Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Belangrijk
Deze pagina bevat instructies voor het beheren van Azure IoT Operations-onderdelen met behulp van Kubernetes-implementatiemanifesten, die zich in PREVIEW bevinden. Deze functie is voorzien van verschillende beperkingen en mag niet worden gebruikt voor productieworkloads.
Raadpleeg de Aanvullende voorwaarden voor Microsoft Azure-previews voor juridische voorwaarden die van toepassing zijn op Azure-functies die in bèta of preview zijn of die anders nog niet algemeen beschikbaar zijn.
Met optionele transformaties is een gegevensstroom het pad dat gegevens van de bron naar de bestemming neemt. U kunt de gegevensstroom configureren door een aangepaste gegevensstroomresource te maken of door de webinterface van Operations Experience te gebruiken. Een gegevensstroom bestaat uit drie delen: de bron, de transformatie en de bestemming.

Als u de bron en het doel wilt definiëren, moet u de eindpunten voor de gegevensstroom configureren. De transformatie is optioneel en kan bewerkingen bevatten, zoals het verrijken van de gegevens, het filteren van de gegevens en het toewijzen van de gegevens aan een ander veld.
Belangrijk
Elke gegevensstroom moet het standaardeindpunt van de lokale MQTT-broker van Azure IoT Operations hebben als de bron of het doel.
U kunt de bewerkingservaring in Azure IoT-bewerkingen gebruiken om een gegevensstroom te maken. De bewerkingservaring biedt een visuele interface voor het configureren van de gegevensstroom. U kunt bicep ook gebruiken om een gegevensstroom te maken met behulp van een Bicep-bestand of Kubernetes gebruiken om een gegevensstroom te maken met behulp van een YAML-bestand.
Lees verder voor meer informatie over het configureren van de bron, transformatie en bestemming.
Vereisten
U kunt gegevensstromen implementeren zodra u een exemplaar van Azure IoT Operations hebt met behulp van het standaardgegevensstroomprofiel en -eindpunt. Mogelijk wilt u echter gegevensstroomprofielen en -eindpunten configureren om de gegevensstroom aan te passen.
Gegevensstroomprofiel
Als u geen andere schaalinstellingen voor uw gegevensstromen nodig hebt, gebruikt u het standaardgegevensstroomprofiel dat wordt geleverd door Azure IoT Operations. Vermijd het koppelen van te veel gegevensstromen aan één gegevensstroomprofiel. Als u een groot aantal gegevensstromen hebt, distribueert u deze over meerdere gegevensstroomprofielen om het risico te beperken dat de configuratielimiet van het gegevensstroomprofiel wordt overschreden van 70.
Zie Gegevensstroomprofielen configureren voor meer informatie over het configureren van een nieuw gegevensstroomprofiel.
Eindpunten voor gegevensstroom
Eindpunten voor gegevensstromen zijn vereist om de bron en het doel voor de gegevensstroom te configureren. Als u snel aan de slag wilt gaan, kunt u het standaardeindpunt voor de gegevensstroom voor de lokale MQTT-broker gebruiken. U kunt ook andere typen eindpunten voor gegevensstromen maken, zoals Kafka, Event Hubs, OpenTelemetry of Azure Data Lake Storage. Zie Eindpunten voor gegevensstromen configureren voor meer informatie over het configureren van elk type gegevensstroomeindpunt.
Aan de slag
Zodra u aan de vereisten voldoet, kunt u beginnen met het maken van een gegevensstroom.
Als u een gegevensstroom wilt maken in de bewerkingservaring, selecteert u Gegevensstroom>Gegevensstroom Maken.
Selekteer de tijdelijke naam nieuwe gegevensstroom om de eigenschappen van de gegevensstroom in te stellen. Voer de naam van de gegevensstroom in en kies het gegevensstroomprofiel dat u wilt gebruiken. Het standaardprofiel voor gegevensstromen is standaard geselecteerd. Zie Gegevensstroomprofiel configureren voor meer informatie over gegevensstroomprofielen.
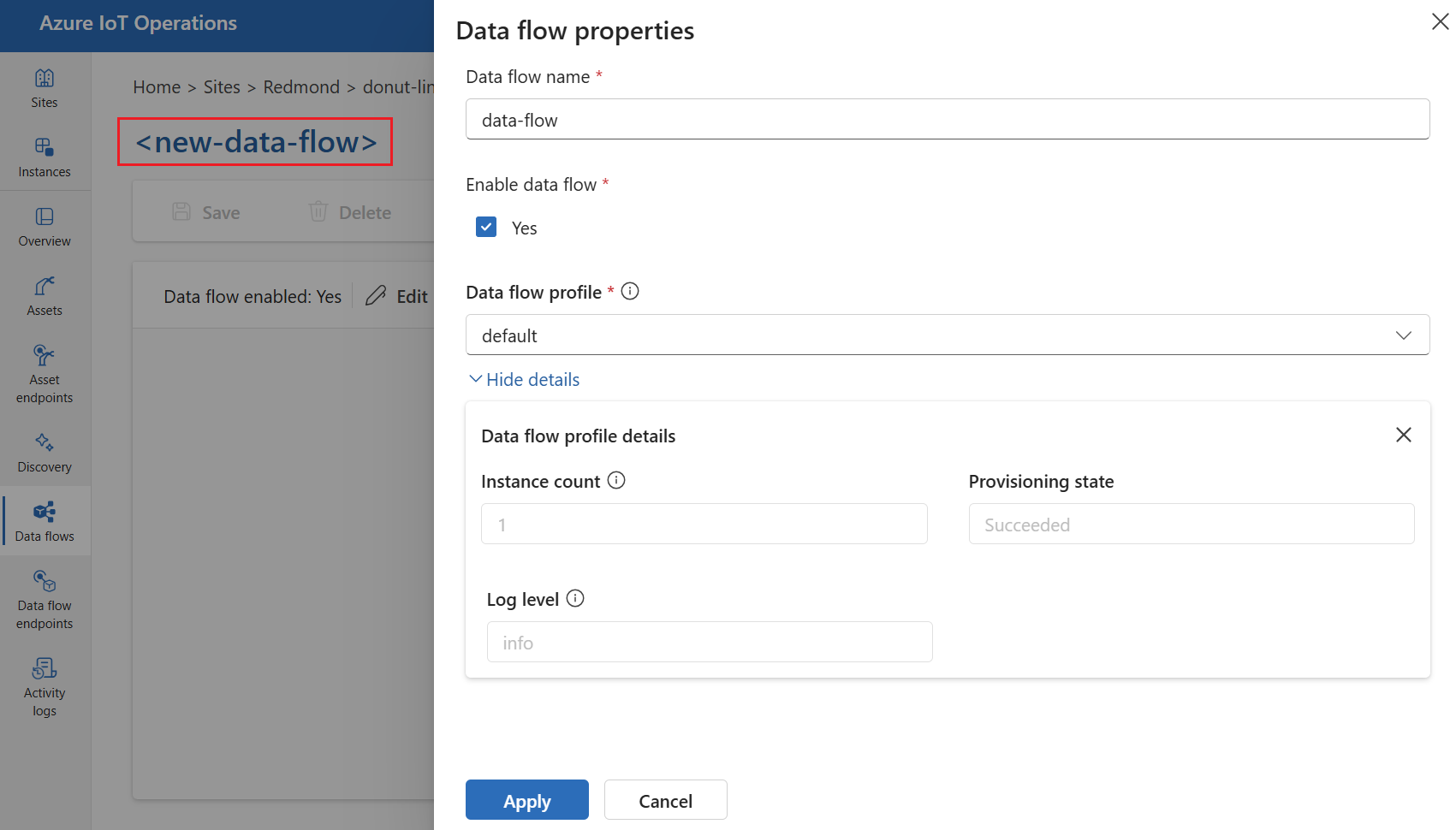
Belangrijk
U kunt alleen het gegevensstroomprofiel kiezen bij het maken van een gegevensstroom. U kunt het gegevensstroomprofiel niet wijzigen nadat de gegevensstroom is gemaakt. Als u het gegevensstroomprofiel van een bestaande gegevensstroom wilt wijzigen, verwijdert u de oorspronkelijke gegevensstroom en maakt u een nieuw gegevensstroomprofiel met het nieuwe gegevensstroomprofiel.
Configureer het bron-, transformatie- en doeleindpunt voor de gegevensstroom door de items in het gegevensstroomdiagram te selecteren.
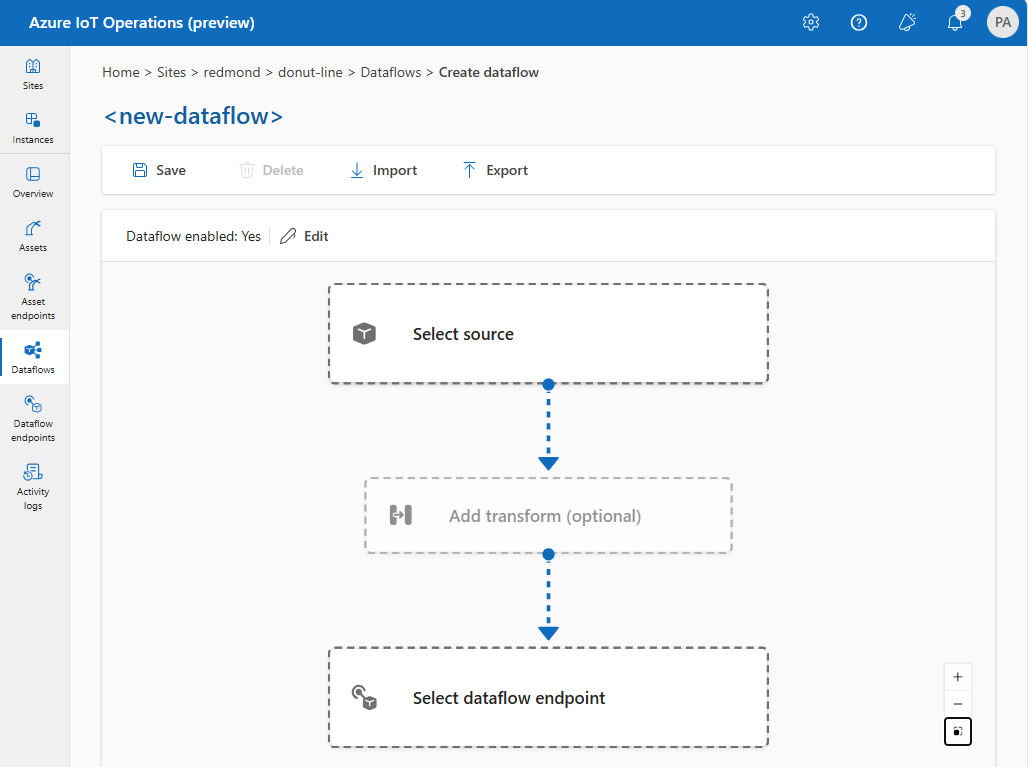
Bekijk de volgende secties voor meer informatie over het configureren van de bewerkingstypen van de gegevensstroom.
Bron
Als u een bron voor de gegevensstroom wilt configureren, geeft u de eindpuntreferentie en een lijst met gegevensbronnen voor het eindpunt op. Kies een van de volgende opties als bron voor de gegevensstroom.
Als het standaardeindpunt niet als bron wordt gebruikt, moet het als doel worden gebruikt. Zie Gegevensstromen moeten gebruikmaken van het lokale MQTT-brokereindpunt voor meer informatie over het gebruik van het lokale MQTT-brokereindpunt.
Optie 1: Standaardeindpunt voor berichtbroker gebruiken als bron
Selecteer onder Brondetails de optie Berichtbroker.
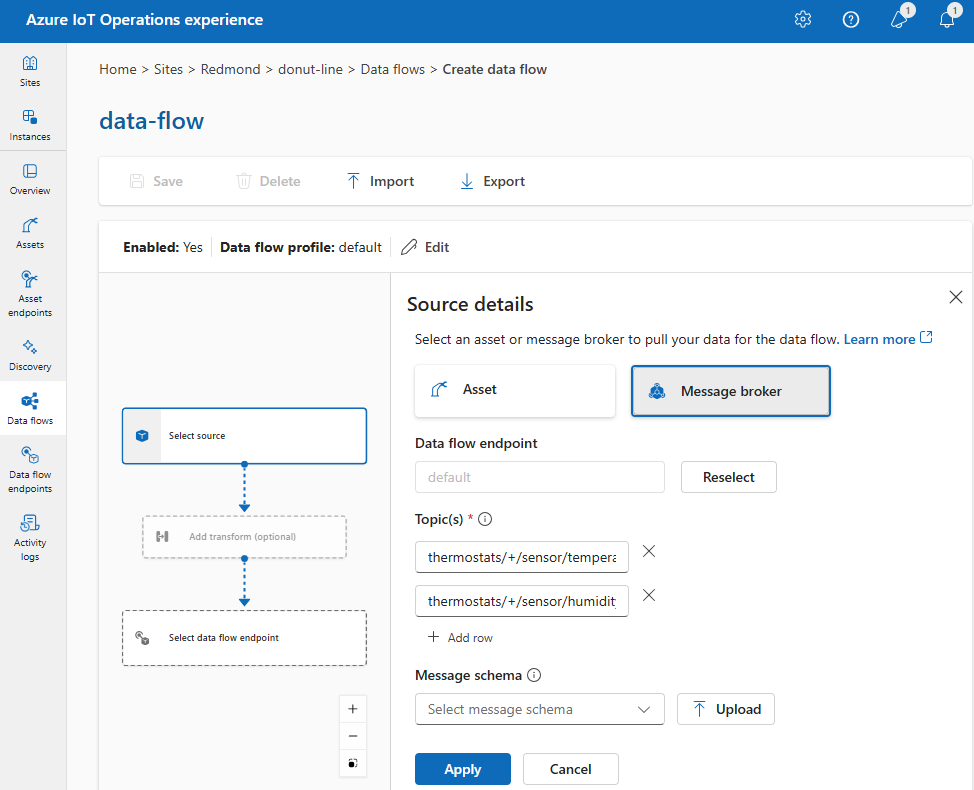
Voer de volgende instellingen in voor de berichtbrokerbron:
Instelling Beschrijving Eindpunt van gegevensstroom Selecteer de standaardwaarde om het standaardeindpunt van de MQTT-berichtbroker te gebruiken. Onderwerp Het onderwerpfilter waarop u zich wilt abonneren voor binnenkomende berichten. Gebruik onderwerp(en)> Rij toevoegen om meerdere onderwerpen toe te voegen. Zie MQTT- of Kafka-onderwerpen configureren voor meer informatie over onderwerpen. Berichtschema Het schema dat moet worden gebruikt om de binnenkomende berichten te deserialiseren. Zie Schema opgeven om gegevens te deserialiseren. Selecteer Toepassen.
Omdat dataSources u MQTT- of Kafka-onderwerpen kunt opgeven zonder de eindpuntconfiguratie te wijzigen, kunt u het eindpunt opnieuw gebruiken voor meerdere gegevensstromen, zelfs als de onderwerpen verschillend zijn. Zie Gegevensbronnen configureren voor meer informatie.
Optie 2: Asset als bron gebruiken
U kunt een asset gebruiken als de bron voor de gegevensstroom. Het gebruik van een asset als bron is alleen beschikbaar in de bewerkingservaring.
Selecteer Asset onder Brondetails.
Selecteer de asset die u wilt gebruiken als het broneindpunt.
Selecteer Doorgaan.
Er wordt een lijst met gegevenspunten voor de geselecteerde asset weergegeven.
