Een Python-modelonderdeel maken
In dit artikel wordt een onderdeel in Azure Machine Learning Designer beschreven.
Leer hoe u het onderdeel Python-model maken gebruikt om een niet-getraind model te maken op basis van een Python-script. U kunt het model baseren op elke cursist die is opgenomen in een Python-pakket in de Azure Machine Learning Designer-omgeving.
Nadat u het model hebt gemaakt, kunt u Train Model gebruiken om het model te trainen op een gegevensset, zoals elke andere cursist in Azure Machine Learning. Het getrainde model kan worden doorgegeven aan Score Model om voorspellingen te doen. Vervolgens kunt u het getrainde model opslaan en de scorewerkstroom publiceren als een webservice.
Waarschuwing
Momenteel is het niet mogelijk om dit onderdeel te verbinden met het onderdeel Model Hyperparameters afstemmen of de gescoorde resultaten van een Python-model door te geven aan Evaluate Model. Als u de hyperparameters wilt afstemmen of een model wilt evalueren, kunt u een aangepast Python-script schrijven met behulp van het python-scriptonderdeel Uitvoeren .
Het onderdeel configureren
Het gebruik van dit onderdeel vereist tussenliggende of deskundige kennis van Python. Het onderdeel ondersteunt het gebruik van alle cursisten die zijn opgenomen in de Python-pakketten die al zijn geïnstalleerd in Azure Machine Learning. Zie de vooraf geïnstalleerde Python-pakketlijst in Python-script uitvoeren.
Notitie
Wees voorzichtig bij het schrijven van uw script en zorg ervoor dat er geen syntaxisfout optreedt, zoals het gebruik van een niet-gedeclareerd object of een niet-geïmporteerd onderdeel.
Notitie
Let ook op de vooraf geïnstalleerde onderdelenlijst in Python-script uitvoeren. Importeer alleen vooraf geïnstalleerde onderdelen. Installeer geen extra pakketten zoals pip install xgboost in dit script, anders worden er fouten gegenereerd bij het lezen van modellen in downstream-onderdelen.
In dit artikel wordt beschreven hoe u Een Python-model maken gebruikt met een eenvoudige pijplijn. Hier volgt een diagram van de pijplijn:
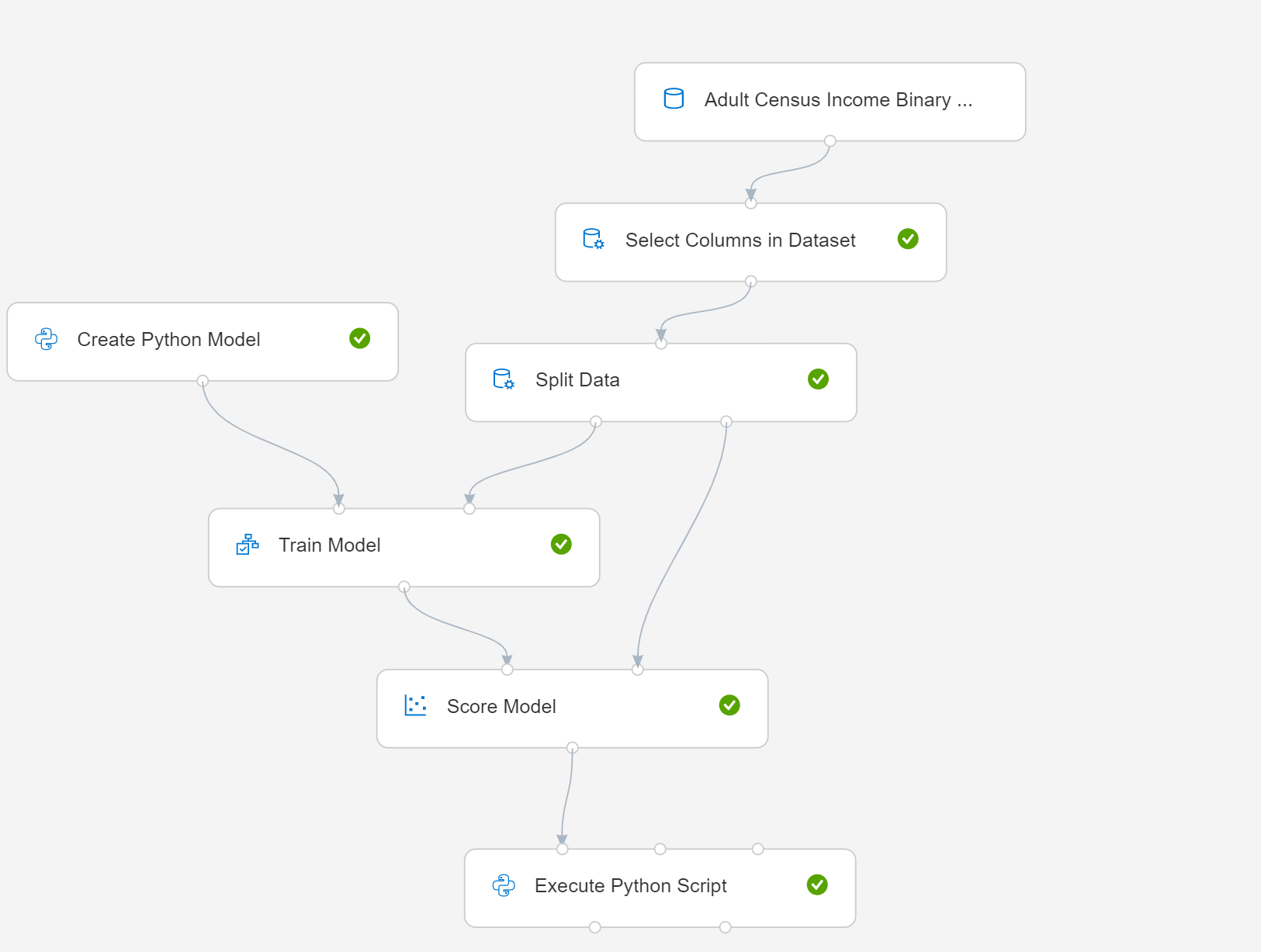
- Selecteer Python-model maken en bewerk het script om uw modellerings- of gegevensbeheerproces te implementeren. U kunt het model baseren op elke cursist die is opgenomen in een Python-pakket in de Azure Machine Learning-omgeving.
Notitie
Let op de opmerkingen in de voorbeeldcode van het script en zorg ervoor dat uw script strikt voldoet aan de vereiste, inclusief de klassenaam, methoden en methodehandtekening. Schending leidt tot uitzonderingen. Python-model maken biedt alleen ondersteuning voor het maken van een model op basis van sklearn dat moet worden getraind met Train Model.
De volgende voorbeeldcode van de naive Bayes-classificatie van twee klassen maakt gebruik van het populaire sklearn-pakket :
