Overzicht van Gestructureerde streaming van Apache Spark
Met Apache Spark Structured Streaming kunt u schaalbare, fouttolerante toepassingen met hoge doorvoer implementeren voor het verwerken van gegevensstromen. Structured Streaming is gebaseerd op de Spark SQL-engine en verbetert de constructies van Spark SQL Data Frames en Datasets, zodat u streamingquery's op dezelfde manier kunt schrijven als bij het schrijven van batchquery's.
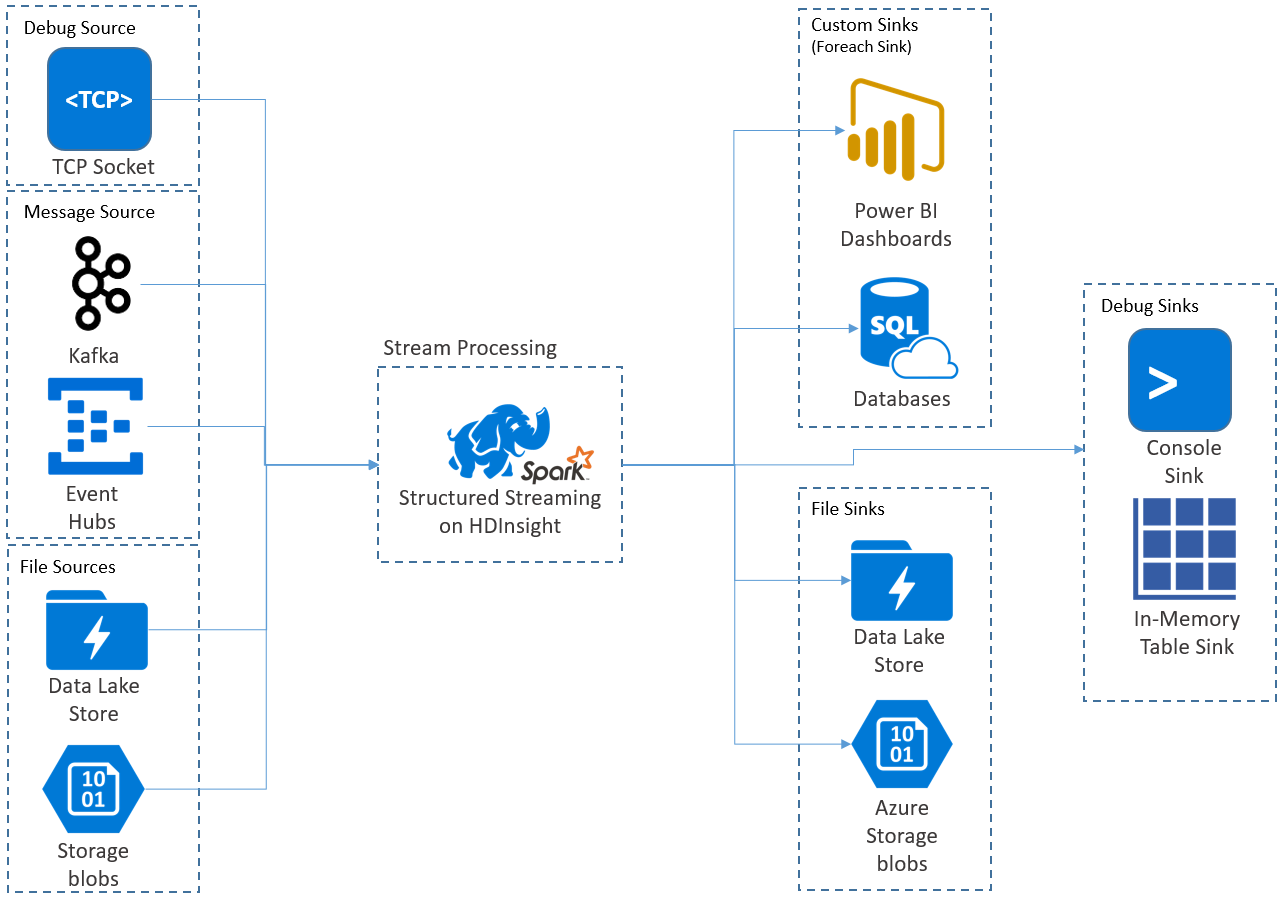
Gestructureerde streamingtoepassingen worden uitgevoerd op HDInsight Spark-clusters en maken verbinding met streaminggegevens van Apache Kafka, een TCP-socket (voor foutopsporing), Azure Storage of Azure Data Lake Storage. Met de laatste twee opties, die afhankelijk zijn van externe opslagservices, kunt u kijken naar nieuwe bestanden die zijn toegevoegd aan de opslag en de inhoud ervan verwerken alsof ze zijn gestreamd.
Structured Streaming maakt een langlopende query waarin u bewerkingen toepast op de invoergegevens, zoals selectie, projectie, aggregatie, vensters en het samenvoegen van het streaming DataFrame met referentie-DataFrames. Vervolgens voert u de resultaten uit naar bestandsopslag (Azure Storage-blobs of Data Lake Storage) of naar een gegevensarchief met behulp van aangepaste code (zoals SQL Database of Power BI). Structured Streaming biedt ook uitvoer naar de console voor het lokaal opsporen van fouten en naar een tabel in het geheugen, zodat u de gegevens kunt zien die zijn gegenereerd voor foutopsporing in HDInsight.
Notitie
Spark Structured Streaming vervangt Spark Streaming (DStreams). In de toekomst ontvangt Structured Streaming verbeteringen en onderhoud, terwijl DStreams zich alleen in de onderhoudsmodus bevindt. Structured Streaming is momenteel niet zo volledig als DStreams voor de bronnen en sinks die het ondersteunt, dus evalueer uw vereisten om de juiste Spark-stroomverwerkingsoptie te kiezen.
Streams als tabellen
Spark Structured Streaming vertegenwoordigt een gegevensstroom als een tabel die niet-afhankelijk is, dat wil gezegd, de tabel blijft groeien naarmate er nieuwe gegevens binnenkomen. Deze invoertabel wordt continu verwerkt door een langlopende query en de resultaten die naar een uitvoertabel worden verzonden:

In Structured Streaming komen gegevens binnen op het systeem en worden ze onmiddellijk opgenomen in een invoertabel. U schrijft query's (met behulp van dataframe- en gegevensset-API's) die bewerkingen uitvoeren op deze invoertabel. De queryuitvoer levert een andere tabel op, de resultatentabel. De resultatentabel bevat de resultaten van uw query, waaruit u gegevens tekent voor een extern gegevensarchief, zoals een relationele database. De timing van wanneer gegevens uit de invoertabel worden verwerkt, wordt bepaald door het triggerinterval. Standaard is het triggerinterval nul, dus Structured Streaming probeert de gegevens te verwerken zodra deze binnenkomen. In de praktijk betekent dit dat zodra Structured Streaming klaar is met het verwerken van de uitvoering van de vorige query, er een andere verwerkingsbewerking wordt gestart op nieuwe ontvangen gegevens. U kunt de trigger zo configureren dat deze met een interval wordt uitgevoerd, zodat de streaminggegevens worden verwerkt in batches op basis van tijd.
De gegevens in de resultatentabellen bevatten mogelijk alleen de gegevens die nieuw zijn sinds de laatste keer dat de query is verwerkt (toevoegmodus) of de tabel kan telkens worden vernieuwd wanneer er nieuwe gegevens zijn, zodat de tabel alle uitvoergegevens bevat sinds de streamingquery is gestart (volledige modus).
Toevoegmodus
In de toevoegmodus zijn alleen de rijen toegevoegd aan de resultatentabel omdat de laatste queryuitvoering aanwezig is in de resultatentabel en naar externe opslag zijn geschreven. Met de eenvoudigste query worden bijvoorbeeld alleen alle gegevens uit de invoertabel gekopieerd naar de resultatentabel, ongewijzigd. Telkens wanneer een triggerinterval is verstreken, worden de nieuwe gegevens verwerkt en worden de rijen weergegeven die aangeven dat nieuwe gegevens worden weergegeven in de resultatentabel.
