Algoritmen selecteren voor Azure Machine Learning
Als u zich afvraagt welk machine learning-algoritme moet worden gebruikt, hangt het antwoord voornamelijk af van twee aspecten van uw data science-scenario:
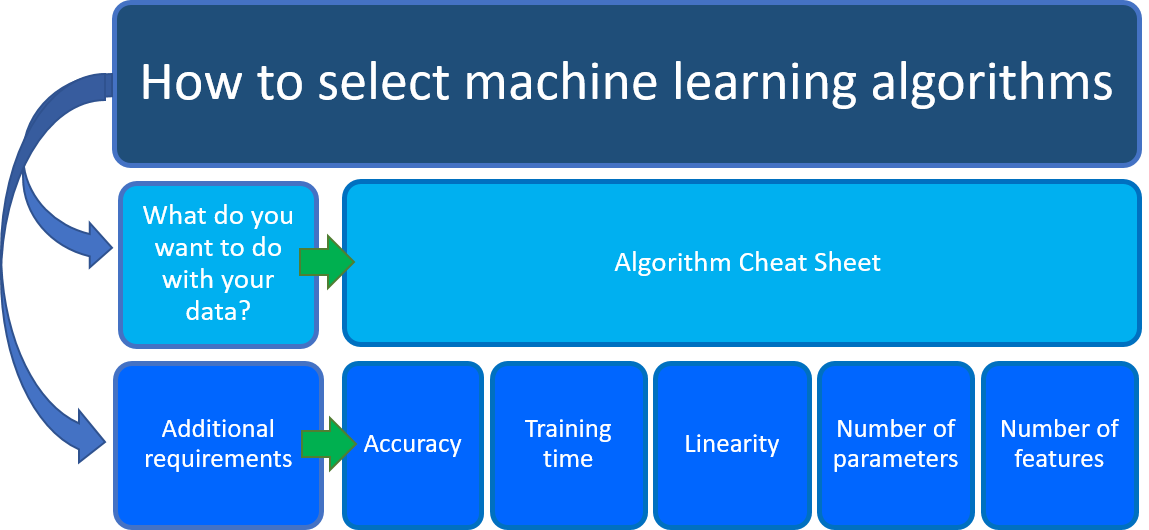
Wat wilt u doen met uw gegevens? Wat is de zakelijke vraag die u wilt beantwoorden door te leren van uw eerdere gegevens?
Wat zijn de vereisten van uw data science-scenario? Wat zijn de functies, nauwkeurigheid, trainingstijd, lineariteit en parameters die uw oplossing ondersteunt?
Notitie
De Azure Machine Learning-ontwerpfunctie ondersteunt twee typen onderdelen: klassieke vooraf gedefinieerde onderdelen (v1) en aangepaste onderdelen (v2). Deze twee typen onderdelen zijn NIET compatibel.
Klassieke vooraf gebouwde onderdelen zijn voornamelijk bedoeld voor gegevensverwerking en traditionele machine learning-taken, zoals regressie en classificatie. Dit type onderdeel wordt nog steeds ondersteund, maar er worden geen nieuwe onderdelen toegevoegd.
Met aangepaste onderdelen kunt u uw eigen code verpakken als onderdeel. Ze ondersteunen het delen van onderdelen in werkruimten en naadloze creatie in Studio-, CLI v2- en SDK v2-interfaces.
Voor nieuwe projecten raden we u sterk aan aangepaste onderdelen te gebruiken, die compatibel zijn met AzureML V2 en nieuwe updates blijven ontvangen.
Dit artikel is van toepassing op klassieke vooraf samengestelde onderdelen en is niet compatibel met CLI v2 en SDK v2.
Cheatsheet voor Azure Machine Learning-algoritme
Het cheatsheet voor Azure Machine Learning-algoritme helpt u bij de eerste overweging: Wat wilt u doen met uw gegevens? Zoek op het cheatsheet naar de taak die u wilt uitvoeren en zoek vervolgens een Azure Machine Learning Designer-algoritme voor de predictive analytics-oplossing.
Notitie
U kunt het cheatsheet voor machine learning-algoritmen downloaden.
