Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Het implementeren van verantwoorde AI in de praktijk vereist strenge engineering. Maar strenge engineering kan tijdrovend, handmatig en tijdrovend zijn zonder de juiste tooling en infrastructuur.
Het Dashboard Verantwoorde AI biedt één interface waarmee u verantwoorde AI in de praktijk effectief en efficiënt kunt implementeren. Het brengt verschillende volwassen verantwoordelijke AI-hulpprogramma's samen op het gebied van:
- Modelprestatie- en billijkheidsevaluatie
- Gegevens verkennen
- Interpreteerbaarheid van machine learning
- Foutenanalyse
- Contrafactuele analyse en verstoringen
- Causale deductie
Het dashboard biedt een holistische evaluatie en foutopsporing van modellen, zodat u weloverwogen gegevensgestuurde beslissingen kunt nemen. Als u toegang hebt tot al deze hulpprogramma's in één interface, kunt u het volgende doen:
Evalueer en los fouten op in uw machine learning-modellen door modelfouten en fairness-problemen te identificeren, te diagnosticeren waarom deze fouten optreden en uw risicobeperkingsstappen te informeren.
Verhoog uw gegevensgestuurde besluitvormingsmogelijkheden door vragen zoals:
"Wat is de minimale wijziging die gebruikers op hun functies kunnen toepassen om een ander resultaat te krijgen van het model?"
"Wat is het causale effect van het verminderen of verhogen van een functie (bijvoorbeeld rood vleesverbruik) op een werkelijk resultaat (bijvoorbeeld diabetesvoortgang)?"
U kunt het dashboard aanpassen om alleen de subset van hulpprogramma's op te nemen die relevant zijn voor uw use-case.
Het verantwoordelijke AI-dashboard wordt vergezeld van een PDF-scorecard. Met de scorecard kunt u verantwoorde AI-metagegevens en -inzichten exporteren naar uw gegevens en modellen. U kunt ze vervolgens offline delen met de belanghebbenden van het product en de naleving.
