Router- en connectiviteitsvereisten voor Azure Machine Learning-deductie
Azure Machine Learning-deductierouter is een essentieel onderdeel voor realtime deductie met kubernetes-cluster. In dit artikel vindt u meer informatie over:
- Wat is de Azure Machine Learning-deductierouter?
- Hoe automatisch schalen werkt
- Prestaties van deductieaanvraag configureren en voldoen (# van aanvragen per seconde en latentie)
- Verbinding maken iviteitsvereisten voor AKS-deductiecluster
Wat is de Azure Machine Learning-deductierouter?
Azure Machine Learning-deductierouter is het front-endonderdeel (azureml-fe) dat is geïmplementeerd op AKS- of Arc Kubernetes-cluster tijdens de implementatietijd van de Azure Machine Learning-extensie. Het heeft de volgende functies:
- Hiermee worden binnenkomende deductieaanvragen van de load balancer van het cluster of de ingangscontroller naar de bijbehorende modelpods gerouteerd.
- Taken verdelen over alle binnenkomende deductieaanvragen met slimme gecoördineerde routering.
- Beheert automatisch schalen van modelpods.
- Fouttolerante en failovermogelijkheid, waardoor deductieaanvragen altijd worden verwerkt voor kritieke bedrijfstoepassingen.
De volgende stappen zijn de wijze waarop aanvragen worden verwerkt door de front-end:
- Client verzendt een aanvraag naar de load balancer.
- Load balancer verzendt naar een van de front-ends.
- De front-end zoekt de servicerouter (het front-endexemplaren die als coördinator fungeert) voor de service.
- De servicerouter selecteert een back-end en retourneert deze naar de front-end.
- De front-end stuurt de aanvraag door naar de back-end.
- Nadat de aanvraag is verwerkt, verzendt de back-end een antwoord naar het front-endonderdeel.
- De front-end geeft het antwoord weer door aan de client.
- De front-end informeert de servicerouter dat de back-end is verwerkt en beschikbaar is voor andere aanvragen.
In het volgende diagram ziet u deze stroom:
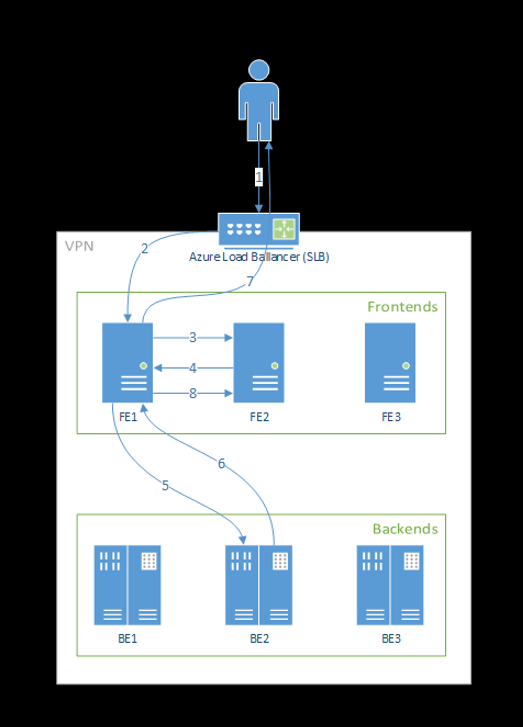
Zoals u in het bovenstaande diagram kunt zien, worden standaard drie azureml-fe exemplaren gemaakt tijdens de implementatie van de Azure Machine Learning-extensie. Eén exemplaar fungeert als coördinerende rol en de andere exemplaren dienen binnenkomende deductieaanvragen. Het coördinerende exemplaar bevat alle informatie over modelpods en neemt beslissingen over welke modelpod binnenkomende aanvraag moet worden verwerkt, terwijl de serverexemplaren azureml-fe verantwoordelijk zijn voor het routeren van de aanvraag naar de geselecteerde modelpod en het antwoord weer doorgeven aan de oorspronkelijke gebruiker.
Automatisch schalen
De Azure Machine Learning-deductierouter verwerkt automatisch schalen voor alle modelimplementaties in het Kubernetes-cluster. Omdat alle deductieaanvragen deze doorlopen, beschikt het over de benodigde gegevens om de geïmplementeerde modellen automatisch te schalen.
Belangrijk
Schakel Kubernetes Horizontal Pod Autoscaler (HPA) niet in voor modelimplementaties. Hierdoor concurreren de twee onderdelen voor automatisch schalen met elkaar. Azureml-fe is ontworpen voor het automatisch schalen van modellen die zijn geïmplementeerd door Azure Machine Learning, waarbij HPA het gebruik van modellen zou moeten raden of benaderen op basis van een algemeen metrische waarde, zoals CPU-gebruik of een aangepaste metrische configuratie.
Azureml-fe schaalt het aantal knooppunten in een AKS-cluster niet, omdat dit kan leiden tot onverwachte kostenstijgingen. In plaats daarvan wordt het aantal replica's voor het model binnen de grenzen van het fysieke cluster geschaald. Als u het aantal knooppunten in het cluster wilt schalen, kunt u het cluster handmatig schalen of de automatische schaalaanpassing van AKS-clusters configureren.
Automatische schaalaanpassing kan worden beheerd door scale_settings de eigenschap in de YAML-implementatie. In het volgende voorbeeld ziet u hoe u automatische schaalaanpassing inschakelt:
# deployment yaml
# other properties skipped
scale_setting:
type: target_utilization
min_instances: 3
max_instances: 15
target_utilization_percentage: 70
polling_interval: 10
# other deployment properties continue
De beslissing om omhoog of omlaag te schalen is gebaseerd op utilization of the current container replicas.
utilization_percentage = (The number of replicas that are busy processing a request + The number of requests queued in azureml-fe) / The total number of current replicas
Als dit aantal groter is target_utilization_percentage, worden er meer replica's gemaakt. Als deze lager is, worden replica's verminderd. Standaard is het doelgebruik 70%.
Beslissingen om replica's toe te voegen zijn gretig en snel (ongeveer 1 seconde). Beslissingen om replica's te verwijderen zijn conservatief (ongeveer 1 minuut).
Als u bijvoorbeeld een modelservice wilt implementeren en wilt weten dat veel exemplaren (pods/replica's) moeten worden geconfigureerd voor doelaanvragen per seconde (RPS) en doelresponstijd. U kunt de vereiste replica's berekenen met behulp van de volgende code:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Prestaties van azureml-fe
De azureml-fe kan 5 K aanvragen per seconde (QPS) bereiken met een goede latentie, met een overhead die gemiddeld niet groter is dan 3 ms en 15 ms bij een percentiel van 99%.
Notitie
Als u RPS-vereisten hebt die hoger zijn dan 10.000, kunt u de volgende opties overwegen:
- Verhoog resourceaanvragen/-limieten voor
azureml-fepods. Standaard heeft het 2 vCPU- en 1.2G-geheugenresourcelimiet. - Verhoog het aantal exemplaren voor
azureml-fe. Azure Machine Learning maakt standaard 3 of 1azureml-feexemplaren per cluster.- Dit aantal exemplaren is afhankelijk van uw configuratie van
inferenceRouterHAde Azure Machine Learning-entensie. - Het verhoogde aantal exemplaren kan niet worden behouden, omdat het wordt overschreven met uw geconfigureerde waarde zodra de extensie is bijgewerkt.
- Dit aantal exemplaren is afhankelijk van uw configuratie van
- Neem contact op met Microsoft-experts voor hulp.
Informatie over de connectiviteitsvereisten voor het AKS-deductiecluster
Een AKS-cluster wordt geïmplementeerd met een van de volgende twee netwerkmodellen:
- Kubenet-netwerken: de netwerkresources worden doorgaans gemaakt en geconfigureerd als het AKS-cluster wordt geïmplementeerd.
- CNI-netwerken (Azure Container Networking Interface): het AKS-cluster is verbonden met een bestaande virtuele netwerkresource en -configuraties.
Voor Kubenet-netwerken wordt het netwerk gemaakt en juist geconfigureerd voor Azure Machine Learning Service. Voor het CNI-netwerk moet u de connectiviteitsvereisten begrijpen en ervoor zorgen dat DNS-omzetting en uitgaande connectiviteit voor AKS-deductie. U hebt bijvoorbeeld aanvullende stappen nodig als u een firewall gebruikt om netwerkverkeer te blokkeren.
In het volgende diagram ziet u de connectiviteitsvereisten voor AKS-deductie. Zwarte pijlen vertegenwoordigen de werkelijke communicatie en blauwe pijlen vertegenwoordigen de domeinnamen. Mogelijk moet u vermeldingen voor deze hosts toevoegen aan uw firewall of aan uw aangepaste DNS-server.
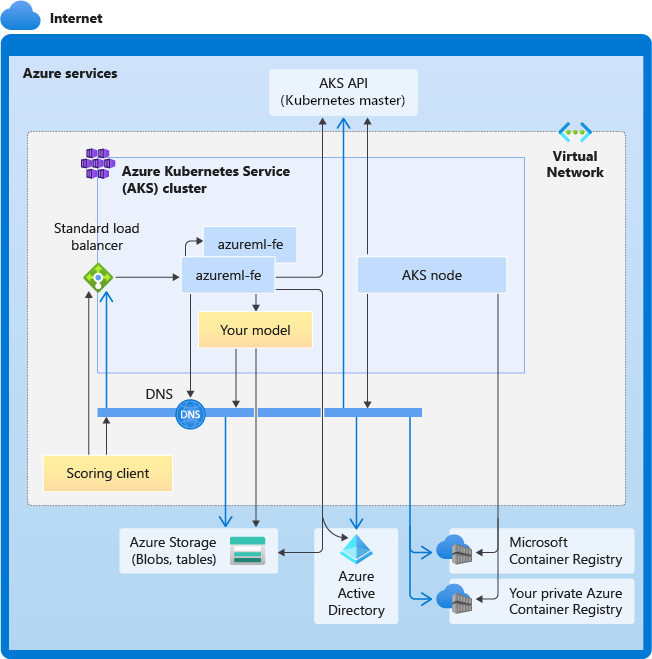
Zie Uitgaand verkeer voor clusterknooppunten in Azure Kubernetes Service beheren voor algemene AKS-connectiviteitsvereisten.
Zie Inkomend en uitgaand netwerkverkeer configureren voor toegang tot Azure Machine Learning-services achter een firewall.
Algemene VEREISTEN voor DNS-omzetting
DNS-omzetting binnen een bestaand VNet is onder uw controle. Bijvoorbeeld een firewall of aangepaste DNS-server. De volgende hosts moeten bereikbaar zijn:
| Hostnaam | Wordt gebruikt door |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
AKS API-server |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Your Azure Container Registry (ACR) |
<account>.blob.core.windows.net |
Azure Storage-account (blobopslag) |
api.azureml.ms |
Microsoft Entra-verificatie |
ingest-vienna<region>.kusto.windows.net |
Kusto-eindpunt voor het uploaden van telemetrie |
Verbinding maken iviteitsvereisten in chronologische volgorde: van cluster maken tot modelimplementatie
Direct nadat azureml-fe is geïmplementeerd, wordt geprobeerd om te starten. Hiervoor is het volgende vereist:
- DNS voor AKS-API-server oplossen
- Een query uitvoeren op de AKS-API-server om andere exemplaren van zichzelf te detecteren (dit is een service met meerdere pods)
- Verbinding maken naar andere exemplaren van zichzelf
Zodra azureml-fe is gestart, is de volgende verbinding vereist om goed te functioneren:
- Verbinding maken naar Azure Storage om dynamische configuratie te downloaden
- Dns voor Microsoft Entra-verificatieserver api.azureml.ms oplossen en ermee communiceren wanneer de geïmplementeerde service gebruikmaakt van Microsoft Entra-verificatie.
- Een query uitvoeren op de AKS-API-server om geïmplementeerde modellen te detecteren
- Communiceren met geïmplementeerde model-POD's
Op het moment van modelimplementatie moet het AKS-knooppunt voor een geslaagde modelimplementatie het volgende kunnen doen:
- DNS voor de ACR van de klant oplossen
- Afbeeldingen downloaden van de ACR van de klant
- DNS voor Azure-BLObs oplossen waar het model is opgeslagen
- Modellen downloaden van Azure-BLOBs
Nadat het model is geïmplementeerd en de service is gestart, detecteert azureml-fe het automatisch met behulp van de AKS-API en kan de aanvraag naar het model worden gerouteerd. Het moet kunnen communiceren met model-POD's.
Notitie
Als voor het geïmplementeerde model connectiviteit is vereist (bijvoorbeeld het opvragen van een externe database of een andere REST-service, het downloaden van een BLOB, enzovoort), moeten zowel DNS-omzetting als uitgaande communicatie voor deze services zijn ingeschakeld.
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor