Tekst voorverwerken
In dit artikel wordt een onderdeel in Azure Machine Learning Designer beschreven.
Gebruik het onderdeel Tekst vooraf verwerken om tekst op te schonen en te vereenvoudigen. Het ondersteunt deze algemene tekstverwerkingsbewerkingen:
- Stopwoorden verwijderen
- Reguliere expressies gebruiken om specifieke doeltekenreeksen te zoeken en te vervangen
- Lemmatisatie, die meerdere gerelateerde woorden converteert naar één canonieke vorm
- Casenormalisatie
- Verwijderen van bepaalde klassen tekens, zoals getallen, speciale tekens en reeksen herhaalde tekens, zoals 'aaaa'
- Identificatie en verwijdering van e-mailberichten en URL's
Het onderdeel Preprocess Text ondersteunt momenteel alleen Engels.
Tekstvoorverwerking configureren
Voeg het tekstonderdeel Preprocess toe aan uw pijplijn in Azure Machine Learning. U vindt dit onderdeel onder Text Analytics.
Verbind een gegevensset met ten minste één kolom met tekst.
Selecteer de taal in de vervolgkeuzelijst Taal .
Te wissen tekstkolom: selecteer de kolom die u vooraf wilt verwerken.
Stopwoorden verwijderen: selecteer deze optie als u een vooraf gedefinieerde stopwoordlijst wilt toepassen op de tekstkolom.
Stopword-lijsten zijn taalafhankelijk en aanpasbaar.
Lemmatisatie: Selecteer deze optie als u wilt dat woorden in hun canonieke vorm worden weergegeven. Deze optie is handig voor het verminderen van het aantal unieke exemplaren van anderszins vergelijkbare teksttokens.
Het lemmatisatieproces is zeer taalafhankelijk..
Zinnen detecteren: selecteer deze optie als u wilt dat het onderdeel een zingrensmarkering invoegt bij het uitvoeren van een analyse.
In dit onderdeel wordt een reeks van drie sluistekens
|||gebruikt om het zinseindteken weer te geven.Voer optionele bewerkingen voor zoeken en vervangen uit met behulp van reguliere expressies. De reguliere expressie wordt eerst verwerkt, vóór alle andere ingebouwde opties.
- Aangepaste reguliere expressie: definieer de tekst die u zoekt.
- Aangepaste vervangingstekenreeks: definieer één vervangingswaarde.
Hoofdletters normaliseren naar kleine letters: selecteer deze optie als u ASCII-hoofdletters wilt converteren naar hun kleine letters.
Als tekens niet worden genormaliseerd, wordt hetzelfde woord in hoofdletters en kleine letters beschouwd als twee verschillende woorden.
U kunt ook de volgende typen tekens of tekenreeksen verwijderen uit de verwerkte uitvoertekst:
Getallen verwijderen: selecteer deze optie om alle numerieke tekens voor de opgegeven taal te verwijderen. Identificatienummers zijn afhankelijk van een domein en taal. Als numerieke tekens een integraal onderdeel zijn van een bekend woord, wordt het getal mogelijk niet verwijderd. Meer informatie vindt u in Technische notities.
Speciale tekens verwijderen: gebruik deze optie om speciale tekens die niet alfanumerieke tekens bevatten, te verwijderen.
Dubbele tekens verwijderen: selecteer deze optie om extra tekens te verwijderen in eventuele reeksen die meer dan twee keer worden herhaald. Een reeks zoals 'aaaaa' wordt bijvoorbeeld gereduceerd tot 'aa'.
E-mailadressen verwijderen: selecteer deze optie om een willekeurige volgorde van de indeling
<string>@<string>te verwijderen.URL's verwijderen: selecteer deze optie om een reeks te verwijderen die de volgende URL-voorvoegsels bevat:
http,https, ,ftpwww
Vouw werkwoordcontracties uit: deze optie is alleen van toepassing op talen die werkwoordcontracties gebruiken; momenteel alleen Engels.