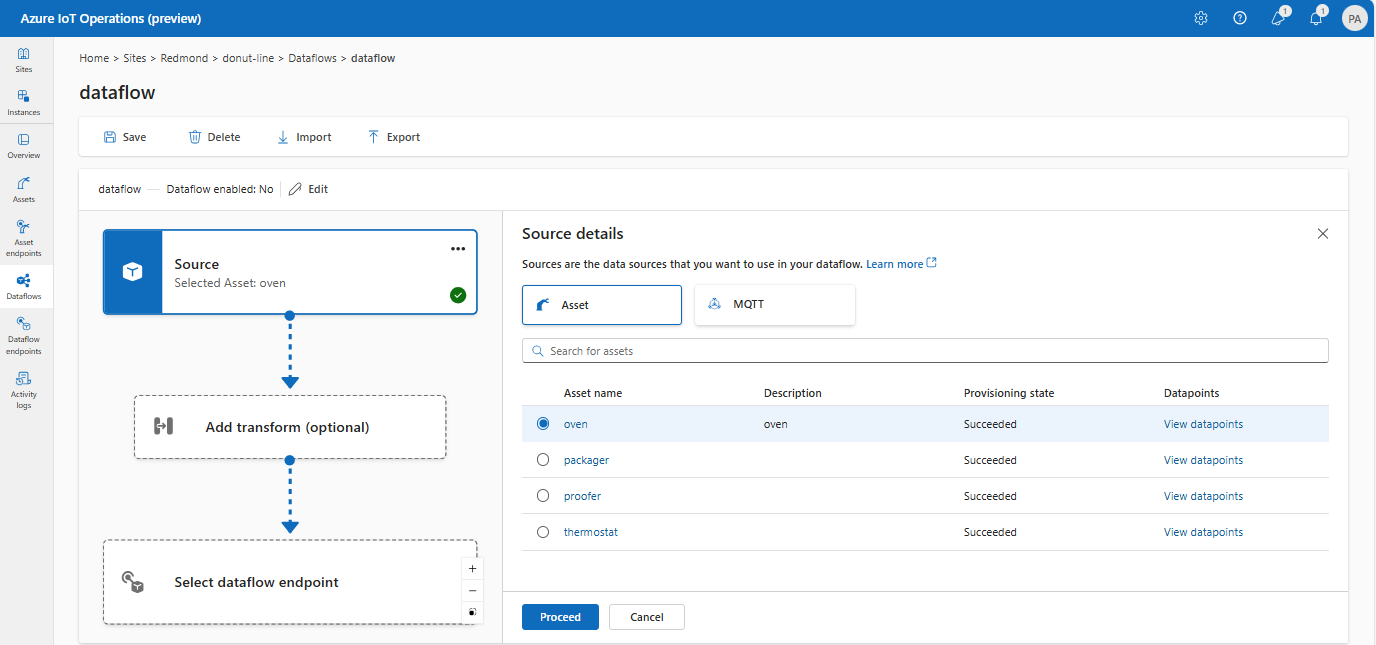
Selecteer Toepassen om de asset als broneindpunt te gebruiken.
Wanneer u een asset als bron gebruikt, wordt de assetdefinitie gebruikt om het schema voor de gegevensstroom af te leiden. De assetdefinitie bevat het schema voor de gegevenspunten van de asset. Zie Assetconfiguraties op afstand beheren voor meer informatie.
Zodra het systeem is geconfigureerd, bereiken de gegevens van de asset de gegevensstroom via de lokale MQTT-broker. Wanneer u dus een asset als bron gebruikt, gebruikt de gegevensstroom het standaardeindpunt van de lokale MQTT-broker als de bron in werkelijkheid.
Optie 3: Aangepast MQTT- of Kafka-gegevensstroomeindpunt als bron gebruiken
Als u een aangepast MQTT- of Kafka-gegevensstroomeindpunt hebt gemaakt (bijvoorbeeld voor gebruik met Event Grid of Event Hubs), kunt u dit gebruiken als bron voor de gegevensstroom. Houd er rekening mee dat eindpunten van het opslagtype, zoals Data Lake of Fabric OneLake, niet als bron kunnen worden gebruikt.
Selecteer onder Brondetails de optie Berichtbroker.

Voer de volgende instellingen in voor de berichtbrokerbron:
Instelling Beschrijving Eindpunt van gegevensstroom Gebruik de knop Opnieuw selecteren om een aangepast MQTT- of Kafka-gegevensstroomeindpunt te selecteren. Zie MQTT-gegevensstroomeindpunten configureren of Azure Event Hubs en Kafka-gegevensstroomeindpunten configureren voor meer informatie. Onderwerp Het onderwerpfilter waarop u zich wilt abonneren voor binnenkomende berichten. Gebruik onderwerp(en)> Rij toevoegen om meerdere onderwerpen toe te voegen. Zie MQTT- of Kafka-onderwerpen configureren voor meer informatie over onderwerpen. Berichtschema Het schema dat moet worden gebruikt om de binnenkomende berichten te deserialiseren. Zie Schema opgeven om gegevens te deserialiseren. Selecteer Toepassen.
Gegevensbronnen (MQTT- of Kafka-onderwerpen) configureren
U kunt meerdere MQTT- of Kafka-onderwerpen in een bron opgeven zonder de configuratie van het gegevensstroomeindpunt te hoeven wijzigen. Deze flexibiliteit betekent dat hetzelfde eindpunt opnieuw kan worden gebruikt voor meerdere gegevensstromen, zelfs als de onderwerpen verschillen. Zie voor meer informatie Hergebruik gegevensstroom-eindpunten.
MQTT-onderwerpen
Wanneer de bron een MQTT-eindpunt is, inclusief Event Grid, kunt u de MQTT-topicfilter gebruiken om u te abonneren op binnenkomende berichten. Het onderwerpfilter kan jokertekens bevatten om u te abonneren op meerdere onderwerpen. Bijvoorbeeld, thermostats/+/sensor/temperature/# abonneert zich op alle berichten van temperatuursensoren van thermostaten. De MQTT-onderwerpfilters configureren:
Selecteer in de gegevensstroom van bron Informatie de Bericht broker, en gebruik vervolgens het veld Onderwerp(en) om de MQTT-onderwerpfilters op te geven waarop u zich wilt abonneren voor binnenkomende berichten. U kunt meerdere MQTT-onderwerpen toevoegen door rij toevoegen te selecteren en een nieuw onderwerp in te voeren.
Gedeelde abonnementen
Als u gedeelde abonnementen wilt gebruiken met berichtenbrokerbronnen, kunt u het onderwerp van het gedeelde abonnement opgeven in de vorm van $shared/<GROUP_NAME>/<TOPIC_FILTER>.
Gebruik in de gegevensstroom voor operationele ervaring Details van bron de Message broker en het veld Onderwerp om de gedeelde abonnementsgroep en het onderwerp op te geven.
Als het aantal exemplaren in het gegevensstroomprofiel groter is dan één, wordt het gedeelde abonnement automatisch ingeschakeld voor alle gegevensstromen die gebruikmaken van een berichtenbrokerbron. In dit geval wordt het $shared voorvoegsel toegevoegd en wordt automatisch de naam van de gedeelde abonnementsgroep gegenereerd. Als u bijvoorbeeld een gegevensstroomprofiel hebt met het aantal exemplaren van 3 en uw gegevensstroom een berichtbrokereindpunt gebruikt als bron die is geconfigureerd met onderwerpen topic1 en topic2, worden deze automatisch geconverteerd naar gedeelde abonnementen als $shared/<GENERATED_GROUP_NAME>/topic1 en $shared/<GENERATED_GROUP_NAME>/topic2.
U kunt expliciet een onderwerp maken met de naam $shared/mygroup/topic in uw configuratie. Het toevoegen van het $shared onderwerp wordt echter niet expliciet aanbevolen, omdat het $shared voorvoegsel automatisch wordt toegevoegd wanneer dat nodig is. Gegevensstromen kunnen optimalisaties maken met de groepsnaam als deze niet is ingesteld. Is bijvoorbeeld $share niet ingesteld en gegevensstromen hoeven alleen te worden uitgevoerd via de onderwerpnaam.
Belangrijk
Gegevensstromen waarvoor een gedeeld abonnement is vereist wanneer het aantal exemplaren groter is dan één, is belangrijk bij het gebruik van Event Grid MQTT Broker als bron, omdat het geen ondersteuning biedt voor gedeelde abonnementen. Als u ontbrekende berichten wilt voorkomen, stelt u het aantal exemplaren van het gegevensstroomprofiel in op één wanneer u Event Grid MQTT-broker als bron gebruikt. Dit is het geval wanneer de gegevensstroom fungeert als abonnee en berichten ontvangt van de cloud.
Kafka-onderwerpen
Wanneer de bron een Kafka-eindpunt (opgenomen Event Hubs) is, geeft u de afzonderlijke Kafka-onderwerpen op waarop u zich wilt abonneren voor binnenkomende berichten. Jokertekens worden niet ondersteund, dus u moet elk onderwerp statisch opgeven.
Notitie
Wanneer u Event Hubs via het Kafka-eindpunt gebruikt, is elke afzonderlijke Event Hub binnen de naamruimte het Kafka-onderwerp. Als u bijvoorbeeld een Event Hubs-naamruimte met twee Event Hubs-hubs thermostats hebt en humidifiersu kunt elke Event Hub opgeven als een Kafka-onderwerp.
De Kafka-onderwerpen configureren:
In de gegevensstroom van de bewerkingservaring Brongegevens, selecteer Berichtbroker en gebruik vervolgens het veld Onderwerp om het Kafka-onderwerpfilter op te geven waarop u zich wilt abonneren voor binnenkomende berichten.
Notitie
Er kan slechts één onderwerpfilter worden opgegeven in de bewerkingservaring. Als u meerdere onderwerpfilters wilt gebruiken, gebruikt u Bicep of Kubernetes.
Bronschema opgeven
Wanneer u MQTT of Kafka als bron gebruikt, kunt u een schema opgeven om de lijst met gegevenspunten in de webgebruikersinterface van de operations-ervaring weer te geven. Het gebruik van een schema om binnenkomende berichten te deserialiseren en valideren, wordt momenteel niet ondersteund.
Als de bron een asset is, wordt het schema automatisch afgeleid van de assetdefinitie.
Aanbeveling
Als u het schema wilt genereren op basis van een voorbeeldgegevensbestand, gebruikt u de Helper voor Schema Gen.
Het schema configureren dat wordt gebruikt om de binnenkomende berichten van een bron te deserialiseren:
Selecteer in de ervaring met gegevensstroom, Broninformatie, de optie Berichtbroker en gebruik het Berichtschema veld om het schema op te geven. U kunt de knop Uploaden gebruiken om eerst een schemabestand te uploaden. Zie Berichtschema's begrijpen voor meer informatie.
Zie Berichtschema's begrijpen voor meer informatie.
Schijfpersistentie aanvragen
Door schijfpersistentie aan te vragen, kunnen gegevensstromen de status behouden bij opnieuw opstarten. Wanneer u deze functie inschakelt, herstelt de grafiek de verwerkingsstatus als de verbonden broker opnieuw wordt opgestart. Deze functie is handig voor stateful verwerkingsscenario's waarbij het verlies van tussenliggende gegevens een probleem is. Wanneer u schijfpersistentie aanvraagt, bewaart de broker de MQTT-gegevens, zoals berichten in de wachtrij voor abonnees, op schijf. Deze aanpak zorgt ervoor dat de gegevensbron van uw gegevensstroom geen gegevens verliest tijdens stroomstoringen of dat broker opnieuw wordt opgestart. De broker onderhoudt optimale prestaties omdat persistentie per gegevensstroom is geconfigureerd, dus alleen de gegevensstromen die persistentie nodig hebben, gebruiken deze functie.
De gegevensstroomgrafiek vraagt deze persistentie tijdens het abonnement aan met behulp van een MQTTv5-gebruikerseigenschap. Deze functie werkt alleen wanneer:
- De gegevensstroom maakt gebruik van de MQTT-broker of asset als de bron
- De MQTT-broker heeft persistentie ingeschakeld met dynamische persistentiemodus ingesteld op
Enabledvoor het gegevenstype, zoals abonneewachtrijen
Met deze configuratie kunnen MQTT-clients, zoals gegevensstromen, schijfpersistentie voor hun abonnementen aanvragen met behulp van MQTTv5-gebruikerseigenschappen. Zie MQTT-brokerpersistentie configureren voor meer informatie over de configuratie van MQTT-brokerpersistentie.
De instelling accepteert Enabled of Disabled.
Disabled is de standaardwaarde.
Wanneer u een gegevensstroom maakt of bewerkt, selecteert u Bewerken en selecteert u Vervolgens Ja naast Persistentie van gegevens aanvragen.
Transformatie
Met de transformatiebewerking kunt u de gegevens van de bron transformeren voordat u deze naar de bestemming verzendt. Transformaties zijn optioneel. Als u geen wijzigingen in de gegevens hoeft aan te brengen, neemt u de transformatiebewerking niet op in de configuratie van de gegevensstroom. Meerdere transformaties worden in fasen gekoppeld, ongeacht de volgorde waarin ze zijn opgegeven in de configuratie. De volgorde van de fasen is altijd:
- Verrijken: voeg aanvullende gegevens toe aan de brongegevens op basis van een gegevensset en voorwaarde die overeenkomen.
- Filter: Filter de gegevens op basis van een voorwaarde.
- Een nieuwe eigenschap toewijzen, berekenen, hernoemen of toevoegen: verplaats gegevens van het ene veld naar het andere met een optionele conversie.
Deze sectie is een inleiding tot gegevensstroomtransformaties. Zie Kaartgegevens met behulp van gegevensstromen, Gegevens converteren met behulp van gegevensstroomconversies en Gegevens verrijken met behulp van gegevensstromen voor meer gedetailleerde informatie.
Selecteer in de bewerkingservaring de optie Gegevensstroom>Transformatie toevoegen (optioneel).
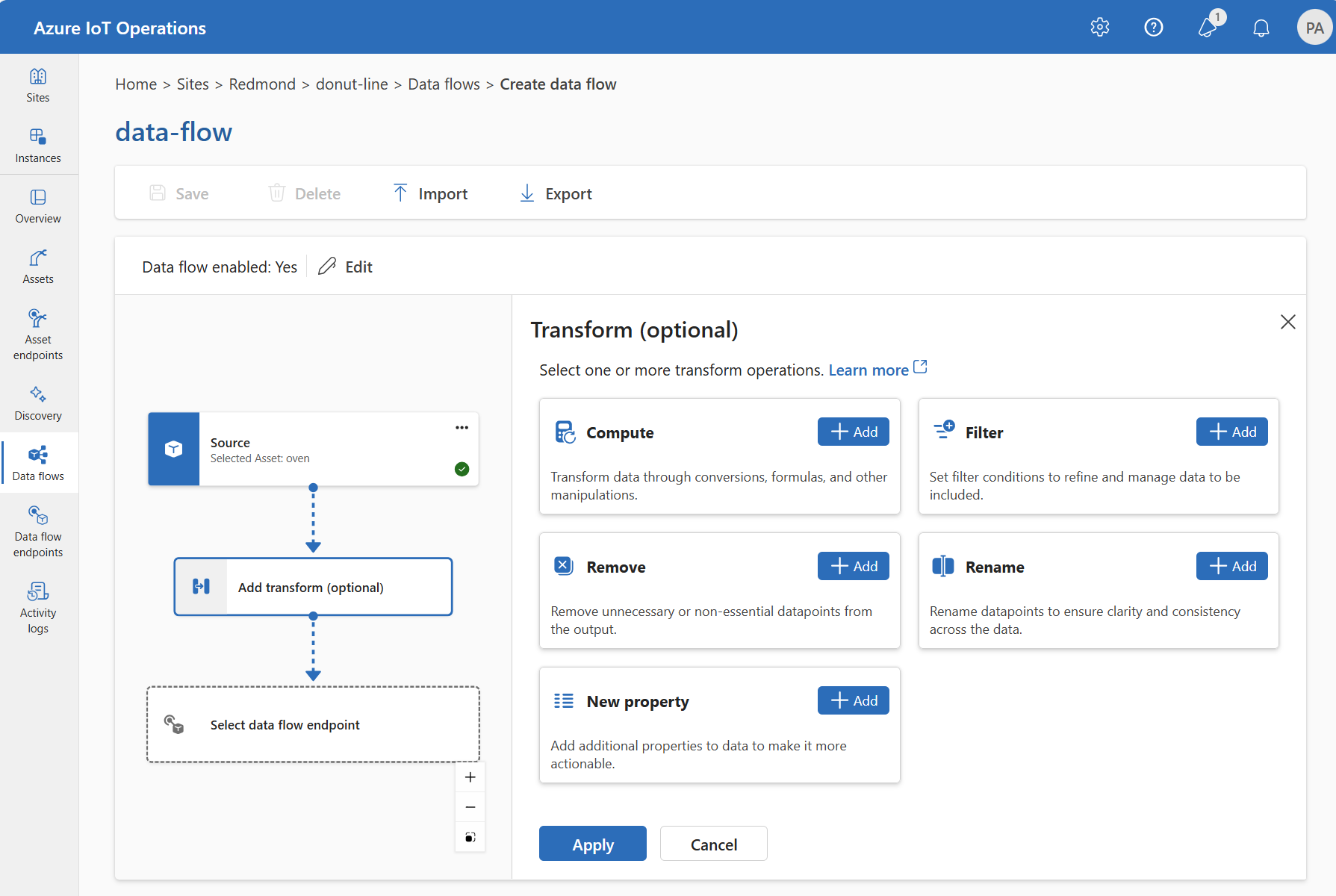
Verrijken: Referentiegegevens toevoegen
Als u de gegevens wilt verrijken, voegt u eerst een referentiegegevensset toe in het azure IoT Operations-statusarchief. De gegevensset wordt gebruikt om extra gegevens toe te voegen aan de brongegevens op basis van een voorwaarde. De voorwaarde wordt opgegeven als een veld in de brongegevens die overeenkomen met een veld in de gegevensset.
