Machine Learning-pijplijnen maken en uitvoeren met behulp van onderdelen met de Azure Machine Learning CLI
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
Azure CLI ml-extensie v2 (huidige)
In dit artikel leert u hoe u machine learning-pijplijnen maakt en uitvoert met behulp van Azure CLI en onderdelen. U kunt pijplijnen maken zonder onderdelen te gebruiken, maar onderdelen bieden de grootste mate van flexibiliteit en hergebruik. Azure Machine Learning-pijplijnen kunnen worden gedefinieerd in YAML en worden uitgevoerd vanuit de CLI, geschreven in Python of samengesteld in Azure Machine Learning-studio Designer met slepen en neerzetten. Dit document is gericht op de CLI.
Vereisten
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint. Probeer de gratis of betaalde versie van Azure Machine Learning.
Een Azure Machine Learning-werkruimte. Werkruimtebronnen maken.
Installeer en stel de Azure CLI-extensie voor Machine Learning in.
Kloon de opslagplaats met voorbeelden:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Voorgestelde prereading
Uw eerste pijplijn maken met onderdeel
Laten we uw eerste pijplijn maken met onderdelen met behulp van een voorbeeld. Deze sectie is bedoeld om u een eerste indruk te geven van hoe een pijplijn en onderdeel eruitzien in Azure Machine Learning met een concreet voorbeeld.
Navigeer vanuit de cli/jobs/pipelines-with-components/basics map van de azureml-examples opslagplaats naar de 3b_pipeline_with_data submap. Deze map bevat drie typen bestanden. Dit zijn de bestanden die u moet maken bij het bouwen van uw eigen pijplijn.
pipeline.yml: Dit YAML-bestand definieert de machine learning-pijplijn. In dit YAML-bestand wordt beschreven hoe u een volledige machine learning-taak in een werkstroom met meerdere stappen onderbreekt. Als u bijvoorbeeld een eenvoudige machine learning-taak overweegt om historische gegevens te gebruiken om een verkoopprognosemodel te trainen, kunt u een opeenvolgende werkstroom bouwen met gegevensverwerking, modeltraining en modelevaluatiestappen. Elke stap is een onderdeel dat goed gedefinieerde interface heeft en onafhankelijk kan worden ontwikkeld, getest en geoptimaliseerd. De YAML-pijplijn definieert ook hoe de onderliggende stappen verbinding maken met andere stappen in de pijplijn, bijvoorbeeld dat de modeltrainingsstap een modelbestand genereert en het modelbestand wordt doorgegeven aan een modelevaluatiestap.
component.yml: Dit YAML-bestand definieert het onderdeel. De volgende informatie wordt verpakt:
- Metagegevens: naam, weergavenaam, versie, beschrijving, type, enzovoort. De metagegevens helpen bij het beschrijven en beheren van het onderdeel.
- Interface: invoer en uitvoer. Een modeltrainingsonderdeel gebruikt bijvoorbeeld trainingsgegevens en het aantal tijdvakken als invoer en genereert een getraind modelbestand als uitvoer. Zodra de interface is gedefinieerd, kunnen verschillende teams het onderdeel onafhankelijk ontwikkelen en testen.
- Opdracht, code en omgeving: de opdracht, code en omgeving om het onderdeel uit te voeren. Opdracht is de shell-opdracht om het onderdeel uit te voeren. Code verwijst meestal naar een broncodemap. Omgeving kan een Azure Machine Learning-omgeving zijn (gecureerd of door de klant gemaakt), docker-installatiekopieën of conda-omgeving.
component_src: dit is de broncodemap voor een specifiek onderdeel. Deze bevat de broncode die in het onderdeel wordt uitgevoerd. U kunt uw voorkeurstaal (Python, R...) gebruiken. De code moet worden uitgevoerd met een shell-opdracht. De broncode kan enkele invoer van de opdrachtregel van de shell nemen om te bepalen hoe deze stap wordt uitgevoerd. Een trainingsstap kan bijvoorbeeld trainingsgegevens, leersnelheid, aantal tijdvakken nemen om het trainingsproces te beheren. Het argument van een shell-opdracht wordt gebruikt om invoer en uitvoer door te geven aan de code.
We gaan nu een pijplijn maken met behulp van het 3b_pipeline_with_data voorbeeld. In de volgende secties wordt de gedetailleerde betekenis van elk bestand uitgelegd.
Geef eerst uw beschikbare rekenresources weer met de volgende opdracht:
az ml compute list
Als u dit niet hebt, maakt u een cluster dat wordt aangeroepen cpu-cluster door het volgende uit te voeren:
Notitie
Sla deze stap over om serverloze berekeningen te gebruiken.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
Maak nu een pijplijntaak die is gedefinieerd in het pipeline.yml-bestand met de volgende opdracht. Naar het rekendoel wordt in het pipeline.yml-bestand verwezen als azureml:cpu-cluster. Als uw rekendoel een andere naam gebruikt, moet u dit bijwerken in het pipeline.yml bestand.
az ml job create --file pipeline.yml
U ontvangt een JSON-woordenlijst met informatie over de pijplijntaak, waaronder:
| Toets | Beschrijving |
|---|---|
name |
De op GUID gebaseerde naam van de taak. |
experiment_name |
De naam waaronder taken worden georganiseerd in studio. |
services.Studio.endpoint |
Een URL voor het bewaken en controleren van de pijplijntaak. |
status |
De status van de taak. Dit is Preparing waarschijnlijk op dit moment. |
Open de services.Studio.endpoint URL om een grafiekvisualisatie van de pijplijn te bekijken.
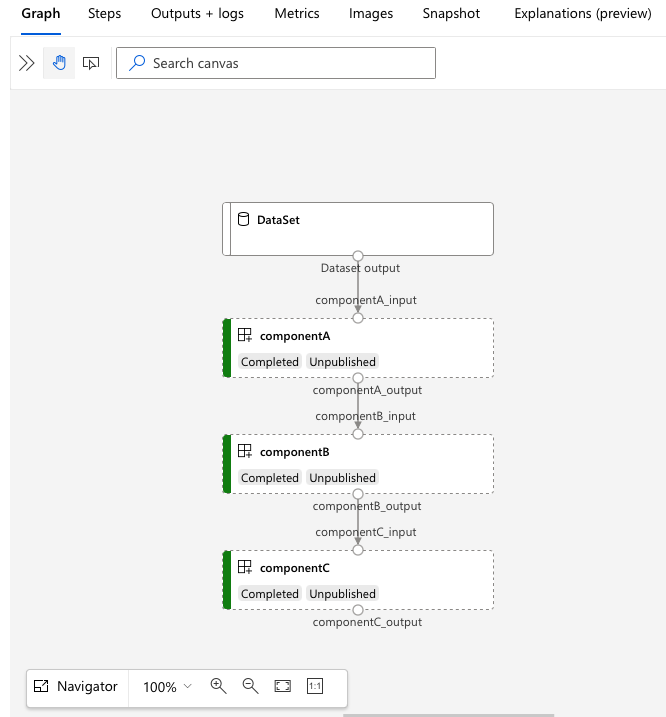
Inzicht in de YAML van de pijplijndefinitie
Laten we eens kijken naar de pijplijndefinitie in het bestand 3b_pipeline_with_data/pipeline.yml .
Notitie
Als u serverloze berekeningen wilt gebruiken, vervangt default_compute: azureml:cpu-cluster default_compute: azureml:serverless u door in dit bestand.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
In de tabel worden de meest gebruikte velden van het YAML-schema van de pijplijn beschreven. Zie het volledige YAML-schema voor pijplijnen voor meer informatie.
| sleutel | beschrijving |
|---|---|
| type | Vereist. Het taaktype moet voor pijplijntaken zijn pipeline . |
| display_name | Weergavenaam van de pijplijntaak in de gebruikersinterface van Studio. Bewerkbaar in de gebruikersinterface van Studio. Het hoeft niet uniek te zijn voor alle taken in de werkruimte. |
| Banen | Vereist. Woordenlijst van de set afzonderlijke taken die moeten worden uitgevoerd als stappen in de pijplijn. Deze taken worden beschouwd als onderliggende taken van de bovenliggende pijplijntaak. In deze release zijn command ondersteunde taaktypen in de pijplijn en sweep |
| Ingangen | Woordenlijst met invoer voor de pijplijntaak. De sleutel is een naam voor de invoer binnen de context van de taak en de waarde is de invoerwaarde. Naar deze pijplijninvoer kan worden verwezen door de invoer van een afzonderlijke staptaak in de pijplijn met behulp van de ${{ parent.inputs.<> input_name }} expressie. |
| uitvoer | Woordenlijst met uitvoerconfiguraties van de pijplijntaak. De sleutel is een naam voor de uitvoer binnen de context van de taak en de waarde is de uitvoerconfiguratie. Naar deze pijplijnuitvoer kan worden verwezen door de uitvoer van een afzonderlijke staptaak in de pijplijn met behulp van de uitvoer ${{ parents.outputs.<> output_name }} expressie. |
In het 3b_pipeline_with_data voorbeeld hebben we een pijplijn met drie stappen gemaakt.
- De drie stappen worden gedefinieerd onder
jobs. Alle drie de stappen zijn opdrachttaak. De definitie van elke stap bevindt zich in het bijbehorendecomponent.ymlbestand. U kunt de YAML-onderdelenbestanden onder 3b_pipeline_with_data map zien. In de volgende sectie wordt de componentA.yml uitgelegd. - Deze pijplijn heeft gegevensafhankelijkheid, wat gebruikelijk is in de meeste echte pijplijnen. Component_a neemt gegevensinvoer uit de lokale map onder
./data(regel 17-20) en geeft de uitvoer door aan componentB (regel 29). Component_a uitvoer kan worden verwezen als${{parent.jobs.component_a.outputs.component_a_output}}. - Hiermee
computedefinieert u de standaard rekenkracht voor deze pijplijn. Als een onderdeel onderjobseen ander rekenproces voor dit onderdeel definieert, respecteert het systeem de specifieke instelling voor onderdelen.

Gegevens lezen en schrijven in pijplijn
Een veelvoorkomend scenario is het lezen en schrijven van gegevens in uw pijplijn. In Azure Machine Learning gebruiken we hetzelfde schema om gegevens te lezen en te schrijven voor alle soorten taken (pijplijntaak, opdrachttaak en opruimen). Hieronder volgen voorbeelden van pijplijntaakvoorbeelden van het gebruik van gegevens voor veelvoorkomende scenario's.
- lokale gegevens
- webbestand met openbare URL
- Azure Machine Learning-gegevensopslag en -pad
- Azure Machine Learning-gegevensasset
Inzicht in de YAML van de onderdeeldefinitie
Laten we nu eens kijken naar de componentA.yml als voorbeeld om inzicht te hebben in YAML voor onderdeeldefinities.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
Het meest gebruikte schema van het yamL-onderdeel wordt beschreven in de tabel. Zie het volledige YAML-schema voor onderdelen voor meer informatie.
| sleutel | beschrijving |
|---|---|
| naam | Vereist. Naam van het onderdeel. Moet uniek zijn in de Azure Machine Learning-werkruimte. Moet beginnen met kleine letters. Kleine letters, cijfers en onderstrepingstekens(_) toestaan. De maximale lengte is 255 tekens. |
| display_name | Weergavenaam van het onderdeel in de gebruikersinterface van studio. Kan niet-zelfstandig zijn binnen de werkruimte. |
| opdracht | Vereist dat de opdracht moet worden uitgevoerd |
| code | Lokaal pad naar de broncodemap die moet worden geüpload en gebruikt voor het onderdeel. |
| omgeving | Vereist. De omgeving die wordt gebruikt om het onderdeel uit te voeren. |
| Ingangen | Woordenlijst van onderdeelinvoer. De sleutel is een naam voor de invoer binnen de context van het onderdeel en de waarde is de definitie van de onderdeelinvoer. In de opdracht kan naar invoer worden verwezen met behulp van de invoer ${{ .<> input_name }} expressie. |
| uitvoer | Woordenlijst van onderdeeluitvoer. De sleutel is een naam voor de uitvoer binnen de context van het onderdeel en de waarde is de definitie van de onderdeeluitvoer. Er kan naar uitvoer worden verwezen in de opdracht met behulp van de uitvoer ${{ .<> output_name }} expressie. |
| is_deterministic | Of het resultaat van de vorige taak opnieuw moet worden gebruikt als de invoer van het onderdeel niet is gewijzigd. Standaardwaarde is true, ook wel hergebruik genoemd. Het veelvoorkomende scenario bij het instellen als false het geforceerd opnieuw laden van gegevens uit een cloudopslag of URL. |
Voor het voorbeeld in 3b_pipeline_with_data/componentA.yml heeft componentA één gegevensinvoer en één gegevensuitvoer, die kan worden verbonden met andere stappen in de bovenliggende pijplijn. Alle bestanden in code de sectie in onderdeel YAML worden geüpload naar Azure Machine Learning bij het verzenden van de pijplijntaak. In dit voorbeeld worden bestanden onder ./componentA_src geüpload (regel 16 in componentA.yml). U ziet de geüploade broncode in de gebruikersinterface van Studio: dubbel selecteer de componentA-stap en navigeer naar het tabblad Momentopname, zoals wordt weergegeven in de volgende schermopname. We kunnen zien dat het een hallo-wereldscript is om eenvoudig af te drukken en huidige datum/tijd naar het componentA_output pad te schrijven. Het onderdeel neemt invoer en uitvoer via het opdrachtregelargument en wordt verwerkt in de hello.py met behulp van argparse.

Invoer en uitvoer
Invoer en uitvoer definiëren de interface van een onderdeel. Invoer en uitvoer kunnen een letterlijke waarde (van het type string,number,integer of ) of booleaneen object met invoerschema zijn.
Objectinvoer (van het type uri_file, uri_folder,mltable,mlflow_model,)custom_model kan verbinding maken met andere stappen in de bovenliggende pijplijntaak en gegevens/model daarom doorgeven aan andere stappen. In de pijplijngrafiek wordt de invoer van het objecttype weergegeven als een verbindingspunt.
Letterlijke waarde-invoer (string,number,integer,boolean) zijn de parameters die u tijdens runtime aan het onderdeel kunt doorgeven. U kunt de standaardwaarde van letterlijke invoer onder default het veld toevoegen. Voor number en integer typt u ook de minimum- en maximumwaarde van de geaccepteerde waarde met behulp min van en max velden. Als de invoerwaarde de minimum- en maximumwaarde overschrijdt, mislukt de pijplijn bij de validatie. Validatie vindt plaats voordat u een pijplijntaak verzendt om uw tijd te besparen. Validatie werkt voor CLI, Python SDK en designer-gebruikersinterface. In de volgende schermopname ziet u een validatievoorbeeld in de gebruikersinterface van de ontwerpfunctie. Op dezelfde manier kunt u toegestane waarden definiëren in enum het veld.

Als u invoer aan een onderdeel wilt toevoegen, moet u drie plaatsen bewerken:
inputsveld in component YAMLcommandveld in component YAML.- Broncode van onderdeel voor het afhandelen van de opdrachtregelinvoer. Deze is gemarkeerd in het groene vak in de vorige schermafbeelding.
Zie Invoer en uitvoer van onderdelen en pijplijnen beheren voor meer informatie over invoer en uitvoer.
Omgeving
Omgeving definieert de omgeving voor het uitvoeren van het onderdeel. Dit kan een Azure Machine Learning-omgeving zijn (gecureerd of aangepast geregistreerd), docker-installatiekopieën of conda-omgeving. Zie de volgende voorbeelden.
- Geregistreerde omgevingsasset van Azure Machine Learning. Er wordt naar verwezen in de volgende
azureml:<environment-name>:<environment-version>syntaxis van het onderdeel. - openbare docker-installatiekopieën
- Conda-bestand Conda-bestand moet samen met een basisinstallatiekopieën worden gebruikt.
Onderdeel registreren voor hergebruik en delen
Hoewel sommige onderdelen specifiek zijn voor een bepaalde pijplijn, komt het echte voordeel van onderdelen uit hergebruik en delen. Registreer een onderdeel in uw Machine Learning-werkruimte om het beschikbaar te maken voor hergebruik. Geregistreerde onderdelen ondersteunen automatische versiebeheer, zodat u het onderdeel kunt bijwerken, maar ervoor zorgen dat pijplijnen waarvoor een oudere versie is vereist, blijven werken.
Navigeer in de opslagplaats azureml-examples naar de cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components map.
Gebruik de az ml component create opdracht om een onderdeel te registreren:
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
Nadat deze opdrachten zijn voltooid, ziet u de onderdelen in Studio onder Asset -> Components:

Selecteer een onderdeel. U ziet gedetailleerde informatie voor elke versie van het onderdeel.
Op het tabblad Details ziet u basisinformatie van het onderdeel, zoals de naam, gemaakt door, versie, enzovoort. U ziet bewerkbare velden voor tags en beschrijving. De tags kunnen worden gebruikt voor het toevoegen van snel gezochte trefwoorden. Het beschrijvingsveld ondersteunt Markdown-opmaak en moet worden gebruikt om de functionaliteit en het basisgebruik van uw onderdeel te beschrijven.
Op het tabblad Taken ziet u de geschiedenis van alle taken die gebruikmaken van dit onderdeel.
Geregistreerde onderdelen gebruiken in een YAML-bestand voor een pijplijntaak
Laten we een demo maken 1b_e2e_registered_components over het gebruik van een geregistreerd onderdeel in pijplijn YAML. Navigeer naar 1b_e2e_registered_components de map en open het pipeline.yml bestand. De sleutels en waarden in de inputs en velden zijn vergelijkbaar met de sleutels en outputs waarden die al zijn besproken. Het enige significante verschil is de waarde van het component veld in de jobs.<JOB_NAME>.component vermeldingen. De component waarde is van het formulier azureml:<COMPONENT_NAME>:<COMPONENT_VERSION>. De train-job definitie geeft bijvoorbeeld de nieuwste versie van het geregistreerde onderdeel my_train moet worden gebruikt:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Onderdelen beheren
U kunt de details van onderdelen controleren en het onderdeel beheren met behulp van CLI (v2). Gebruik az ml component -h deze opdracht om gedetailleerde instructies voor de onderdeelopdracht op te halen. De volgende tabel bevat alle beschikbare opdrachten. Zie meer voorbeelden in azure CLI-naslaginformatie.
| opdrachten | beschrijving |
|---|---|
az ml component create |
Een onderdeel maken |
az ml component list |
Onderdelen in een werkruimte vermelden |
az ml component show |
Details van een onderdeel weergeven |
az ml component update |
Een onderdeel bijwerken. Slechts enkele velden (beschrijving, display_name) ondersteunen update |
az ml component archive |
Een onderdeelcontainer archiveren |
az ml component restore |
Een gearchiveerd onderdeel herstellen |