# The script MUST define a class named Azure Machine LearningModel.
# This class MUST at least define the following three methods:
# __init__: in which self.model must be assigned,
# train: which trains self.model, the two input arguments must be pandas DataFrame,
# predict: which generates prediction result, the input argument and the prediction result MUST be pandas DataFrame.
# The signatures (method names and argument names) of all these methods MUST be exactly the same as the following example.
# Please do not install extra packages such as "pip install xgboost" in this script,
# otherwise errors will be raised when reading models in down-stream components.
import pandas as pd
from sklearn.naive_bayes import GaussianNB
class AzureMLModel:
def __init__(self):
self.model = GaussianNB()
self.feature_column_names = list()
def train(self, df_train, df_label):
# self.feature_column_names records the column names used for training.
# It is recommended to set this attribute before training so that the
# feature columns used in predict and train methods have the same names.
self.feature_column_names = df_train.columns.tolist()
self.model.fit(df_train, df_label)
def predict(self, df):
# The feature columns used for prediction MUST have the same names as the ones for training.
# The name of score column ("Scored Labels" in this case) MUST be different from any other columns in input data.
return pd.DataFrame(
{'Scored Labels': self.model.predict(df[self.feature_column_names]),
'probabilities': self.model.predict_proba(df[self.feature_column_names])[:, 1]}
)
Verbind het python-modelonderdeel maken dat u zojuist hebt gemaakt om model en scoremodel te trainen.
Als u het model wilt evalueren, voegt u een Python-scriptonderdeel Uitvoeren toe en bewerkt u het Python-script.
Het volgende script is voorbeeld van evaluatiecode:
# The script MUST contain a function named azureml_main # which is the entry point for this component. # imports up here can be used to import pandas as pd # The entry point function MUST have two input arguments: # Param<dataframe1>: a pandas.DataFrame # Param<dataframe2>: a pandas.DataFrame def azureml_main(dataframe1 = None, dataframe2 = None): from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, roc_curve import pandas as pd import numpy as np scores = dataframe1.ix[:, ("income", "Scored Labels", "probabilities")] ytrue = np.array([0 if val == '<=50K' else 1 for val in scores["income"]]) ypred = np.array([0 if val == '<=50K' else 1 for val in scores["Scored Labels"]]) probabilities = scores["probabilities"] accuracy, precision, recall, auc = \ accuracy_score(ytrue, ypred),\ precision_score(ytrue, ypred),\ recall_score(ytrue, ypred),\ roc_auc_score(ytrue, probabilities) metrics = pd.DataFrame(); metrics["Metric"] = ["Accuracy", "Precision", "Recall", "AUC"]; metrics["Value"] = [accuracy, precision, recall, auc] return metrics,
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.