid. Er zijn twee ResourceManagers, rm1 en rm2, die respectievelijk worden uitgevoerd op hoofdknooppunt 0 en hoofdknooppunt 1. Net als NameNode is YARN ResourceManager ook geconfigureerd voor automatische failover. Een andere ResourceManager wordt automatisch geselecteerd om actief te zijn wanneer de huidige actieve ResourceManager uitvalt of niet reageert.
YARN ResourceManager gebruikt de ingesloten ActiveStandbyElector als foutdetector en leiderkiezer. In tegenstelling tot HDFS NameNode heeft YARN ResourceManager geen afzonderlijke ZKFC-daemon nodig. De actieve ResourceManager schrijft de statussen naar Apache Zookeeper.
De hoge beschikbaarheid van yarn ResourceManager is onafhankelijk van NameNode en andere HDInsight HA-services. De actieve ResourceManager kan niet worden uitgevoerd op het actieve hoofdknooppunt of het hoofdknooppunt waarop de actieve NameNode wordt uitgevoerd. Zie ResourceManager hoge beschikbaarheid voor meer informatie over hoge beschikbaarheid van YARN ResourceManager.
HBase-master
HDInsight HBase-clusters ondersteunen hoge beschikbaarheid van HBase Master. In tegenstelling tot andere HA-services, die worden uitgevoerd op hoofdknooppunten, worden HBase Masters uitgevoerd op de drie Zookeeper-knooppunten, waarbij een van deze services de actieve master is en de andere twee stand-by zijn. Net als NameNode coördineert HBase Master met Apache Zookeeper voor leiderverkiezing en voert automatische failover uit wanneer de huidige actieve master problemen heeft. Er is maar één actieve HBase-master op elk gewenst moment.
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor