Clusterprestaties in Azure HDInsight bewaken
Het bewaken van de status en prestaties van een HDInsight-cluster is essentieel voor het behoud van optimale prestaties en resourcegebruik. Bewaking kan u ook helpen bij het detecteren en oplossen van clusterconfiguratiefouten en problemen met gebruikerscode.
In de volgende secties wordt beschreven hoe u de belasting van uw clusters, Apache Hadoop YARN-wachtrijen bewaakt en optimaliseert en problemen met opslagbeperking detecteert.
Hadoop-clusters kunnen de meest optimale prestaties leveren wanneer de belasting op het cluster gelijkmatig wordt verdeeld over alle knooppunten. Hierdoor kunnen de verwerkingstaken worden uitgevoerd zonder dat deze worden beperkt door RAM-, CPU- of schijfbronnen op afzonderlijke knooppunten.
Als u een algemeen overzicht wilt krijgen van de knooppunten van uw cluster en het laden ervan, meldt u zich aan bij de Ambari-webgebruikersinterface en selecteert u vervolgens het tabblad Hosts . Uw hosts worden vermeld door hun volledig gekwalificeerde domeinnamen. De operationele status van elke host wordt weergegeven met een gekleurde statusindicator:
| Color | Beschrijving |
|---|---|
| Rood | Ten minste één hoofdonderdeel op de host is offline. Beweeg de muisaanwijzer om knopinfo weer te geven waarin de betrokken onderdelen worden vermeld. |
| Orange | Ten minste één secundair onderdeel op de host is offline. Beweeg de muisaanwijzer om knopinfo weer te geven waarin de betrokken onderdelen worden vermeld. |
| Geel | Ambari Server heeft meer dan 3 minuten geen heartbeat van de host ontvangen. |
| Groen | Normale werkingsstatus. |
U ziet ook kolommen met het aantal kernen en de hoeveelheid RAM voor elke host, en het schijfgebruik en het gemiddelde van de belasting.
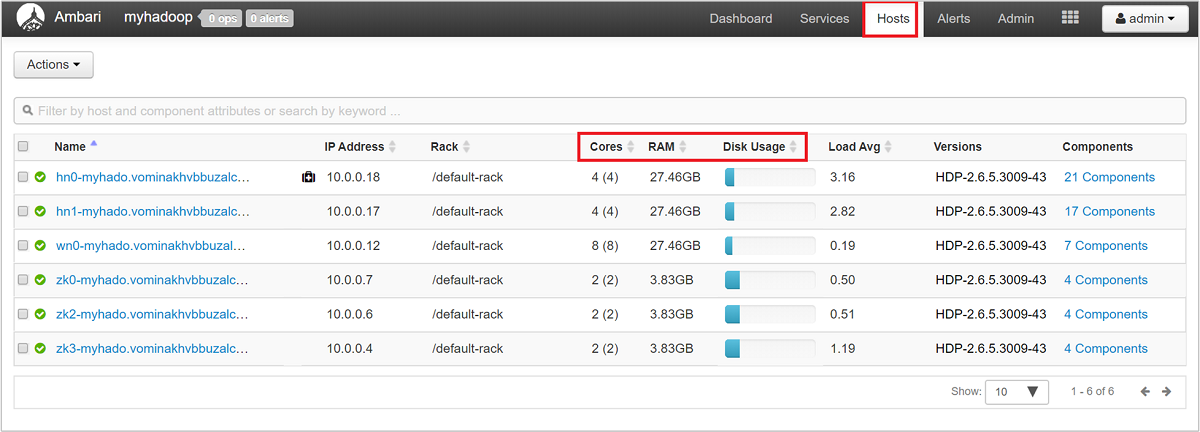
Selecteer een van de hostnamen voor een gedetailleerd overzicht van de onderdelen die op die host worden uitgevoerd en de bijbehorende metrische gegevens. De metrische gegevens worden weergegeven als een selecteerbare tijdlijn van CPU-gebruik, belasting, schijfgebruik, geheugengebruik, netwerkgebruik en het aantal processen.
