Azure Machine Learning Studio gebruiken in een virtueel Azure-netwerk
Tip
Microsoft raadt het gebruik van door Azure Machine Learning beheerde virtuele netwerken aan in plaats van de stappen in dit artikel. Met een beheerd virtueel netwerk verwerkt Azure Machine Learning de taak van netwerkisolatie voor uw werkruimte en beheerde berekeningen. U kunt ook privé-eindpunten toevoegen voor resources die nodig zijn voor de werkruimte, zoals een Azure Storage-account. Zie Werkruimte-beheerd netwerkisolatie voor meer informatie.
In dit artikel wordt uitgelegd hoe u Azure Machine Learning-studio gebruikt in een virtueel netwerk. De studio bevat functies zoals AutoML, de ontwerper en gegevenslabels.
Sommige functies van de studio zijn standaard uitgeschakeld in een virtueel netwerk. Als u deze functies opnieuw wilt inschakelen, moet u beheerde identiteit inschakelen voor opslagaccounts die u in de studio wilt gebruiken.
De volgende bewerkingen zijn standaard uitgeschakeld in een virtueel netwerk:
- Voorbeeld van gegevens in de studio bekijken.
- Gegevens visualiseren in de ontwerpfunctie.
- Een model in de ontwerpfunctie implementeren.
- Een AutoML-experiment indienen.
- Een labelproject beginnen.
De studio ondersteunt het lezen van gegevens uit de volgende gegevensopslagtypen in een virtueel netwerk:
- Azure Storage-account (blob en bestand)
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure SQL Database
In dit artikel leert u het volgende:
- Geef de studio toegang tot gegevens die zijn opgeslagen in een virtueel netwerk.
- Open de studio vanuit een resource in een virtueel netwerk.
- Inzicht in hoe de studio van invloed is op opslagbeveiliging.
Vereisten
Lees het overzicht van netwerkbeveiliging om inzicht te hebben in veelvoorkomende scenario's en architectuur voor virtuele netwerken.
Een bestaand virtueel netwerk en subnet dat moet worden gebruikt.
Een bestaande Azure Machine Learning-werkruimte met een privé-eindpunt.
Een bestaand Azure-opslagaccount heeft uw virtuele netwerk toegevoegd.
Een bestaande Azure Machine Learning-werkruimte met een privé-eindpunt.
Een bestaand Azure-opslagaccount heeft uw virtuele netwerk toegevoegd.
- Zie Zelfstudie: Een beveiligde werkruimte of zelfstudie maken: Een beveiligde werkruimte maken: een beveiligde werkruimte maken met behulp van een sjabloon voor meer informatie over het maken van een beveiligde werkruimte.
Beperkingen
Azure-opslagaccount
Wanneer het opslagaccount zich in het virtuele netwerk bevindt, zijn er extra validatievereisten voor het gebruik van studio:
- Als het opslagaccount een service-eindpunt gebruikt, moeten het privé-eindpunt van de werkruimte en het eindpunt van de opslagservice zich in hetzelfde subnet van het virtuele netwerk bevinden.
- Als het opslagaccount een privé-eindpunt gebruikt, moeten het privé-eindpunt van de werkruimte en het privé-eindpunt van de opslag zich in hetzelfde virtuele netwerk bevinden. In dit geval kunnen ze zich in verschillende subnetten bevinden.
Voorbeeldpijplijn designer
Er is een bekend probleem waarbij gebruikers geen voorbeeldpijplijn kunnen uitvoeren op de startpagina van de ontwerpfunctie. Dit probleem treedt op omdat de voorbeeldgegevensset die in de voorbeeldpijplijn wordt gebruikt, een globale Azure-gegevensset is. Deze kan niet worden geopend vanuit een virtuele netwerkomgeving.
U kunt dit probleem oplossen door een openbare werkruimte te gebruiken om de voorbeeldpijplijn uit te voeren. Of vervang de voorbeeldgegevensset door uw eigen gegevensset in de werkruimte in een virtueel netwerk.
Gegevensarchief: Azure Storage-account
Gebruik de volgende stappen om toegang in te schakelen tot gegevens die zijn opgeslagen in Azure Blob en File Storage:
Tip
De eerste stap is niet vereist voor het standaardopslagaccount voor de werkruimte. Alle andere stappen zijn vereist voor elk opslagaccount achter het VNet en wordt gebruikt door de werkruimte, inclusief het standaardopslagaccount.
Als het opslagaccount de standaardopslag voor uw werkruimte is, slaat u deze stap over. Als dit niet de standaardinstelling is, verleent u de door de werkruimte beheerde identiteit de rol Opslagblobgegevenslezer voor het Azure-opslagaccount, zodat deze gegevens uit blobopslag kan lezen.
Zie de ingebouwde rol blobgegevenslezer voor meer informatie.
Verdeel uw Azure-gebruikersidentiteit de rol opslagblobgegevenslezer voor het Azure-opslagaccount. De studio gebruikt uw identiteit voor toegang tot gegevens tot blobopslag, zelfs als de beheerde identiteit van de werkruimte de rol Lezer heeft.
Zie de ingebouwde rol blobgegevenslezer voor meer informatie.
Verdeel de beheerde identiteit van de werkruimte de rol Lezer voor privé-eindpunten voor opslag. Als uw opslagservice een privé-eindpunt gebruikt, verleent u de lezer van de beheerde identiteit van de werkruimte toegang tot het privé-eindpunt. De beheerde identiteit van de werkruimte in Microsoft Entra ID heeft dezelfde naam als uw Azure Machine Learning-werkruimte. Een privé-eindpunt is nodig voor zowel blob- als bestandsopslagtypen.
Tip
Uw opslagaccount heeft mogelijk meerdere privé-eindpunten. Eén opslagaccount kan bijvoorbeeld een afzonderlijk privé-eindpunt hebben voor blob, bestand en dfs (Azure Data Lake Storage Gen2). Voeg de beheerde identiteit toe aan al deze eindpunten.
Zie de ingebouwde rol Lezer voor meer informatie.
Schakel verificatie van beheerde identiteiten in voor standaardopslagaccounts. Elke Azure Machine Learning-werkruimte heeft twee standaardopslagaccounts, een standaard blob-opslagaccount en een standaardbestandsarchiefaccount. Beide worden gedefinieerd wanneer u uw werkruimte maakt. U kunt ook nieuwe standaardwaarden instellen op de beheerpagina Gegevensarchief.
In de volgende tabel wordt beschreven waarom verificatie van beheerde identiteit wordt gebruikt voor de standaardopslagaccounts van uw werkruimte.
Opslagaccount Opmerkingen Standaard-blobopslag voor werkruimten Slaat modelassets op van de ontwerpfunctie. Schakel verificatie van beheerde identiteiten in voor dit opslagaccount om modellen in de ontwerpfunctie te implementeren. Als verificatie van beheerde identiteit is uitgeschakeld, wordt de identiteit van de gebruiker gebruikt voor toegang tot gegevens die zijn opgeslagen in de blob.
U kunt een ontwerppijplijn visualiseren en uitvoeren als er een niet-standaardgegevensarchief wordt gebruikt dat is geconfigureerd voor het gebruik van beheerde identiteit. Als u echter probeert een getraind model te implementeren zonder dat beheerde identiteit is ingeschakeld voor het standaardgegevensarchief, mislukt de implementatie, ongeacht alle andere gegevensarchieven die worden gebruikt.Standaardbestandsarchief voor werkruimte Slaat AutoML-experimentassets op. Schakel verificatie van beheerde identiteiten in voor dit opslagaccount om AutoML-experimenten te verzenden. Configureer gegevensarchieven voor het gebruik van verificatie van beheerde identiteiten. Nadat u een Azure-opslagaccount hebt toegevoegd aan uw virtuele netwerk met een service-eindpunt of privé-eindpunt, moet u uw gegevensarchief configureren voor het gebruik van verificatie van beheerde identiteiten. Hierdoor heeft de studio toegang tot gegevens in uw opslagaccount.
Azure Machine Learning maakt gebruik van een gegevensarchief om verbinding te maken met opslagaccounts. Wanneer u een nieuw gegevensarchief maakt, gebruikt u de volgende stappen om een gegevensarchief te configureren voor het gebruik van verificatie van beheerde identiteiten:
Selecteer Gegevensarchieven in de studio.
Als u een nieuw gegevensarchief wilt maken, selecteert u + Maken.
Schakel in de instellingen voor het gegevensarchief de schakeloptie voor door de werkruimte beheerde identiteit gebruiken in voor gegevensvoorbeelden en profilering in Azure Machine Learning-studio.
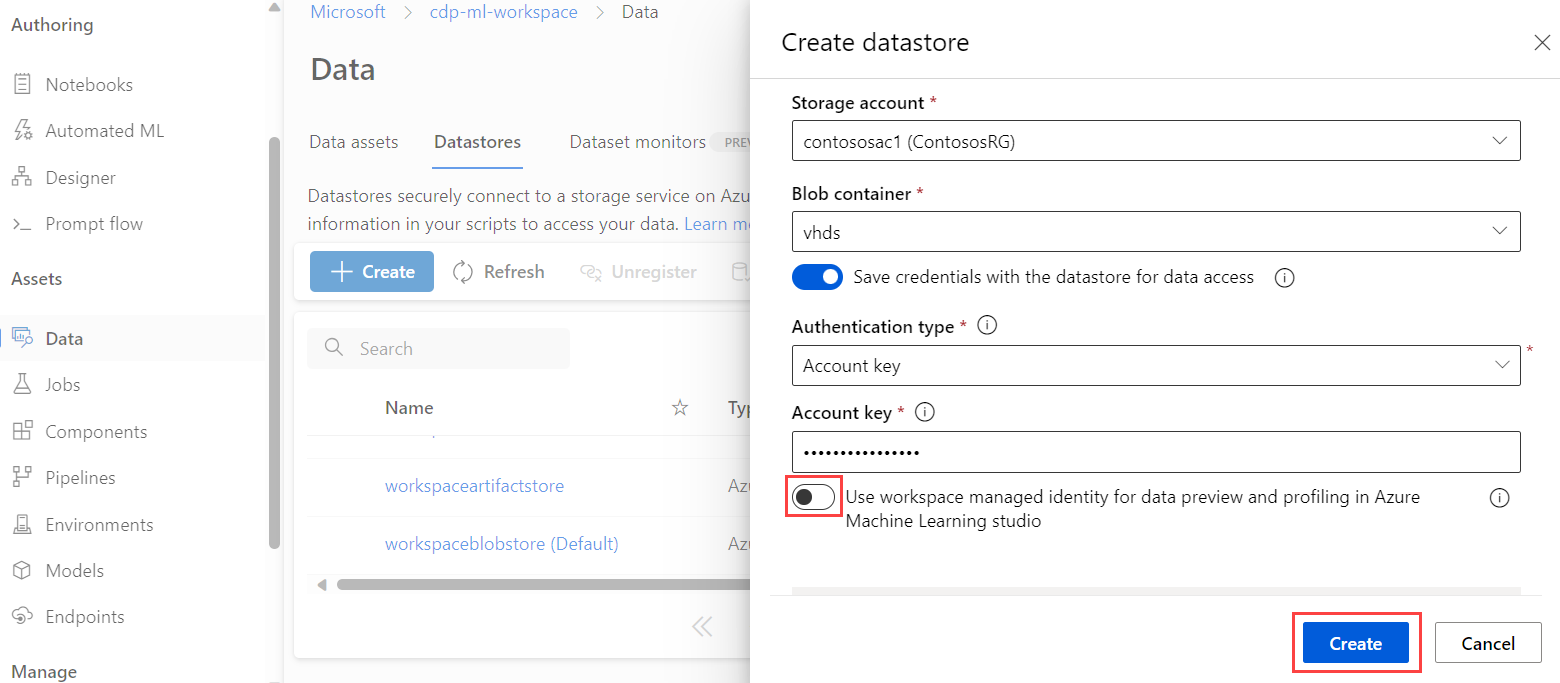
Voeg in de netwerkinstellingen voor het Azure Storage-account het
Microsoft.MachineLearningService/workspacesresourcetype toe en stel de naam van het exemplaar in op de werkruimte.
Met deze stappen voegt u de beheerde identiteit van de werkruimte toe als lezer aan de nieuwe opslagservice met behulp van op rollen gebaseerd toegangsbeheer van Azure (RBAC). Met lezertoegang kan de werkruimte de resource bekijken, maar geen wijzigingen aanbrengen.


Gegevensarchief: Azure Data Lake Storage Gen1
Wanneer u Azure Data Lake Storage Gen1 als gegevensarchief gebruikt, kunt u alleen posix-achtige toegangsbeheerlijsten gebruiken. U kunt de beheerde identiteit van de werkruimte net als elke andere beveiligingsprincipaal toewijzen aan resources. Zie Toegangsbeheer in Azure Data Lake Storage Gen1 voor meer informatie.
Gegevensarchief: Azure Data Lake Storage Gen2
Wanneer u Azure Data Lake Storage Gen2 als gegevensarchief gebruikt, kunt u toegangsbeheerlijsten (ACL's) van Azure RBAC en POSIX gebruiken om de toegang tot gegevens in een virtueel netwerk te beheren.
Als u Azure RBAC wilt gebruiken, volgt u de stappen in het gedeelte Datastore: Azure Storage-account van dit artikel. Data Lake Storage Gen2 is gebaseerd op Azure Storage, dus dezelfde stappen zijn van toepassing wanneer u Azure RBAC gebruikt.
Als u ACL's wilt gebruiken, kan de beheerde identiteit van de werkruimte net als elke andere beveiligingsprincipal worden toegewezen. Zie Toegangsbeheerlijsten voor bestanden en mappen voor meer informatie.
Gegevensarchief: Azure SQL Database
Als u toegang wilt krijgen tot gegevens die zijn opgeslagen in een Azure SQL Database met een beheerde identiteit, moet u een in SQL opgenomen gebruiker maken die is toegewezen aan de beheerde identiteit. Zie Ingesloten gebruikers maken die zijn toegewezen aan Microsoft Entra-identiteiten voor meer informatie over het maken van een gebruiker van een externe provider.
Nadat u een ingesloten SQL-gebruiker hebt gemaakt, verleent u er machtigingen aan met behulp van de opdracht GRANT T-SQL.
Uitvoer van tussenliggende onderdelen
Wanneer u de uitvoer van de tussenliggende onderdelen van azure Machine Learning Designer gebruikt, kunt u de uitvoerlocatie opgeven voor elk onderdeel in de ontwerpfunctie. Gebruik deze uitvoer om tussenliggende gegevenssets op een afzonderlijke locatie op te slaan voor beveiligings-, logboek- of controledoeleinden. Voer de volgende stappen uit om uitvoer op te geven:
- Selecteer het onderdeel waarvan u de uitvoer wilt opgeven.
- Selecteer uitvoerinstellingen in het deelvenster Met onderdeelinstellingen.
- Geef het gegevensarchief op dat u wilt gebruiken voor de uitvoer van elk onderdeel.
Zorg ervoor dat u toegang hebt tot de tussenliggende opslagaccounts in uw virtuele netwerk. Anders mislukt de pijplijn.
Schakel verificatie van beheerde identiteit in voor tussenliggende opslagaccounts om uitvoergegevens te visualiseren.
Toegang tot de studio vanuit een resource in het VNet
Als u de studio opent vanuit een resource in een virtueel netwerk (bijvoorbeeld een rekenproces of virtuele machine), moet u uitgaand verkeer van het virtuele netwerk naar de studio toestaan.
Als u bijvoorbeeld netwerkbeveiligingsgroepen (NSG) gebruikt om uitgaand verkeer te beperken, voegt u een regel toe aan een servicetagbestemming van AzureFrontDoor.Frontend.
Firewallinstellingen
Sommige opslagservices, zoals Azure Storage-account, hebben firewallinstellingen die van toepassing zijn op het openbare eindpunt voor dat specifieke service-exemplaar. Meestal kunt u met deze instelling toegang vanaf specifieke IP-adressen vanaf het openbare internet toestaan/weigeren. Dit wordt niet ondersteund bij het gebruik van Azure Machine Learning-studio. Dit wordt ondersteund bij het gebruik van de Azure Machine Learning SDK of CLI.
Tip
Azure Machine Learning-studio wordt ondersteund bij het gebruik van de Azure Firewall-service. Zie Inkomend en uitgaand netwerkverkeer configureren voor meer informatie.
Gerelateerde inhoud
Dit artikel maakt deel uit van een reeks over het beveiligen van een Azure Machine Learning-werkstroom. Zie de andere artikelen in deze reeks: