Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
In dit artikel wordt beschreven hoe u gegevensassets maakt en beheert in Azure Machine Learning.
Gegevensassets kunnen u helpen wanneer u het volgende nodig hebt:
- Versiebeheer: gegevensassets ondersteunen versiebeheer van gegevens.
- Reproduceerbaarheid: Nadat u een gegevensassetversie hebt gemaakt, is deze onveranderbaar. Het kan niet worden gewijzigd of verwijderd. Daarom kunnen trainingstaken of pijplijnen die de gegevensasset gebruiken, worden gereproduceerd.
- Controlebaarheid: omdat de gegevensassetversie onveranderbaar is, kunt u de assetversies bijhouden, die een versie hebben bijgewerkt en wanneer de versie-updates hebben plaatsgevonden.
- Herkomst: Voor elk gegeven gegevensasset kunt u bekijken welke taken of pijplijnen de gegevens verbruiken.
-
Gebruiksgemak: Een Azure Machine Learning-gegevensasset lijkt op bladwijzers van webbrowsers (favorieten). In plaats van lange opslagpaden (URI's) te onthouden die verwijzen naar
azureml:<my_data_asset_name>:<version>
Aanbeveling
Als u toegang wilt krijgen tot uw gegevens in een interactieve sessie (bijvoorbeeld een notebook) of een taak, hoeft u niet eerst een gegevensasset te maken. U kunt datastore-URI's gebruiken om toegang te krijgen tot de gegevens. Gegevensopslag-URI's bieden een eenvoudige manier om toegang te krijgen tot gegevens om aan de slag te gaan met Azure Machine Learning.
Vereisten
Als u gegevensassets wilt maken en ermee wilt werken, hebt u het volgende nodig:
Een Azure-abonnement. Als u nog geen abonnement hebt, maakt u een gratis account voordat u begint. Probeer de gratis of betaalde versie van Azure Machine Learning.
Een Azure Machine Learning-werkruimte. Werkruimtebronnen maken.
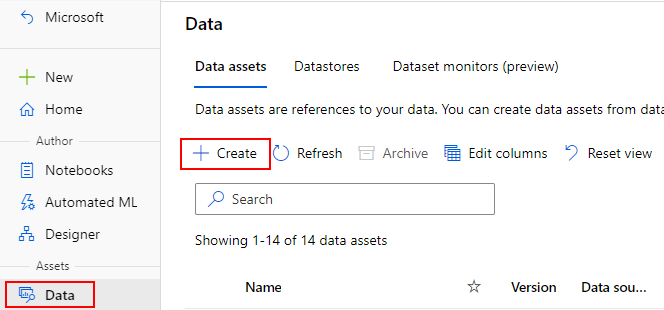
Gegevensassets maken
Wanneer u uw gegevensasset maakt, moet u het gegevensassettype instellen. Azure Machine Learning ondersteunt drie typen gegevensassets:
| Typologie | API (Application Programming Interface) | Canonieke scenario's |
|---|---|---|
|
Bestand Naar één bestand verwijzen |
uri_file |
Lees één bestand in Azure Storage (het bestand kan elke indeling hebben). |
|
Map Naar een map verwijzen |
uri_folder |
Lees een map met parquet-/CSV-bestanden in Pandas/Spark. Niet-gestructureerde gegevens lezen (afbeeldingen, tekst, audio, enzovoort) die zich in een map bevinden. |
|
Tabel Verwijzen naar een gegevenstabel |
mltable |
U hebt een complex schema dat onderhevig is aan frequente wijzigingen, of u hebt een subset met grote tabelgegevens nodig. AutoML met tabellen. Niet-gestructureerde gegevens (afbeeldingen, tekst, audio, enzovoort) lezen die verspreid zijn over meerdere opslaglocaties. |
Notitie
Gebruik alleen ingesloten nieuwe lijnen in CSV-bestanden als u de gegevens registreert als MLTable. Ingesloten nieuwe lijnen in CSV-bestanden kunnen verkeerd uitgelijnde veldwaarden veroorzaken wanneer u de gegevens leest. MLTable heeft de support_multi_line parameter die beschikbaar is in de read_delimited transformatie, om regeleinden tussen aanhalingsmogelijkheden als één record te interpreteren.