U kunt voorbeeldgegevens in het statusarchief laden met behulp van de statusarchief-CLI. Sleutelnamen in het statusarchief komen overeen met een gegevensset in de configuratie van de gegevensstroom.
Momenteel wordt de verrijkingsfase niet ondersteund in de bewerkingservaring.
Als de gegevensset een record met het asset veld heeft, vergelijkbaar met:
{
"asset": "thermostat1",
"location": "room1",
"manufacturer": "Contoso"
}
De gegevens van de bron waarbij het deviceId-veld overeenkomt met thermostat1, hebben de location- en manufacturer-velden beschikbaar in de filter- en kaartstadia.
Zie Gegevens verrijken met behulp van gegevensstromen en gegevens converteren met behulp van gegevensstromen en gegevens converteren met behulp van gegevensstromen voor meer informatie over de syntaxis van voorwaarden.
Filter: Gegevens filteren op basis van een voorwaarde
Als u de gegevens op een voorwaarde wilt filteren, kunt u de filter fase gebruiken. De voorwaarde wordt opgegeven als een veld in de brongegevens die overeenkomen met een waarde.
Selecteer Onder Transformeren (optioneel) de optie Filter>toevoegen.

Voer de vereiste instellingen in.
Instelling Beschrijving Filtervoorwaarde De voorwaarde om de gegevens te filteren op basis van een veld in de brongegevens. Beschrijving Geef een beschrijving op voor de filtervoorwaarde. Typ
@of selecteer Ctrl + Spatie in het filtervoorwaarde-veld om datapunten in een vervolgkeuzelijst te kiezen.U kunt MQTT-metagegevenseigenschappen invoeren met behulp van de indeling
@$metadata.user_properties.<property>of@$metadata.topic. U kunt ook $metadata headers invoeren met behulp van de indeling@$metadata.<header>. De$metadatasyntaxis is alleen nodig voor MQTT-eigenschappen die deel uitmaken van de berichtkop. Zie veldverwijzingen voor meer informatie.De voorwaarde kan de velden in de brongegevens gebruiken. U kunt bijvoorbeeld een filtervoorwaarde gebruiken, zoals
@temperature > 20het filteren van gegevens kleiner dan of gelijk aan 20 op basis van het temperatuurveld.Selecteer Toepassen.
Kaart: Gegevens van het ene veld naar het andere verplaatsen
Als u de gegevens wilt toewijzen aan een ander veld met optionele conversie, kunt u de map bewerking gebruiken. De conversie wordt opgegeven als een formule die gebruikmaakt van de velden in de brongegevens.
In de operatie-ervaring wordt mapping momenteel ondersteund met de transformaties Compute, Hernoemen, en Nieuwe eigenschap.
Berekenen
U kunt de compute-transformatie gebruiken om een formule toe te passen op de brongegevens. Deze bewerking wordt gebruikt om een formule toe te passen op de brongegevens en het resultaatveld op te slaan.
Onder Transformeren (optioneel), selecteer Compute>Add.
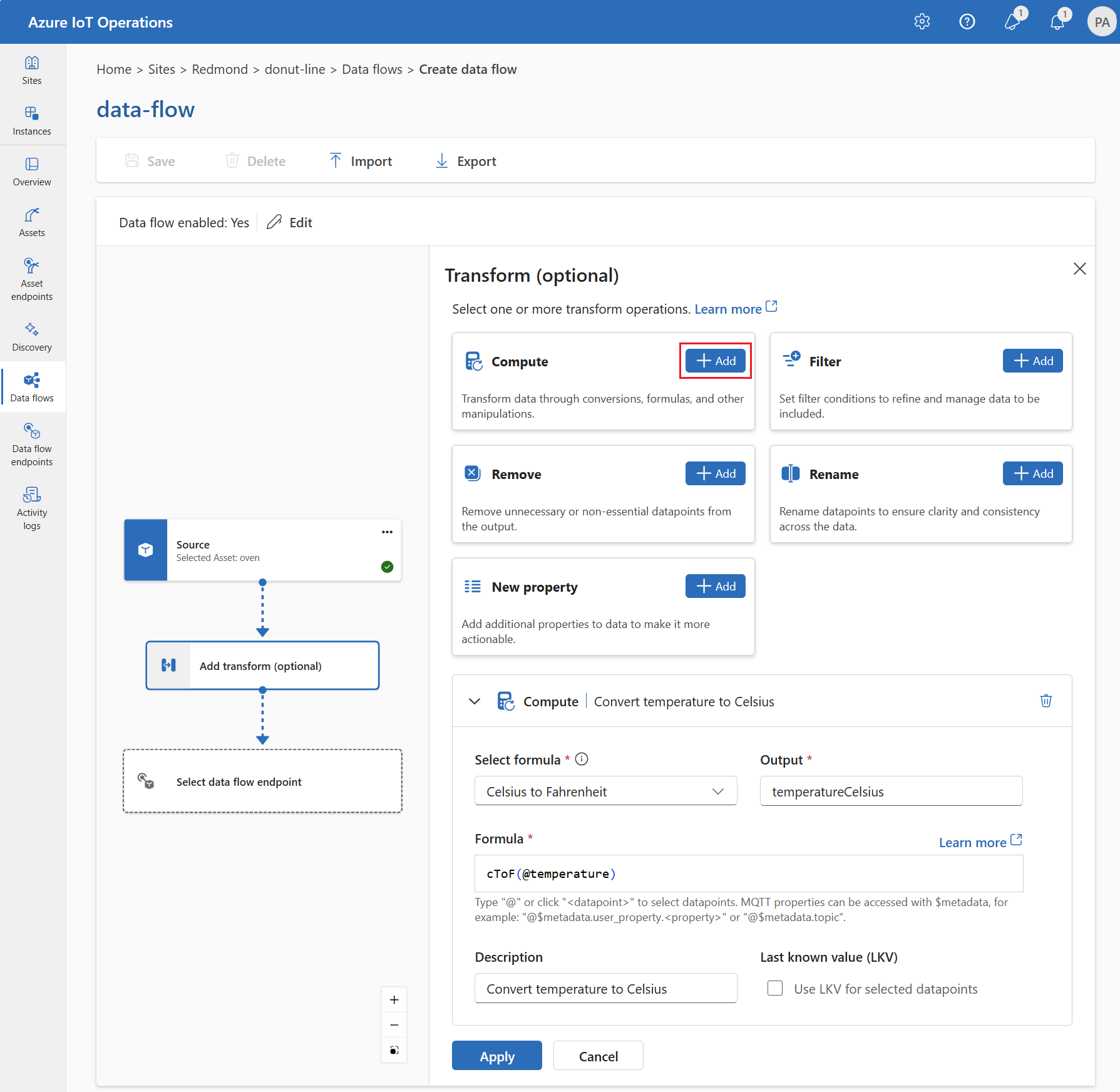
Voer de vereiste instellingen in.
Instelling Beschrijving Formule selecteren Kies een bestaande formule in de vervolgkeuzelijst of selecteer Aangepast om handmatig een formule in te voeren. Uitvoer Geef de uitvoerweergavenaam op, voor het resultaat. Formule Voer de formule in die moet worden toegepast op de brongegevens. Beschrijving Geef een beschrijving op voor de transformatie. Laatst bekende waarde Gebruik eventueel de laatst bekende waarde als de huidige waarde niet beschikbaar is. U kunt een formule invoeren of bewerken in het veld Formule . De formule kan de velden in de brongegevens gebruiken. Typ
@of selecteer Ctrl+ spatiebalk om gegevenspunten te kiezen in een vervolgkeuzelijst. Voor ingebouwde formules selecteert u de<dataflow>tijdelijke aanduiding om de lijst met beschikbare gegevenspunten weer te geven.U kunt MQTT-metagegevenseigenschappen invoeren met behulp van de indeling
@$metadata.user_properties.<property>of@$metadata.topic. U kunt ook $metadata headers invoeren met behulp van de indeling@$metadata.<header>. De$metadatasyntaxis is alleen nodig voor MQTT-eigenschappen die deel uitmaken van de berichtkop. Zie veldverwijzingen voor meer informatie.De formule kan de velden in de brongegevens gebruiken. U kunt bijvoorbeeld het
temperatureveld in de brongegevens gebruiken om de temperatuur naar Celsius te converteren en op te slaan in hettemperatureCelsiusuitvoerveld.Selecteer Toepassen.