Overweeg een scenario waarin u telemetrie van temperatuursensoren verwerkt, zoals een thermostaat. Stel dat de eerste trigger één gebeurtenis heeft verwerkt op het moment 00:01 voor apparaat 1 met een temperatuurleeswaarde van 95 graden. In de eerste trigger van de query wordt alleen de rij met tijd 00:01 weergegeven in de resultatentabel. Op het moment 00:02 wanneer een andere gebeurtenis binnenkomt, is de enige nieuwe rij de rij met tijd 00:02 en bevat de resultatentabel dus slechts die ene rij.
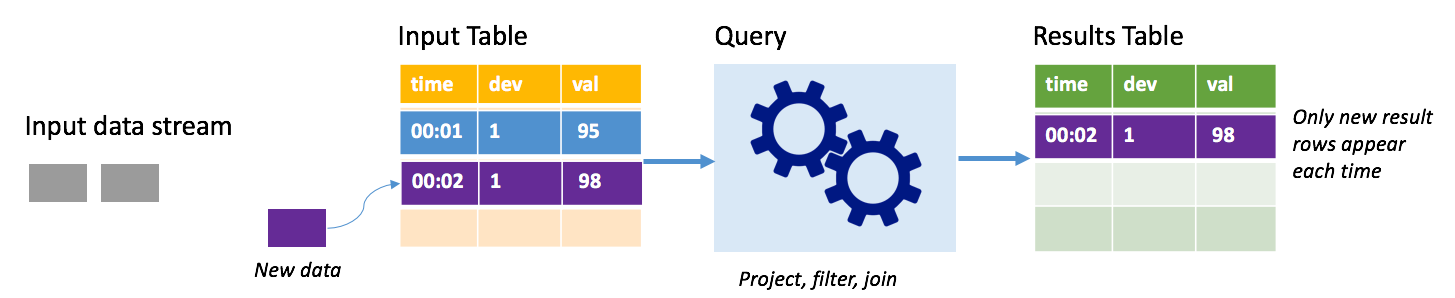
Wanneer u de toevoegmodus gebruikt, past uw query projecties toe (waarbij u de kolommen selecteert waar het om gaat), filteren (alleen rijen kiezen die voldoen aan bepaalde voorwaarden) of samenvoegen (de gegevens uitbreiden met gegevens uit een statische opzoektabel). Met de toevoegmodus kunt u eenvoudig alleen de relevante nieuwe gegevens naar externe opslag pushen.
Volledige modus
Houd rekening met hetzelfde scenario, deze keer met behulp van de volledige modus. In de volledige modus wordt de volledige uitvoertabel vernieuwd op elke trigger, zodat de tabel gegevens bevat die niet alleen afkomstig zijn van de meest recente triggeruitvoering, maar van alle uitvoeringen. U kunt de volledige modus gebruiken om de gegevens ongewijzigd van de invoertabel naar de resultatentabel te kopiëren. Bij elke geactiveerde uitvoering worden de nieuwe resultaatrijen samen met alle vorige rijen weergegeven. De tabel met uitvoerresultaten slaat uiteindelijk alle gegevens op die zijn verzameld sinds de query is gestart en u hebt uiteindelijk onvoldoende geheugen. De volledige modus is bedoeld voor gebruik met statistische query's die de binnenkomende gegevens op een bepaalde manier samenvatten, dus bij elke trigger wordt de resultatentabel bijgewerkt met een nieuwe samenvatting.
Stel dat er tot nu toe vijf seconden aan gegevens zijn verwerkt en dat het tijd is om de gegevens voor de zesde seconde te verwerken. De invoertabel bevat gebeurtenissen voor tijd 00:01 en tijd 00:03. Het doel van deze voorbeeldquery is om de gemiddelde temperatuur van het apparaat om de vijf seconden te geven. Bij de implementatie van deze query wordt een aggregatie toegepast die alle waarden gebruikt die binnen elk venster van 5 seconden vallen, de temperatuur gemiddelden en een rij produceert voor de gemiddelde temperatuur gedurende dat interval. Aan het einde van het eerste venster van 5 seconden zijn er twee tuples: (00:01, 1, 95) en (00:03, 1, 98). Voor het venster 00:00-00:05 produceert de aggregatie dus een tuple met de gemiddelde temperatuur van 96,5 graden. In het volgende venster van 5 seconden is er slechts één gegevenspunt op het moment 00:06, dus de resulterende gemiddelde temperatuur is 98 graden. Op tijd 00:10, met behulp van de volledige modus, bevat de resultatentabel de rijen voor zowel Windows 00:00-00:05 als 00:05-00:10 omdat de query alle samengevoegde rijen uitvoert, niet alleen de nieuwe rijen. Daarom blijft de resultatentabel groeien naarmate er nieuwe vensters worden toegevoegd.
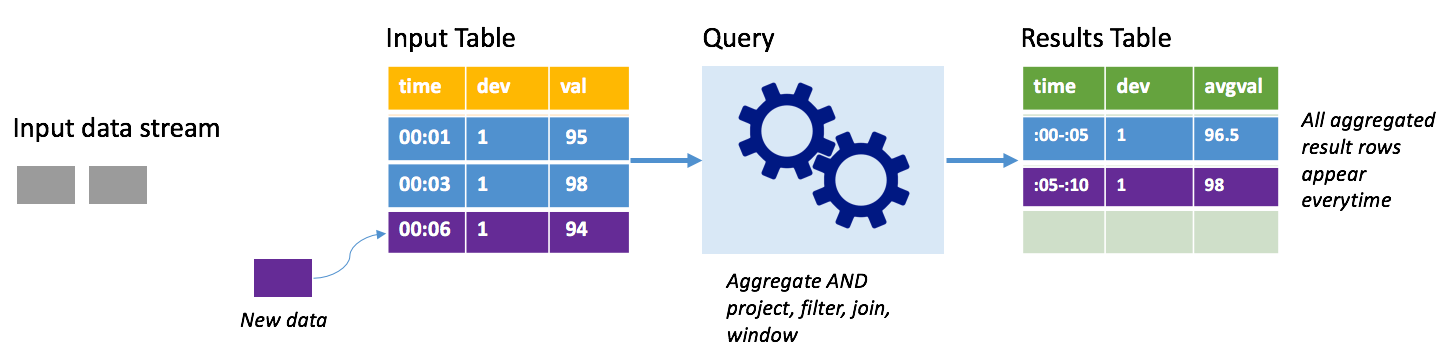
Niet alle query's die de volledige modus gebruiken, zorgen ervoor dat de tabel zonder grenzen groeit. Houd in het vorige voorbeeld rekening met het gemiddelde van de temperatuur per tijdvenster, maar in plaats daarvan op apparaat-id. De resultaattabel bevat een vast aantal rijen (één per apparaat) met de gemiddelde temperatuur voor het apparaat voor alle gegevenspunten die van dat apparaat zijn ontvangen. Wanneer er nieuwe temperaturen worden ontvangen, wordt de resultatentabel bijgewerkt, zodat de gemiddelden in de tabel altijd actueel zijn.
Onderdelen van een Spark Structured Streaming-toepassing
Met een eenvoudige voorbeeldquery kunt u de temperatuurmetingen per uurvensters samenvatten. In dit geval worden de gegevens opgeslagen in JSON-bestanden in Azure Storage (gekoppeld als de standaardopslag voor het HDInsight-cluster):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
Deze JSON-bestanden worden opgeslagen in de temps submap onder de container van het HDInsight-cluster.
De invoerbron definiëren
Configureer eerst een DataFrame dat de bron van de gegevens en eventuele instellingen beschrijft die voor die bron zijn vereist. In dit voorbeeld worden de JSON-bestanden in Azure Storage opgehaald en wordt er een schema op toegepast tijdens het lezen.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
De query toepassen
Pas vervolgens een query toe die de gewenste bewerkingen bevat voor het Streaming DataFrame. In dit geval groepeert een aggregatie alle rijen in vensters van 1 uur en berekent vervolgens de minimum-, gemiddelde- en maximumtemperatuur in dat venster van 1 uur.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
De uitvoersink definiëren
Definieer vervolgens de bestemming voor de rijen die binnen elk triggerinterval aan de resultatentabel worden toegevoegd. In dit voorbeeld worden alleen alle rijen uitgevoerd naar een tabel in het geheugen temps die u later kunt opvragen met SparkSQL. De volledige uitvoermodus zorgt ervoor dat alle rijen voor alle vensters elke keer worden uitgevoerd.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
De query starten
Start de streamingquery en voer deze uit totdat er een beëindigingssignaal wordt ontvangen.
val query = streamingOutDF.start()
De resultaten bekijken
Terwijl de query wordt uitgevoerd, kunt u in dezelfde SparkSession een SparkSQL-query uitvoeren op de temps tabel waarin de queryresultaten worden opgeslagen.
select * from temps
Deze query levert resultaten op die vergelijkbaar zijn met de volgende:
| Venster | min(temp) | avg(temp) | max(temp) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
Zie de Apache Spark Structured Streaming Programming Guide voor meer informatie over de Spark Structured Stream-API, samen met de invoergegevensbronnen, bewerkingen en uitvoersinks die worden ondersteund.
Controlepunten en logboeken voor write-ahead
Om tolerantie en fouttolerantie te bieden, is Structured Streaming afhankelijk van controlepunten om ervoor te zorgen dat de stroomverwerking ononderbroken kan worden voortgezet, zelfs met knooppuntfouten. In HDInsight maakt Spark controlepunten voor duurzame opslag, Azure Storage of Data Lake Storage. Deze controlepunten slaan de voortgangsgegevens over de streamingquery op. Daarnaast maakt Structured Streaming gebruik van een write-ahead-logboek (WAL). De WAL legt opgenomen gegevens vast die zijn ontvangen maar nog niet zijn verwerkt door een query. Als er een fout optreedt en de verwerking opnieuw wordt gestart vanuit de WAL, gaan alle gebeurtenissen die van de bron worden ontvangen, niet verloren.
Spark Streaming-toepassingen implementeren
Doorgaans bouwt u een Spark Streaming-toepassing lokaal in een JAR-bestand en implementeert u deze vervolgens in Spark in HDInsight door het JAR-bestand te kopiëren naar de standaardopslag die is gekoppeld aan uw HDInsight-cluster. U kunt uw toepassing starten met de Apache Livy REST API's die beschikbaar zijn in uw cluster met behulp van een POST-bewerking. De hoofdtekst van de POST bevat een JSON-document dat het pad naar uw JAR biedt, de naam van de klasse waarvan de hoofdmethode de streamingtoepassing definieert en uitvoert, en eventueel de resourcevereisten van de taak (zoals het aantal uitvoerders, geheugen en kernen) en eventuele configuratie-instellingen die uw toepassingscode vereist.
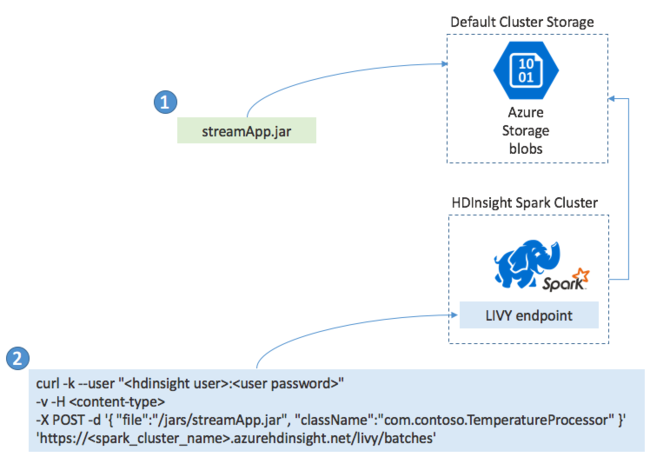
De status van alle toepassingen kan ook worden gecontroleerd met een GET-aanvraag voor een LIVY-eindpunt. Ten slotte kunt u een actieve toepassing beëindigen door een DELETE-aanvraag uit te geven op het LIVY-eindpunt. Zie Externe taken met Apache LIVY voor meer informatie over de LIVY-API
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor