Prestaties van Apache Spark-workloads verbeteren met behulp van Azure HDInsight IO Cache
Notitie
- IO Cache werd ondersteund tot Spark 2.3 en wordt niet ondersteund in Spark 2.4 (HDInsight 4.0) en Spark 3.1.2 (HDInsight 5.0)
IO Cache is een gegevenscacheservice voor Azure HDInsight waarmee de prestaties van Apache Spark-taken worden verbeterd. IO Cache werkt ook met Apache TEZ - en Apache Hive-workloads , die kunnen worden uitgevoerd op Apache Spark-clusters . IO Cache maakt gebruik van een opensource-cacheonderdeel met de naam RubiX. RubiX is een lokale schijfcache voor gebruik met big data-analyse-engines die toegang hebben tot gegevens van cloudopslagsystemen. RubiX is uniek in cachesystemen, omdat het SSD's (Solid-State Drives) gebruikt in plaats van het operationele geheugen te reserveren voor cachingdoeleinden. De IO Cache-service wordt gestart en beheert RubiX Metadata Servers op elk werkknooppunt van het cluster. Het configureert ook alle services van het cluster voor transparant gebruik van RubiX cache.
De meeste SCHIJVEN bieden meer dan 1 GByte per seconde bandbreedte. Deze bandbreedte, aangevuld met de in-memory bestandscache van het besturingssysteem, biedt voldoende bandbreedte voor het laden van verwerkingsengines voor big data, zoals Apache Spark. Het operationele geheugen blijft beschikbaar voor Apache Spark voor het verwerken van veel geheugenafhankelijke taken, zoals willekeurige volgordes. Met exclusief gebruik van het operationele geheugen kan Apache Spark optimaal resourcegebruik bereiken.
Notitie
IO Cache maakt momenteel gebruik van RubiX als cacheonderdeel, maar dit kan veranderen in toekomstige versies van de service. Gebruik IO Cache-interfaces en neem geen afhankelijkheden rechtstreeks op de RubiX-implementatie. IO Cache wordt momenteel alleen ondersteund met Azure BLOB Storage.
Voordelen van Azure HDInsight IO Cache
Het gebruik van IO Cache biedt een prestatieverhoging voor taken die gegevens lezen uit Azure Blob Storage.
U hoeft geen wijzigingen aan te brengen in uw Spark-taken om de prestaties te zien toenemen bij het gebruik van IO Cache. Wanneer IO Cache is uitgeschakeld, worden met deze Spark-code gegevens op afstand gelezen vanuit Azure Blob Storage: spark.read.load('wasbs:///myfolder/data.parquet').count(). Wanneer IO Cache wordt geactiveerd, zorgt dezelfde coderegel ervoor dat een in de cache gelezen wordt via IO Cache. Bij het volgen van leesbewerkingen worden de gegevens lokaal gelezen vanuit SSD. Werkknooppunten in HDInsight-cluster zijn uitgerust met lokaal gekoppelde, toegewezen SSD-stations. HDInsight IO Cache maakt gebruik van deze lokale HDD's voor caching, wat het laagste latentieniveau biedt en bandbreedte maximaliseert.
Aan de slag
Azure HDInsight IO Cache is standaard gedeactiveerd in preview. IO Cache is beschikbaar in Azure HDInsight 3.6+ Spark-clusters, waarop Apache Spark 2.3 wordt uitgevoerd. Voer de volgende stappen uit om IO Cache in HDInsight 4.0 te activeren:
Navigeer in een webbrowser naar
https://CLUSTERNAME.azurehdinsight.net, waarbijCLUSTERNAMEde naam van uw cluster is.Selecteer de IO Cache-service aan de linkerkant.
Selecteer Acties (serviceacties in HDI 3.6) en activeer deze.
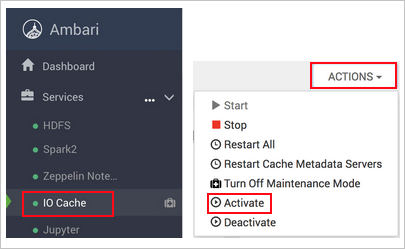
Bevestig het opnieuw opstarten van alle betrokken services op het cluster.
Notitie
Hoewel de voortgangsbalk is geactiveerd, wordt IO Cache pas daadwerkelijk ingeschakeld wanneer u de andere betrokken services opnieuw start.
Probleemoplossing
Mogelijk krijgt u fouten met schijfruimte bij het uitvoeren van Spark-taken na het inschakelen van IO Cache. Deze fouten treden op omdat Spark ook lokale schijfopslag gebruikt voor het opslaan van gegevens tijdens het opsnielen van bewerkingen. Spark kan onvoldoende SSD-ruimte hebben zodra IO Cache is ingeschakeld en de ruimte voor Spark-opslag wordt verminderd. De hoeveelheid ruimte die door IO Cache wordt gebruikt, wordt standaard ingesteld op de helft van de totale SSD-ruimte. Het schijfruimtegebruik voor IO Cache kan worden geconfigureerd in Ambari. Als er schijfruimtefouten optreden, vermindert u de hoeveelheid SSD-ruimte die wordt gebruikt voor IO Cache en start u de service opnieuw op. Ga als volgt te werk om de ruimteset voor IO Cache te wijzigen:
Selecteer in Apache Ambari de HDFS-service aan de linkerkant.
Selecteer de tabbladen Configuraties en Geavanceerd .
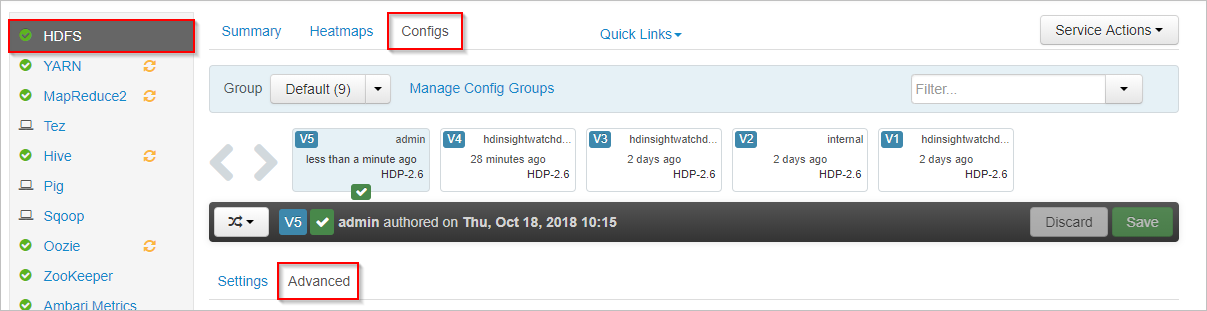
Schuif omlaag en vouw het gebied Aangepaste kernsite uit.
Zoek de eigenschap hadoop.cache.data.fullness.percentage.
Wijzig de waarde in het vak.
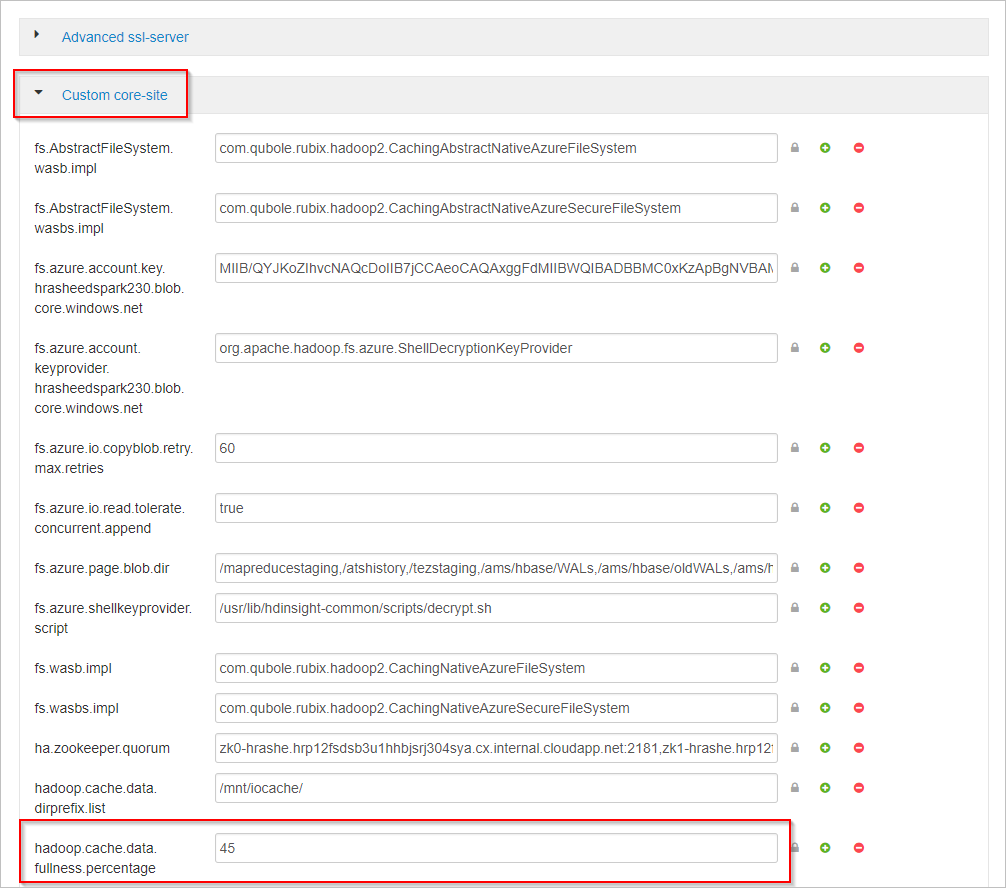
Selecteer Opslaan in de rechterbovenhoek.
Selecteer Opnieuw opstarten>alles opnieuw opstarten.

Selecteer Alles opnieuw opstarten bevestigen.
Als dat niet werkt, schakelt u IO Cache uit.
Volgende stappen
Lees meer over IO Cache, inclusief prestatiebenchmarks in dit blogbericht: Apache Spark-taken krijgen een snelheid van maximaal 9x met HDInsight IO Cache