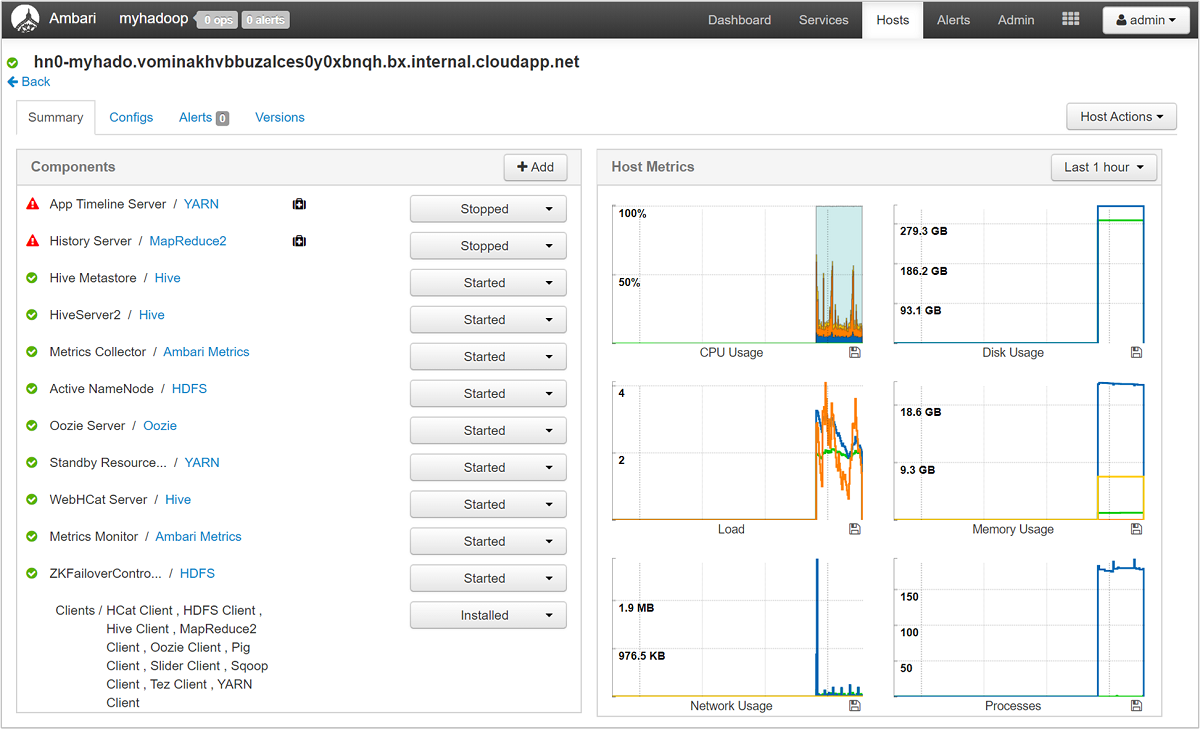
Zie HDInsight-clusters beheren met behulp van de Apache Ambari-webgebruikersinterface voor meer informatie over het instellen van waarschuwingen en het weergeven van metrische gegevens.
Hadoop heeft verschillende services die worden uitgevoerd op het gedistribueerde platform. YARN (Yet Another Resource Negotiator) coördineert deze services en wijst clusterresources toe om ervoor te zorgen dat elke belasting gelijkmatig over het cluster wordt verdeeld.
YARN verdeelt de twee verantwoordelijkheden van jobtracker, resourcebeheer en taakplanning/bewaking in twee daemons: een globale Resource Manager en een ApplicationMaster (AM) per toepassing.
Resource Manager is een pure scheduler en scheidt alleen beschikbare resources tussen alle concurrerende toepassingen. Resource Manager zorgt ervoor dat alle resources altijd in gebruik zijn en optimaliseren voor verschillende constanten, zoals SLA's, capaciteitsgaranties, enzovoort. ApplicationMaster onderhandelt over resources van Resource Manager en werkt samen met de NodeManager(s) om de containers en het resourceverbruik ervan uit te voeren en te bewaken.
Wanneer meerdere tenants een groot cluster delen, is er concurrentie voor de resources van het cluster. CapacityScheduler is een pluggable scheduler die helpt bij het delen van resources door aanvragen in de wachtrij te plaatsen. De CapacityScheduler ondersteunt ook hiërarchische wachtrijen om ervoor te zorgen dat resources worden gedeeld tussen de submappen van een organisatie, voordat wachtrijen van andere toepassingen gratis resources mogen gebruiken.
MET YARN kunnen we resources toewijzen aan deze wachtrijen en kunt u zien of al uw beschikbare resources zijn toegewezen. Als u informatie over uw wachtrijen wilt bekijken, meldt u zich aan bij de Ambari-webgebruikersinterface en selecteert u YARN Queue Manager in het bovenste menu.
Op de pagina YARN Queue Manager ziet u een lijst met uw wachtrijen aan de linkerkant, samen met het percentage capaciteit dat aan elke wachtrij is toegewezen.
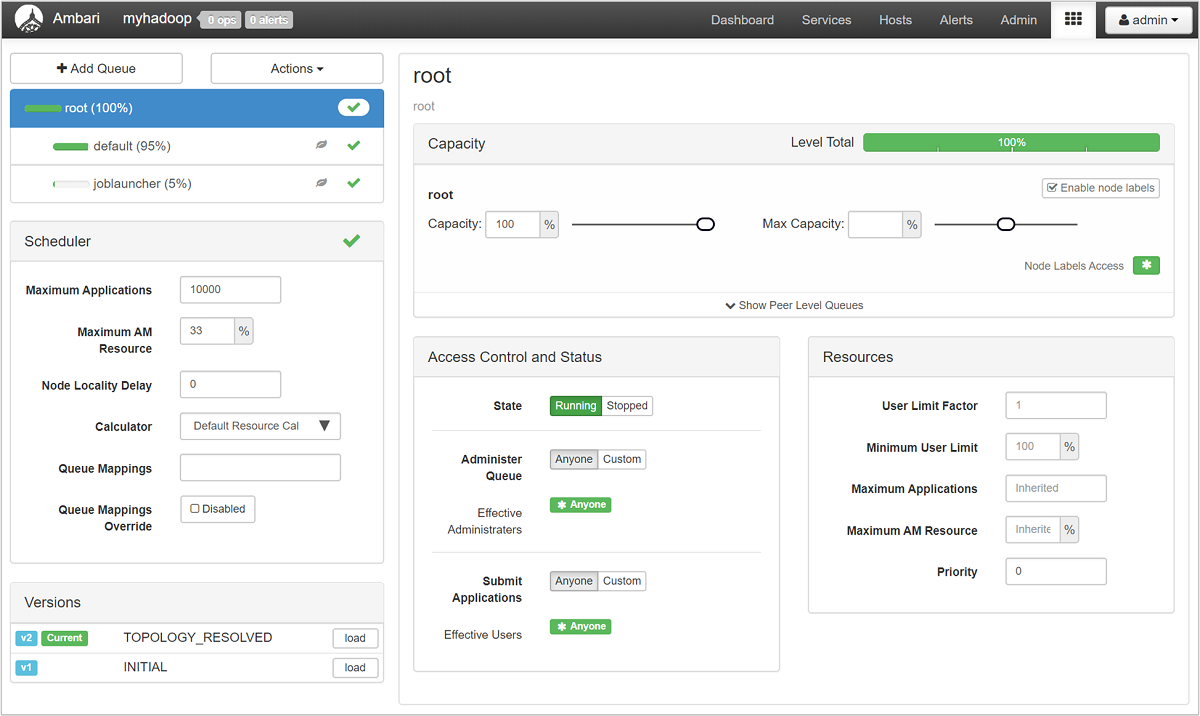
Voor een gedetailleerder overzicht van uw wachtrijen selecteert u in het Ambari-dashboard de YARN-service in de lijst aan de linkerkant. Selecteer vervolgens in het vervolgkeuzemenu Snelle koppelingen de Resource Manager-gebruikersinterface onder uw actieve knooppunt.
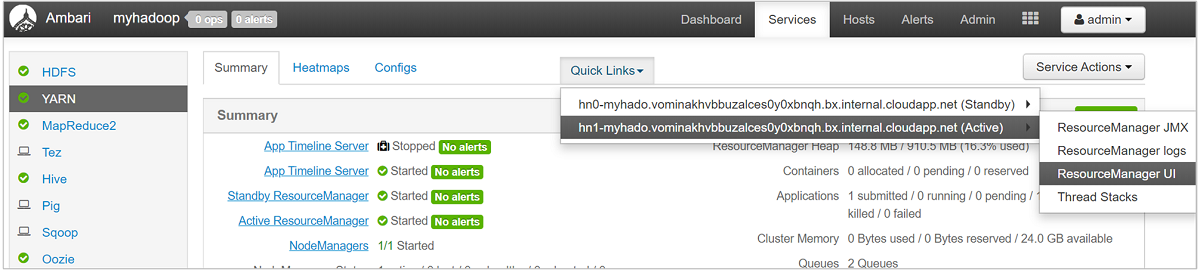
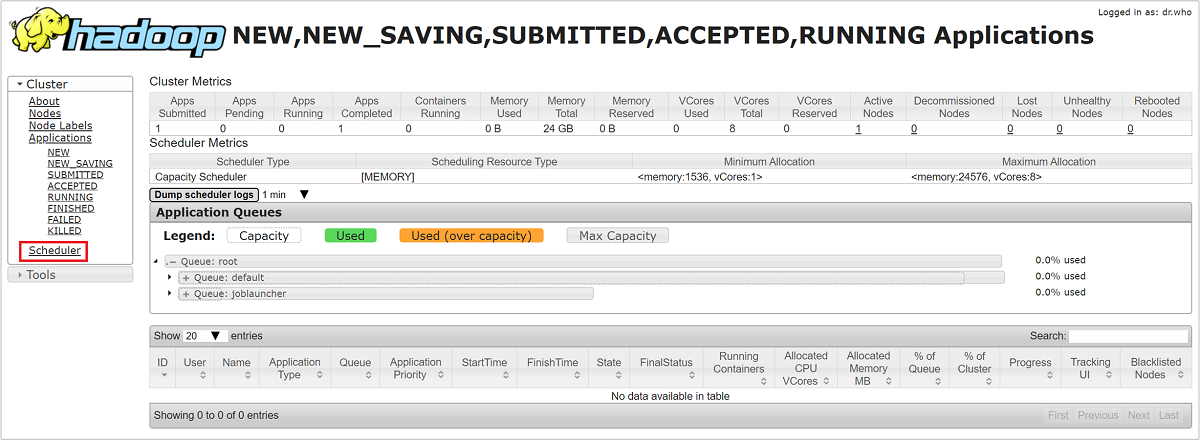
Selecteer Scheduler in de gebruikersinterface van Resource Manager in het menu aan de linkerkant. U ziet een lijst met uw wachtrijen onder Toepassingswachtrijen. Hier ziet u de capaciteit die wordt gebruikt voor elk van uw wachtrijen, hoe goed de taken ertussen worden verdeeld en of taken resourcebeperking hebben.
Het prestatieknelpunt van een cluster kan zich voordoen op opslagniveau. Dit type knelpunt wordt meestal veroorzaakt door blokkering van invoer-/uitvoerbewerkingen (IO), wat gebeurt wanneer uw actieve taken meer IO verzenden dan de opslagservice kan verwerken. Met deze blokkering wordt een wachtrij met IO-aanvragen gemaakt die moeten worden verwerkt totdat de huidige IOS zijn verwerkt. De blokken zijn vanwege opslagbeperking, wat geen fysieke limiet is, maar eerder een limiet die wordt opgelegd door de opslagservice door een SLA (Service Level Agreement). Deze limiet zorgt ervoor dat er geen enkele client of tenant de service kan verdoveren. De SLA beperkt het aantal IOS's per seconde (IOPS) voor Azure Storage. Zie schaalbaarheids- en prestatiedoelen voor standaardopslagaccounts voor meer informatie.
Als u Azure Storage gebruikt, raadpleegt u Controleren, diagnosticeren en problemen met Microsoft Azure Storage oplossen voor informatie over het bewaken van problemen met opslag, waaronder beperking.
Als het back-uparchief van uw cluster Azure Data Lake Storage (ADLS) is, is uw beperking waarschijnlijk vanwege bandbreedtelimieten. Beperking in dit geval kan worden geïdentificeerd door beperkingsfouten in taaklogboeken te observeren. Zie de sectie beperking voor de juiste service in deze artikelen voor ADLS:
- Richtlijnen voor het afstemmen van prestaties voor Apache Hive in HDInsight en Azure Data Lake Storage
- Richtlijnen voor het afstemmen van prestaties voor MapReduce in HDInsight en Azure Data Lake Storage
In sommige gevallen kan er sprake zijn van een traagheid vanwege onvoldoende schijfruimte op het cluster. Onderzoek met deze stappen:
Gebruik de ssh-opdracht om verbinding te maken met elk van de knooppunten.
Controleer het schijfgebruik door een van de volgende opdrachten uit te voeren:
df -h du -h --max-depth=1 / | sort -hControleer de uitvoer en controleer op de aanwezigheid van grote bestanden in de
mntmap of andere mappen. Normaal gesproken bevatten deusercachemappen enappcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) grote bestanden.Als er grote bestanden zijn, veroorzaakt een huidige taak de bestandsgroei of kan een mislukte vorige taak hebben bijgedragen aan dit probleem. Voer de volgende opdracht uit om te controleren of dit gedrag wordt veroorzaakt door een huidige taak:
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/Als met deze opdracht een specifieke taak wordt aangeduid, kunt u ervoor kiezen de taak te beëindigen met behulp van een opdracht die er ongeveer als volgt uitziet:
yarn application -kill -applicationId <application_id>Vervang door
application_idde toepassings-id. Als er geen specifieke taken worden aangeduid, gaat u naar de volgende stap.Nadat de bovenstaande opdracht is voltooid of als er geen specifieke taken zijn aangegeven, verwijdert u de grote bestanden die u hebt geïdentificeerd door een opdracht uit te voeren die er ongeveer als volgt uitziet:
rm -rf filecache usercache
Zie Onvoldoende schijfruimte voor meer informatie over problemen met schijfruimte.
Notitie
Als u grote bestanden hebt die u wilt behouden, maar die bijdragen aan het probleem met weinig schijfruimte, moet u uw HDInsight-cluster omhoog schalen en uw services opnieuw opstarten. Nadat u deze procedure hebt voltooid en enkele minuten hebt gewacht, ziet u dat de opslag is vrijgemaakt en dat de gebruikelijke prestaties van het knooppunt worden hersteld.
Ga naar de volgende koppelingen voor meer informatie over het oplossen van problemen en het bewaken van uw clusters: