In dit artikel leert u hoe u Open Neural Network Exchange (ONNX) gebruikt om voorspellingen te doen op computer vision-modellen die zijn gegenereerd op basis van geautomatiseerde machine learning (AutoML) in Azure Machine Learning.
Als u ONNX wilt gebruiken voor voorspellingen, moet u het volgende doen:
Download ONNX-modelbestanden uit een AutoML-trainingsuitvoering.
Inzicht in de invoer en uitvoer van een ONNX-model.
Verwerkt uw gegevens vooraf zodat deze de vereiste indeling hebben voor invoerafbeeldingen.
Deductie uitvoeren met ONNX Runtime voor Python.
Visualiseer voorspellingen voor objectdetectie en exemplaarsegmentatietaken.
ONNX is een open standaard voor machine learning- en Deep Learning-modellen. Hiermee kunt u model importeren en exporteren (interoperabiliteit) in de populaire AI-frameworks. Bekijk het ONNX GitHub-project voor meer informatie.
ONNX Runtime is een opensource-project dat ondersteuning biedt voor platformoverschrijdende deductie. ONNX Runtime biedt API's voor programmeertalen (waaronder Python, C++, C#, C, Java en JavaScript). U kunt deze API's gebruiken om deductie uit te voeren op invoerafbeeldingen. Nadat u het model hebt geëxporteerd naar de ONNX-indeling, kunt u deze API's gebruiken voor elke programmeertaal die uw project nodig heeft.
In deze handleiding leert u hoe u Python-API's voor ONNX Runtime gebruikt om voorspellingen te doen over afbeeldingen voor populaire vision-taken. U kunt deze geëxporteerde ONNX-modellen in verschillende talen gebruiken.
Installeer het onnxruntime-pakket . De methoden in dit artikel zijn getest met versie 1.3.0 tot en met 1.8.0.
ONNX-modelbestanden downloaden
U kunt ONNX-modelbestanden downloaden van AutoML-uitvoeringen met behulp van de Azure Machine Learning-studio-gebruikersinterface of de Azure Machine Learning Python SDK. U kunt het beste downloaden via de SDK met de naam van het experiment en de bovenliggende uitvoerings-id.
Azure Machine Learning Studio
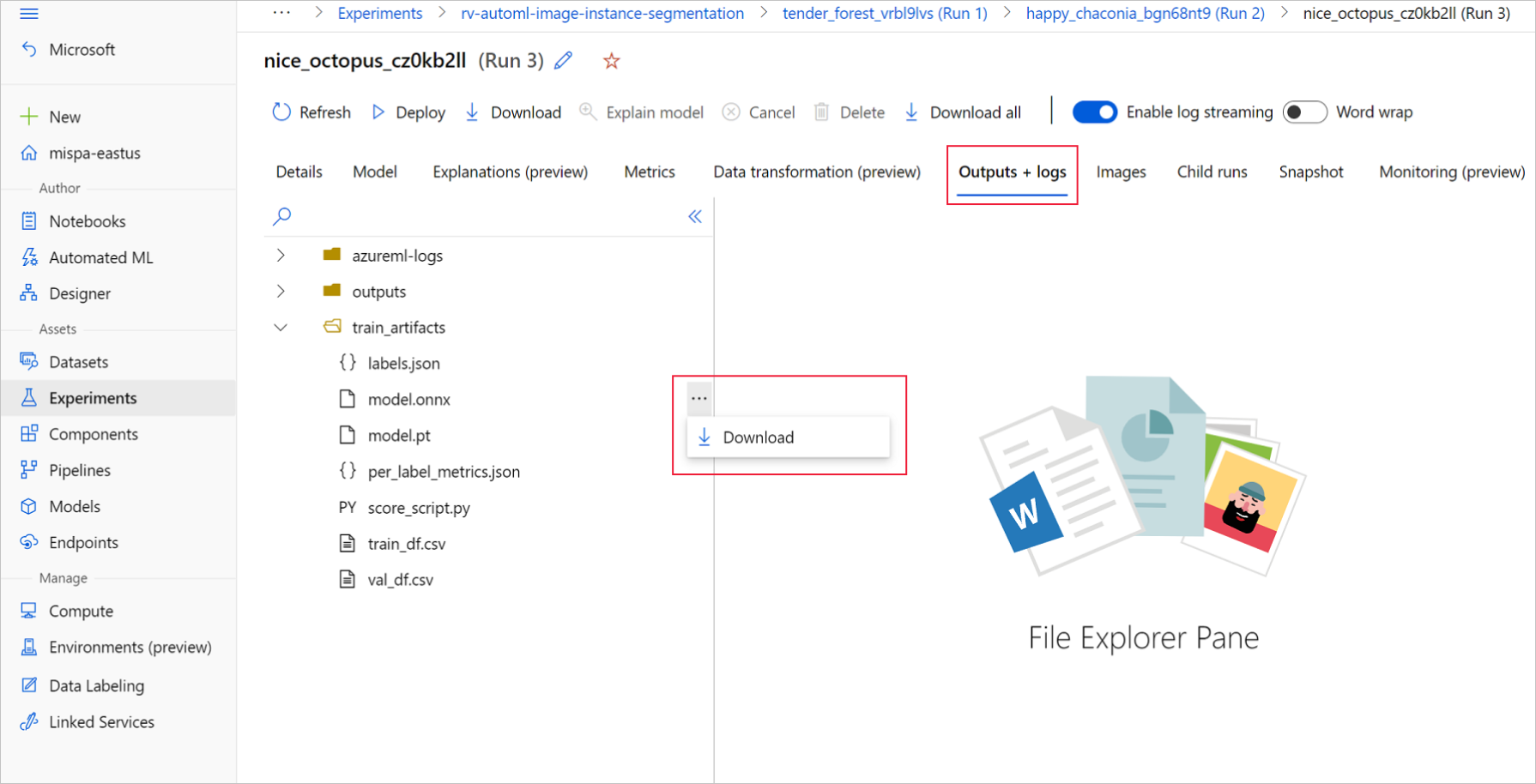
Ga in Azure Machine Learning-studio naar uw experiment met behulp van de hyperlink naar het experiment dat is gegenereerd in het trainingsnotitieblok of door de naam van het experiment te selecteren op het tabblad Experimenten onder Assets. Selecteer vervolgens de beste onderliggende uitvoering.
Ga binnen de beste onderliggende uitvoering naar Outputs+logs>train_artifacts. Gebruik de knop Downloaden om de volgende bestanden handmatig te downloaden:
labels.json: bestand dat alle klassen of labels in de trainingsgegevensset bevat.
model.onnx: Model in ONNX-indeling.
Sla de gedownloade modelbestanden op in een map. In het voorbeeld in dit artikel wordt de map ./automl_models gebruikt.
Python SDK voor Azure Machine Learning
Met de SDK kunt u de beste onderliggende uitvoering (op primaire metrische gegevens) selecteren met de naam van het experiment en de bovenliggende uitvoerings-id. Vervolgens kunt u de labels.json- en model.onnx-bestanden downloaden.
De volgende code retourneert de beste onderliggende uitvoering op basis van de relevante primaire metrische gegevens.
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
mlflow_client = MlflowClient()
credential = DefaultAzureCredential()
ml_client = None
try:
ml_client = MLClient.from_config(credential)
except Exception as ex:
print(ex)
# Enter details of your Azure Machine Learning workspace
subscription_id = ''
resource_group = ''
workspace_name = ''
ml_client = MLClient(credential, subscription_id, resource_group, workspace_name)
import mlflow
from mlflow.tracking.client import MlflowClient
# Obtain the tracking URL from MLClient
MLFLOW_TRACKING_URI = ml_client.workspaces.get(
name=ml_client.workspace_name
).mlflow_tracking_uri
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
# Specify the job name
job_name = ''
# Get the parent run
mlflow_parent_run = mlflow_client.get_run(job_name)
best_child_run_id = mlflow_parent_run.data.tags['automl_best_child_run_id']
# get the best child run
best_run = mlflow_client.get_run(best_child_run_id)
Download het labels.json-bestand , dat alle klassen en labels in de trainingsgegevensset bevat.
local_dir = './automl_models'
if not os.path.exists(local_dir):
os.mkdir(local_dir)
labels_file = mlflow_client.download_artifacts(
best_run.info.run_id, 'train_artifacts/labels.json', local_dir
)
AutoML voor afbeeldingen ondersteunt standaard batchgewijs scoren voor classificatie. Maar objectdetectie en exemplaarsegmentatie ONNX-modellen bieden geen ondersteuning voor batchdeductie. In het geval van batchdeductie voor objectdetectie en exemplaarsegmentatie gebruikt u de volgende procedure om een ONNX-model te genereren voor de vereiste batchgrootte. Modellen die zijn gegenereerd voor een specifieke batchgrootte werken niet voor andere batchgrootten.
Download het conda-omgevingsbestand en maak een omgevingsobject dat moet worden gebruikt met de opdrachttaak.
# Download conda file and define the environment
conda_file = mlflow_client.download_artifacts(
best_run.info.run_id, "outputs/conda_env_v_1_0_0.yml", local_dir
)
from azure.ai.ml.entities import Environment
env = Environment(
name="automl-images-env-onnx",
description="environment for automl images ONNX batch model generation",
image="mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.1-cudnn8-ubuntu18.04",
conda_file=conda_file,
)
Gebruik de volgende modelspecifieke argumenten om het script in te dienen. Raadpleeg voor meer informatie over argumenten modelspecifieke hyperparameters en voor ondersteunde objectdetectiemodelnamen de sectie ondersteunde modelarchitectuur.
Als u de argumentwaarden wilt ophalen die nodig zijn om het batchscoremodel te maken, raadpleegt u de scorescripts die zijn gegenereerd onder de uitvoermap van de AutoML-trainingsuitvoeringen. Gebruik de hyperparameterwaarden die beschikbaar zijn in de variabele modelinstellingen in het scorebestand voor de beste onderliggende uitvoering.
Voor afbeeldingsclassificatie met meerdere klassen ondersteunt het gegenereerde ONNX-model voor de beste onderliggende uitvoering standaard batchscores. Daarom zijn er geen modelspecifieke argumenten nodig voor dit taaktype en kunt u doorgaan naar de sectie Labels en ONNX-modelbestanden laden.
Voor afbeeldingsclassificatie met meerdere labels ondersteunt het gegenereerde ONNX-model voor de beste onderliggende uitvoering standaard batchgewijs scoren. Daarom zijn er geen modelspecifieke argumenten nodig voor dit taaktype en kunt u doorgaan naar de sectie Labels en ONNX-modelbestanden laden.
inputs = {'model_name': 'fasterrcnn_resnet34_fpn', # enter the faster rcnn or retinanet model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
inputs = {'model_name': 'yolov5', # enter the yolo model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 640, # enter the height of input to ONNX model
'width_onnx': 640, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'img_size': 640, # image size for inference
'model_size': 'small', # size of the yolo model
'box_score_thresh': 0.1, # threshold to return proposals with a classification score > box_score_thresh
'box_iou_thresh': 0.5
}
inputs = {'model_name': 'maskrcnn_resnet50_fpn', # enter the maskrcnn model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-instance-segmentation',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
Download en bewaar het ONNX_batch_model_generator_automl_for_images.py bestand in de huidige map om het script in te dienen. Gebruik de volgende opdrachttaak om het script ONNX_batch_model_generator_automl_for_images.py te verzenden dat beschikbaar is in de GitHub-opslagplaats met azureml-voorbeelden om een ONNX-model van een specifieke batchgrootte te genereren. In de volgende code wordt de getrainde modelomgeving gebruikt om dit script te verzenden om het ONNX-model te genereren en op te slaan in de uitvoermap.
Voor afbeeldingsclassificatie met meerdere klassen ondersteunt het gegenereerde ONNX-model voor de beste onderliggende uitvoering standaard batchscores. Daarom zijn er geen modelspecifieke argumenten nodig voor dit taaktype en kunt u doorgaan naar de sectie Labels en ONNX-modelbestanden laden.
Voor afbeeldingsclassificatie met meerdere labels ondersteunt het gegenereerde ONNX-model voor de beste onderliggende uitvoering standaard batchgewijs scoren. Daarom zijn er geen modelspecifieke argumenten nodig voor dit taaktype en kunt u doorgaan naar de sectie Labels en ONNX-modelbestanden laden.
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-rcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --img_size ${{inputs.img_size}} --model_size ${{inputs.model_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_iou_thresh ${{inputs.box_iou_thresh}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-maskrcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
Zodra het batchmodel is gegenereerd, downloadt u het vanuit Outputs+logs> handmatig via de gebruikersinterface of gebruikt u de volgende methode:
batch_size = 8 # use the batch size used to generate the model
returned_job_run = mlflow_client.get_run(returned_job.name)
# Download run's artifacts/outputs
onnx_model_path = mlflow_client.download_artifacts(
returned_job_run.info.run_id, 'outputs/model_'+str(batch_size)+'.onnx', local_dir
)
Na de stap voor het downloaden van het model gebruikt u het PYTHON-pakket ONNX Runtime om deductie uit te voeren met behulp van het bestand model.onnx . Voor demonstratiedoeleinden gebruikt dit artikel de gegevenssets uit Het voorbereiden van afbeeldingsgegevenssets voor elke vision-taak.
We hebben de modellen getraind voor alle vision-taken met hun respectieve gegevenssets om deductie van ONNX-modellen te demonstreren.
De labels en ONNX-modelbestanden laden
Met het volgende codefragment wordt labels.json geladen, waarbij klassenamen worden geordend. Dat wil zeggen dat als het ONNX-model een label-id voorspelt als 2, het overeenkomt met de labelnaam die is opgegeven bij de derde index in het labels.json bestand.
import json
import onnxruntime
labels_file = "automl_models/labels.json"
with open(labels_file) as f:
classes = json.load(f)
print(classes)
try:
session = onnxruntime.InferenceSession(onnx_model_path)
print("ONNX model loaded...")
except Exception as e:
print("Error loading ONNX file: ", str(e))
Verwachte invoer- en uitvoerdetails voor een ONNX-model ophalen
Wanneer u het model hebt, is het belangrijk om bepaalde modelspecifieke en taakspecifieke details te kennen. Deze details omvatten het aantal invoer- en uitvoerwaarden, de verwachte invoervorm of -indeling voor het vooraf verwerken van de afbeelding en de uitvoershape, zodat u de modelspecifieke of taakspecifieke uitvoer kent.
sess_input = session.get_inputs()
sess_output = session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
for idx, input_ in enumerate(range(len(sess_input))):
input_name = sess_input[input_].name
input_shape = sess_input[input_].shape
input_type = sess_input[input_].type
print(f"{idx} Input name : { input_name }, Input shape : {input_shape}, \
Input type : {input_type}")
for idx, output in enumerate(range(len(sess_output))):
output_name = sess_output[output].name
output_shape = sess_output[output].shape
output_type = sess_output[output].type
print(f" {idx} Output name : {output_name}, Output shape : {output_shape}, \
Output type : {output_type}")
Verwachte invoer- en uitvoerindelingen voor het ONNX-model
Elk ONNX-model heeft een vooraf gedefinieerde set invoer- en uitvoerindelingen.
Invoer is een vooraf verwerkte afbeelding, met de shape (1, 3, 224, 224) voor een batchgrootte van 1 en een hoogte en breedte van 224. Deze getallen komen overeen met de waarden die in het trainingsvoorbeeld worden gebruikt crop_size .
Uitvoerindeling
De uitvoer is een matrix met logboeken voor alle klassen/labels.
Uitvoernaam
Uitvoershape
Uitvoertype
Beschrijving
output1
(batch_size, num_classes)
ndarray(float)
Model retourneert logboeken (zonder softmax). Voor batchgrootte 1 en 4 klassen retourneert (1, 4)deze bijvoorbeeld .
In dit voorbeeld wordt het model gebruikt dat is getraind op de gegevensset koelkastobjecten met 128 afbeeldingen en 4 klassen/labels om deductie van ONNX-modellen uit te leggen. Zie het notitieblok voor afbeeldingsclassificatie met meerdere labels voor meer informatie over modeltraining voor afbeeldingsclassificatie met meerdere labels.
Invoerindeling
Invoer is een vooraf verwerkte afbeelding.
