Prognose op schaal: veel modellen en gedistribueerde training
Dit artikel gaat over het trainen van voorspellingsmodellen voor grote hoeveelheden historische gegevens. Instructies en voorbeelden voor het trainen van prognosemodellen in AutoML vindt u in ons artikel over het instellen van AutoML voor het voorspellen van tijdreeksen .
Tijdreeksgegevens kunnen groot zijn vanwege het aantal reeksen in de gegevens, het aantal historische waarnemingen of beide. Veel modellen en hiërarchische tijdreeksen, of HTS, zijn schaaloplossingen voor het voormalige scenario, waarbij de gegevens uit een groot aantal tijdreeksen bestaan. In deze gevallen kan het nuttig zijn voor modelnauwkeurigheid en schaalbaarheid om de gegevens in groepen te partitioneren en een groot aantal onafhankelijke modellen parallel op de groepen te trainen. Daarentegen zijn er scenario's waarin een of enkele modellen met hoge capaciteit beter zijn. Gedistribueerde DNN-training is gericht op dit geval. In de rest van het artikel bekijken we concepten over deze scenario's.
Veel modellen
Met de vele onderdelen van modellen in AutoML kunt u miljoenen modellen parallel trainen en beheren. Stel dat u historische verkoopgegevens hebt voor een groot aantal winkels. U kunt veel modellen gebruiken om parallelle AutoML-trainingstaken voor elke winkel te starten, zoals in het volgende diagram:

Het trainingsonderdeel voor veel modellen past autoML's modelverruiming en selectie onafhankelijk toe op elke winkel in dit voorbeeld. Deze modelafhankelijkheid helpt schaalbaarheid en kan ten goede komen aan modelnauwkeurigheid, met name wanneer de winkels uiteenlopende verkoopdynamiek hebben. Een enkele modelbenadering kan echter nauwkeurigere prognoses opleveren wanneer er sprake is van algemene verkoopdynamiek. Zie de sectie gedistribueerde DNN-training voor meer informatie over dat geval.
U kunt de gegevenspartitionering, de AutoML-instellingen voor de modellen en de mate van parallelle uitvoering voor veel trainingstaken voor modellen configureren. Zie onze handleidingsectie over veel modellenonderdelen voor voorbeelden.
Hiërarchische tijdreeksprognoses
Het is gebruikelijk dat tijdreeksen in bedrijfstoepassingen geneste kenmerken hebben die een hiërarchie vormen. Geografie- en productcataloguskenmerken zijn vaak genest, bijvoorbeeld. Bekijk een voorbeeld waarbij de hiërarchie twee geografische kenmerken, status- en winkel-id en twee productkenmerken, categorie en SKU heeft:

Deze hiërarchie wordt geïllustreerd in het volgende diagram:

Belangrijk is dat de verkoophoeveelheden op het niveau van het blad (SKU) tot de geaggregeerde verkoophoeveelheden op de staats- en totale verkoopniveaus worden opgeteld. Hiërarchische prognosemethoden behouden deze aggregatie-eigenschappen bij het voorspellen van de hoeveelheid die op een willekeurig niveau van de hiërarchie wordt verkocht. Prognoses met deze eigenschap zijn coherent met betrekking tot de hiërarchie.
AutoML ondersteunt de volgende functies voor hiërarchische tijdreeksen (HTS):
- Training op elk niveau van de hiërarchie. In sommige gevallen kunnen de gegevens op bladniveau luidruchtig zijn, maar aggregaties zijn mogelijk meer toegankelijk voor prognoses.
- Puntprognoses ophalen op elk niveau van de hiërarchie. Als het prognoseniveau 'lager' is dan het trainingsniveau, worden prognoses van het trainingsniveau opgesplitst via gemiddelde historische verhoudingen of verhoudingen van historische gemiddelden. Prognoses op trainingsniveau worden opgeteld volgens de aggregatiestructuur wanneer het prognoseniveau 'boven' het trainingsniveau ligt.
- Kwantiel/probabilistische voorspellingen ophalen voor niveaus op of onder het trainingsniveau. De huidige modelleringsmogelijkheden bieden ondersteuning voor het uitsplitsen van probabilistische prognoses.
HTS-onderdelen in AutoML zijn gebouwd op veel modellen, dus HTS deelt de schaalbare eigenschappen van veel modellen. Zie de handleidingsectie over HTS-onderdelen voor voorbeelden.
Gedistribueerde DNN-training (preview)
Belangrijk
Deze functie is momenteel beschikbaar als openbare preview-versie. Deze preview-versie wordt geleverd zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt.
Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Gegevensscenario's met grote hoeveelheden historische waarnemingen en/of grote aantallen gerelateerde tijdreeksen kunnen profiteren van een schaalbare benadering van één model. Daarom ondersteunt AutoML gedistribueerde training en modelzoekopdrachten op tijdelijke TCN-modellen (Convolutional Network), een type deep neural network (DNN) voor tijdreeksgegevens. Zie ons DNN-artikel voor meer informatie over de TCN-modelklasse van AutoML.
Gedistribueerde DNN-training realiseert schaalbaarheid met behulp van een algoritme voor gegevenspartitionering dat de grenzen van tijdreeksen respecteert. In het volgende diagram ziet u een eenvoudig voorbeeld met twee partities:
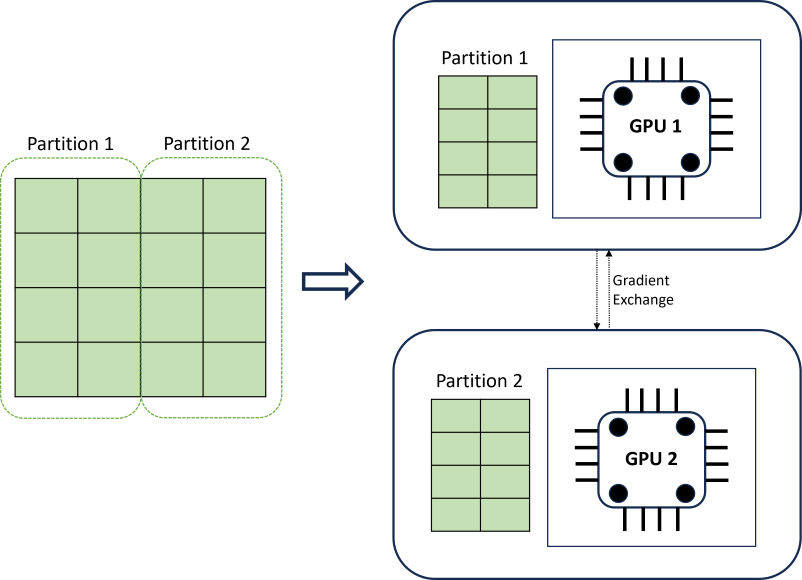
Tijdens de training worden de DNN-gegevensladers op elke rekenbelasting precies wat ze nodig hebben om een iteratie van back-doorgifte te voltooien; de hele gegevensset wordt nooit in het geheugen gelezen. De partities worden verder verdeeld over meerdere rekenkernen (meestal GPU's) op mogelijk meerdere knooppunten om de training te versnellen. Coördinatie tussen berekeningen wordt geboden door het Horovod-framework .
Volgende stappen
- Meer informatie over het instellen van AutoML voor het trainen van een tijdreeksprognosemodel.
- Meer informatie over hoe AutoML machine learning gebruikt om prognosemodellen te bouwen.
- Meer informatie over deep learning-modellen voor prognoses in AutoML