Naam wijzigen
U kunt de naam van een gegevenspunt wijzigen met behulp van de transformatie Naam wijzigen . Deze bewerking wordt gebruikt om de naam van een gegevenspunt in de brongegevens te wijzigen in een nieuwe naam. De nieuwe naam kan worden gebruikt in de volgende fasen van de gegevensstroom.
Onder Transformeren (optioneel) selecteer Naam wijzigen> en Toevoegen.

Voer de vereiste instellingen in.
Instelling Beschrijving Gegevenspunt Selecteer een gegevenspunt in de vervolgkeuzelijst of voer een $metadata koptekst in. Nieuwe gegevenspuntnaam Voer de nieuwe naam in voor het gegevenspunt. Beschrijving Geef een beschrijving op voor de transformatie. U kunt MQTT-metagegevenseigenschappen invoeren met behulp van de indeling
@$metadata.user_properties.<property>of@$metadata.topic. U kunt ook $metadata headers invoeren met behulp van de indeling@$metadata.<header>. De$metadatasyntaxis is alleen nodig voor MQTT-eigenschappen die deel uitmaken van de berichtkop. Zie veldverwijzingen voor meer informatie.Selecteer Toepassen.
Nieuwe eigenschap
U kunt met behulp van de Nieuwe eigenschap-transformatie een nieuwe eigenschap toevoegen aan de brongegevens. Deze bewerking wordt gebruikt om een nieuwe eigenschap toe te voegen aan de brongegevens. De nieuwe eigenschap kan worden gebruikt in de volgende fasen van de gegevensstroom.
Selecteer onder Transformeren (optioneel) de optie Nieuwe eigenschap>Toevoegen.
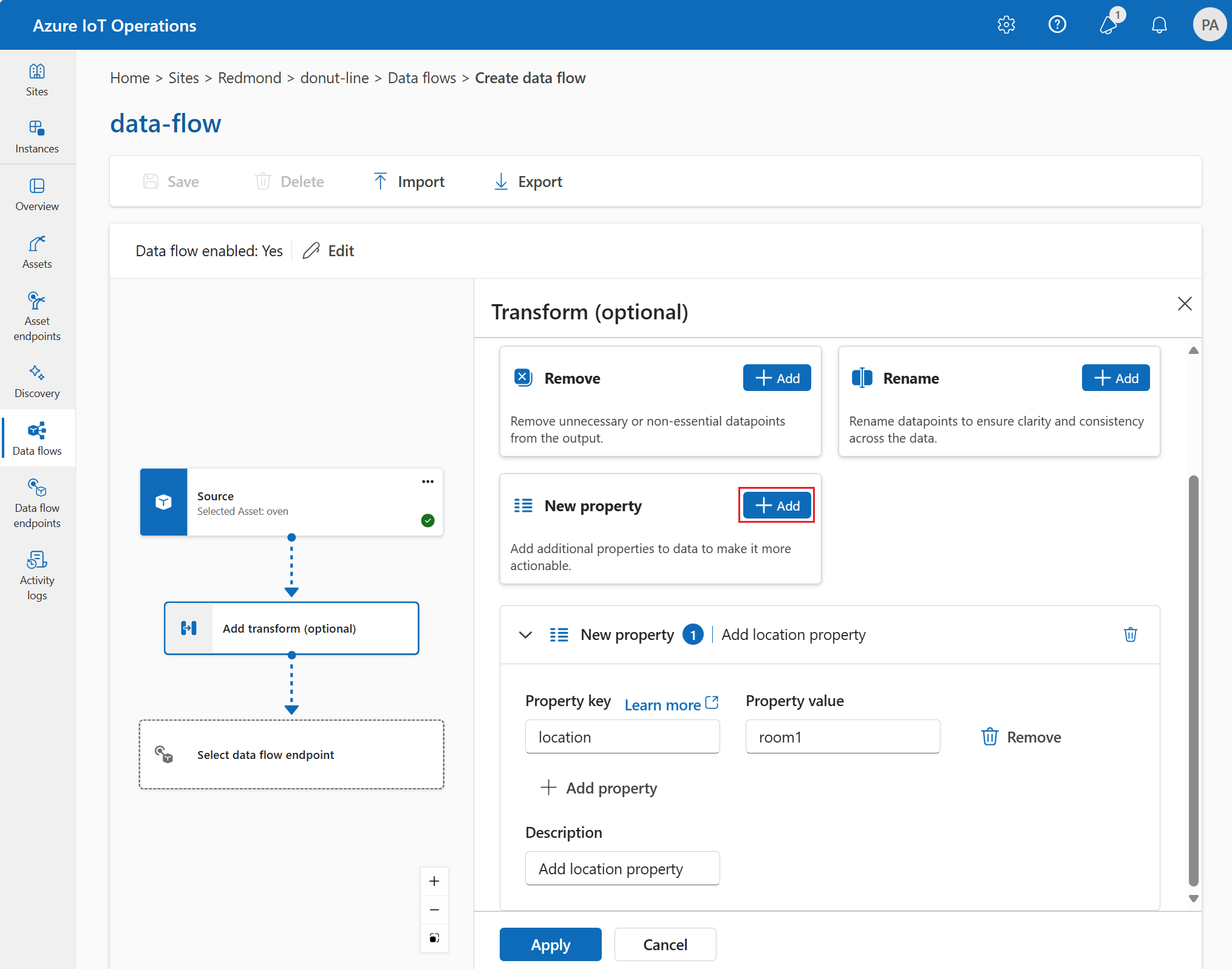
Voer de vereiste instellingen in.
Instelling Beschrijving Eigenschapssleutel Voer de sleutel voor de nieuwe eigenschap in. Eigenschapwaarde Voer de waarde voor de nieuwe eigenschap in. Beschrijving Geef een beschrijving voor de nieuwe eigenschap. Selecteer Toepassen.
Zie Kaartgegevens met behulp van gegevensstromen en Gegevens converteren met behulp van gegevensstromen voor meer informatie.
Verwijderen
Standaard worden alle gegevenspunten opgenomen in het uitvoerschema. U kunt elk gegevenspunt uit de bestemming verwijderen met behulp van de transformatie Verwijderen .
Selecteer Verwijderen onder Transformeren (optioneel).
Selecteer het gegevenspunt dat u wilt verwijderen uit het uitvoerschema.
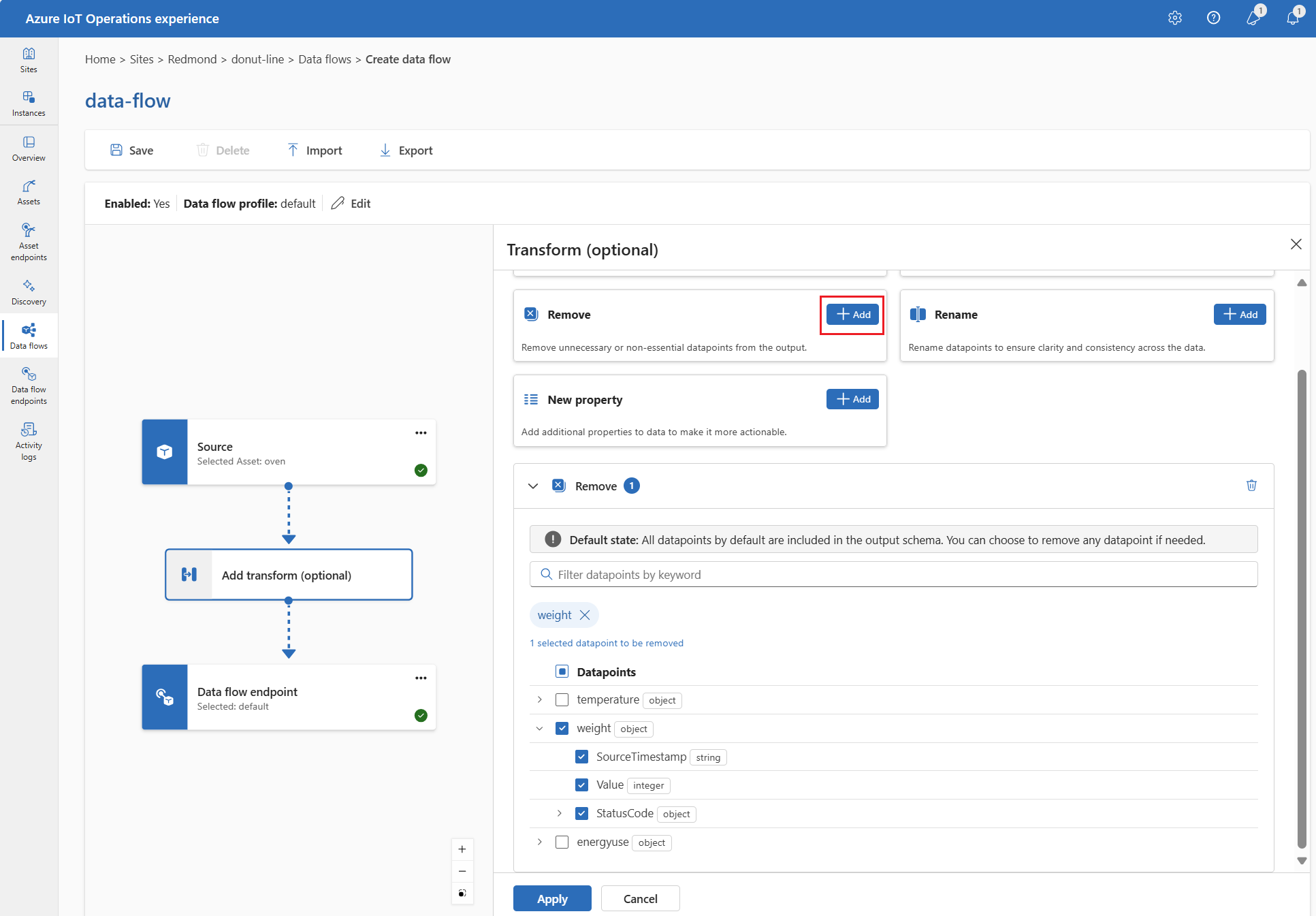
Selecteer Toepassen.
Zie Kaartgegevens met behulp van gegevensstromen en Gegevens converteren met behulp van gegevensstromen voor meer informatie.
Gegevens serialiseren volgens een schema
Als u de gegevens wilt serialiseren voordat u deze naar de bestemming verzendt, moet u een schema en serialisatie-indeling opgeven. Anders worden de gegevens geserialiseerd in JSON met de afgeleide typen. Voor opslageindpunten, zoals Microsoft Fabric of Azure Data Lake, is een schema vereist om gegevensconsistentie te garanderen. Ondersteunde serialisatie-indelingen zijn Parquet en Delta.
Aanbeveling
Als u het schema wilt genereren op basis van een voorbeeldgegevensbestand, gebruikt u de Helper voor Schema Gen.
Voor operationele ervaringen specificeert u het schema en het serialisatieformaat in de details van het eindpunt voor gegevensstromen. De eindpunten die serialisatie-indelingen ondersteunen, zijn Microsoft Fabric OneLake, Azure Data Lake Storage Gen 2, Azure Data Explorer en lokale opslag. Als u bijvoorbeeld de gegevens in Delta-indeling wilt serialiseren, moet u een schema uploaden naar het schemaregister en ernaar verwijzen in de eindpuntconfiguratie van het doeleindpunt voor de gegevensstroom.

Zie Berichtschema's begrijpen voor meer informatie over het schemaregister.
Bestemming
Als u een bestemming voor de gegevensstroom wilt configureren, geeft u de eindpuntreferentie en het doel van de gegevens op. U kunt een lijst met gegevensbestemmingen voor het eindpunt opgeven.
Als u gegevens wilt verzenden naar een andere bestemming dan de lokale MQTT-broker, maakt u een eindpunt voor de gegevensstroom. Zie Eindpunten voor gegevensstromen configureren voor meer informatie. Als de bestemming niet de lokale MQTT-broker is, moet deze worden gebruikt als bron. Zie Gegevensstromen moeten gebruikmaken van het lokale MQTT-brokereindpunt voor meer informatie over het gebruik van het lokale MQTT-brokereindpunt.
Belangrijk
Voor opslageindpunten is een schema voor serialisatie vereist. Als u een gegevensstroom wilt gebruiken met Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer of Lokale opslag, moet u een schemaverwijzing opgeven.
Selecteer het eindpunt van de gegevensstroom dat u als doel wilt gebruiken.

Voor opslageindpunten is een schema voor serialisatie vereist. Als u een Doeleindpunt voor Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer of Local Storage kiest, moet u een schemaverwijzing opgeven. Als u bijvoorbeeld de gegevens wilt serialiseren naar een Microsoft Fabric-eindpunt in Delta-indeling, moet u een schema uploaden naar het schemaregister en ernaar verwijzen in de eindpuntconfiguratie van het doeleindpunt van de gegevensstroom.

Selecteer Doorgaan om de bestemming te configureren.
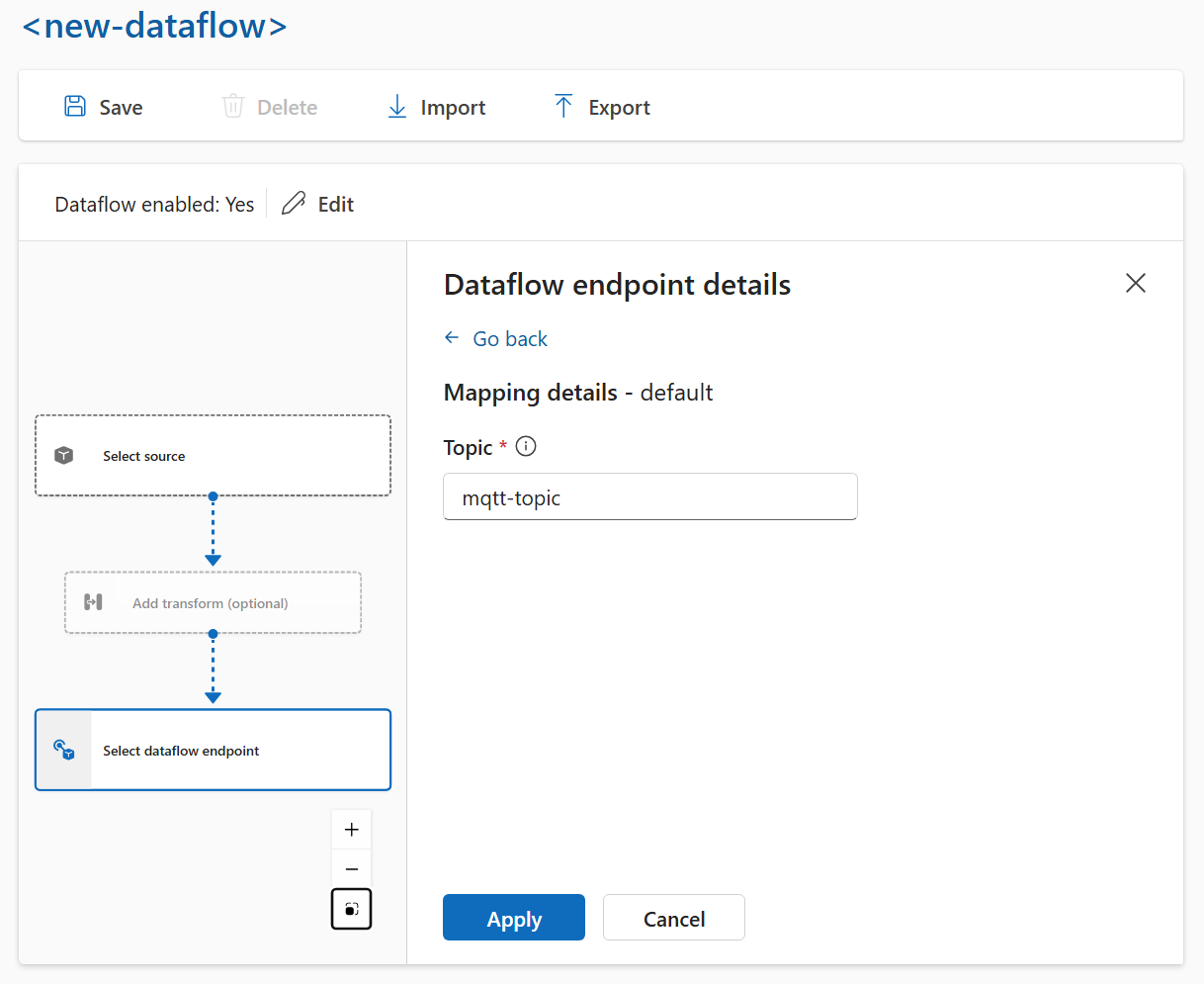
Voer de vereiste instellingen voor de bestemming in, inclusief het onderwerp of de tabel waarnaar de gegevens moeten worden verzonden. Zie Gegevensdoel configureren (onderwerp, container of tabel) voor meer informatie.
Gegevensbestemming configureren (onderwerp, container of tabel)
Net als bij gegevensbronnen is de gegevensbestemming een concept dat wordt gebruikt om de eindpunten van de gegevensstroom herbruikbaar te houden voor meerdere gegevensstromen. In wezen vertegenwoordigt het de submap in de configuratie van het gegevensstroomeindpunt. Als het eindpunt van de gegevensstroom bijvoorbeeld een opslageindpunt is, is de gegevensbestemming de tabel in het opslagaccount. Als het eindpunt van de gegevensstroom een Kafka-eindpunt is, is de gegevensbestemming het Kafka-onderwerp.
| Eindpunttype | Betekenis van gegevensbestemming | Beschrijving |
|---|---|---|
| MQTT (of Event Grid) | Onderwerp | Het MQTT-onderwerp waar de gegevens worden verzonden. Ondersteunt zowel statische onderwerpen als dynamische onderwerpomzetting met behulp van variabelen zoals ${inputTopic} en ${inputTopic.index}. Zie dynamische doelonderwerpen voor meer informatie. |
| Kafka (of Event Hubs) | Onderwerp | Het Kafka-onderwerp waar de gegevens worden verzonden. Alleen statische onderwerpen worden ondersteund, geen wildcards. Als het eindpunt een Event Hubs-naamruimte is, is de gegevensbestemming de afzonderlijke Event Hub binnen de naamruimte. |
| Azure Data Lake Storage | Opslagtank | De container in het opslagaccount. Niet de tabel. |
| Microsoft Fabric OneLake | Tabel of map | Komt overeen met het geconfigureerde padtype voor het eindpunt. |
| Azure-gegevensverkenner | Tabel | De tabel in de Azure Data Explorer-database. |
| Lokale opslag | Map | De map- of directorynaam in de volumekoppeling van de permanente lokale opslag. Wanneer u Azure Container Storage gebruikt dat is ingeschakeld door Azure Arc Cloud Ingest Edge Volumes, moet dit overeenkomen met de spec.path parameter voor het subvolume dat u hebt gemaakt. |
| OpenTelemetry | Onderwerp | Het OpenTelemetry-onderwerp waarin de gegevens worden verzonden. Alleen statische onderwerpen worden ondersteund. |
De gegevensbestemming configureren:
Wanneer u de bewerkingservaring gebruikt, wordt het gegevensdoelveld automatisch geïnterpreteerd op basis van het eindpunttype. Als het eindpunt voor de gegevensstroom bijvoorbeeld een opslageindpunt is, wordt u op de pagina met doelgegevens gevraagd om de containernaam in te voeren. Als het eindpunt van de gegevensstroom een MQTT-eindpunt is, wordt u op de pagina met doelgegevens gevraagd het onderwerp in te voeren, enzovoort.
Onderwerpen over dynamische bestemmingen
Voor MQTT-eindpunten kunt u dynamische onderwerpvariabelen in het dataDestination veld gebruiken om berichten te routeren op basis van de brononderwerpstructuur. De volgende variabelen zijn beschikbaar:
-
${inputTopic}- Het volledige oorspronkelijke invoeronderwerp -
${inputTopic.index}- Een segment van het invoeronderwerp (index begint bij 1)
Hiermee worden processed/factory/${inputTopic.2} bijvoorbeeld berichten gerouteerd van factory/1/data naar processed/factory/1. Onderwerpsegmenten zijn 1 geïndexeerd en voorloop-/volgslashes worden genegeerd.
Als een onderwerpvariabele niet kan worden opgelost (bijvoorbeeld ${inputTopic.5} wanneer het invoeronderwerp slechts drie segmenten heeft), wordt het bericht verwijderd en wordt er een waarschuwing vastgelegd. Jokertekens (# en +) zijn niet toegestaan in doelonderwerpen.
Notitie
De tekens $, {en } zijn geldig in MQTT-onderwerpnamen, dus een onderwerp is factory/$inputTopic.2 acceptabel, maar onjuist als u de dynamische onderwerpvariabele wilt gebruiken.
Voorbeeld
Het volgende voorbeeld is een gegevensstroomconfiguratie die gebruikmaakt van het MQTT-eindpunt voor de bron en het doel. De bron filtert de gegevens uit het MQTT-onderwerp azure-iot-operations/data/thermostat. De transformatie converteert de temperatuur naar Fahrenheit en filtert de gegevens waarbij de temperatuur vermenigvuldigd met de vochtigheid kleiner is dan 100000. De bestemming verzendt de gegevens naar het MQTT-onderwerp factory.

Zie Azure REST API - Gegevensstroom en de quickstart Bicep voor meer voorbeelden van gegevensstroomconfiguraties.
Controleren of een gegevensstroom werkt
Volg de zelfstudie: Bidirectionele MQTT-brug naar Azure Event Grid om te controleren of de gegevensstroom werkt.
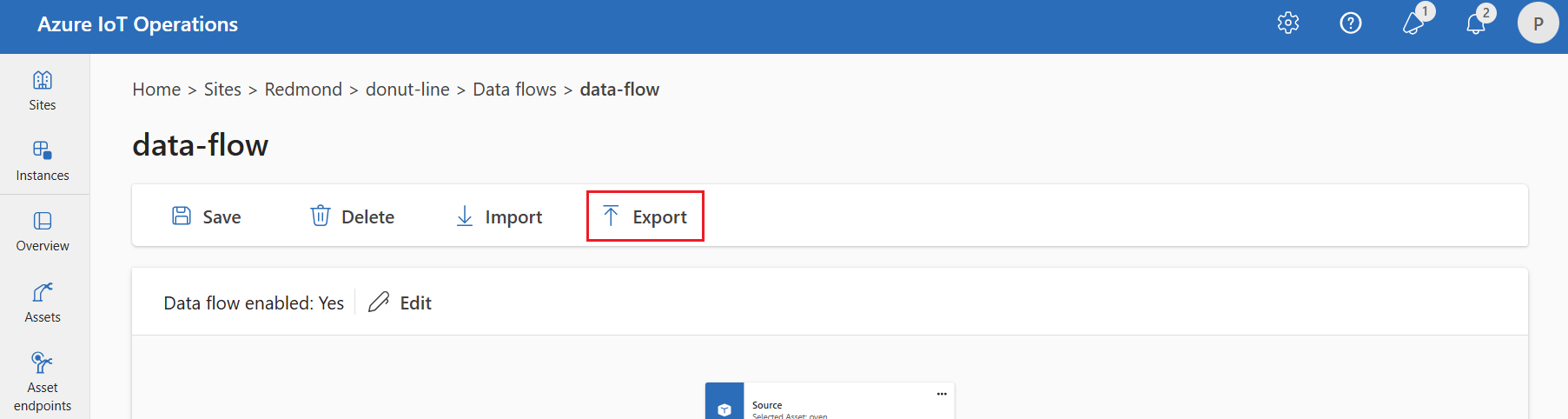
Configuratie van gegevensstroom exporteren
Als u de configuratie van de gegevensstroom wilt exporteren, kunt u de bewerkingservaring gebruiken of door de aangepaste resource voor de gegevensstroom te exporteren.
Selecteer de gegevensstroom die u wilt exporteren en selecteer Exporteren op de werkbalk.
Juiste configuratie van gegevensstromen
Controleer het volgende om ervoor te zorgen dat de gegevensstroom werkt zoals verwacht:
- Het standaardeindpunt van de MQTT-gegevensstroom moet worden gebruikt als de bron of het doel.
- Het gegevensstroomprofiel bestaat en wordt verwezen in de configuratie van de gegevensstroom.
- De bron is een MQTT-eindpunt, Kafka-eindpunt of een asset. Eindpunten van het opslagtype kunnen niet worden gebruikt als bron.
- Wanneer u Event Grid als bron gebruikt, wordt het aantal exemplaren van het gegevensstroomprofiel ingesteld op 1 omdat Event Grid MQTT Broker geen ondersteuning biedt voor gedeelde abonnementen.
- Wanneer u Event Hubs als bron gebruikt, is elke Event Hub in de naamruimte een afzonderlijk Kafka-onderwerp en moet deze worden opgegeven als de gegevensbron.
- De transformatie, indien toegepast, wordt geconfigureerd met de juiste syntaxis, inclusief het juiste escapen van speciale tekens.
- Wanneer u eindpunten van het opslagtype als bestemming gebruikt, wordt een schema opgegeven.
- Wanneer u dynamische doelonderwerpen gebruikt voor MQTT-eindpunten, moet u ervoor zorgen dat onderwerpvariabelen verwijzen naar geldige segmenten.