Invoernaam
Invoershape
Input type
Beschrijving
input1
(batch_size, num_channels, height, width)
ndarray(float)
Invoer is een vooraf verwerkte afbeelding, met de shape (1, 3, 224, 224) voor een batchgrootte van 1 en een hoogte en breedte van 224. Deze getallen komen overeen met de waarden die in het trainingsvoorbeeld worden gebruikt crop_size .
Uitvoerindeling
De uitvoer is een matrix met logboeken voor alle klassen/labels.
Uitvoernaam
Uitvoershape
Uitvoertype
Beschrijving
output1
(batch_size, num_classes)
ndarray(float)
Model retourneert logboeken (zonder sigmoid). Voor batchgrootte 1 en 4 klassen retourneert (1, 4)deze bijvoorbeeld .
In dit voorbeeld van objectdetectie wordt het model gebruikt dat is getraind op de koelkastObjects-detectiegegevensset van 128 afbeeldingen en 4 klassen/labels om deductie van ONNX-modellen uit te leggen. In dit voorbeeld worden snellere R-CNN-modellen getraind om deductiestappen te demonstreren. Zie het notitieblok voor objectdetectie voor objecten voor meer informatie over trainingsobjectdetectiemodellen.
Invoerindeling
Invoer is een vooraf verwerkte afbeelding.
Invoernaam
Invoershape
Input type
Beschrijving
Invoer
(batch_size, num_channels, height, width)
ndarray(float)
Invoer is een vooraf verwerkte afbeelding, met de shape (1, 3, 600, 800) voor een batchgrootte van 1 en een hoogte van 600 en een breedte van 800.
Uitvoerindeling
De uitvoer is een tuple van output_names en voorspellingen. output_names Hier en predictions zijn lijsten met lengte 3*batch_size elk. Voor snellere R-CNN-volgorde van uitvoer zijn vakken, labels en scores, terwijl voor RetinaNet-uitvoer vakken, scores, labels zijn.
Uitvoernaam
Uitvoershape
Uitvoertype
Beschrijving
output_names
(3*batch_size)
Lijst met sleutels
Voor een batchgrootte van 2, output_names is ['boxes_0', 'labels_0', 'scores_0', 'boxes_1', 'labels_1', 'scores_1']
predictions
(3*batch_size)
Lijst met ndarray(float)
Voor een batchgrootte van 2, predictions neemt u de vorm van [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n2_boxes, 4), (n2_boxes), (n2_boxes)]. Hier komen waarden bij elke index overeen met dezelfde index in output_names.
In de volgende tabel worden vakken, labels en scores beschreven die worden geretourneerd voor elk voorbeeld in de batch met afbeeldingen.
Naam
Vorm
Type
Description
Dozen
(n_boxes, 4), waarbij elk vak x_min, y_min, x_max, y_max
ndarray(float)
Model retourneert n vakken met de coördinaten linksboven en rechtsonder.
Etiketten
(n_boxes)
ndarray(float)
Label of klasse-id van een object in elk vak.
Scores
(n_boxes)
ndarray(float)
Betrouwbaarheidsscore van een object in elk vak.
In dit voorbeeld van objectdetectie wordt het model gebruikt dat is getraind op de koelkastObjects-detectiegegevensset van 128 afbeeldingen en 4 klassen/labels om deductie van ONNX-modellen uit te leggen. In dit voorbeeld worden YOLO-modellen getraind om deductiestappen te demonstreren. Zie het notitieblok voor objectdetectie voor objecten voor meer informatie over trainingsobjectdetectiemodellen.
Invoerindeling
De invoer is een vooraf verwerkte afbeelding, met de vorm (1, 3, 640, 640) voor een batchgrootte van 1 en een hoogte en breedte van 640. Deze getallen komen overeen met de waarden die in het trainingsvoorbeeld worden gebruikt.
Invoernaam
Invoershape
Input type
Beschrijving
Invoer
(batch_size, num_channels, height, width)
ndarray(float)
Invoer is een vooraf verwerkte afbeelding, met de shape (1, 3, 640, 640) voor een batchgrootte van 1 en een hoogte van 640 en een breedte van 640.
Uitvoerindeling
ONNX-modelvoorspellingen bevatten meerdere uitvoer. De eerste uitvoer is nodig om niet-maximale onderdrukking voor detecties uit te voeren. Voor gebruiksgemak geeft geautomatiseerde ML de uitvoerindeling weer na de nms-naverwerkingsstap. De uitvoer na NMS is een lijst met vakken, labels en scores voor elk voorbeeld in de batch.
Uitvoernaam
Uitvoershape
Uitvoertype
Beschrijving
Uitvoer
(batch_size)
Lijst met ndarray(float)
Model retourneert boxdetecties voor elk voorbeeld in de batch
Elke cel in de lijst geeft vakdetecties aan van een steekproef met vorm(n_boxes, 6), waarbij elk vak .x_min, y_min, x_max, y_max, confidence_score, class_id
Alleen Mask R-CNN wordt ondersteund voor exemplaarsegmentatietaken. De invoer- en uitvoerindelingen zijn alleen gebaseerd op Mask R-CNN.
Invoerindeling
De invoer is een vooraf verwerkte afbeelding. Het ONNX-model voor Mask R-CNN is geëxporteerd om te werken met afbeeldingen van verschillende vormen. U wordt aangeraden de grootte ervan te wijzigen in een vaste grootte die consistent is met de grootte van trainingsafbeeldingen, voor betere prestaties.
Invoernaam
Invoershape
Input type
Beschrijving
Invoer
(batch_size, num_channels, height, width)
ndarray(float)
Invoer is een vooraf verwerkte afbeelding, met vorm (1, 3, input_image_height, input_image_width) voor een batchgrootte van 1 en een hoogte en breedte die vergelijkbaar is met een invoerafbeelding.
Uitvoerindeling
De uitvoer is een tuple van output_names en voorspellingen. output_names Hier en predictions zijn lijsten met lengte 4*batch_size elk.
Uitvoernaam
Uitvoershape
Uitvoertype
Beschrijving
output_names
(4*batch_size)
Lijst met sleutels
Voor een batchgrootte van 2, output_names is ['boxes_0', 'labels_0', 'scores_0', 'masks_0', 'boxes_1', 'labels_1', 'scores_1', 'masks_1']
predictions
(4*batch_size)
Lijst met ndarray(float)
Voor een batchgrootte van 2, predictions neemt u de vorm van [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n1_boxes, 1, height_onnx, width_onnx), (n2_boxes, 4), (n2_boxes), (n2_boxes), (n2_boxes, 1, height_onnx, width_onnx)]. Hier komen waarden bij elke index overeen met dezelfde index in output_names.
Naam
Vorm
Type
Description
Dozen
(n_boxes, 4), waarbij elk vak x_min, y_min, x_max, y_max
ndarray(float)
Model retourneert n vakken met de coördinaten linksboven en rechtsonder.
Etiketten
(n_boxes)
ndarray(float)
Label of klasse-id van een object in elk vak.
Scores
(n_boxes)
ndarray(float)
Betrouwbaarheidsscore van een object in elk vak.
Maskers
(n_boxes, 1, height_onnx, width_onnx)
ndarray(float)
Maskers (veelhoeken) van gedetecteerde objecten met de hoogte en breedte van een invoerafbeelding.
Voer de volgende voorverwerkingsstappen uit voor de deductie van het ONNX-model:
Converteer de afbeelding naar RGB.
Wijzig het formaat van de afbeelding valid_resize_size en valid_resize_size waarden die overeenkomen met de waarden die tijdens de training worden gebruikt bij de transformatie van de validatiegegevensset. De standaardwaarde is valid_resize_size 256.
Centreren van de afbeelding tot height_onnx_crop_size en width_onnx_crop_sizemet . Deze komt overeen valid_crop_size met de standaardwaarde 224.
Wijzig HxWxC in CxHxW.
Converteren naar floattype.
Normaliseren met ImageNet's mean = [0.485, 0.456, 0.406] en std = [0.229, 0.224, 0.225].
Als u verschillende waarden hebt gekozen voor de hyperparametersvalid_resize_size en valid_crop_size tijdens de training, moeten deze waarden worden gebruikt.
Haal de invoershape op die nodig is voor het ONNX-model.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Met PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Voer de volgende voorverwerkingsstappen uit voor de deductie van het ONNX-model. Deze stappen zijn hetzelfde voor afbeeldingsclassificatie met meerdere klassen.
Converteer de afbeelding naar RGB.
Wijzig het formaat van de afbeelding valid_resize_size en valid_resize_size waarden die overeenkomen met de waarden die tijdens de training worden gebruikt bij de transformatie van de validatiegegevensset. De standaardwaarde is valid_resize_size 256.
Centreren van de afbeelding tot height_onnx_crop_size en width_onnx_crop_sizemet . Dit komt overeen met valid_crop_size de standaardwaarde 224.
Wijzig HxWxC in CxHxW.
Converteren naar floattype.
Normaliseren met ImageNet's mean = [0.485, 0.456, 0.406] en std = [0.229, 0.224, 0.225].
Als u verschillende waarden hebt gekozen voor de hyperparametersvalid_resize_size en valid_crop_size tijdens de training, moeten deze waarden worden gebruikt.
Haal de invoershape op die nodig is voor het ONNX-model.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Met PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Voor objectdetectie met de Snellere R-CNN-architectuur volgt u dezelfde voorverwerkingsstappen als afbeeldingsclassificatie, met uitzondering van het bijsnijden van afbeeldingen. U kunt het formaat van de afbeelding wijzigen met hoogte 600 en breedte 800. U kunt de verwachte invoerhoogte en -breedte ophalen met de volgende code.
Voer vervolgens de stappen voor voorverwerking uit.
import glob
import numpy as np
from PIL import Image
def preprocess(image, height_onnx, width_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param height_onnx: expected height of an input image in onnx model
:type height_onnx: Int
:param width_onnx: expected width of an input image in onnx model
:type width_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((width_onnx, height_onnx))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_od/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Voor objectdetectie met de YOLO-architectuur volgt u dezelfde voorverwerkingsstappen als afbeeldingsclassificatie, met uitzondering van bijsnijden van afbeeldingen. U kunt het formaat van de afbeelding wijzigen met hoogte 600 en breedte 800en de verwachte invoerhoogte en -breedte ophalen met de volgende code.
import glob
import numpy as np
from yolo_onnx_preprocessing_utils import preprocess
# use height and width based on the generated model
test_images_path = "automl_models_od_yolo/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
pad_list = []
for i in range(batch_size):
img_processed, pad = preprocess(image_files[i])
img_processed_list.append(img_processed)
pad_list.append(pad)
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Belangrijk
Alleen Mask R-CNN wordt ondersteund voor exemplaarsegmentatietaken. De voorverwerkingsstappen zijn alleen gebaseerd op Mask R-CNN.
Voer de volgende voorverwerkingsstappen uit voor de deductie van het ONNX-model:
Converteer de afbeelding naar RGB.
Pas het formaat van de afbeelding aan.
Wijzig HxWxC in CxHxW.
Converteren naar floattype.
Normaliseren met ImageNet's mean = [0.485, 0.456, 0.406] en std = [0.229, 0.224, 0.225].
resize_widthU resize_height kunt ook de waarden gebruiken die u tijdens de training hebt gebruikt, gebonden door de min_size en max_sizehyperparameters voor Mask R-CNN.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_height, resize_width):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_height: resize height of an input image
:type resize_height: Int
:param resize_width: resize width of an input image
:type resize_width: Int
:return: pre-processed image in numpy format
:rtype: ndarray of shape 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((resize_width, resize_height))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
# use height and width based on the trained model
# use height and width based on the generated model
test_images_path = "automl_models_is/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Deductie met ONNX Runtime
Deductie met ONNX Runtime verschilt voor elke computer vision-taak.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session, img_data):
"""perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
(No. of boxes, 4) (No. of boxes,) (No. of boxes,)
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""perform predictions with ONNX Runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
:rtype: list
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
pred = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return pred[0]
result = get_predictions_from_ONNX(session, img_data)
Het segmentatiemodel van het exemplaar voorspelt vakken, labels, scores en maskers. ONNX voert een voorspeld masker per exemplaar uit, samen met de bijbehorende begrenzingsvakken en de betrouwbaarheidsscore van klassen. Mogelijk moet u indien nodig converteren van binair masker naar veelhoek.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores , masks with shapes
(No. of instances, 4) (No. of instances,) (No. of instances,)
(No. of instances, 1, HEIGHT, WIDTH))
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
Pas softmax() op voorspelde waarden toe om betrouwbaarheidsscores (waarschijnlijkheden) voor elke klasse op te halen. Vervolgens is de voorspelling de klasse met de hoogste waarschijnlijkheid.
conf_scores = torch.nn.functional.softmax(torch.from_numpy(scores), dim=1)
class_preds = torch.argmax(conf_scores, dim=1)
print("predicted classes:", ([(class_idx.item(), classes[class_idx]) for class_idx in class_preds]))
Deze stap verschilt van classificatie van meerdere klassen. U moet van toepassing zijn op sigmoid de logboeken (ONNX-uitvoer) om betrouwbaarheidsscores te krijgen voor afbeeldingsclassificatie met meerdere labels.
Zonder PyTorch
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = sigmoid(scores)
image_wise_preds = np.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Met PyTorch
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = torch.sigmoid(torch.from_numpy(scores))
image_wise_preds = torch.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Voor classificatie met meerdere klassen en meerdere labels kunt u dezelfde stappen volgen die eerder zijn vermeld voor alle ondersteunde modelarchitecturen in AutoML.
Voor objectdetectie worden voorspellingen automatisch op de schaal van height_onnx, width_onnx. Als u de voorspelde vakcoördinaten wilt transformeren naar de oorspronkelijke dimensies, kunt u de volgende berekeningen implementeren.
Xmin * original_width/width_onnx
Ymin * original_height/height_onnx
Xmax * original_width/width_onnx
Ymax * original_height/height_onnx
Een andere optie is om de volgende code te gebruiken om de afmetingen van het vak te schalen in het bereik van [0, 1]. Hierdoor kunnen de vakcoördinaten worden vermenigvuldigd met de oorspronkelijke afbeeldingshoogte en -breedte met respectieve coördinaten (zoals beschreven in de sectie Voorspellingen visualiseren) om vakken in oorspronkelijke afbeeldingsdimensies op te halen.
def _get_box_dims(image_shape, box):
box_keys = ['topX', 'topY', 'bottomX', 'bottomY']
height, width = image_shape[0], image_shape[1]
box_dims = dict(zip(box_keys, [coordinate.item() for coordinate in box]))
box_dims['topX'] = box_dims['topX'] * 1.0 / width
box_dims['bottomX'] = box_dims['bottomX'] * 1.0 / width
box_dims['topY'] = box_dims['topY'] * 1.0 / height
box_dims['bottomY'] = box_dims['bottomY'] * 1.0 / height
return box_dims
def _get_prediction(boxes, labels, scores, image_shape, classes):
bounding_boxes = []
for box, label_index, score in zip(boxes, labels, scores):
box_dims = _get_box_dims(image_shape, box)
box_record = {'box': box_dims,
'label': classes[label_index],
'score': score.item()}
bounding_boxes.append(box_record)
return bounding_boxes
# Filter the results with threshold.
# Please replace the threshold for your test scenario.
score_threshold = 0.8
filtered_boxes_batch = []
for batch_sample in range(0, batch_size*3, 3):
# in case of retinanet change the order of boxes, labels, scores to boxes, scores, labels
# confirm the same from order of boxes, labels, scores output_names
boxes, labels, scores = predictions[batch_sample], predictions[batch_sample + 1], predictions[batch_sample + 2]
bounding_boxes = _get_prediction(boxes, labels, scores, (height_onnx, width_onnx), classes)
filtered_bounding_boxes = [box for box in bounding_boxes if box['score'] >= score_threshold]
filtered_boxes_batch.append(filtered_bounding_boxes)
Met de volgende code worden vakken, labels en scores gemaakt. Gebruik deze details van het begrenzingsvak om dezelfde naverwerkingsstappen uit te voeren als voor het Snellere R-CNN-model.
U kunt de stappen voor Snellere R-CNN gebruiken (in het geval van Mask R-CNN heeft elk voorbeeld vier elementenvakken, labels, scores, maskers) of raadpleegt u de sectie voorspellingen visualiseren voor exemplaarsegmentatie.
 Python SDK azure-ai-ml v2 (actueel)
Python SDK azure-ai-ml v2 (actueel)