Als u bijvoorbeeld deze optie selecteert, kunt u de zin 'daar niet blijven' vervangen door 'zou daar niet blijven'.
Backslashes normaliseren naar slashes: selecteer deze optie om alle exemplaren van
\\aan toe te/wijzen.Tokens splitsen op speciale tekens: selecteer deze optie als u woorden wilt opsplitsen op tekens zoals
&,-enzovoort. Met deze optie kunt u ook de speciale tekens verminderen wanneer deze meer dan twee keer wordt herhaald.De tekenreeks
MS---WORDwordt bijvoorbeeld gescheiden in drie tokens,MS,-enWORD.Verzend de pijplijn.
Technische notities
Het voorverwerkingstekstonderdeel in Studio(klassiek) en de ontwerper maken gebruik van verschillende taalmodellen. De ontwerpfunctie maakt gebruik van een cnn-model met meerdere taken dat is getraind vanuit spaCy. Verschillende modellen geven verschillende tokenizer en een deel-van-spraak tagger, wat leidt tot verschillende resultaten.
Hier volgen enkele voorbeelden:
| Configuratie | Uitvoerresultaat |
|---|---|
| Met alle opties geselecteerd Uitleg: Voor de gevallen zoals '3test' in de 'WC-3 3test 4test', verwijdert de ontwerper het hele woord '3test', omdat in dit verband het onderdeel van spraak tagger dit token '3test' als numeriek opgeeft, en volgens het onderdeel van spraak wordt het onderdeel verwijderd. |
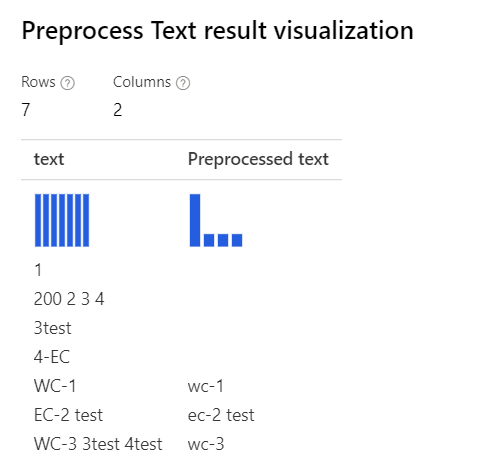
|
Met alleen Removing number geselecteerde uitleg: Voor de gevallen zoals '3test', '4-EC', splitst de designer tokenizer deze gevallen niet en behandelt deze als de hele tokens. De getallen in deze woorden worden dus niet verwijderd. |

|
U kunt ook een reguliere expressie gebruiken om aangepaste resultaten uit te voeren:
| Configuratie | Uitvoerresultaat |
|---|---|
| Met alle opties geselecteerd Aangepaste reguliere expressie: (\s+)*(-|\d+)(\s+)* Aangepaste vervangingstekenreeks: \1 \2 \3 |

|
Removing number Alleen geselecteerde aangepaste reguliere expressie: (\s+)*(-|\d+)(\s+)* Aangepaste vervangingstekenreeks: \1 \2 \3 |
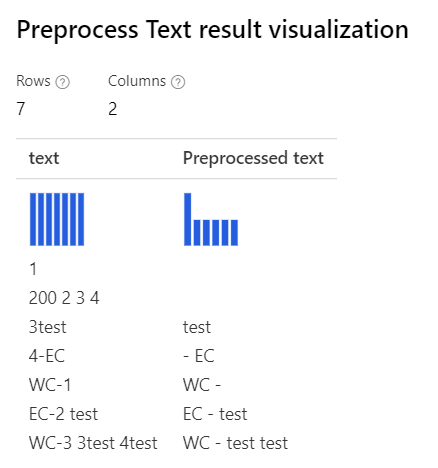
|
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.