De ontwerpfunctie biedt een uitgebreide portfolio met algoritmen, zoals Multiclass Decision Forest, Aanbevelingssystemen, Neural Network Regression, Multiclass Neural Network en K-Means Clustering. Elk algoritme is ontworpen om een ander type machine learning-probleem op te lossen. Zie de referentie voor het algoritme en onderdeel voor een volledige lijst, samen met documentatie over hoe elk algoritme werkt en hoe u parameters kunt afstemmen om het algoritme te optimaliseren.
Houd naast deze richtlijnen rekening met andere vereisten bij het kiezen van een machine learning-algoritme. Hieronder volgen aanvullende factoren om rekening mee te houden, zoals de nauwkeurigheid, trainingstijd, lineariteit, het aantal parameters en het aantal functies.
Vergelijking van machine learning-algoritmen
Sommige algoritmen maken specifieke veronderstellingen over de structuur van de gegevens of de gewenste resultaten. Als u er een kunt vinden die aansluit bij uw behoeften, kunt u hiermee nuttigere resultaten, nauwkeurigere voorspellingen of snellere trainingstijden krijgen.
De volgende tabel bevat een overzicht van enkele van de belangrijkste kenmerken van algoritmen uit de classificatie-, regressie- en clusteringfamilies:
| Algoritme | Nauwkeurigheid | Trainingstijd | Lineariteit | Parameters | Notes |
|---|---|---|---|---|---|
| Classificatiefamilie | |||||
| Twee klassen logistieke regressie | Goed | Snel | Ja | 4 | |
| Beslissingsforest met twee klassen | Uitstekend | Matig | Nee | 5 | Toont tragere scoretijden. We raden u aan om niet te werken met One-vs-All Multiclass, vanwege tragere scoretijden veroorzaakt door threadvergrendeling bij het verzamelen van structuurvoorspellingen |
| Twee klassen versterkte beslissingsstructuur | Uitstekend | Matig | Nee | 6 | Grote geheugenvoetafdruk |
| Twee klassen neuraal netwerk | Goed | Matig | Nee | 8 | |
| Gemiddelde perceptron van twee klassen | Goed | Matig | Ja | 4 | |
| Ondersteuningsvectormachine met twee klassen | Goed | Snel | Ja | 5 | Geschikt voor grote functiesets |
| Logistieke regressie met meerdere klassen | Goed | Snel | Ja | 4 | |
| Beslissingsforest met meerdere klassen | Uitstekend | Matig | Nee | 5 | Toont tragere scoretijden |
| Versterkte beslissingsstructuur met meerdere klassen | Uitstekend | Matig | Nee | 6 | Heeft de neiging om de nauwkeurigheid te verbeteren met een klein risico van minder dekking |
| Neural netwerk met meerdere klassen | Goed | Matig | Nee | 8 | |
| Een-vs-alle multiklasse | - | - | - | - | Eigenschappen van de geselecteerde methode met twee klassen weergeven |
| Regressiefamilie | |||||
| Lineaire regressie | Goed | Snel | Ja | 4 | |
| Regressie van beslissingsforest | Uitstekend | Matig | Nee | 5 | |
| Versterkte beslissingsstructuurregressie | Uitstekend | Matig | Nee | 6 | Grote geheugenvoetafdruk |
| Regressie van neuraal netwerk | Goed | Matig | Nee | 8 | |
| Clusteringfamilie | |||||
| K-means-clustering | Uitstekend | Matig | Ja | 8 | Een clustering-algoritme |
Vereisten voor data science-scenario's
Zodra u weet wat u met uw gegevens wilt doen, moet u andere vereisten voor uw data science-scenario bepalen.
Maak keuzes en eventueel compromissen voor de volgende vereisten:
- Nauwkeurigheid
- Trainingstijd
- Lineariteit
- Aantal parameters
- Aantal functies
Nauwkeurigheid
Nauwkeurigheid in machine learning meet de effectiviteit van een model als het aandeel werkelijke resultaten in totaal. In de ontwerpfunctie berekent het onderdeel Evaluate Model een set metrische metrische gegevens voor evaluatie van industriestandaarden. U kunt dit onderdeel gebruiken om de nauwkeurigheid van een getraind model te meten.
Het verkrijgen van het meest nauwkeurige antwoord dat mogelijk is, is niet altijd nodig. Soms is een benadering voldoende, afhankelijk van waarvoor u deze wilt gebruiken. Als dat het geval is, kunt u de verwerkingstijd mogelijk aanzienlijk verminderen door te blijven met meer methoden bij benadering. Bij benaderingsmethoden worden ook op natuurlijke wijze overfitting voorkomen.
Er zijn drie manieren om het onderdeel Evaluate Model te gebruiken:
- Genereer scores voor uw trainingsgegevens om het model te evalueren.
- Genereer scores op het model, maar vergelijk deze scores met scores voor een gereserveerde testset.
- Vergelijk scores voor twee verschillende maar gerelateerde modellen met behulp van dezelfde set gegevens.
Zie het onderdeel Model evalueren voor een volledige lijst met metrische gegevens en benaderingen die u kunt gebruiken om de nauwkeurigheid van machine learning-modellen te evalueren.
Trainingstijd
Bij leren onder supervisie betekent training het gebruik van historische gegevens om een machine learning-model te bouwen waarmee fouten worden geminimaliseerd. Het aantal minuten of uren dat nodig is om een model te trainen, varieert veel tussen algoritmen. Trainingstijd is vaak nauw gekoppeld aan nauwkeurigheid; de ene gaat meestal mee met de andere.
Daarnaast zijn sommige algoritmen gevoeliger voor het aantal gegevenspunten dan andere. U kunt een specifiek algoritme kiezen omdat u een tijdsbeperking hebt, met name wanneer de gegevensset groot is.
In de ontwerpfunctie is het maken en gebruiken van een machine learning-model doorgaans een proces met drie stappen:
Configureer een model door een bepaald type algoritme te kiezen en vervolgens de parameters of hyperparameters te definiëren.
Geef een gegevensset op die is gelabeld en die compatibel is met het algoritme. Verbind zowel de gegevens als het model met het onderdeel Train Model.
Nadat de training is voltooid, gebruikt u het getrainde model met een van de scoreonderdelen om voorspellingen te doen over nieuwe gegevens.
Lineariteit
Lineariteit in statistieken en machine learning betekent dat er een lineaire relatie is tussen een variabele en een constante in uw gegevensset. Bij lineaire classificatiealgoritmen wordt bijvoorbeeld ervan uitgegaan dat klassen kunnen worden gescheiden door een rechte lijn (of een hogeredimensionale analog).
Veel machine learning-algoritmen maken gebruik van lineariteit. In de Azure Machine Learning-ontwerpfunctie zijn deze onder andere:
- Logistieke regressie met meerdere klassen
- Twee klassen logistieke regressie
- Ondersteuningsvectormachines
Lineaire regressiealgoritmen gaan ervan uit dat gegevenstrends een rechte lijn volgen. Deze aanname is niet slecht voor sommige problemen, maar voor andere problemen vermindert het de nauwkeurigheid. Ondanks hun nadelen zijn lineaire algoritmen populair als eerste strategie. Ze zijn meestal algoritmes eenvoudig en snel te trainen.
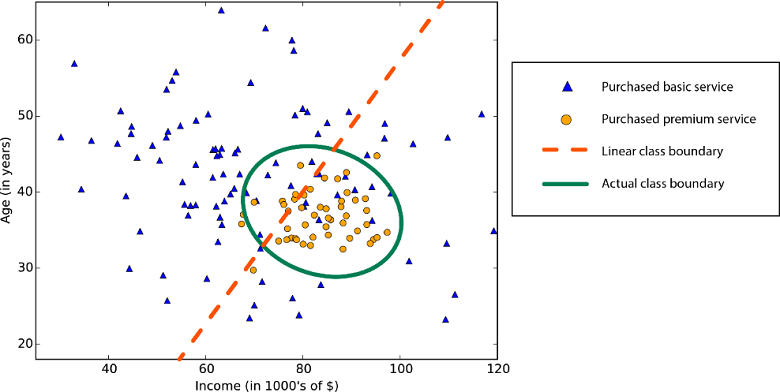
Niet-lineaire klassegrens: afhankelijk van een lineair classificatie-algoritme zou een lage nauwkeurigheid opleveren.
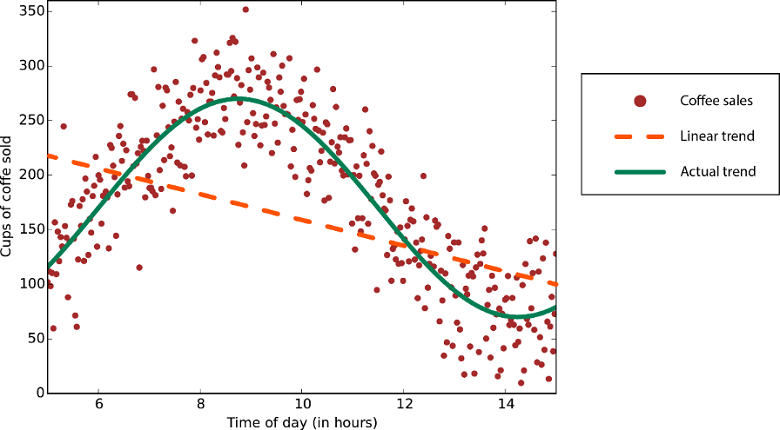
Gegevens met een niet-lineaire trend: Het gebruik van een lineaire regressiemethode genereert veel grotere fouten dan nodig is.
Aantal parameters
Parameters zijn de knoppen die een data scientist krijgt bij het instellen van een algoritme. Dit zijn getallen die van invloed zijn op het gedrag van het algoritme, zoals fouttolerantie of het aantal iteraties, of opties tussen varianten van hoe het algoritme zich gedraagt. De trainingstijd en nauwkeurigheid van het algoritme kunnen soms gevoelig zijn voor het verkrijgen van precies de juiste instellingen. Normaal gesproken vereisen algoritmen met grote aantallen parameters de meeste proefversies en fouten om een goede combinatie te vinden.
U kunt ook het onderdeel Tune Model Hyperparameters gebruiken in de ontwerpfunctie. Het doel van dit onderdeel is om de optimale hyperparameters voor een machine learning-model te bepalen. Het onderdeel bouwt en test meerdere modellen met behulp van verschillende combinaties van instellingen. Het vergelijkt metrische gegevens over alle modellen om de combinaties van instellingen op te halen.
Hoewel dit een uitstekende manier is om ervoor te zorgen dat u de parameterruimte overspant, neemt de tijd die nodig is om een model te trainen exponentieel toe met het aantal parameters. Het voordeel is dat het hebben van veel parameters meestal aangeeft dat een algoritme meer flexibiliteit heeft. Het kan vaak zeer goede nauwkeurigheid bereiken, mits u de juiste combinatie van parameterinstellingen kunt vinden.
Aantal functies
In machine learning is een functie een kwantificeerbare variabele van het fenomeen dat u probeert te analyseren. Voor bepaalde typen gegevens kan het aantal functies zeer groot zijn in vergelijking met het aantal gegevenspunten. Dit is vaak het geval bij genetica of tekstuele gegevens.
Een groot aantal functies kan een aantal leeralgoritmen vertragen, waardoor trainingstijd onfeasibly lang wordt. Ondersteuningsvectormachines zijn geschikt voor scenario's met een groot aantal functies. Daarom zijn ze in veel toepassingen gebruikt van het ophalen van gegevens naar tekst- en afbeeldingsclassificatie. Ondersteuningsvectormachines kunnen worden gebruikt voor zowel classificatie- als regressietaken.
Functieselectie verwijst naar het proces van het toepassen van statistische tests op invoer, op basis van een opgegeven uitvoer. Het doel is om te bepalen welke kolommen meer voorspellend zijn voor de uitvoer. Het onderdeel Functieselectie op basis van filters in de ontwerpfunctie biedt meerdere functieselectiealgoritmen waaruit u kunt kiezen. Het onderdeel bevat correlatiemethoden zoals Pearson-correlatie en chi-kwadraatwaarden.
U kunt ook het onderdeel Permutation Feature Importance gebruiken om een set scoren voor functiebelang te berekenen voor uw gegevensset. Vervolgens kunt u deze scores gebruiken om de beste functies te bepalen die u in een model kunt gebruiken.