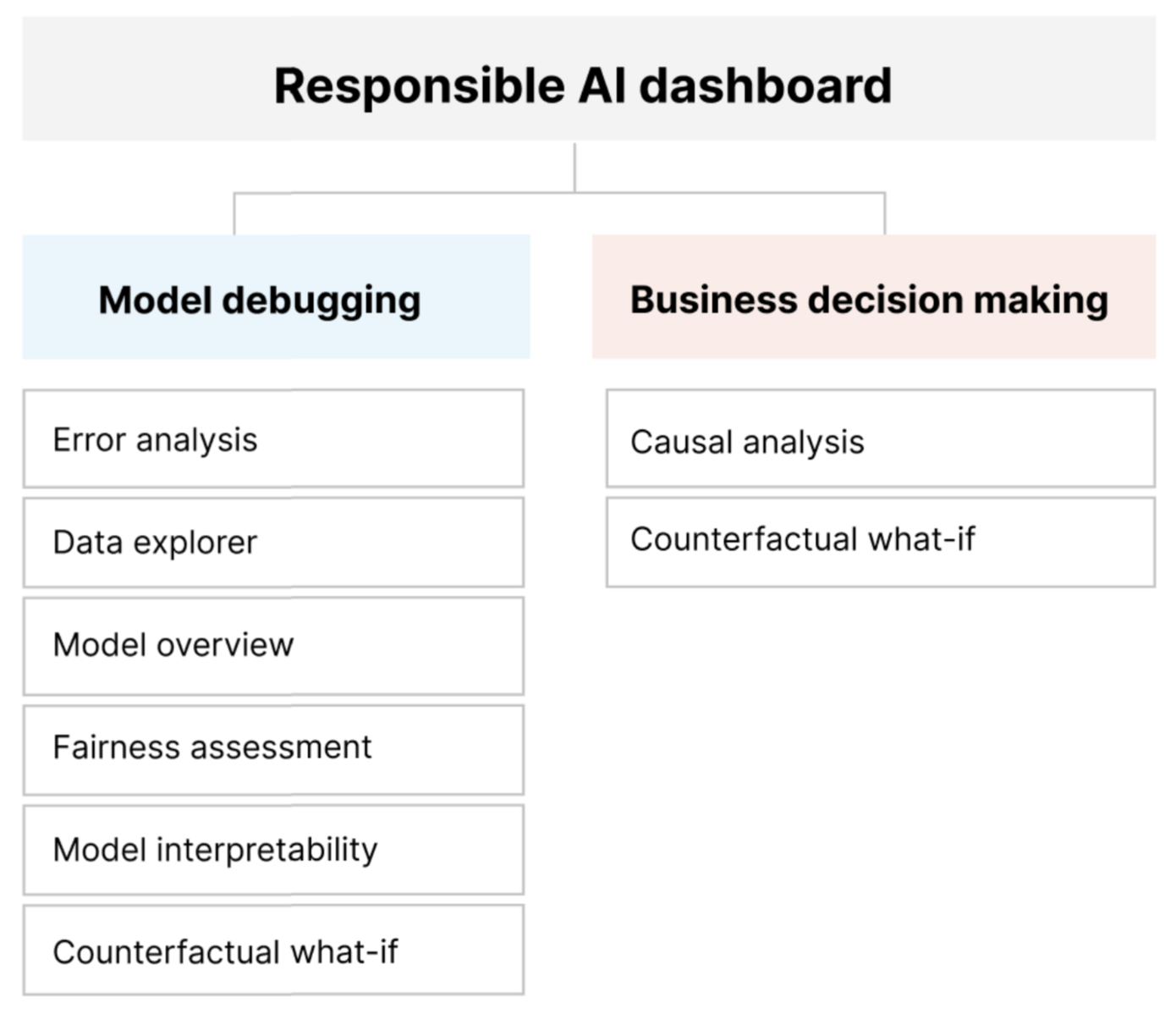
Verantwoordelijke AI-dashboardonderdelen
Het verantwoordelijke AI-dashboard combineert, in een uitgebreide weergave, verschillende nieuwe en bestaande hulpprogramma's. Het dashboard integreert deze hulpprogramma's met Azure Machine Learning CLI v2, Azure Machine Learning Python SDK v2 en Azure Machine Learning-studio. Tot de hulpmiddelen behoren:
- Gegevensanalyse, om uw gegevenssetdistributies en statistieken te begrijpen en te verkennen.
- Modeloverzicht en beoordeling van redelijkheid, om de prestaties van uw model te evalueren en de problemen met de groep fairness van uw model te evalueren (hoe de voorspellingen van uw model van invloed zijn op diverse groepen personen).
- Foutanalyse, om weer te geven en te begrijpen hoe fouten worden gedistribueerd in uw gegevensset.
- Modelinterpreteerbaarheid (urgentiewaarden voor statistische en afzonderlijke functies) om inzicht te krijgen in de voorspellingen van uw model en hoe deze algemene en afzonderlijke voorspellingen worden gedaan.
- Counterfactual what-if, om te zien hoe functievertragingen van invloed zijn op uw modelvoorspellingen terwijl de dichtstbijzijnde gegevenspunten tegengestelde of verschillende modelvoorspellingen worden geboden.
- Causale analyse, om historische gegevens te gebruiken om de causale effecten van behandelingsfuncties op resultaten in de praktijk weer te geven.
Samen helpen deze hulpprogramma's u bij het opsporen van fouten in machine learning-modellen, terwijl u uw zakelijke beslissingen op basis van gegevens en modellen informeert. In het volgende diagram ziet u hoe u deze kunt opnemen in uw AI-levenscyclus om uw modellen te verbeteren en solide gegevensinzichten te verkrijgen.
Modelopsporing
Het beoordelen en opsporen van fouten in machine learning-modellen is essentieel voor modelbetrouwbaarheid, interpreteerbaarheid, redelijkheid en naleving. Het helpt te bepalen hoe en waarom AI-systemen zich gedragen zoals ze dat doen. Vervolgens kunt u deze kennis gebruiken om de modelprestaties te verbeteren. Conceptueel bestaat modelfoutopsporing uit drie fasen:
Identificeer, om modelfouten en/of fairness-problemen te begrijpen en te herkennen door de volgende vragen aan te pakken:
"Welke soorten fouten heeft mijn model?"
"In welke gebieden komen fouten het vaakst voor?"
Diagnosticeren, om de redenen achter de geïdentificeerde fouten te onderzoeken door het volgende aan te pakken:
"Wat zijn de oorzaken van deze fouten?"
"Waar moet ik mijn resources richten om mijn model te verbeteren?"
Beperken, om de identificatie- en diagnoseinzichten uit eerdere fasen te gebruiken om gerichte risicobeperkingsstappen uit te voeren en vragen aan te pakken, zoals:
"Hoe kan ik mijn model verbeteren?"
"Welke sociale of technische oplossingen bestaan er voor deze problemen?"

In de volgende tabel wordt beschreven wanneer u onderdelen van het Verantwoorde AI-dashboard gebruikt ter ondersteuning van modelopsporing:
| Fase | Onderdeel | Beschrijving |
|---|---|---|
| Identificeren | Foutenanalyse | Met het onderdeel foutanalyse krijgt u meer inzicht in de verdeling van modelfouten en kunt u snel onjuiste cohorten (subgroepen) van gegevens identificeren. De mogelijkheden van dit onderdeel in het dashboard zijn afkomstig van het pakket Foutanalyse . |
| Identificeren | Fairness-analyse | Het fairness-onderdeel definieert groepen in termen van gevoelige kenmerken, zoals geslacht, ras en leeftijd. Vervolgens wordt beoordeeld hoe uw modelvoorspellingen van invloed zijn op deze groepen en hoe u verschillen kunt beperken. Het evalueert de prestaties van uw model door de distributie van uw voorspellingswaarden en de waarden van de metrische gegevens van uw modelprestaties in de groepen te verkennen. De mogelijkheden van dit onderdeel in het dashboard zijn afkomstig van het Fairlearn-pakket . |
| Identificeren | Overzicht van modellen | Het modeloverzichtsonderdeel voegt metrische gegevens voor modelevaluatie samen in een algemeen overzicht van modelvoorspellingsdistributie voor een beter onderzoek naar de prestaties. Dit onderdeel maakt het ook mogelijk om de beoordeling van de redelijkheid van groepen te beoordelen door de uitsplitsing van modelprestaties in gevoelige groepen te markeren. |
| Diagnosticeren | Gegevensanalyse | Gegevensanalyse visualiseert gegevenssets op basis van voorspelde en werkelijke resultaten, foutgroepen en specifieke functies. Vervolgens kunt u problemen met oververtegenwoordigdheid en ondervertegenwoordigdheid identificeren, samen met het zien hoe gegevens worden geclusterd in de gegevensset. |
| Diagnose stellen | Interpreteerbaarheid van modellen | Het interpreteerbaarheidsonderdeel genereert begrijpelijke uitleg over de voorspellingen van een machine learning-model. Het biedt meerdere weergaven in het gedrag van een model: - Globale uitleg (bijvoorbeeld welke functies van invloed zijn op het algehele gedrag van een leningtoewijzingsmodel) - Lokale uitleg (bijvoorbeeld waarom de aanvraag voor een lening van een aanvrager is goedgekeurd of afgewezen) De mogelijkheden van dit onderdeel in het dashboard zijn afkomstig van het InterpretML-pakket . |
| Diagnose stellen | Contrafactuele analyse en wat-als | Dit onderdeel bestaat uit twee functies voor betere foutdiagnose: - Het genereren van een reeks voorbeelden waarin minimale wijzigingen in een bepaald punt de voorspelling van het model wijzigen. Dat wil gezegd, de voorbeelden tonen de dichtstbijzijnde gegevenspunten met tegenovergestelde modelvoorspellingen. - Interactieve en aangepaste what-if-verstoringen inschakelen voor afzonderlijke gegevenspunten om te begrijpen hoe het model reageert op functiewijzigingen. De mogelijkheden van dit onderdeel in het dashboard zijn afkomstig van het DiCE-pakket . |
Risicobeperkingsstappen zijn beschikbaar via zelfstandige hulpprogramma's zoals Fairlearn. Zie de algoritmen voor het beperken van oneerlijke heid voor meer informatie.
Verantwoorde besluitvorming
Besluitvorming is een van de grootste beloften van machine learning. Met het dashboard Verantwoordelijke AI kunt u weloverwogen zakelijke beslissingen nemen via:
Gegevensgestuurde inzichten om meer inzicht te krijgen in causale behandelingseffecten op een resultaat door alleen historische gegevens te gebruiken. Voorbeeld:
"Hoe zou een geneesmiddel de bloeddruk van een patiënt beïnvloeden?"
"Hoe beïnvloedt het leveren van promotiewaarden aan bepaalde klanten de omzet?"
Deze inzichten worden geboden via het causale deductieonderdeel van het dashboard.
Modelgestuurde inzichten om vragen van gebruikers te beantwoorden (zoals 'Wat kan ik doen om een ander resultaat te krijgen van uw AI volgende keer?') zodat ze actie kunnen ondernemen. Deze inzichten worden gegeven aan gegevenswetenschappers via het contrafactuele wat-als-onderdeel .

Verkennende gegevensanalyse, causale deductie en contrafactuele analysemogelijkheden kunnen u helpen bij het maken van geïnformeerde modelgestuurde en gegevensgestuurde beslissingen op verantwoorde wijze.
Deze onderdelen van het verantwoordelijke AI-dashboard ondersteunen verantwoorde besluitvorming:
Gegevensanalyse: U kunt het onderdeel voor gegevensanalyse hier opnieuw gebruiken om inzicht te hebben in gegevensdistributies en om oververtegenwoordigdheid en ondervertegenwoordigdheid te identificeren. Gegevensverkenning is een essentieel onderdeel van besluitvorming, omdat het niet haalbaar is om weloverwogen beslissingen te nemen over een cohort dat ondervertegenwoordigd is in de gegevens.
Causale deductie: Het causale deductieonderdeel schat hoe een werkelijk resultaat verandert in de aanwezigheid van een interventie. Het helpt ook om veelbelovende interventies te bouwen door functiereacties op verschillende interventies te simuleren en regels te maken om te bepalen welke populatiecohorten van een bepaalde interventie zouden profiteren. Gezamenlijk kunt u met deze functies nieuwe beleidsregels toepassen en echte veranderingen in de praktijk toepassen.
De mogelijkheden van dit onderdeel zijn afkomstig uit het EconML-pakket , dat heterogene behandelingseffecten van observationele gegevens schat via machine learning.
Contrafactuele analyse: u kunt het contrafactuele analyseonderdeel hier opnieuw gebruiken om minimale wijzigingen te genereren die zijn toegepast op de functies van een gegevenspunt die leiden tot tegenovergestelde modelvoorspellingen. Bijvoorbeeld: Taylor zou de goedkeuring van de lening van de AI hebben verkregen als ze $ 10.000 meer verdienden in het jaarlijkse inkomen en twee minder creditcards open hadden.
Het verstrekken van deze informatie aan gebruikers informeert hun perspectief. Het informeert hen over hoe ze actie kunnen ondernemen om het gewenste resultaat van de AI in de toekomst te verkrijgen.
De mogelijkheden van dit onderdeel zijn afkomstig van het DiCE-pakket .
Redenen voor het gebruik van het verantwoordelijke AI-dashboard
Hoewel er vooruitgang is geboekt met afzonderlijke hulpprogramma's voor specifieke gebieden van verantwoorde AI, moeten gegevenswetenschappers vaak verschillende hulpprogramma's gebruiken om hun modellen en gegevens holistisch te evalueren. Bijvoorbeeld: ze moeten modelinterpretabiliteit en fairness-evaluatie samen gebruiken.
Als gegevenswetenschappers een eerlijkheidsprobleem met één hulpprogramma detecteren, moeten ze naar een ander hulpprogramma gaan om te begrijpen welke gegevens- of modelfactoren de hoofdoorzaak van het probleem zijn voordat ze stappen ondernemen om het probleem te beperken. De volgende factoren maken dit uitdagende proces nog ingewikkelder:
- Er is geen centrale locatie om de hulpprogramma's te ontdekken en te leren, waardoor de tijd die nodig is om te onderzoeken en nieuwe technieken te leren uitbreiden.
- De verschillende hulpprogramma's communiceren niet met elkaar. Gegevenswetenschappers moeten de gegevenssets, modellen en andere metagegevens wrangeren wanneer ze deze doorgeven tussen de hulpprogramma's.
- De metrische gegevens en visualisaties zijn niet eenvoudig vergelijkbaar en de resultaten zijn moeilijk te delen.
Het verantwoordelijke AI-dashboard daagt deze status-quo uit. Het is een uitgebreid maar aanpasbaar hulpprogramma dat gefragmenteerde ervaringen op één plek samenbrengt. Hiermee kunt u naadloos onboarden naar één aanpasbaar framework voor modelopsporing en gegevensgestuurde besluitvorming.
Met behulp van het verantwoordelijke AI-dashboard kunt u cohorten voor gegevenssets maken, deze cohorten doorgeven aan alle ondersteunde onderdelen en de modelstatus voor uw geïdentificeerde cohorten observeren. U kunt inzichten van alle ondersteunde onderdelen in verschillende vooraf gemaakte cohorten verder vergelijken om een niet-samengevoegde analyse uit te voeren en de blinde vlekken van uw model te vinden.
Wanneer u klaar bent om deze inzichten te delen met andere belanghebbenden, kunt u ze eenvoudig extraheren met behulp van de verantwoordelijke AI PDF-scorecard. Voeg het PDF-rapport toe aan uw nalevingsrapporten of deel het met collega's om vertrouwen te bouwen en hun goedkeuring te krijgen.
Manieren om het verantwoordelijke AI-dashboard aan te passen
De kracht van het verantwoordelijke AI-dashboard ligt in de aanpasbaarheid. Het stelt gebruikers in staat om aangepaste, end-to-end modelontsporing en besluitvormingswerkstromen te ontwerpen die voldoen aan hun specifieke behoeften.
Heb je inspiratie nodig? Hier volgen enkele voorbeelden van hoe de onderdelen van het dashboard kunnen worden samengesteld om scenario's op verschillende manieren te analyseren:
| Verantwoordelijke AI-dashboardstroom | Gebruiksscenario |
|---|---|
| Analysegegevensanalyse > van modeloverzicht > | Modelfouten identificeren en diagnosticeren door inzicht te krijgen in de onderliggende gegevensdistributie |
| Modeloverzicht > beoordelingsgegevensanalyse > | Modelproblemen identificeren en diagnosticeren door inzicht te krijgen in de onderliggende gegevensdistributie |
| Modeloverzicht > foutanalyse > counterfactuals-analyse en what-if | Fouten in afzonderlijke exemplaren diagnosticeren met contrafactuele analyse (minimale wijziging om te leiden tot een andere modelvoorspelling) |
| Analyse van modeloverzichtsgegevens > | Inzicht in de hoofdoorzaak van fouten en billijkheidsproblemen die worden geïntroduceerd via onbalans van gegevens of een gebrek aan representatie van een bepaald gegevenscohort |
| Interpreteerbaarheid van modeloverzicht > | Modelfouten diagnosticeren door te begrijpen hoe het model de voorspellingen heeft gedaan |
| Causale deductie van gegevensanalyse > | Om onderscheid te maken tussen correlaties en causaties in de gegevens of de beste behandelingen te bepalen die moeten worden toegepast om een positief resultaat te krijgen |
| Causale interpretatie van deductie > | Als u wilt weten of de factoren die het model heeft gebruikt voor voorspellingen een causaal effect hebben op het werkelijke resultaat |
| Data-analyse > contrafeitelijke analyse en wat-als | Om de vragen van klanten te beantwoorden over wat ze de volgende keer kunnen doen om een ander resultaat te krijgen van een AI-systeem |
Personen die het verantwoordelijke AI-dashboard moeten gebruiken
De volgende personen kunnen het verantwoordelijke AI-dashboard en de bijbehorende verantwoordelijke AI-scorecard gebruiken om vertrouwen te bouwen met AI-systemen:
- Machine learning-professionals en gegevenswetenschappers die geïnteresseerd zijn in foutopsporing en het verbeteren van hun machine learning-modellen vóór de implementatie
- Machine learning-professionals en gegevenswetenschappers die geïnteresseerd zijn in het delen van hun modelstatusrecords met productmanagers en zakelijke belanghebbenden om vertrouwen te bouwen en implementatiemachtigingen te ontvangen
- Productmanagers en zakelijke belanghebbenden die machine learning-modellen beoordelen vóór de implementatie
- Risicofunctionarissen die machine learning-modellen beoordelen om inzicht te krijgen in getrouwheids- en betrouwbaarheidsproblemen
- Providers van AI-oplossingen die modelbeslissingen willen uitleggen aan gebruikers of die hen helpen het resultaat te verbeteren
- Professionals in sterk gereglementeerde ruimten die machine learning-modellen moeten beoordelen met regelgevers en auditors
Ondersteunde scenario's en beperkingen
- Het verantwoordelijke AI-dashboard ondersteunt momenteel regressie- en classificatiemodellen (binaire en multiklasse) die zijn getraind op gestructureerde gegevens in tabelvorm.
- Het verantwoordelijke AI-dashboard ondersteunt momenteel alleen MLflow-modellen die zijn geregistreerd in Azure Machine Learning met een sklearn -smaak (scikit-learn). De scikit-learn-modellen moeten methoden implementeren
predict()/predict_proba()of het model moet worden verpakt in een klasse die methoden implementeertpredict()/predict_proba(). De modellen moeten in de onderdeelomgeving kunnen worden geladen en moeten pickleable zijn. - Het verantwoordelijke AI-dashboard visualiseert momenteel maximaal 5K van uw gegevenspunten in de dashboardgebruikersinterface. U moet de gegevensset downsampleeren naar 5K of minder voordat u deze doorgeeft aan het dashboard.
- De invoer van de gegevensset in het dashboard voor verantwoorde AI moet pandas DataFrames zijn in Parquet-indeling. NumPy- en SciPy-sparsegegevens worden momenteel niet ondersteund.
- Het verantwoordelijke AI-dashboard ondersteunt momenteel numerieke of categorische functies. Voor categorische functies moet de gebruiker expliciet de functienamen opgeven.
- Het verantwoordelijke AI-dashboard biedt momenteel geen ondersteuning voor gegevenssets met meer dan 10.000 kolommen.
- Het verantwoordelijke AI-dashboard biedt momenteel geen ondersteuning voor het AutoML MLFlow-model.
- Het verantwoordelijke AI-dashboard biedt momenteel geen ondersteuning voor geregistreerde AutoML-modellen uit de gebruikersinterface.
Volgende stappen
- Meer informatie over het genereren van het verantwoordelijke AI-dashboard via CLI en SDK of Azure Machine Learning-studio ui.
- Meer informatie over het genereren van een verantwoordelijke AI-scorecard op basis van de inzichten die zijn waargenomen op het dashboard voor verantwoorde AI.