Wanneer u de gegevensasset in een Azure Machine Learning-taak gebruikt, kunt u de asset koppelen of downloaden naar de rekenknooppunten. Ga voor meer informatie naar Modi.
U moet ook een path parameter opgeven die verwijst naar de locatie van de gegevensasset. Ondersteunde paden zijn onder andere:
| Locatie | Voorbeelden |
|---|---|
| Een pad op uw lokale computer | ./home/username/data/my_data |
| Een pad in een gegevensarchief | azureml://datastores/<data_store_name>/paths/<path> |
| Een pad op een openbare HTTP(s)-server | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Een pad in Azure Storage | (Blob) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS Gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS Gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Notitie
Wanneer u een gegevensasset maakt op basis van een lokaal pad, wordt deze automatisch geüpload naar het standaardgegevensarchief van de Azure Machine Learning-cloud.
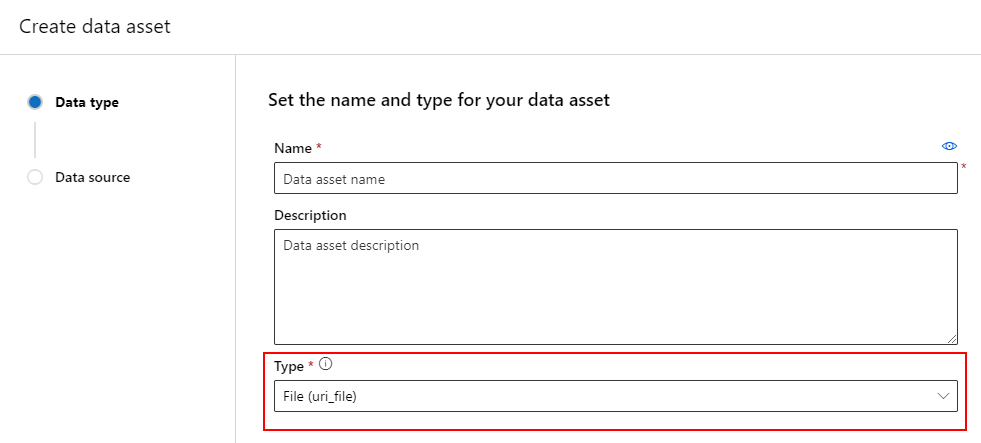
Een gegevensasset maken: bestandstype
Een gegevensasset van een bestand (uri_file) verwijst naar één bestand in de opslag (bijvoorbeeld een CSV-bestand). U kunt een gegevensasset met bestandstypen maken met:
Maak een YAML-bestand en kopieer en plak het volgende codefragment. Zorg ervoor dat u de <> tijdelijke aanduidingen bijwerkt met de
- naam van uw gegevensasset
- de versie
- beschrijving
- pad naar één bestand op een ondersteunde locatie
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Voer vervolgens de volgende opdracht uit in de CLI. Zorg ervoor dat u de <filename> tijdelijke aanduiding bijwerkt naar de YAML-bestandsnaam.
az ml data create -f <filename>.yml
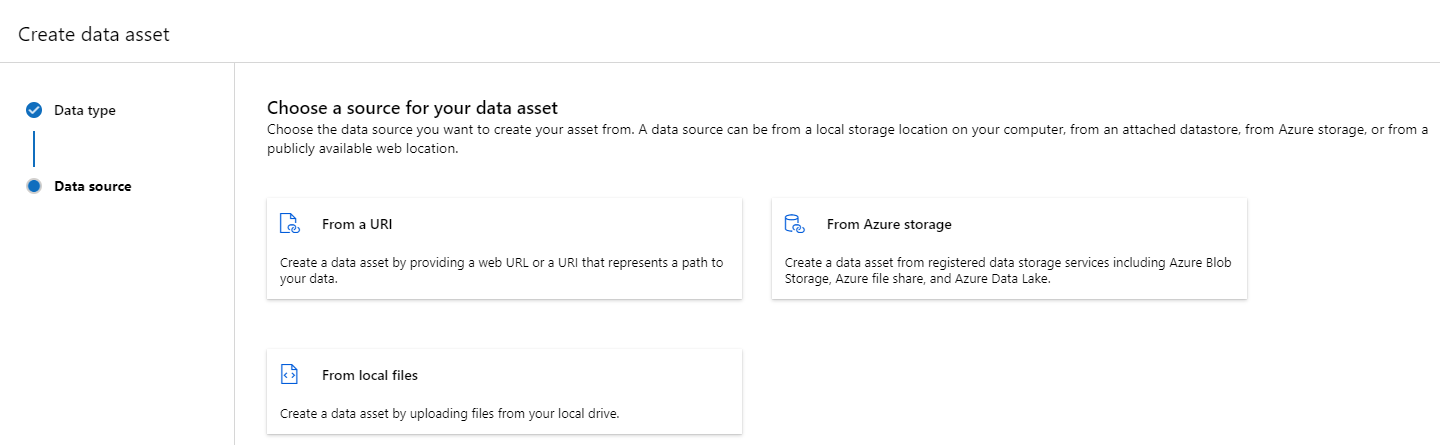
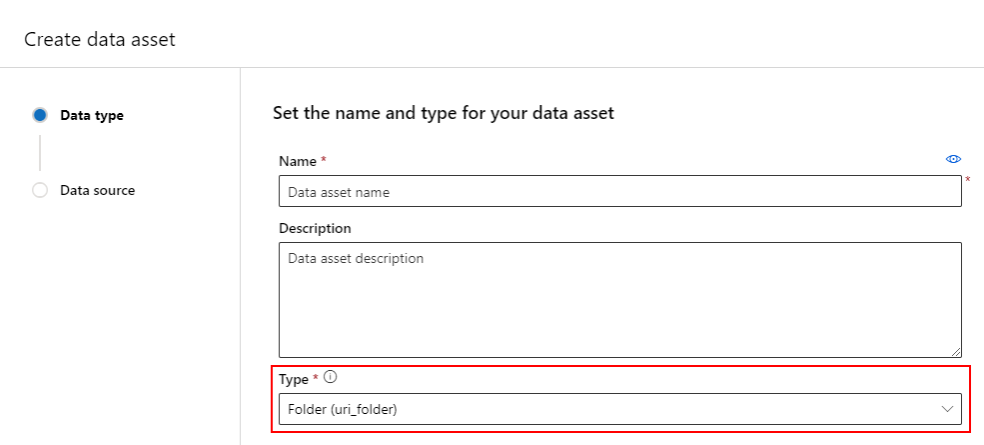
Een gegevensasset maken: maptype
Een map (uri_folder) type gegevensasset verwijst naar een map in een opslagresource, bijvoorbeeld een map met verschillende submappen van afbeeldingen. U kunt een gegevensasset met een maptype maken met:
Kopieer en plak de volgende code in een nieuw YAML-bestand. Zorg ervoor dat u de <> tijdelijke aanduidingen bijwerkt met de
- Naam van uw gegevensasset
- De versie
- Beschrijving
- Pad naar een map op een ondersteunde locatie
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Voer vervolgens de volgende opdracht uit in de CLI. Zorg ervoor dat u de <filename> tijdelijke aanduiding bijwerkt naar de YAML-bestandsnaam.
az ml data create -f <filename>.yml
Een gegevensasset maken: tabeltype
Azure Machine Learning-tabellen (MLTable) hebben uitgebreide functionaliteit, zoals beschreven in Het werken met tabellen in Azure Machine Learning. In plaats van deze documentatie hier te herhalen, leest u dit voorbeeld waarin wordt beschreven hoe u een tabelgetypeerde gegevensasset maakt, met Titanic-gegevens op een openbaar beschikbaar Azure Blob Storage-account.
Maak eerst een nieuwe map met de naam gegevens en maak een bestand met de naam MLTable:
mkdir data
touch MLTable
Kopieer en plak vervolgens de volgende YAML in het MLTable-bestand dat u in de vorige stap hebt gemaakt:
Let op
Wijzig MLTable in MLTable.yaml of MLTable.yml. Azure Machine Learning verwacht een MLTable bestand.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
Voer de volgende opdracht uit in de CLI. Zorg ervoor dat u de <> tijdelijke aanduidingen bijwerkt met de gegevensassetnaam en versiewaarden.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Belangrijk
Dit path moet een map zijn die een geldig MLTable bestand bevat.
Gegevensassets maken van taakuitvoer
U kunt een gegevensasset maken op basis van een Azure Machine Learning-taak. Hiervoor stelt u de name parameter in de uitvoer in. In dit voorbeeld verzendt u een taak waarmee gegevens uit een openbaar blobarchief worden gekopieerd naar uw standaard Azure Machine Learning-gegevensarchief en een gegevensasset wordt gemaakt met de naam job_output_titanic_asset.
Een YAML-bestand met taakspecificatie maken (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
Verzend vervolgens de taak met behulp van de CLI:
az ml job create --file <file-name>.yml
Gegevensassets beheren
Een gegevensassets verwijderen
Belangrijk
Het verwijderen van gegevensassets wordt standaard niet ondersteund.
Als azure machine learning verwijdering van gegevensassets heeft toegestaan, heeft dit de volgende negatieve en negatieve gevolgen:
- Productietaken die gegevensassets verbruiken die later zijn verwijderd, mislukken.
- Het zou moeilijker worden om een ML-experiment te reproduceren .
- Taakherkomst zou breken, omdat het onmogelijk zou worden om de verwijderde gegevensassetversie weer te geven.
- U zou niet goed kunnen bijhouden en controleren , omdat versies mogelijk ontbreken.
Daarom biedt de onveranderbaarheid van gegevensassets een beveiligingsniveau bij het werken in een team dat productieworkloads maakt.
Voor een per ongeluk gemaakte gegevensasset, bijvoorbeeld met een onjuiste naam, type of pad, biedt Azure Machine Learning oplossingen voor het afhandelen van de situatie zonder de negatieve gevolgen van verwijdering:
| Ik wil deze gegevensasset verwijderen omdat... | Oplossing |
|---|---|
| De naam is onjuist | De gegevensasset archiveren |
| Het team gebruikt de gegevensasset niet meer | De gegevensasset archiveren |
| De lijst met gegevensassets wordt onbelangrijke e-mail | De gegevensasset archiveren |
| Het pad is onjuist | Maak een nieuwe versie van de gegevensasset (dezelfde naam) met het juiste pad. Ga naar Gegevensassets maken voor meer informatie. |
| Het heeft een onjuist type | Op dit moment staat Azure Machine Learning het maken van een nieuwe versie met een ander type dan de eerste versie niet toe. (1) De gegevensasset archiveren (2) Maak een nieuwe gegevensasset onder een andere naam met het juiste type. |
Archiveer een gegevensasset
Als u een gegevensasset archivert, wordt deze standaard verborgen voor zowel lijstquery's (bijvoorbeeld in de CLI az ml data list) als de vermelding van gegevensassets in de gebruikersinterface van Studio. U kunt nog steeds verwijzen naar en een gearchiveerd gegevensasset in uw werkstromen gebruiken. U kunt het volgende archiveren:
- Alle versies van de gegevensasset onder een bepaalde naam
of
- Een specifieke versie van gegevensasset
Alle versies van een gegevensasset archiveren
Als u alle versies van de gegevensasset onder een bepaalde naam wilt archiveren, gebruikt u:
Voer de volgende opdracht uit. Zorg ervoor dat u de <> tijdelijke aanduidingen bijwerkt met uw gegevens.
az ml data archive --name <NAME OF DATA ASSET>
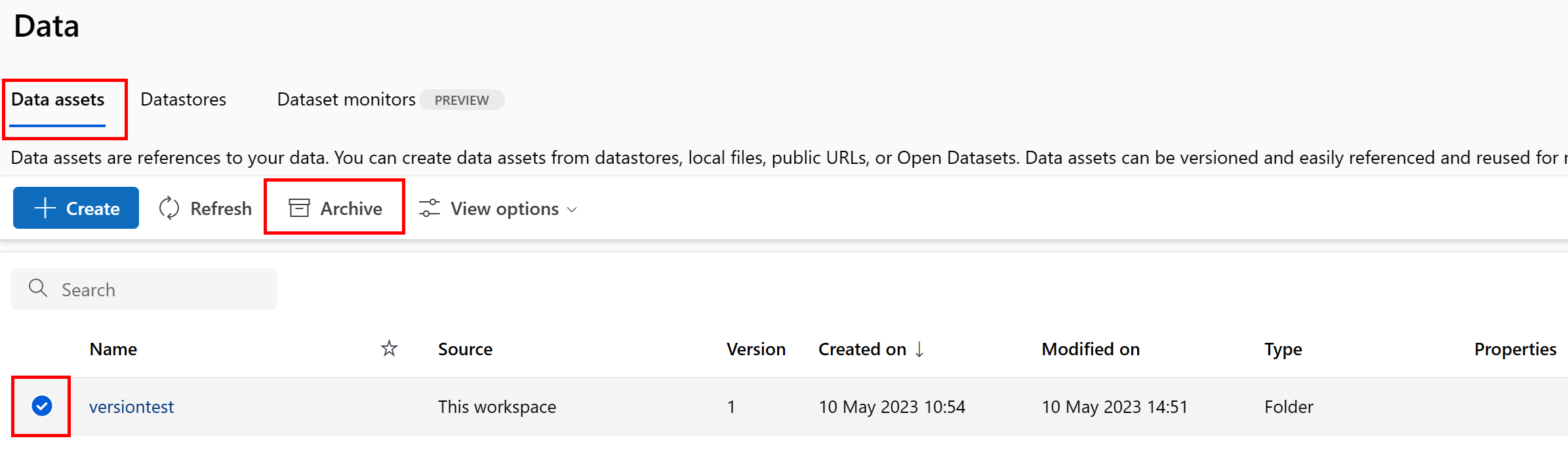
Een specifieke gegevensassetversie archiveren
Als u een specifieke versie van een gegevensasset wilt archiveren, gebruikt u:
Voer de volgende opdracht uit. Zorg ervoor dat u de <> tijdelijke aanduidingen bijwerkt met de naam van uw gegevensasset en versie.
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Een gearchiveerde gegevensasset herstellen
U kunt een gearchiveerde gegevensasset herstellen. Als alle versies van de gegevensasset zijn gearchiveerd, kunt u geen afzonderlijke versies van de gegevensasset herstellen. U moet alle versies herstellen.
Alle versies van een gegevensasset herstellen
Als u alle versies van de gegevensasset onder een bepaalde naam wilt herstellen, gebruikt u:
Voer de volgende opdracht uit. Zorg ervoor dat u de <> tijdelijke aanduidingen bijwerkt met de naam van uw gegevensasset.
az ml data restore --name <NAME OF DATA ASSET>

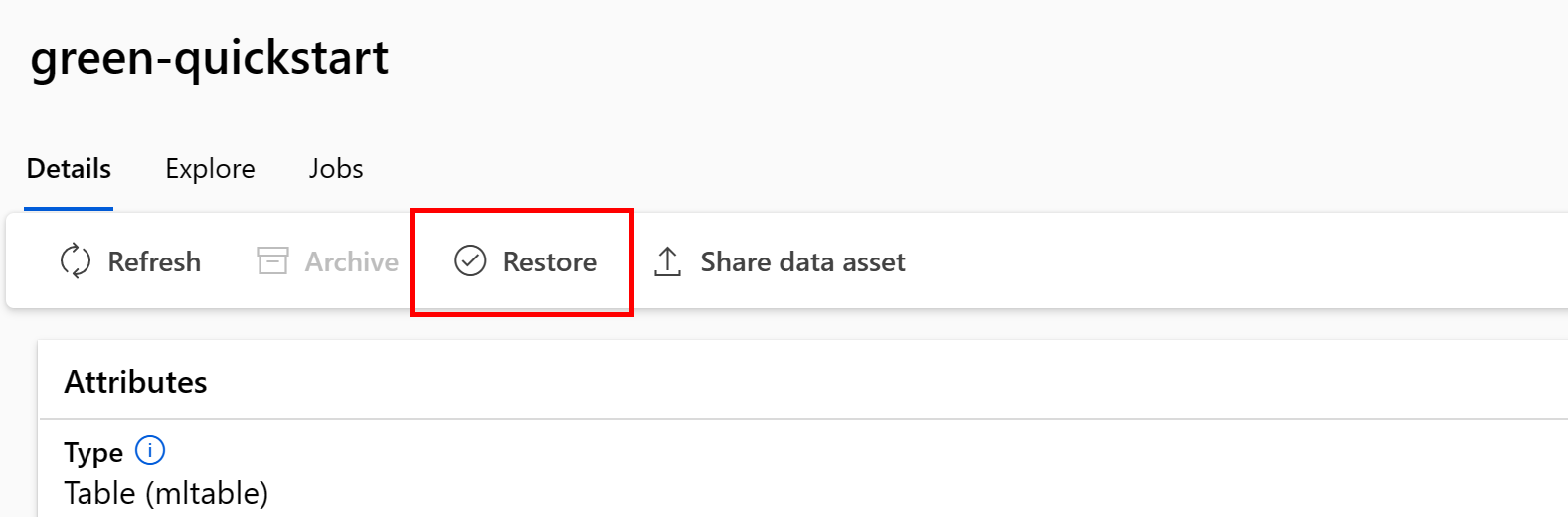
Een specifieke gegevensassetversie herstellen
Belangrijk
Als alle gegevensassetversies zijn gearchiveerd, kunt u geen afzonderlijke versies van de gegevensasset herstellen. U moet alle versies herstellen.
Als u een specifieke versie van een gegevensasset wilt herstellen, gebruikt u:
Voer de volgende opdracht uit. Zorg ervoor dat u de <> tijdelijke aanduidingen bijwerkt met de naam van uw gegevensasset en versie.
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Gegevensherkomst
Gegevensherkomst wordt algemeen begrepen als de levenscyclus die de oorsprong van de gegevens omvat en waar deze zich in de loop van de tijd in de opslag verplaatst. Verschillende soorten achterwaarts uitziende scenario's gebruiken dit bijvoorbeeld
- Probleemoplossing
- Hoofdoorzaken in ML-pijplijnen traceren
- Foutopsporing
Analyse van gegevenskwaliteit, naleving en 'what if'-scenario's maken ook gebruik van herkomst. Gegevensherkomst wordt visueel weergegeven om gegevens weer te geven die van de bron naar de bestemming worden verplaatst. Daarnaast worden gegevenstransformaties behandeld. Gezien de complexiteit van de meeste zakelijke gegevensomgevingen, kunnen deze weergaven moeilijk te begrijpen worden zonder consolidatie of maskering van randapparatuurgegevenspunten.
In een Azure Machine Learning-pijplijn tonen gegevensassets de oorsprong van de gegevens en hoe de gegevens zijn verwerkt, bijvoorbeeld:
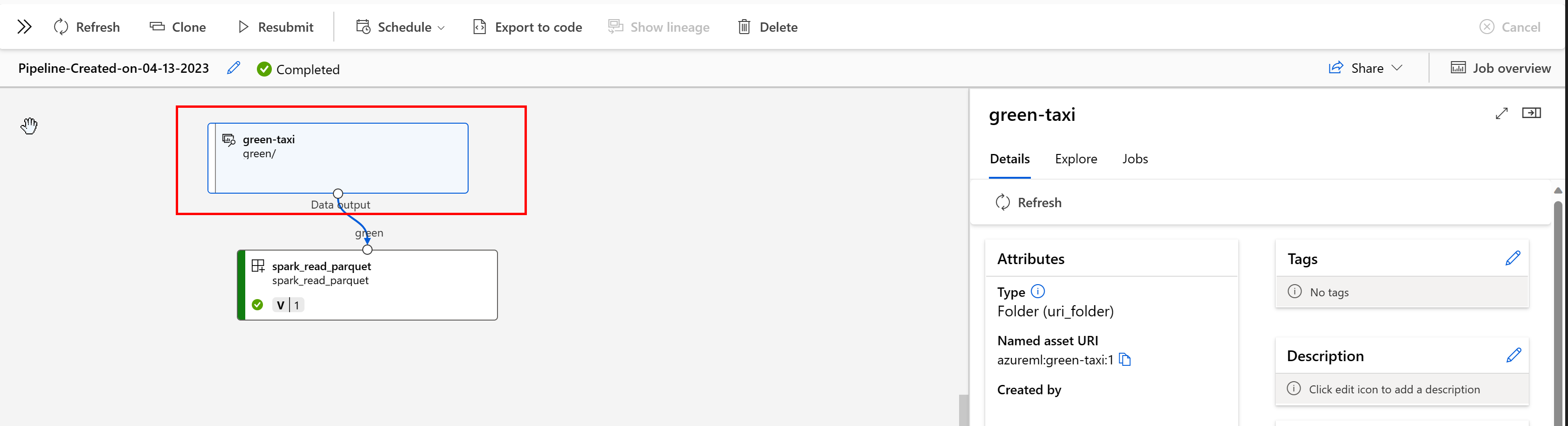
U kunt de taken weergeven die de gegevensasset gebruiken in de gebruikersinterface van Studio. Selecteer eerst Gegevens in het linkermenu en selecteer vervolgens de naam van de gegevensasset. Let op de taken die gebruikmaken van de gegevensasset:
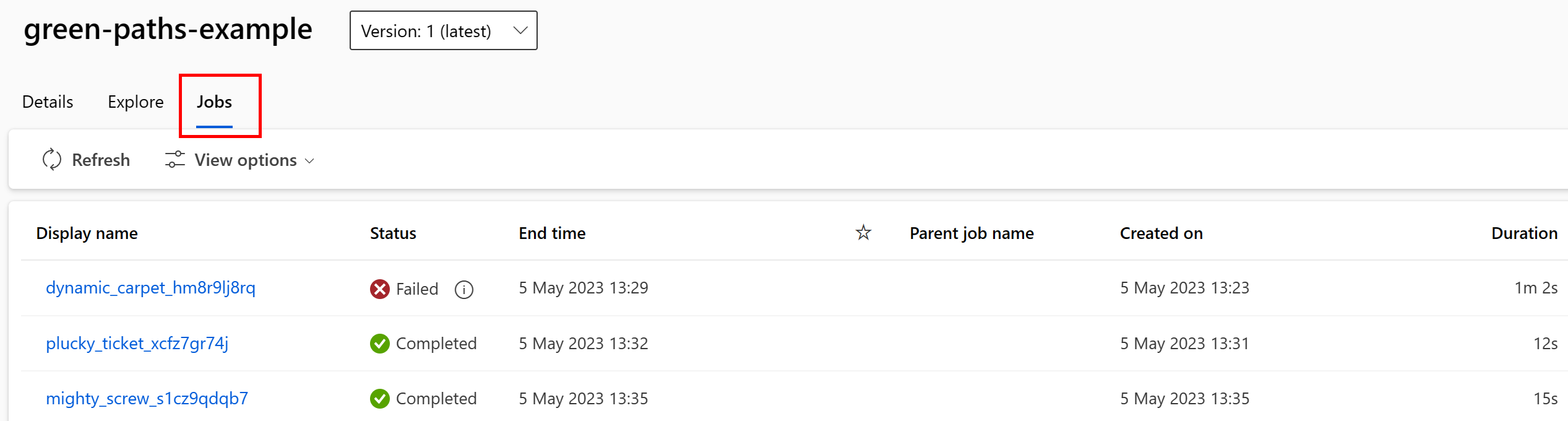
De takenweergave in gegevensassets maakt het gemakkelijker om taakfouten te vinden en hoofdoorzaakanalyse uit te voeren in uw ML-pijplijnen en foutopsporing.
Taggen van gegevensassets
Gegevensassets ondersteunen taggen. Dit zijn extra metagegevens die als sleutel-waardepaar worden toegepast op de gegevensasset. Gegevenstags bieden veel voordelen:
- Beschrijving van gegevenskwaliteit. Als uw organisatie bijvoorbeeld gebruikmaakt van een medalsight lakehouse-architectuur, kunt u assets taggen met
medallion:bronze(onbewerkt),medallion:silver(gevalideerd) enmedallion:gold(verrijkt). - Efficiënt zoeken en filteren van gegevens, zodat gegevens kunnen worden gedetecteerd.
- Identificatie van gevoelige persoonsgegevens om de toegang tot gegevens correct te beheren en te beheren. Bijvoorbeeld:
sensitivity:PII/sensitivity:nonPII. - Bepalen of gegevens al dan niet worden goedgekeurd door een verantwoorde AI-audit (RAI). Bijvoorbeeld:
RAI_audit:approved/RAI_audit:todo.
U kunt tags toevoegen aan gegevensassets als onderdeel van hun aanmaakstroom of u kunt tags toevoegen aan bestaande gegevensassets. In deze sectie ziet u beide:
Tags toevoegen als onderdeel van de stroom voor het maken van gegevensassets
Maak een YAML-bestand en kopieer en plak de volgende code in dat YAML-bestand. Zorg ervoor dat u de <> tijdelijke aanduidingen bijwerkt met de
- naam van uw gegevensasset
- de versie
- beschrijving
- tags (sleutel-waardeparen)
- pad naar één bestand op een ondersteunde locatie
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
Voer de volgende opdracht uit in de CLI. Zorg ervoor dat u de <filename> tijdelijke aanduiding bijwerkt naar de YAML-bestandsnaam.
az ml data create -f <filename>.yml
Tags toevoegen aan een bestaande gegevensasset
Voer de volgende opdracht uit in de Azure CLI. Zorg ervoor dat u de <> tijdelijke aanduidingen bijwerkt met de
- Naam van uw gegevensasset
- De versie
- Sleutel-waardepaar voor de tag
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

Best practices voor versiebeheer
Normaal gesproken organiseren uw ETL-processen uw mapstructuur in Azure Storage op tijd, bijvoorbeeld:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
Met de combinatie van gestructureerde mappen met tijd/versie en Azure Machine Learning-tabellen (MLTable) kunt u versiegegevenssets maken. Een hypothetisch voorbeeld laat zien hoe u versiegegevens kunt verkrijgen met Azure Machine Learning-tabellen. Stel dat u elke week een proces hebt waarmee camera-afbeeldingen worden geüpload naar Azure Blob Storage, in deze structuur:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Notitie
Hoewel we laten zien hoe u versie-installatiekopiegegevens (jpeg) gebruikt, werkt dezelfde benadering voor elk bestandstype (bijvoorbeeld Parquet, CSV).
Met Azure Machine Learning-tabellen (mltable) maakt u een tabel met paden die de gegevens tot het einde van de eerste week in 2023 bevatten. Maak vervolgens een gegevensasset:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Aan het einde van de volgende week heeft uw ETL de gegevens bijgewerkt om meer gegevens op te nemen:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
De eerste versie (20230108) blijft alleen bestanden koppelen/downloaden van year=2022/week=52 en year=2023/week=1 omdat de paden in het MLTable bestand worden gedeclareerd. Dit zorgt voor reproduceerbaarheid voor uw experimenten. Als u een nieuwe versie van de gegevensasset wilt maken die deze bevat year=2023/week2, gebruikt u:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
U hebt nu twee versies van de gegevens, waarbij de naam van de versie overeenkomt met de datum waarop de afbeeldingen naar de opslag zijn geüpload:
- 20230108: De afbeeldingen tot 2023-jan-08.
- 20230115: De afbeeldingen tot 2023-jan-15.
In beide gevallen maakt MLTable een tabel met paden die alleen de afbeeldingen tot die datums bevatten.
In een Azure Machine Learning-taak kunt u deze paden in de versie van MLTable koppelen of downloaden naar uw rekendoel met behulp van de eval_download of eval_mount modi:
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
Notitie
De eval_mount en eval_download modi zijn uniek voor MLTable. In dit geval evalueert de AzureML-gegevensruntime het MLTable bestand en koppelt u de paden op het rekendoel.