Overzicht van Azure Storage in HDInsight
Azure Storage is een robuuste opslagoplossing voor algemeen gebruik die naadloos kan worden geïntegreerd met HDInsight. HDInsight kan een blobcontainer in Azure Storage gebruiken als het standaardbestandssysteem voor het cluster. Via een HDFS-interface kan de volledige set onderdelen in HDInsight rechtstreeks worden uitgevoerd op gestructureerde of ongestructureerde gegevens die zijn opgeslagen als blobs.
We raden u aan afzonderlijke opslagcontainers te gebruiken voor uw standaardclusteropslag en uw bedrijfsgegevens. De scheiding is het isoleren van de HDInsight-logboeken en tijdelijke bestanden van uw eigen bedrijfsgegevens. U wordt ook aangeraden de standaard-blobcontainer, die toepassings- en systeemlogboeken bevat, te verwijderen na elk gebruik om de opslagkosten te verlagen. Breng de logboeken over naar een andere locatie voordat u de container verwijdert.
Als u ervoor kiest om uw opslagaccount te beveiligen met de beperkingen voor firewalls en virtuele netwerken voor geselecteerde netwerken, moet u de uitzondering Vertrouwde Microsoft-services toestaan inschakelen.... De uitzondering hierop is dat HDInsight toegang heeft tot uw opslagaccount.
HDInsight-opslagarchitectuur
Het volgende diagram biedt een abstracte weergave van de HDInsight-architectuur van Azure Storage:
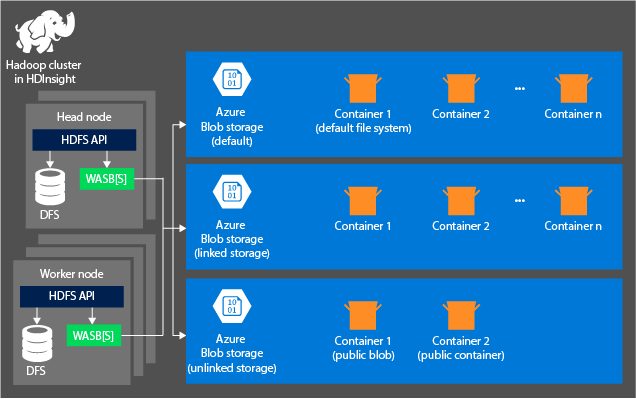
HDInsight biedt toegang tot het Distributed File System dat lokaal wordt gekoppeld aan de rekenknooppunten. Dit bestandssysteem is toegankelijk via de volledig gekwalificeerde URI, bijvoorbeeld:
hdfs://<namenodehost>/<path>
Via HDInsight hebt u ook toegang tot gegevens in Azure Storage. De syntaxis is als volgt:
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
Voor accounts met een hiërarchische naamruimte (Azure Data Lake Storage Gen2) is de syntaxis als volgt:
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
Houd rekening met de volgende principes bij het gebruik van een Azure Storage-account met HDInsight-clusters:
Containers in de opslagaccounts die zijn verbonden met een cluster: omdat de accountnaam en de sleutel tijdens het maken worden gekoppeld aan het cluster, hebt u volledige toegang tot de blobs in deze containers.
Openbare containers of openbare blobs in opslagaccounts die niet zijn verbonden met een cluster: u hebt alleen-lezenmachtigingen voor de blobs in de containers.
Notitie
Met openbare containers kunt u een lijst ophalen met alle blobs die beschikbaar zijn in die container en om containermetagegevens op te halen. Openbare blobs zijn alleen toegankelijk als u de exacte URL weet. Zie Anonieme leestoegang tot containers en blobs beheren voor meer informatie.
Privécontainers in opslagaccounts die niet zijn verbonden met een cluster: u hebt geen toegang tot de blobs in de containers, tenzij u het opslagaccount definieert wanneer u de WebHCat-taken verzendt.
De opslagaccounts die worden gedefinieerd tijdens het creatieproces en de bijbehorende sleutels worden opgeslagen in %HADOOP_HOME%/conf/core-site.xml op de clusterknooppunten. HDInsight maakt standaard gebruik van de opslagaccounts die zijn gedefinieerd in het core-site.xml-bestand. U kunt deze instelling wijzigen met behulp van Apache Ambari. Zie de volgende artikelen voor meer informatie over de instellingen van het opslagaccount die kunnen worden gewijzigd of in het core-site.xml-bestand worden geplaatst:
- Hadoop Azure-ondersteuning: Azure Blob Storage
- Hadoop Azure-ondersteuning: ABFS — Azure Data Lake Storage Gen2
Meerdere WebHCat-taken, waaronder Apache Hive. En MapReduce, Apache Hadoop-streaming en Apache Pig bevatten een beschrijving van opslagaccounts en metagegevens. (Dit aspect geldt momenteel voor Pig met opslagaccounts, maar niet voor metagegevens.) Zie Een HDInsight-cluster gebruiken met alternatieve opslagaccounts en metastores voor meer informatie.
Blobs kunnen worden gebruikt voor gestructureerde en ongestructureerde gegevens. Blobcontainers slaan gegevens op als sleutel-waardeparen en hebben geen maphiërarchie. De sleutelnaam kan echter een slash (/) bevatten, zodat deze wordt weergegeven alsof een bestand wordt opgeslagen in een mapstructuur. De sleutel van een blob kan bijvoorbeeld zijn input/log1.txt. Er bestaat geen werkelijke input map, maar vanwege het slash-teken in de sleutelnaam ziet de sleutel eruit als een bestandspad.
Voordelen van Azure Storage
Rekenclusters en opslagresources die niet zijn gekoppeld, hebben impliciete prestatiekosten. Deze kosten worden beperkt door de manier waarop de rekenclusters dicht bij de resources van het opslagaccount in de Azure-regio worden gemaakt. In deze regio hebben de rekenknooppunten efficiënt toegang tot de gegevens via het snelle netwerk in Azure Storage.
Wanneer u de gegevens opslaat in Azure Storage in plaats van HDFS, krijgt u verschillende voordelen:
Hergebruik en delen van gegevens: de gegevens in HDFS bevinden zich in het rekencluster. Alleen de toepassingen die toegang tot het rekencluster hebben, kunnen de gegevens met HDFS API's gebruiken. De gegevens in Azure Storage zijn daarentegen toegankelijk via de HDFS-API's of de REST API's van Blob Storage. Vanwege deze indeling kan een grotere set toepassingen (inclusief andere HDInsight-clusters) en hulpprogramma's worden gebruikt om de gegevens te produceren en te gebruiken.
Gegevensarchivering: wanneer gegevens worden opgeslagen in Azure Storage, kunnen de HDInsight-clusters die worden gebruikt voor berekeningen veilig worden verwijderd zonder dat gebruikersgegevens verloren gaan.
Kosten voor gegevensopslag: het opslaan van gegevens in DFS voor de lange termijn is duurder dan het opslaan van de gegevens in Azure Storage. Omdat de kosten van een rekencluster hoger zijn dan de kosten van Azure Storage. Omdat de gegevens niet opnieuw hoeven te worden geladen voor elke generatie van rekenclusters, bespaart u ook kosten voor het laden van gegevens.
Elastisch uitbreiden: hoewel HDFS u een uitgebreid bestandssysteem biedt, wordt de schaal bepaald door het aantal knooppunten dat u voor het cluster maakt. Het wijzigen van de schaal kan ingewikkelder zijn dan de elastische schaalmogelijkheden die u automatisch krijgt in Azure Storage.
Geo-replicatie: Uw Azure Storage kan geografisch worden gerepliceerd. Hoewel geo-replicatie u geografische herstel en gegevensredundantie biedt, is een failover naar de geo-gerepliceerde locatie ernstig van invloed op uw prestaties en kunnen er extra kosten in rekening worden gebracht. Kies dus voorzichtig geo-replicatie en alleen als de waarde van de gegevens de extra kosten rechtvaardigt.
Bepaalde MapReduce-taken en -pakketten kunnen tussenliggende resultaten maken die u niet wilt opslaan in Azure Storage. In dat geval kunt u ervoor kiezen om de gegevens op te slaan in de lokale HDFS. HDInsight gebruikt DFS voor verschillende van deze tussenliggende resultaten in Hive-taken en andere processen.
Notitie
De meeste HDFS-opdrachten (bijvoorbeeld ls, copyFromLocalen mkdir) werken zoals verwacht in Azure Storage. Alleen de opdrachten die specifiek zijn voor de systeemeigen HDFS-implementatie (die dfs wordt genoemd), zoals fschk en dfsadmin, geven verschillende gedragingen weer in Azure Storage.