Partitie- en voorbeeldonderdeel
In dit artikel wordt een onderdeel in Azure Machine Learning Designer beschreven.
Gebruik het onderdeel Partitie en Voorbeeld om steekproeven uit te voeren op een gegevensset of om partities te maken op basis van uw gegevensset.
Steekproeven zijn een belangrijk hulpmiddel in machine learning, omdat u hiermee de grootte van een gegevensset kunt verkleinen terwijl u dezelfde verhouding van waarden behoudt. Dit onderdeel ondersteunt verschillende gerelateerde taken die belangrijk zijn in machine learning:
Uw gegevens verdelen in meerdere subsecties van dezelfde grootte.
U kunt de partities gebruiken voor kruisvalidatie of om aanvragen toe te wijzen aan willekeurige groepen.
Gegevens scheiden in groepen en vervolgens met gegevens uit een specifieke groep werken.
Nadat u willekeurig cases aan verschillende groepen hebt toegewezen, moet u mogelijk de functies wijzigen die aan slechts één groep zijn gekoppeld.
Monsterneming.
U kunt een percentage van de gegevens extraheren, willekeurige steekproeven toepassen of een kolom kiezen om de gegevensset te verdelen en gelaagde steekproeven uit te voeren op de waarden.
Een kleinere gegevensset maken om te testen.
Als u veel gegevens hebt, wilt u mogelijk alleen de eerste n rijen gebruiken tijdens het instellen van de pijplijn en vervolgens overschakelen naar het gebruik van de volledige gegevensset wanneer u uw model bouwt. U kunt ook steekproeven gebruiken om een kleinere gegevensset te maken voor gebruik in ontwikkeling.
Het onderdeel configureren
Dit onderdeel ondersteunt de volgende methoden voor het delen van uw gegevens in partities of voor steekproeven. Kies eerst de methode en stel vervolgens extra opties in die de methode vereist.
- Head
- Steekproeven
- Toewijzen aan vouwen
- Kiesvouw
TOP N-rijen ophalen uit een gegevensset
Gebruik deze modus om alleen de eerste n rijen op te halen. Deze optie is handig als u een pijplijn wilt testen op een klein aantal rijen en u de gegevens niet nodig hebt om op welke manier dan ook te worden verdeeld of gemonsterd.
Voeg het onderdeel Partition en Sample toe aan uw pijplijn in de interface en verbind de gegevensset.
Partitie- of voorbeeldmodus: stel deze optie in op Head.
Aantal rijen dat u wilt selecteren: voer het aantal rijen in dat moet worden geretourneerd.
Het aantal rijen moet een niet-negatief geheel getal zijn. Als het aantal geselecteerde rijen groter is dan het aantal rijen in de gegevensset, wordt de hele gegevensset geretourneerd.
Verzend de pijplijn.
Het onderdeel voert één gegevensset uit die alleen het opgegeven aantal rijen bevat. De rijen worden altijd gelezen boven aan de gegevensset.
Een voorbeeld van gegevens maken
Deze optie ondersteunt eenvoudige willekeurige steekproeven of gelaagde willekeurige steekproeven. Dit is handig als u een kleinere representatieve voorbeeldgegevensset wilt maken voor het testen.
Voeg het onderdeel Partition en Sample toe aan uw pijplijn en verbind de gegevensset.
Partitie- of voorbeeldmodus: stel deze optie in op Sampling.
Steekproefsnelheid: voer een waarde tussen 0 en 1 in. met deze waarde geeft u het percentage rijen van de brongegevensset op dat moet worden opgenomen in de uitvoergegevensset.
Als u bijvoorbeeld slechts de helft van de oorspronkelijke gegevensset wilt, geeft u
0.5aan dat de steekproeffrequentie 50 procent moet zijn.De rijen van de invoergegevensset worden in willekeurige volgorde geplaatst en selectief in de uitvoergegevensset geplaatst, volgens de opgegeven verhouding.
Willekeurig zaad voor steekproeven: Voer eventueel een geheel getal in dat moet worden gebruikt als seed-waarde.
Deze optie is belangrijk als u wilt dat de rijen telkens op dezelfde manier worden verdeeld. De standaardwaarde is 0, wat betekent dat een beginzaad wordt gegenereerd op basis van de systeemklok. Deze waarde kan leiden tot iets andere resultaten telkens wanneer u de pijplijn uitvoert.
Gelaagde splitsing voor steekproeven: selecteer deze optie als het belangrijk is dat de rijen in de gegevensset gelijkmatig worden verdeeld door een sleutelkolom voordat u steekproeven gaat nemen.
Voor stratification-sleutelkolom voor steekproeven selecteert u één strata-kolom die u wilt gebruiken bij het delen van de gegevensset. De rijen in de gegevensset worden vervolgens als volgt verdeeld:
Alle invoerrijen worden gegroepeerd (gelaagd) door de waarden in de opgegeven kolom strata.
Rijen worden in willekeurige volgorde in elke groep weergegeven.
Elke groep wordt selectief toegevoegd aan de uitvoergegevensset om te voldoen aan de opgegeven verhouding.
Verzend de pijplijn.
Met deze optie voert het onderdeel één gegevensset uit die een representatieve steekproef van de gegevens bevat. Het resterende, niet-gesampled gedeelte van de gegevensset wordt niet uitgevoerd.
Gegevens splitsen in partities
Gebruik deze optie als u de gegevensset wilt verdelen in subsets van de gegevens. Deze optie is ook handig als u een aangepast aantal vouwen wilt maken voor kruisvalidatie of rijen wilt splitsen in verschillende groepen.
Voeg het onderdeel Partition en Sample toe aan uw pijplijn en verbind de gegevensset.
Voor de partitie- of voorbeeldmodus selecteert u Toewijzen aan vouwen.
Gebruik vervanging in de partitionering: selecteer deze optie als u wilt dat de voorbeeldrij weer in de groep rijen wordt geplaatst voor mogelijk hergebruik. Als gevolg hiervan kan dezelfde rij worden toegewezen aan verschillende vouwen.
Als u geen vervanging gebruikt (de standaardoptie), wordt de voorbeeldrij niet teruggezet in de groep rijen voor mogelijk hergebruik. Als gevolg hiervan kan elke rij worden toegewezen aan slechts één vouw.
Gerandomiseerde splitsing: selecteer deze optie als u wilt dat rijen willekeurig worden toegewezen aan vouwen.
Als u deze optie niet selecteert, worden rijen toegewezen om door de round robin-methode te vouwen.
Willekeurige seed: Voer desgewenst een geheel getal in dat moet worden gebruikt als de seed-waarde. Deze optie is belangrijk als u wilt dat de rijen telkens op dezelfde manier worden verdeeld. Anders betekent de standaardwaarde 0 dat een willekeurig beginzaad wordt gebruikt.
Geef de partitiemethode op: Geef aan hoe u wilt dat gegevens aan elke partitie worden toegewezen met behulp van de volgende opties:
Gelijkmatig partitioneren: gebruik deze optie om een gelijk aantal rijen in elke partitie te plaatsen. Als u het aantal uitvoerpartities wilt opgeven, typt u een geheel getal in het opgeven van het aantal vouwen dat gelijkmatig in het vak moet worden gesplitst.
Partitie met aangepaste verhoudingen: gebruik deze optie om de grootte van elke partitie op te geven als een door komma's gescheiden lijst.
Stel dat u drie partities wilt maken. De eerste partitie bevat 50 procent van de gegevens. De resterende twee partities bevatten elk 25 procent van de gegevens. Voer in de lijst met verhoudingen gescheiden door komma's de volgende getallen in: .5, .25, .25.
De som van alle partitiegrootten moet maximaal 1 bedragen.
Als u getallen invoert die maximaal 1 optellen, wordt er een extra partitie gemaakt om de resterende rijen te bewaren. Als u bijvoorbeeld de waarden .2 en .3 invoert, wordt er een derde partitie gemaakt om de resterende 50 procent van alle rijen te bewaren.
Als u getallen invoert die maximaal 1 optellen, treedt er een fout op wanneer u de pijplijn uitvoert.
Gestratificeerde splitsing: selecteer deze optie als u wilt dat de rijen worden gestratificeerd wanneer u splitst en vervolgens de kolom Strata kiest.
Verzend de pijplijn.
Met deze optie voert het onderdeel meerdere gegevenssets uit. De gegevenssets worden gepartitioneerd volgens de regels die u hebt opgegeven.
Gegevens uit een vooraf gedefinieerde partitie gebruiken
Gebruik deze optie wanneer u een gegevensset hebt onderverdeeld in meerdere partities en nu elke partitie op zijn beurt wilt laden voor verdere analyse of verwerking.
Voeg het partitie- en voorbeeldonderdeel toe aan de pijplijn.
Verbind het onderdeel met de uitvoer van een vorig exemplaar van Partition en Sample. Deze instantie moet de optie Toewijzen aan vouwen hebben gebruikt om een aantal partities te genereren.
Partitie- of voorbeeldmodus: Selecteer Pick Fold.
Geef op uit welke vouw moet worden gemonsterd: Selecteer een partitie die u wilt gebruiken door de index in te voeren. Partitieindexen zijn gebaseerd op 1. Als u de gegevensset bijvoorbeeld in drie delen hebt verdeeld, hebben de partities de indexen 1, 2 en 3.
Als u een ongeldige indexwaarde invoert, wordt er een ontwerptijdfout gegenereerd: 'Fout 0018: Gegevensset bevat ongeldige gegevens'.
Naast het groeperen van de gegevensset op vouwen, kunt u de gegevensset scheiden in twee groepen: een doelvouw en alles anders. Hiervoor voert u de index van één vouw in en selecteert u vervolgens de optie Pick complement van de geselecteerde vouw om alles behalve de gegevens in de opgegeven vouw op te halen.
Als u met meerdere partities werkt, moet u meer exemplaren van het onderdeel Partition en Sample toevoegen om elke partitie te verwerken.
Het onderdeel Partitie en Voorbeeld in de tweede rij is bijvoorbeeld ingesteld op Toewijzen aan vouwen en het onderdeel in de derde rij is ingesteld op Pick Fold.
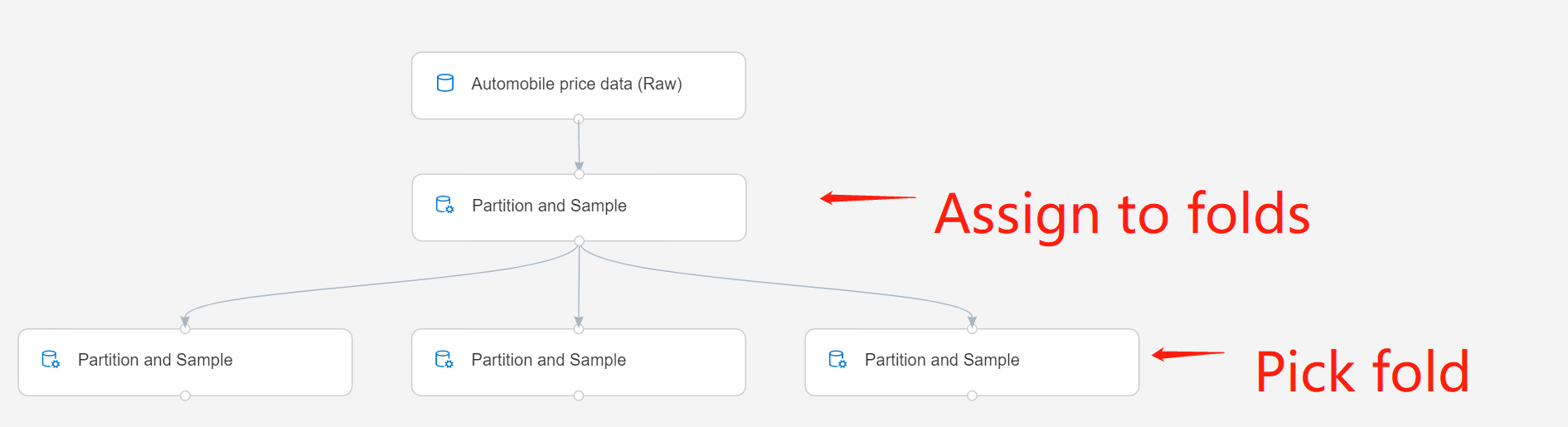
Verzend de pijplijn.
Met deze optie voert het onderdeel één gegevensset uit die alleen de rijen bevat die aan die vouw zijn toegewezen.
Notitie
U kunt de vouwaanduidingen niet rechtstreeks weergeven. Ze zijn alleen aanwezig in de metagegevens.
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.